
如何在 Python 中将 PDF 轉换為图像
PDF(便攜式文件格式)是網路上最受歡迎的資料傳輸文件格式,因為它能保持內容格式,並透過安全權限幫助保護資料安全。 有些情況下,我們需要將 PDF 檔案轉換為 JPG 影像或任何其他影像格式,例如 PNG、BMP、TIFF 或 GIF。 網路上有很多 JPG 轉換資源,但是如果我們用 Python 創建自己的 PDF 轉圖像轉換工具,那該有多酷啊?
什麼是Python?
Python 是一種高階程式語言,用於建立軟體應用程式、網站、自動化任務、進行資料分析以及執行人工智慧和機器學習任務。 它也是一種腳本語言,因為它是解釋執行的,這使得它在快速開發和測試方面更加強大。
要建立 PDF 轉圖像轉換器,我們需要在電腦上安裝 Python 3+。 從官方網站下載並安裝最新版本。
在本文中,我們將使用 Python PDF 轉圖像庫來建立我們自己的圖像轉換應用程式。 為此,我們將使用 Python 中最受歡迎的兩個函式庫:PDF2Image 和 PyMuPDF。
如何在 Python 中將 PDF 文件轉換為圖像文件
- 安裝用於將 PDF 轉換為映像的 Python 庫。
- 從任意位置載入現有的 PDF 檔案。
- 利用轉換方法。
- 遍歷文件的每一頁。
- 使用儲存方法將每一頁儲存為 JPG 或 PNG 映像。
建立一個新的 Python 文件
- 開啟 Python IDLE 應用程序,然後按 Ctrl + N 鍵。 文字編輯器將會開啟。 您可以使用您喜歡的文字編輯器來完成此操作。
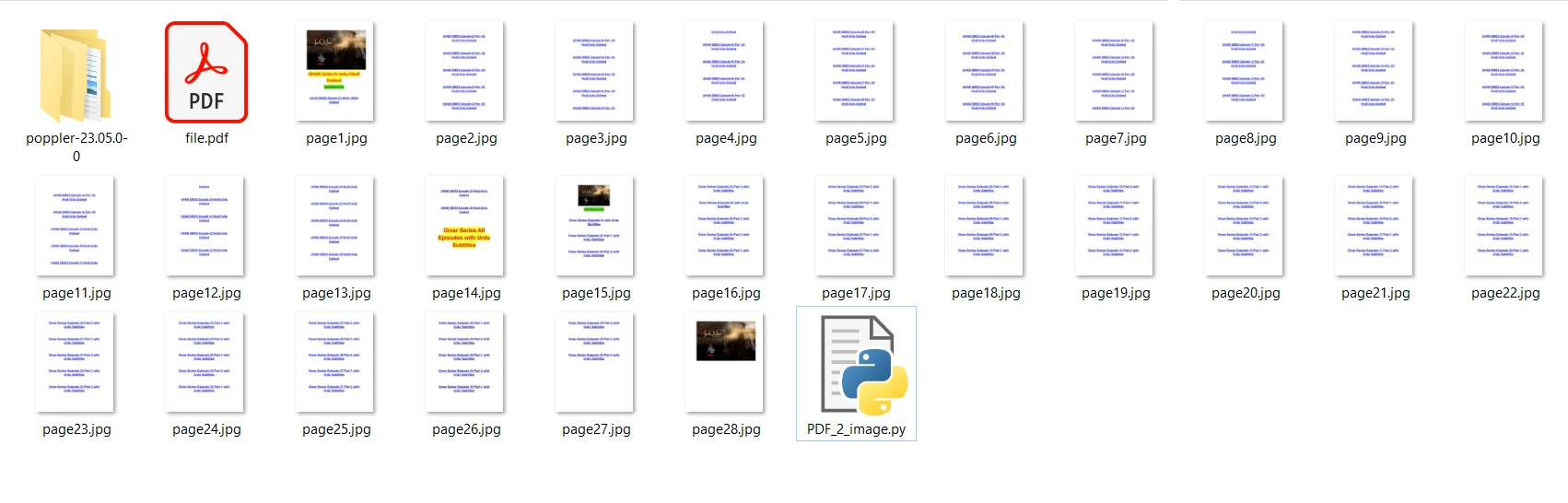
- 將檔案儲存為 pdf2image.py,並儲存在與要轉換為影像的 PDF 檔案相同的位置。
我們將使用的輸入PDF檔案包含28頁,內容如下:

使用 PDF2Image 庫將 PDF 文件轉換為圖像文件
1. 安裝 PDF2Image Python 函式庫
PDF2Image 是一個封裝了 pdftocairo 和 pdftoppm 的模組。 它適用於 Python 3.7+,可將 PDF 轉換為 PIL 影像物件。 其先前的版本歷史記錄顯示,它只是對 pdftoppm 進行了封裝,用於將 PDF 轉換為圖像,並且僅適用於 Python 3+。
若要安裝 pdf2image 軟體包,請開啟 Windows 命令提示字元或 Windows PowerShell,並使用下列 pip 命令:
