
How to Extract Table Data from a PDF File in C#
In many industries, PDF files are the go-to format for sharing structured documents like reports, invoices, and data tables. However, extracting data from PDFs, especially when it comes to tables, can be challenging due to the nature of the PDF format. Unlike structured data formats, PDFs are designed primarily for presentation, not data extraction.
However, with IronPDF, a powerful C# PDF .NET library, you can easily extract structured data like tables directly from PDFs and process them in your .NET applications. This article will guide you step-by-step on how to extract tabular data from PDF files using IronPDF.
When Would You Need to Extract Tables from PDF Documents?
Tables are a handy way of structuring and displaying your data, whether carrying out inventory management, data entry, recording data such as rainfall, etc. Thus, there may also be many reasons for needing to extract tables and table data from PDF documents. Some of the most common use cases include:
- Automating data entry: Extracting data from tables in PDF reports or invoices can automate processes like populating databases or spreadsheets.
- Data analysis: Businesses often receive structured reports in PDF format. Extracting tables allows you to analyze this data programmatically.
- Document conversion: Extracting tabular data into more accessible formats like Excel or CSV enables easier manipulation, storage, and sharing.
- Auditing and compliance: For legal or financial records, extracting tabular data from PDF documents programmatically can help automate audits and ensure compliance.
How Do PDF Tables Work?
The PDF file format does not offer any native ability to store data in structured formats like tables. The table we use in today's example was created in HTML, before being converted to PDF format. Tables are rendered as text and lines, so extracting table data often requires some parsing and interpreting of content unless you are using OCR software, such as IronOCR.
