
Python Requests 库(开发者如何使用)
Python因其简单性和可读性而广受赞誉,使其成为开发者在进行网络抓取和与API交互时的热门选择。实现这种交互的关键库之一是Python Requests 库。 Requests 是一个用于Python的HTTP请求库,让您可以轻松发送HTTP请求。 在本文中,我们将深入探讨Python Requests 库的功能,探索其使用的实际示例,并介绍 IronPDF,展示如何将其与Requests 结合使用以从网络数据创建和操作PDF。
Requests 库介绍
Python Requests 库的创建是为了使HTTP请求更简单和更友好。 它通过一个简单的API抽象出请求过程中的复杂性,以便您可以专注于与网页上的服务和数据进行交互。 无论您是需要获取网页,与REST API交互,禁用SSL证书验证,还是向服务器发送数据,Requests 库都能满足您的需求。
关键特性
1.简洁性:语法易于使用和理解。
- HTTP 方法:支持所有 HTTP 方法 - GET、POST、PUT、DELETE 等。 3.会话对象:在请求之间维护 cookie。 4.身份验证:简化添加身份验证标头的操作。 5.代理:支持 HTTP 代理。 6.超时:有效管理请求超时。
- SSL 验证:默认情况下验证 SSL 证书。
安装 Requests
要开始使用 Requests,您需要先安装它。 这可以通过pip来完成:
pip install requestspip install requests基本用法
