

How to Read PDF Files in Node.js
In the ever-evolving world of web development, Node.js has emerged as a powerful platform that allows developers to build scalable and efficient applications. One fascinating aspect of Node.js is its ability to work seamlessly with various libraries and modules, expanding its functionalities. In this article, we will delve into the realm of Node.js PDF reader capabilities, exploring the IronPDF library and how it can be leveraged for handling PDF files.
What is Node.js PDF Reader?
Node.js PDF Reader is a specialized tool designed to facilitate the reading and manipulation of PDF (Portable Document Format) files within the Node.js environment. PDF files are widely used for document sharing due to their consistent formatting across different platforms. Incorporating PDF reading capabilities into Node.js applications opens up a plethora of possibilities, from extracting information to generating dynamic reports.
How to Read PDF Using Node.js PDF Reader?
- Install the Node.js PDF Reader Library.
- Import the required dependencies.
- Open the PDF file using the
PdfDocument.openmethod. - Extract the text from the PDF file using the
extractTextmethod. - Display the extracted text on the console using the
console.logmethod.
2. Introduction to IronPDF for Node.js
IronPDF is a comprehensive library for working with PDF files in the Node.js ecosystem. It provides a range of functionalities, making it a go-to choice for developers who need to interact with PDF documents programmatically. Developed by the Iron Software team, IronPDF stands out for its simplicity and ease of integration into Node.js projects.
2.1. Key Features of IronPDF
- PDF Generation: IronPDF allows developers to create PDF documents from scratch, providing full control over the content, formatting, and layout.
- PDF Parsing: The library enables the extraction of text, images, and other elements from existing PDF files, empowering developers to work with the data stored within these documents.
- PDF Modification: IronPDF supports the modification of existing PDF files, making it possible to add, remove, or update content dynamically.
- PDF Rendering: With IronPDF, developers can render PDF files in various formats, including from images or from HTML, expanding the possibilities for displaying PDF content within web applications.
- Cross-Platform Compatibility: IronPDF is designed to work seamlessly across different operating systems, ensuring consistent behavior regardless of the deployment environment.
2.2. Installing IronPDF
Before diving into the functionalities of IronPDF, it's essential to install the library in your Node.js project. The installation process is straightforward and can be accomplished using the NPM package manager. Open your terminal and run the following command:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfThis command installs the IronPDF library and makes it available for use in your Node.js application.
To install the IronPDF engine that is a must for using the IronPDF Library, run the following command in the console:
npm install @ironsoftware/ironpdf-engine-windows-x64npm install @ironsoftware/ironpdf-engine-windows-x643. Reading PDF Files with Node.js and IronPDF
Reading PDF files with Node.js and IronPDF involves a series of straightforward steps, and the provided code example illustrates a concise yet powerful approach to achieve this. The code utilizes the PdfDocument class from the @ironsoftware/ironpdf package to open and extract text from a PDF file. Let's break down the code step by step:
Importing
PdfDocument:import { PdfDocument } from "@ironsoftware/ironpdf";import { PdfDocument } from "@ironsoftware/ironpdf";JAVASCRIPTThe code begins by importing the
PdfDocumentclass from the IronPDF library. This class provides methods for working with PDF documents, such as opening, extracting text, and performing various manipulations.Opening a PDF File:
const pdf = await PdfDocument.open("output.pdf");const pdf = await PdfDocument.open("output.pdf");JAVASCRIPTThe
PdfDocument.openmethod is used to open a PDF file. In this example, the file "output.pdf" is specified. Theawaitkeyword is used because theopenmethod returns a promise. This ensures that the code waits for the PDF to be fully loaded before proceeding to the next steps.Extracting Text from the PDF:
const text = await pdf.extractText();const text = await pdf.extractText();JAVASCRIPTOnce the PDF is opened, the
extractTextmethod is called on thepdfobject. This method asynchronously extracts the text content from the PDF document. The result is stored in thetextvariable.Logging the Extracted Text:
console.log(text);console.log(text);JAVASCRIPTFinally, the extracted text is logged to the console using
console.log. This step is crucial for developers to verify that the text extraction process is successful and to inspect the content extracted from the sample PDF.asyncFunction Wrapper:(async () => { // Code goes here })();(async () => { // Code goes here })();JAVASCRIPTThe entire code is wrapped in an asynchronous function using an immediately-invoked function expression (IIFE) with the
asynckeyword. This allows the use ofawaitinside the function, enabling asynchronous operations such as loading the PDF and extracting text.
In summary, this code showcases a concise yet effective method for reading PDF files using Node.js and IronPDF. By leveraging the capabilities of the IronPDF library, developers can easily open PDF documents, extract text content, and integrate these functionalities into their Node.js applications.