How to Extract Table Data from a PDF File in C#
Before we explore how IronPDF can tackle this task, let's first explore an online tool capable of handling PDF extraction. To extract a table from a PDF document using an online PDF tool, follow the steps outlined below:
- Navigate to the free online PDF extraction tool
- Upload the PDF containing the table
- View and download the results
Step One: Navigate to the Free Online PDF Extraction Tool
Today, we will be using Docsumo as our online PDF tool example. Docsumo is an online PDF document AI that offers a free PDF table extraction tool.
Step Two: Upload the PDF Containing the Table
Now, click the "Upload File" button to upload your PDF file for extraction. The tool will immediately begin to process your PDF.
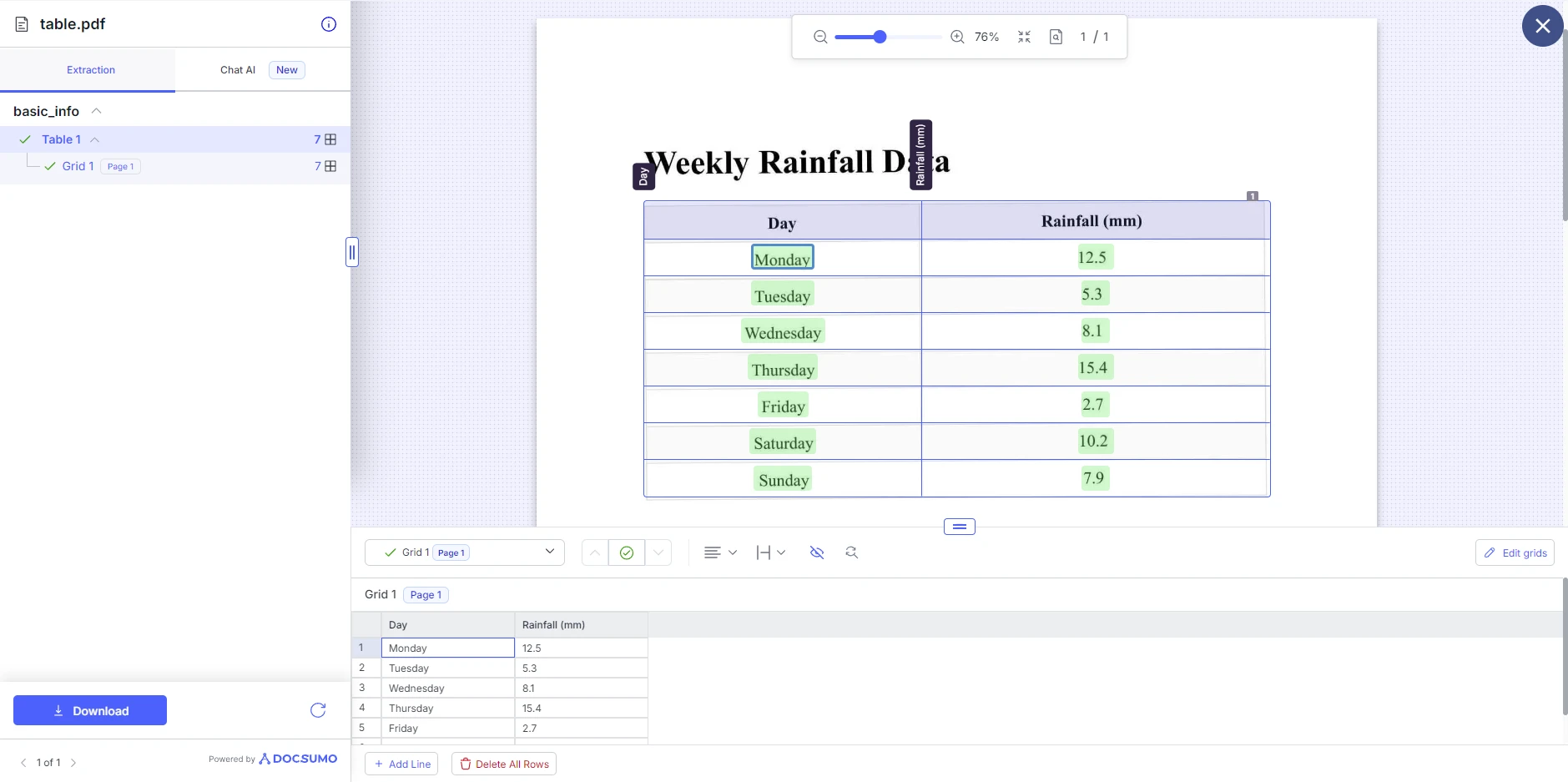
Step Three: View and Download the Results
Once Docsumo has finished processing the PDF, it will display the extracted table. You can then make adjustments to the table structure such as adding and removing rows. Here, you can download the table as either another PDF, XLS, JSON, or Text.
Extract Table Data Using IronPDF
IronPDF allows you to extract data, text, and graphics from PDFs, which can then be used to reconstruct tables programmatically. To do this, you will first need to extract the textual content from the table in the PDF and then use that text to parse the table into rows and columns. Before we start extracting tables, let's take a look at how IronPDF's ExtractAllText() method works by extracting the data within a table:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class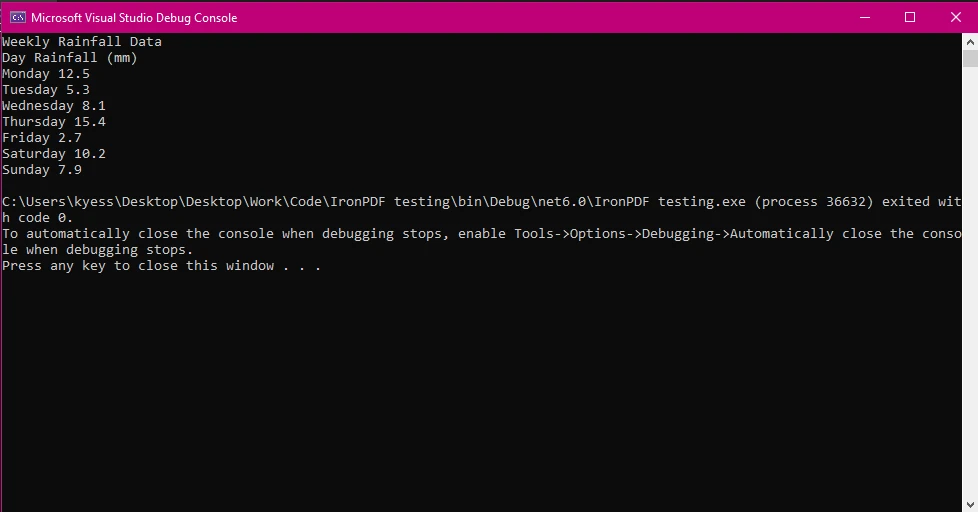
In this example, we have loaded the PDF document using the PdfDocument class, and then used the ExtractAllText() method to extract all the text within the document, before finally displaying the text on the console.
