
如何在 Python 中从扫描的 PDF 中提取文本
从PDF文件中提取文本,特别是扫描的文件,可能具有挑战性。 然而,使用正确的工具和技术可以简化这个过程。 本教程将指导您使用IronPDF,一个Python库,从扫描的PDF文件中提取文本。本文将介绍如何设置您的环境,应用光学字符识别(OCR)并有效地执行文本提取。
1. IronPDF简介
 Python PDF库
Python PDF库
IronPDF是一个设计用于在Python环境中进行PDF操作和处理的多功能且强大的库。 IronPDF以其能够无缝集成Python应用程序而著称,提供了超越基本PDF读取和写入的广泛功能。 它因其能够将HTML转换为PDF、从网页或原始HTML代码呈现PDF文档以及编辑现有PDF文件的能力而脱颖而出。
此外,光学字符识别(OCR)功能对于从扫描的PDF文档中提取文本非常有用。 它是开发者处理各种PDF相关任务的首选工具。 无论是创建、修改,还是从PDF文件中提取数据,IronPDF都是一个强大而可靠的解决方案,满足Python开发者在各种应用中多样的需求。
2. 先决条件
在深入探索从PDF提取文本过程之前,必须具备一些前提条件和必要的库。 这将确保您在进行过程中拥有顺利而有效的工作流程。
- Python环境:确保您的计算机系统上已经安装了Python。 Python是一种多功能的编程语言,其广泛的库支持使其非常适合用于文本提取等任务。 如果您尚未安装Python,可以从Python官方网站下载。 确保下载与您的操作系统兼容的Python版本。
- .NET 6.0 SDK安装:由于IronPDF for Python利用了IronPDF .NET库,该库基于.NET 6.0,因此在系统上安装.NET 6.0 SDK至关重要。 此SDK提供了IronPDF库正常运行所需的运行时和库。 您可以从微软官方.NET网站下载并安装.NET 6.0 SDK。
- IronPDF for Python库: IronPDF是一个用于在Python中处理PDF文档的强大库。 它不仅便于提取文本,还提供了PDF创建、编辑和转换等功能。
- 扫描的PDF文档:准备好可供文本提取的扫描PDF文档。 该文档应清晰可辨,因为扫描PDF的质量会显著影响OCR和提取文本的准确性。
- 基本Python知识:了解Python编程的基础知识是有利的。 熟悉变量、循环、基本文件操作等概念将帮助您更有效地浏览代码并理解文本提取过程。
- 合适的开发环境:虽然不是必须的,但使用Visual Studio Code、PyCharm甚至Jupyter Notebook这样的开发环境可以使您的编码体验更易管理。 这些环境提供了如语法高亮、代码补全、调试工具等功能,对于处理Python脚本非常有帮助。
有了这些前提条件,您就为使用IronPDF for Python库从扫描的PDF文档中提取文本做好了充分的准备。 后续步骤将指导您安装IronPDF、加载PDF文档、应用OCR、提取文本及根据您的特定需求利用提取的数据。
3. 从扫描的PDF中提取文本的逐步指南
步骤1:安装IronPDF
首先,您必须在Python环境中安装IronPDF库。 这通常通过Python的包管理器pip来完成。打开命令行界面并运行以下命令:
pip install ironpdf
 安装 IronPDF 包
安装 IronPDF 包
步骤2:导入IronPDF
安装后,将IronPDF库导入到您的Python脚本中。 这一步对于访问IronPDF提供的功能至关重要:
import ironpdfimport ironpdf导入IronPDF后,您现在可以在脚本中使用其类和方法。
步骤3:应用您的许可证密钥
IronPDF需要许可证密钥才能实现全部功能。 如果您购买了许可证,按如下所示应用您的许可证密钥:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"将"YOUR-LICENSE-KEY-HERE"替换为您的实际IronPDF许可证密钥。 此步骤对于在无任何限制的情况下解锁IronPDF的所有功能至关重要。
步骤4:加载扫描的PDF文件
要提取文本,首先将PDF文档加载到您的脚本中:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")这里的"scannedpdf.pdf"应该替换为您打算处理的PDF文档的实际文件路径。 此命令读取PDF文件并为文本提取做好准备。
步骤5:从PDF文件中提取文本
加载PDF后,您现在可以使用IronPDF的ExtractAllText()方法提取文本,如下代码所示:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()这行代码处理整个PDF文档并提取其文本内容,将其存储在text变量中。