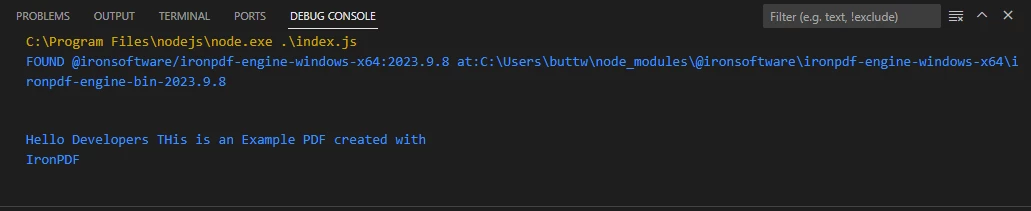 Extracted text from a sample PDF file
Extracted text from a sample PDF file
3.1. Reading Password-Protected PDF Files
Reading password-protected PDF files requires addressing the added layer of security that protects the document's content. In such cases, it is crucial to use PDF reading libraries, like IronPDF, that support password authentication.
The process involves providing the correct password during the file opening phase, enabling the decryption of the content within the PDF. This ensures that only authorized users can access and extract information from password-protected PDF files, enhancing the security of sensitive data contained in these documents.
const pdf = await PdfDocument.open("encrypted.pdf", "password");const pdf = await PdfDocument.open("encrypted.pdf", "password");Using the above code, users can read password-protected PDF file content.
3.2. Reading PDF File Metadata
IronPDF for Node.js offers the ability to read PDF file metadata. The code below will demonstrate how to read metadata from a PDF file.
import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();Output
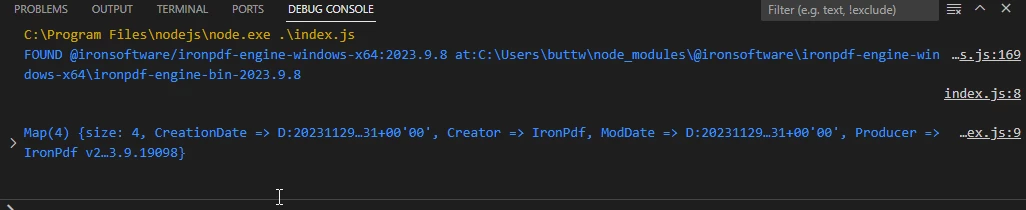 Extracted metadata from a sample PDF file
Extracted metadata from a sample PDF file
4. Conclusion
In conclusion, Node.js PDF Reader, particularly when utilizing the IronPDF library, opens up a world of possibilities for developers working with PDF files. Whether it's extracting text, images, or dynamically modifying existing documents, IronPDF provides a versatile set of tools for handling PDFs in a Node.js environment. It also supports tabular data and the PDF reader module extracts text entries.
To get started with Node.js PDF Reader and IronPDF, follow the steps outlined in this article. Explore the documentation for more in-depth information and advanced use cases. With the right tools and knowledge, you can enhance your Node.js applications by seamlessly integrating PDF reading capabilities.
Why use IronPDF for Node.js?
- Free Trial: IronPDF for Node.js offers a free trial of IronPDF for Node.js, allowing developers to explore its capabilities before committing. This trial period enables users to evaluate the library's suitability for their specific PDF-related tasks without financial commitment.
- Feature-Rich: IronPDF for Node.js is feature-rich, providing a comprehensive set of functionalities for working with PDF files in Node.js. From PDF generation to text extraction and document modification, the library offers a robust toolkit, making it versatile for a wide range of applications.
- Code Examples and Documentation/Support: IronPDF provides extensive documentation and support, making it easy for developers to integrate and utilize its features. The library comes with detailed Node.js PDF conversion examples, facilitating a smooth learning curve and ensuring that developers have the resources they need for successful implementation.
Frequently Asked Questions
How can I read a PDF file in Node.js?
To read a PDF file in Node.js, you can use IronPDF by installing it through npm. Import the necessary dependencies and utilize the PdfDocument.open method to load the PDF. Extract text content using the extractText method and output the results to the console.
What are the benefits of using a PDF library in Node.js?
Using a PDF library like IronPDF in Node.js offers benefits such as PDF generation, parsing, and modification. It enhances Node.js applications by providing robust PDF handling capabilities, including cross-platform compatibility and seamless integration.
How do I install IronPDF in a Node.js project?
To install IronPDF in a Node.js project, use the npm command: npm install @ironsoftware/ironpdf. Additionally, install the IronPDF engine with npm install @ironsoftware/ironpdf-engine-windows-x64 to ensure full functionality.
Can I read password-protected PDFs in Node.js?
Yes, IronPDF allows you to read password-protected PDFs in Node.js. Provide the correct password during the PDF opening process to decrypt and access the content.
How can I extract metadata from a PDF using Node.js?
Using IronPDF in Node.js, you can extract metadata from a PDF by opening the document with PdfDocument.open and using the getMetadata method to retrieve metadata details.
What makes IronPDF a popular choice for Node.js PDF manipulation?
IronPDF is popular among Node.js developers due to its feature-rich capabilities, extensive documentation, and support. It provides a free trial, making it accessible for testing and integration into various applications.
How does IronPDF ensure cross-platform compatibility in Node.js projects?
IronPDF is designed to maintain consistent performance across different operating systems, ensuring that your Node.js projects function reliably regardless of the deployment platform.
Where can I find more resources on using IronPDF in Node.js?
For more resources and examples of using IronPDF in Node.js, visit the official Iron Software website. Explore their documentation and tutorials for comprehensive guidance on PDF manipulation.