Extracting Table Data from Text Using IronPDF
After extracting text from the PDF, the table will appear as a series of rows and columns in plain text. You can split this text based on line breaks (\n) and then further split rows into columns based on consistent spacing or delimiters such as commas or tabs. Here is a basic example of how to parse the table from the text:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class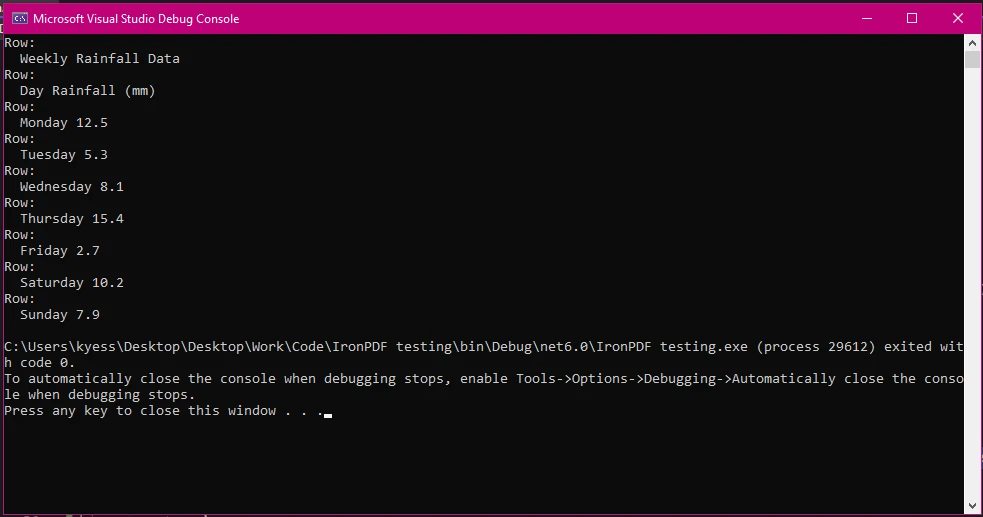
In this example, we followed the same steps as before for loading our PDF document and extracting the text. Then, using text.Split('\n') we split the extracted text into rows based on line breaks and store the results in the lines array. A foreach loop is then used to loop through the rows in the array, where line.Split('\t') is used to further split the rows into columns using the tab character '\t' as the delimiter. The next part of the columns array, Where(col => !string.IsNullOrWhiteSpace(col)).ToArray() filters out empty columns that may arise due to extra spaces, and then adds the columns to the column array.
Finally, we write text to the console output window with basic row and column structuring.
Exporting Extracted Table Data to CSV
Now that we've covered how to extract tables from PDF files, let's take a look at what we can do with that extracted data. Exporting the exported table as a CSV file is one useful way of handling table data and automating tasks such as data entry. For this example, we have filled a table with simulated data, in this case, the daily rainfall amount in a week, extracted the table from the PDF, and then exported it to a CSV file.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
End ClassSample PDF File
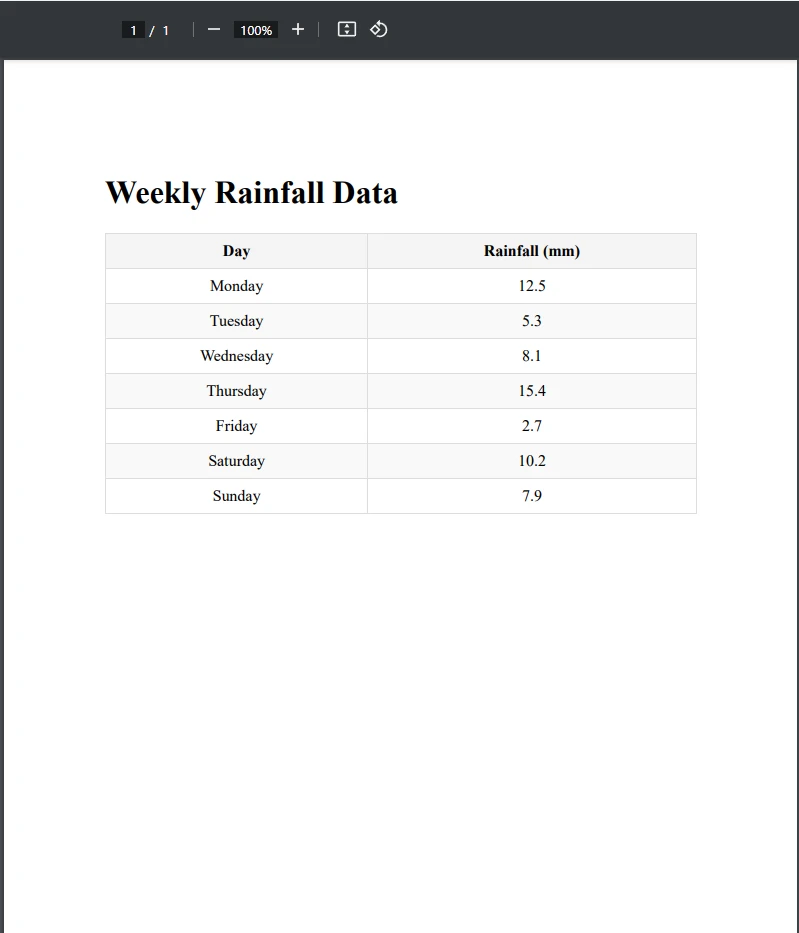
Output CSV File
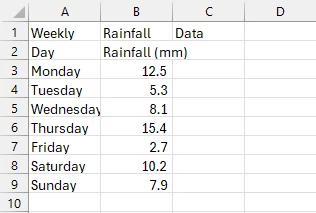
As you can see, we have successfully exported the PDF table to CSV. First, we loaded the PDF containing the table and created a new CSV file path. After this, we extracted the table using the var tableData = ExtractTableDataFromPdf(pdfPath) line, which is called the ExtractTableDataFromPdf() method. This method extracts all of the text on the PDF page that the table resides on, storing it in the text variable.