步骤6:处理和利用提取的文本
提取后,文本数据可在text变量中使用。 您可以将此文本打印到控制台或根据需要进一步处理:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted text此步骤可以包括将提取的文本保存到文件中、执行文本数据分析或将其整合到数据库或Web应用程序中。 在这里,您可以看到上述代码的输出。
输出文本
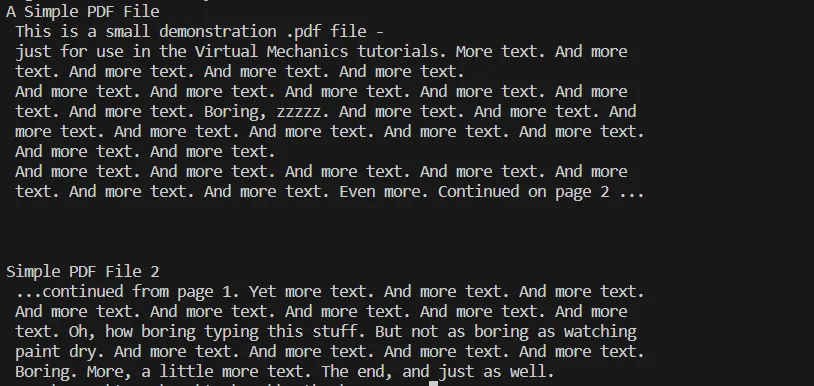 提取PDF文件文本过程的控制台输出
提取PDF文件文本过程的控制台输出
步骤7:额外操作(可选)
IronPDF的功能不仅限于文本提取。 根据您的项目要求,您可以探索其他功能,如编辑PDF、将PDF转换为不同格式,甚至从HTML生成PDF。
4. 高级技术
4.1 处理非文本元素
扫描的PDF通常包含非文本元素,如图像或图表。虽然OCR专注于文本,但您可能希望对这些元素进行不同的处理。 您可能需要额外的Python库来处理或忽略非文本内容。
4.2 提高OCR准确性
文本提取的准确性可能取决于扫描文件的质量。 为了提高OCR结果,请确保您的扫描PDF质量良好,文本尽可能清晰。
4.3 转换为其他格式
从PDF提取文本后,您可能想要将其转换为CSV、JSON或XML等其他格式以便进一步处理。 IronPDF允许进行此类转换,为您提供灵活的数据处理选项。
5. 常见问题排查
在使用OCR和文本提取时,您可能会遇到以下问题:
- 因扫描质量差导致的OCR准确性差。
- 如果OCR未能识别某些字符,则文本丢失。
- 加载大型PDF文件时出错。
要排查这些问题,请确保您的扫描PDF文件清晰且质量高,考虑将大文件分为较小的部分,并验证您的IronPDF库是最新的。
结论
使用IronPDF Python库可以无缝地完成从扫描的PDF文件提取文本。 按照本教程中概述的步骤,您可以将不可搜索的扫描文档转换为文本丰富的格式,能够快速处理和分析。 请记住,仔细处理每个PDF页面,并应用OCR使您的扫描PDF成为可搜索的PDF文件。通过提取的文本,数据操作和使用的可能性是无限的,为创新解决方案和简化工作流程铺平了道路。
总之,本文涵盖了IronPDF的安装和设置,加载PDF文件,应用OCR技术使扫描PDF可搜索,实际文本提取过程以及处理多个PDF页面。 还涉及高级技术以及常见问题排查。 有了这些知识,您可以使用Python从PDF文档中提取文本数据。
IronPDF提供免费试用以获得全功能访问权限,允许用户评估PDF操作和文本提取能力。 试用结束后,付费许可证从$799起,提供全面功能集,适合专业和商业用途。 IronPDF对开发是免费的,使开发人员在应用程序开发阶段可以无成本地整合和测试其功能。
常见问题解答
如何设置使用 Python 从扫描的 PDF 中提取文本的环境?
要设置您的环境,请安装 .NET 6.0 SDK 和 IronPDF 库,使用 Python 的包管理器运行 pip install ironpdf。确保您具备 Python 环境和一个合适的开发环境,如 Visual Studio Code 或 PyCharm。
什么是光学字符识别 (OCR),它如何在 Python 中应用?
光学字符识别 (OCR) 是一种技术,可用于将不同类型的文档(如扫描的纸质文档或 PDF)转换为可编辑和可搜索的数据。在 Python 中,您可以使用 IronPDF 加载扫描的 PDF 并使用库的 OCR 功能提取文本来应用 OCR。
如何确保从扫描的 PDF 中准确提取文本?
为确保准确提取文本,使用高质量的扫描 PDF,因为 OCR 的准确性会随着扫描的清晰度和质量的提高而改善。使用 IronPDF,您可以应用 OCR 提取文本并根据需要进一步处理。
使用 IronPDF 从扫描的 PDF 中提取文本涉及哪些步骤?
步骤包括安装 IronPDF、导入库、应用许可证密钥、加载您的扫描 PDF、应用 OCR 以及使用 ExtractAllText() 方法提取文本。
我可以将提取的文本转换为像 CSV、JSON 或 XML 这样的格式吗?
是的,一旦使用 IronPDF 从扫描的 PDF 中提取文本,您可以将其转换为各种格式,例如 CSV、JSON 或 XML,以供进一步分析或数据操作。
如果文本提取失败,一些常见的故障排查步骤是什么?
如果文本提取失败,请检查扫描 PDF 的质量。确保 IronPDF 已正确安装,并且您的开发环境已正确设置。此外,确认使用了正确的方法和 OCR 功能。
IronPDF 是否提供试用版本?
是的,IronPDF 为用户提供了免费试用版以测试其功能。试用期结束后需要付费许可证才能获得完全功能。
















