A Comparison between IronPDF for Java and Apache PDFBox
This article will cover the following two of the most popular libraries used in Java to work with PDF files:
- IronPDF
- Apache PDFBox
Now which library should we use? In this article, I'll compare both libraries' core functionality to allow you to make a decision about which one is best for your production environment.
How to Convert HTML to PDF in Apache PDFBOX
- Install Java library to convert HTML to PDF
- Create new document and page instance with Apache PDFBox
- Create a new
PDPageContentStreamwith the document and page as input - Use the
PDPageContentStreaminstance to configure and add content - Export the PDF document with
savemethod
IronPDF
The IronPDF library supports HTML to PDF Conversion for Java 8+, Kotlin, and Scala. This creator provides cross-platform support, i.e., Windows, Linux, or Cloud platforms. It is designed especially for Java, prioritizing accuracy, ease of use, and speed.
IronPDF is developed to help software developers create, edit, and extract content from PDF documents. It is based on the success and popularity of IronPDF for .NET.
Standout features of IronPDF include:
Use HTML Assets
- HTML (5 and below), CSS (Screen & Print), images (JPG, PNG, GIF, TIFF, SVG, BMP), JavaScript (+ Render Delays)
- Fonts (Web & Icon)
HTML to PDF
- HTML file/string to PDF document creation and manipulation
- URL to PDF
Convert Images
- Image to new PDF documents
- PDF to Image
Custom Paper Settings
- Custom Paper Size, Orientation & Rotation
- Margins (mm, inch & zero)
- Color & Grayscale, Resolution & JPEG Quality
Additional Features
- Website & System Logins
- Custom User Agents and Proxies
- HTTP Headers
Apache PDFBox library
Apache PDFBox is an open-source Java library for working with PDF files. It allows one to generate, edit, and manipulate existing documents. It can also extract content from files. The library provides several utilities that are used to perform various operations on documents.
Here are the standout features of Apache PDFBox.
Extract Text
- Extract Unicode text from files.
Split & Merge
- Split a single PDF into many files
- Merge multiple documents.
Fill Forms
- Extract data from forms
- Fill a PDF form.
Preflight
- Validate files against the PDF/A-1b standard.
- Print a PDF using the standard printing API.
Save as Image
- Save PDFs as PNG, JPEG, or other image types.
Create PDFs
- Develop a PDF from scratch with embedded fonts and images.
Signing
- Digitally sign files.
Overview
The rest of the article goes as follows:
- IronPDF Installation
- Apache PDFBox Installation
- Create PDF Document
- Images to Document
- Encrypting Documents
- Licensing
- Conclusion
Now, we will download and install the libraries to compare them and their powerful features.
1. IronPDF Installation
Installing IronPDF for Java is simple. There are different ways of doing it. This section will demonstrate two of the most popular ways.
1.1. Download JAR and add the Library
To download the IronPDF JAR file, visit the Maven website for IronPDF and download the latest version of IronPDF.
- Click the Downloads option and download the JAR.
Download IronPDF JAR
Once the JAR is downloaded, it's now time to install the library into our Maven project. You can use any IDE, but we will be using NetBeans. In the Projects section:
- Right-Click the Libraries folder and select the Add JAR/Folder option.
Add IronPDF Library in Netbeans
- Move to the folder where you downloaded the JAR.
- Select the IronPDF JAR and click the Open button.
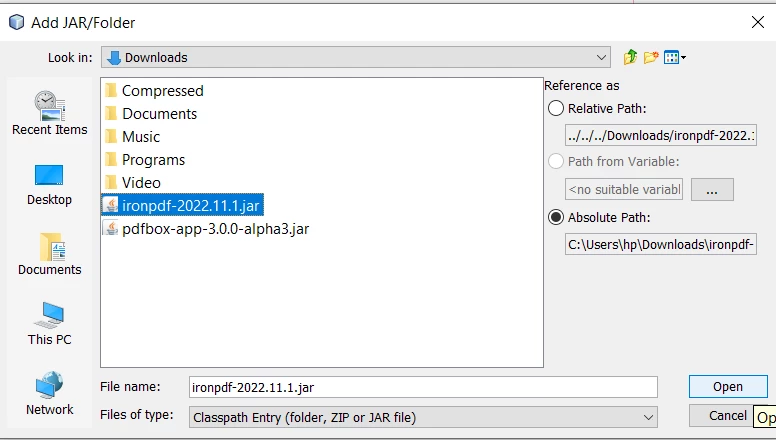
Open IronPDF JAR
1.2. Install via Maven as a Dependency
Another way of downloading and installing IronPDF is using Maven. You can simply add the dependency in the pom.xml or use NetBeans's Dependency tool to include it in your project.