以下是如何使用 Requests 来获取网页的简单示例:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)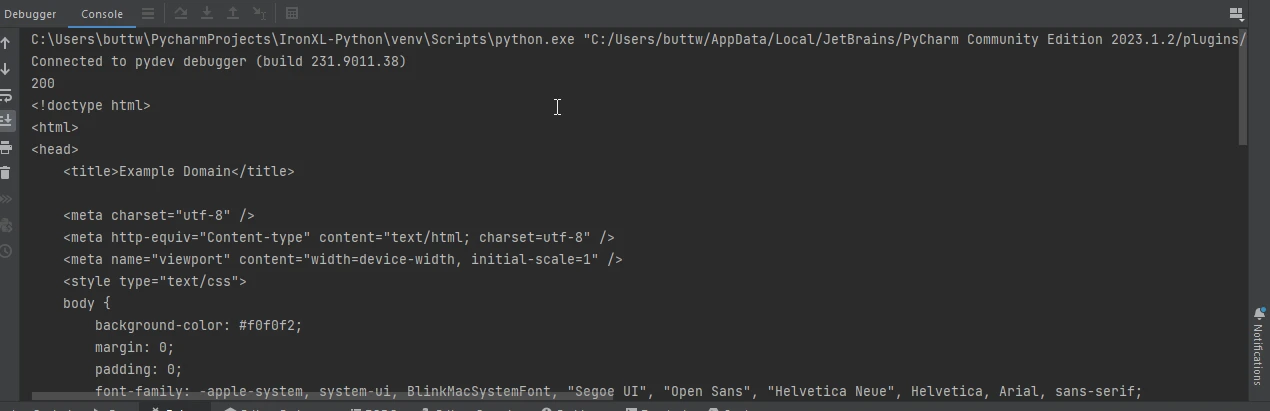
在URL中发送参数
通常,您需要将参数传递给URL。 Python Requests 模块通过params 关键字使这一操作变得简便:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)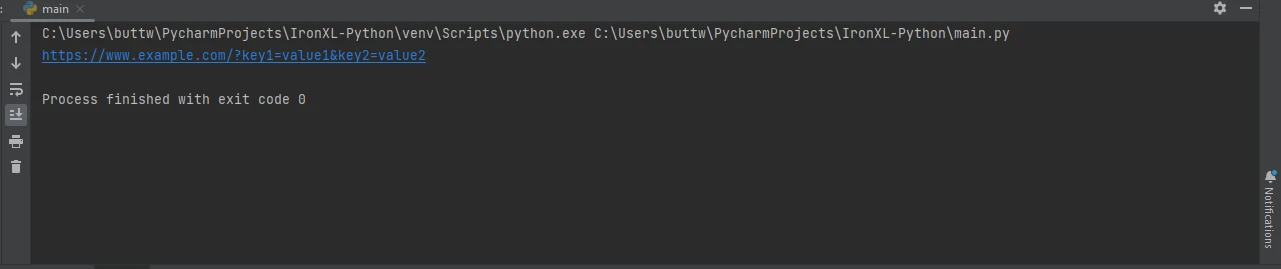
处理JSON数据
与API交互通常涉及JSON数据。 Requests 用内置的JSON支持简化了这一过程:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)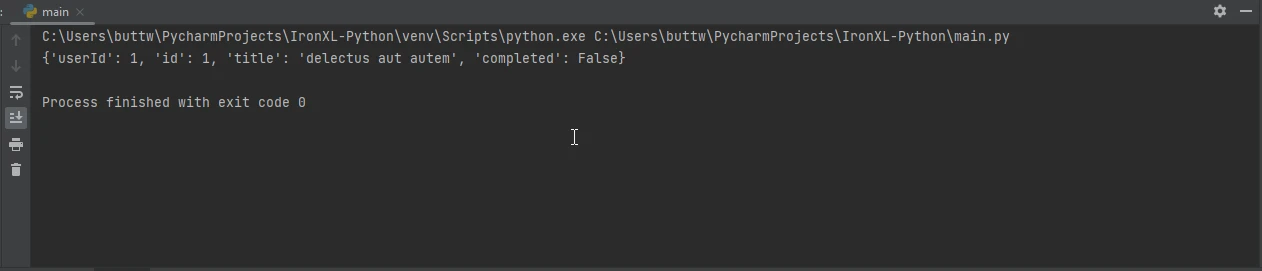
处理请求头
请求头对于HTTP请求至关重要。 您可以像这样添加自定义头到您的请求:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)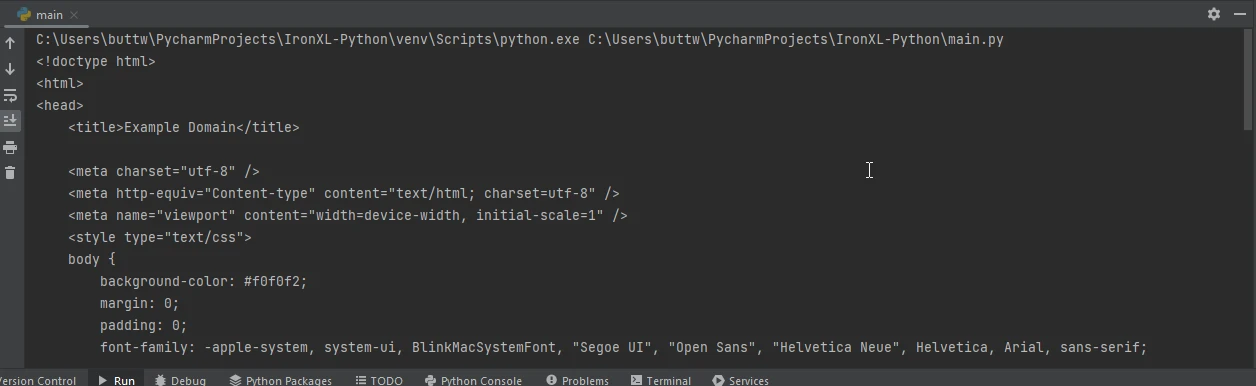
文件上传
Requests 也支持文件上传。 以下是如何上传文件的方法:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)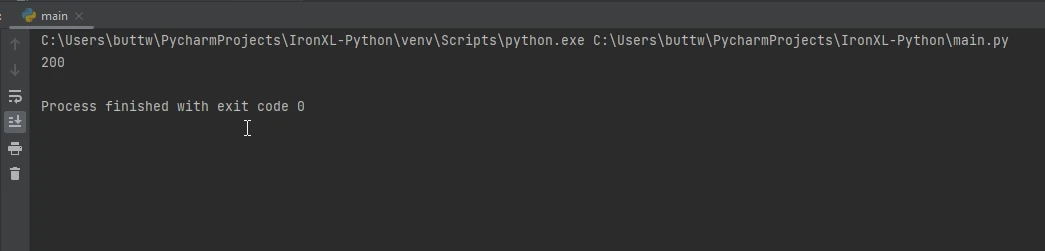
介绍IronPDF for Python
IronPDF是一个功能强大的PDF生成库,可用于在Python应用程序中创建、编辑和操作PDF。 它特别适用于需要从HTML内容生成PDF的场景,成为创建报告、发票或任何需要以便携格式分发的文档的出色工具。