pip install pdf2imagepip install pdf2imagePip (首選安裝程式)是 Python 的套件管理器。 它會下載並安裝第三方軟體包,這些軟體包提供 Python 標準庫中沒有的功能和功能。
注意:要從命令列的任何位置執行此命令,必須將 Python 新增到 PATH 中。 對於 Python 3+,建議使用 pip3,因為它是 pip 的更新版本。
2. 安裝 Poppler
Poppler 是一個用於處理 PDF 檔案的免費開源程式庫。 它用於渲染 PDF 文件、讀取內容以及修改 PDF 文件中的內容。 它常用於Linux用戶。 但是,對於 Windows 系統,我們需要下載最新版本的 Poppler。
適用於 Windows
Windows 使用者可以在這裡下載最新版本的 Poppler: @oschwartz10612 版本。 然後您需要將 bin/資料夾新增至 PATH 環境變數。
適用於 Mac
Mac 用戶還需要安裝Poppler 。 可以使用Brew安裝:
brew install popplerbrew install poppler適用於 Linux
大多數 Linux 發行版都帶有 pdftoppm 和 pdftocairo 命令列實用程式。 如果這些實用程式未安裝,您可以使用軟體套件管理器安裝 poppler-utils。
對於平台無關(使用 conda)
安裝
poppler:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELL安裝 pdf2image:
pip install pdf2imagepip install pdf2imageSHELL
現在一切準備就緒,讓我們開始編寫將 PDF 轉換為圖像的程式碼。
3. 將 PDF 檔案轉換為影像檔案的程式碼
以下程式碼將對輸入的PDF檔案進行影像轉換:
from pdf2image import convert_from_path
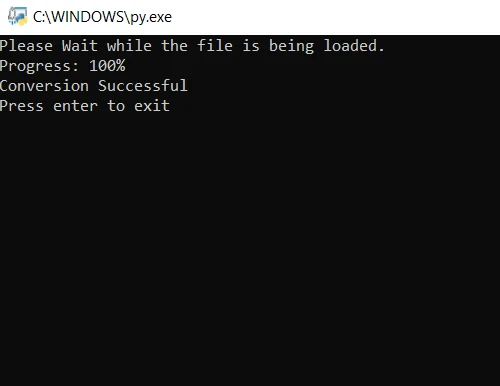
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")在上面的程式碼中,我們首先使用 convert_from_path 方法來開啟檔案。 此方法開啟位於指定路徑的檔案。 然後,我們遍歷 PDF 檔案的每一頁,將其轉換為 JPG 影像。 最後,使用 save 方法將每個轉換後的頁面儲存為 JPG 映像檔。現在,運行程式並等待轉換完成。 輸出影像檔案保存在與程式相同的資料夾中。