Add the Library Dependency in pom.xml
Add the following dependency in your pom.xml:
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies>Add The Library using the Dependencies Feature
- Right-Click on dependencies
- Select Add Dependency and fill in the following details with the updated version
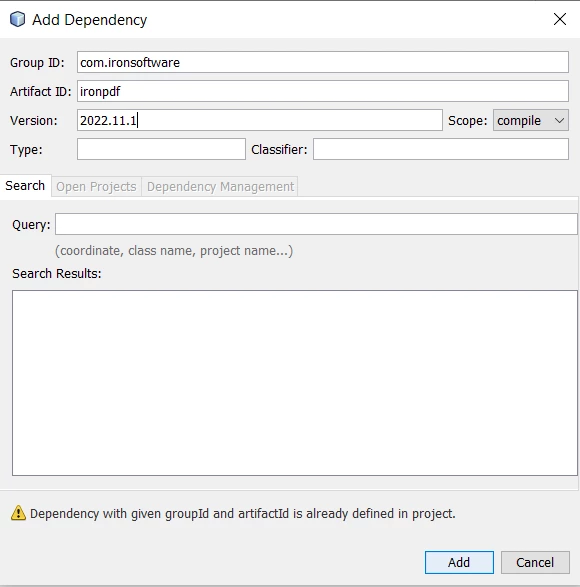
Add IronPDF Dependency
Now let's install Apache PDFBox.
2. Apache PDFBox Installation
We can download and install PDFBox using the same methods as IronPDF.
2.1. Download JAR and Add the Library Manually
To install PDFBox JAR, visit the official website and download the PDFBox library the latest version.
After creating a project, in the project section:
- Right-Click the Libraries folder and select Add JAR/Folder option.
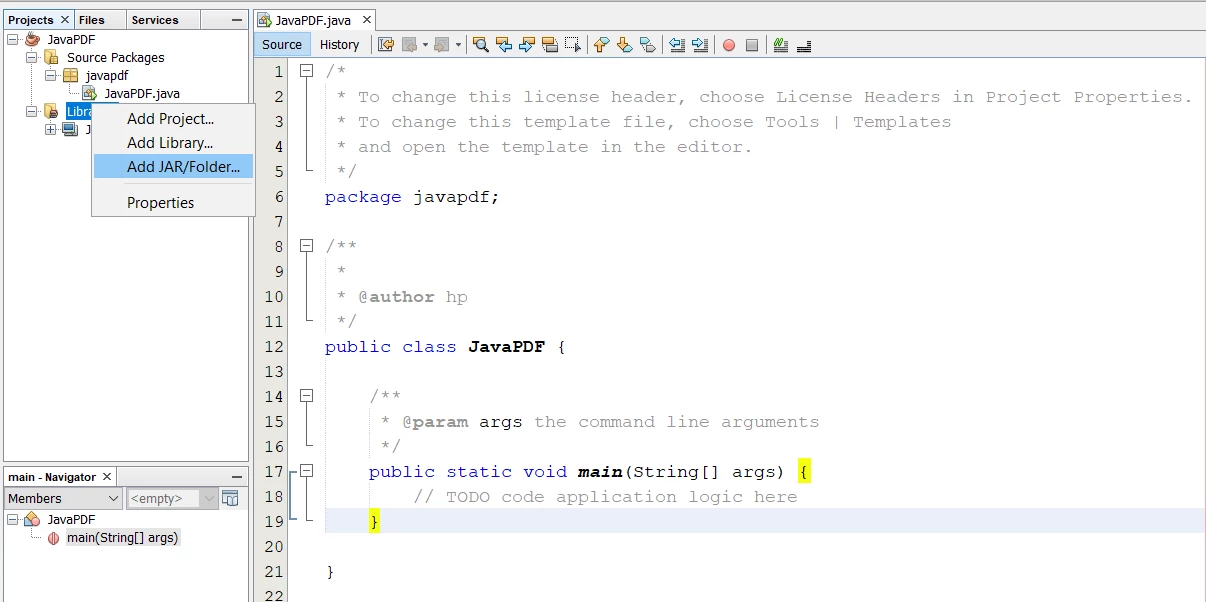
Add Library
- Move to the folder where you downloaded the JAR.