安装 IronPDF
要安装IronPDF,可使用pip:
pip install ironpdf
将IronPDF与Requests结合使用
结合 Requests 和 IronPDF 可让您从网络获取数据并直接将其转换为PDF文档。 这对于从网页数据创建报告或将网页保存为PDF特别有用。
以下是如何使用 Requests 来获取网页,然后使用 IronPDF 将其保存为PDF的示例:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
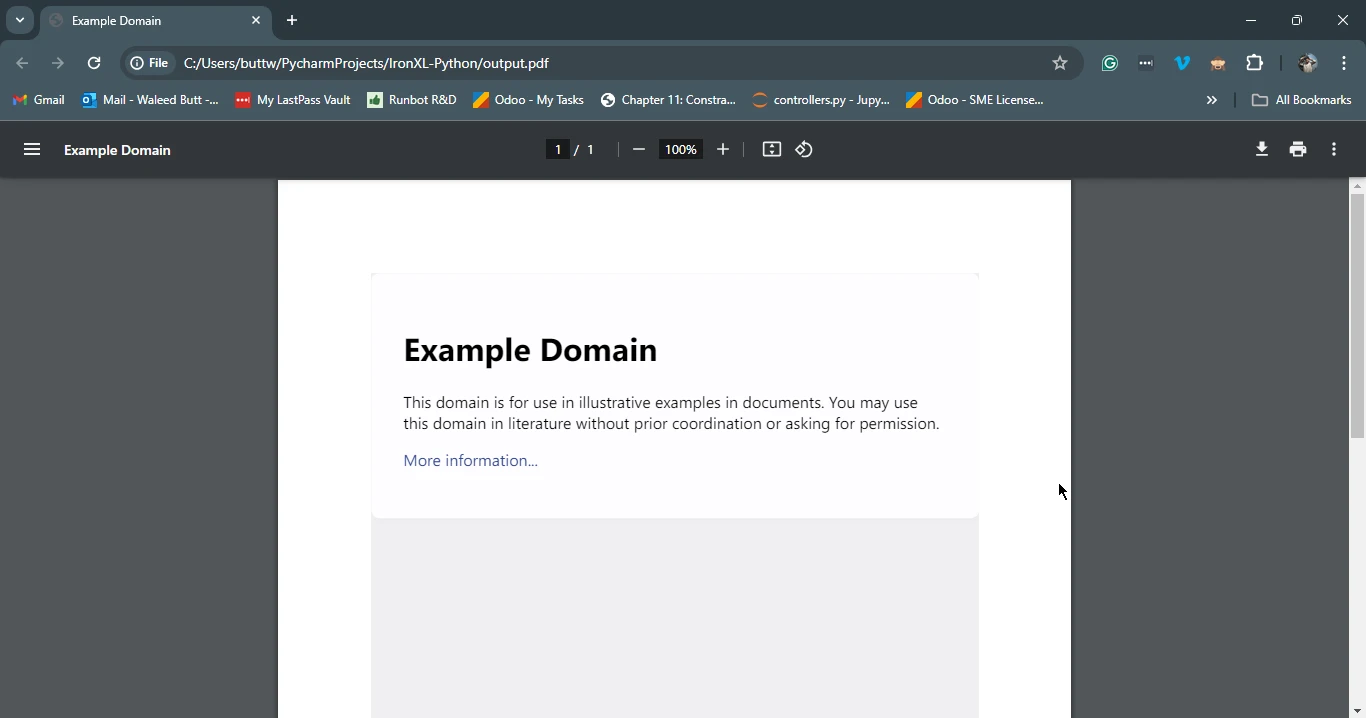
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')此脚本首先使用 Requests 获取指定URL的HTML内容。 然后,它使用IronPDF将这个响应对象的HTML内容转换为PDF,并将生成的PDF保存到文件中。
结论
Requests 库是任何需要与网络API交互的Python开发者不可或缺的工具。其简单性和易用性使其成为进行HTTP请求时的首选。 当与IronPDF结合使用时,它开启了更多可能性,使您能够从网上获取数据并将其转换为专业质量的PDF文件。 无论您是在创建报告、发票,还是归档网络内容,Requests 和 IronPDF 的组合为您的PDF生成需求提供了一个强大的解决方案。
有关IronPDF许可的更多信息,请参考IronPDF许可页面。 您还可以浏览我们关于HTML转PDF转换的详细教程以获取更多见解。
