使用 PyMuPDF 庫將 PDF 文件轉換為圖像
1. 安裝 PyMuPDF Python 函式庫
PyMuPDF 是 MuPDF 的擴展 Python 綁定,MuPDF 是一個輕量級的電子書、PDF 和 XPS 檢視器、渲染器和工具包。 它可以將 PDF 檔案轉換為 JPG 或 PNG 等其他格式。 PyMuPDF 適用於 Python 3.7 以上版本。
若要安裝 PyMuPDF 套件,請開啟 Windows 命令提示字元或 Windows PowerShell,並使用下列 pip 命令:
pip install pymupdfpip install pymupdf請注意,PyMuPDF 不需要像 PDF2Image 套件那樣的任何額外庫。
2. 將 PDF 檔案轉換為圖像的程式碼
以下程式碼將從 PyMuPDF 匯入 fitz 模組,以便我們可以將 PDF 轉換為圖像:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
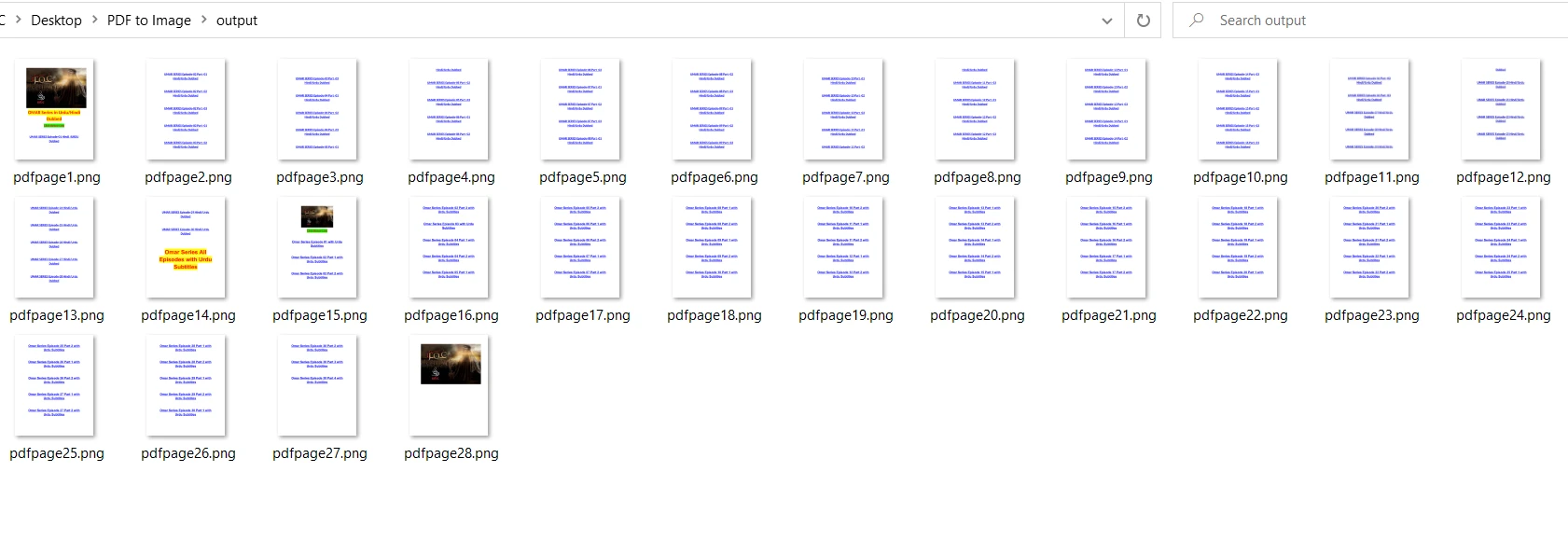
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()在上面的程式碼中,檔案名稱作為參數傳遞給 fitz.open 方法以開啟檔案。接下來,我遍歷整個文件並分別載入每一頁。 使用 get_pixmap 方法將每個文件頁面轉換為映像像素,然後使用 save 方法將產生的影像儲存到輸出資料夾中。 最後,關閉已開啟的文件以釋放記憶體。
與 PDF2Image 相比,PyMuPDF 在將 PDF 轉換為 PNG 時速度更快。 由於壓縮比的原因,PDF2Image 處理 PNG 格式影像時速度可能較慢。 輸出結果與 PDF2Image 的輸出結果相同:
Rendering PDF to Image Conversions in C
IronPDF庫
IronPDF是一個用於產生、讀取和操作 PDF 文件的庫。 它的特點在於藉助 Chromium 核心將 HTML 渲染成 PDF。這項特性使其在需要將 HTML 文件或 URL 轉換為 PDF 文件的開發人員中廣受歡迎。 此外,它還提供將各種格式的文件轉換為 PDF 文件的功能。
您也可以使用兩行程式碼將 PDF 檔案柵格化為影像。 以下程式碼示範如何將 PDF 檔案轉換為不同的影像格式:
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);