Then, we split the text into lines and columns. Finally, after returning the result from this splitting process, we call the method static void WriteDataToCsv() which takes the extracted, split-up text and writes it to our CSV file using StreamWriter.
Tips and Best Practices
When working with PDF tables, following some basic best practices can help to ensure you minimize the chance of running into any errors or issues.
- Pre-process PDFs: If possible, pre-process your PDFs to ensure consistent formatting, which simplifies the extraction process.
- Validate data: Always validate the extracted data to ensure accuracy and completeness.
- Handle errors: Implement error handling to manage cases where text extraction or parsing fails, such as wrapping your code within a try-catch block.
- Optimize performance: For large PDFs, consider optimizing text extraction and parsing to handle performance issues.
IronPDF Licensing
IronPDF offers different licensing options, allowing you to try out all the powerful features IronPDF has to offer for yourself before committing to a license.
Conclusion
Extracting tables from PDFs using IronPDF is a powerful way to automate data extraction, facilitate analysis, and convert documents into more accessible formats. Whether dealing with simple tables or complex, irregular formats, IronPDF provides the tools needed to extract and process table data efficiently.
With IronPDF, you can streamline workflows such as automated data entry, document conversion, and data analysis. The flexibility and advanced features offered by IronPDF make it a valuable tool for handling various PDF-based tasks.
Frequently Asked Questions
How can I extract tables from a PDF using C#?
You can use IronPDF to extract tables from a PDF in C#. Load the PDF document using IronPDF, extract the text, and then parse the text into rows and columns programmatically.
Why is it difficult to extract table data from PDF documents?
PDFs are primarily designed for presentation rather than data structure, which makes extracting structured data like tables challenging. Tools like IronPDF help interpret and extract this data effectively.
What are the benefits of extracting tables from PDFs?
Extracting tables from PDFs facilitates automating data entry, performing data analysis, converting documents to more accessible formats, and ensuring compliance in auditing processes.
How do you handle complex table formats in PDF extraction?
IronPDF offers capabilities to extract and process table data even from complex and irregular table formats, ensuring accurate data extraction.
What is the process to convert extracted PDF table data to CSV?
After extracting and parsing table data from a PDF using IronPDF, you can export this data to a CSV file by writing the parsed data using a StreamWriter.
What are some best practices for PDF table extraction?
Pre-process PDFs for consistent formatting, validate extracted data, implement error handling, and optimize performance when dealing with large PDF files.
Can IronPDF help with auditing and compliance tasks?
Yes, IronPDF can extract tabular data from PDFs and convert it to formats like Excel or CSV, aiding in auditing and compliance by making data more accessible for review and analysis.
What licensing options does IronPDF offer?
IronPDF provides various licensing options, including trial versions, so you can explore its features before purchasing a full license.
What common troubleshooting scenarios might arise when extracting tables from PDFs?
Common issues include inconsistent table formatting and text extraction errors. Using IronPDF’s robust features can help mitigate these challenges by providing accurate parsing capabilities.
Is IronPDF fully compatible with .NET 10 and how does it benefit table extraction workflows?
Yes—IronPDF supports .NET 10 (as well as .NET 9, 8, 7, 6, Core, Standard, and Framework), meaning you can use it in latest .NET 10 projects without configuration issues. Developers building on .NET 10 benefit from runtime performance improvements like reduced allocations and enhanced JIT compiler optimizations, which help speed up PDF processing and table extraction operations.