- Select the PDFBox JAR and click the Open button.
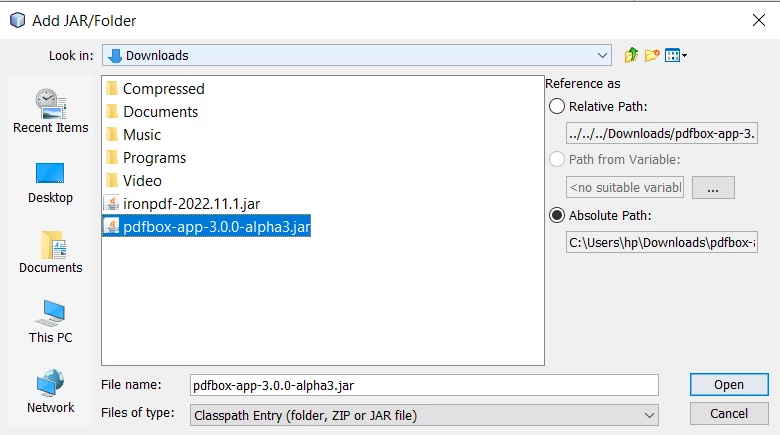
Open PDFBox JAR
2.2. Install via Maven as a Dependency
Add Dependency in the pom.xml
Copy the following code and paste it in the pom.xml.
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies>This will automatically download the PDFBox dependency and install it in the repository folder. It will now be ready to use.
Add Dependency using the Dependencies Feature
- Right-Click on dependencies in the project section
- Select Add Dependency and fill in the following details with the updated version
Add PDFBox Dependency
3. Create PDF Document
3.1. Using IronPDF
IronPDF provides different methods for creating files. Let's have a look at two of the most important methods.
Existing URL to PDF
IronPDF makes it very simple to generate documents from HTML. The following code sample converts a web page's URL to a PDF.
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("url.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("url.pdf"));The output is the below URL that is well formatted and saved as follows:
IronPDF URL Output
HTML Input String to PDF
The following sample code shows how an HTML string can be used to render a PDF in Java. You simply use an HTML string or document to convert it to new documents.
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));The output is as follows:

IronPDF HTML Output
3.2. Using Apache PDFBox
PDFBox can also generate new PDF documents from different formats, but it cannot convert directly from URL or HTML string.
The following code sample creates a document with some text:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}
PDFBox Positioned Output
However, if we remove contentStream.newLineAtOffset(25, 700); from the above code example and then run the project, it produces a PDF with output at the bottom of the page. This can be pretty annoying for some developers, as they have to adjust the text using (x,y) coordinates. y = 0 means that the text will appear at the bottom.

PDFBox without Positioning Output
4. Images to Document
4.1. Using IronPDF
IronPDF can easily convert multiple images to a single PDF. The code for adding multiple images to a single document goes as follows:
import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));
IronPDF Images to Output
4.2. Using Apache PDFBox
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}
PDFBox Images to Output
5. Encrypting Documents
5.1. Using IronPDF
The code for encrypting PDFs with a password in IronPDF is given below:
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));5.2. Using Apache PDFBox
Apache PDFBox also provides document encryption to make the files more secure. You can also add additional information like metadata. The code goes as follows:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}6. Pricing and Licensing
IronPDF Pricing and Licensing
IronPDF is free to use for developing simple PDF applications and can be licensed for commercial use at any time. IronPDF offers single project licenses, single developer licenses, licenses for agencies and multinational organizations, and SaaS and OEM redistribution licenses and support. All licenses are available with a free trial, a 30-day money-back guarantee, and one year of software support and upgrades.
The Lite package is available for $999. There are absolutely no recurring fees with IronPDF products. More detailed information about software licensing is available on the product IronPDF licensing page.
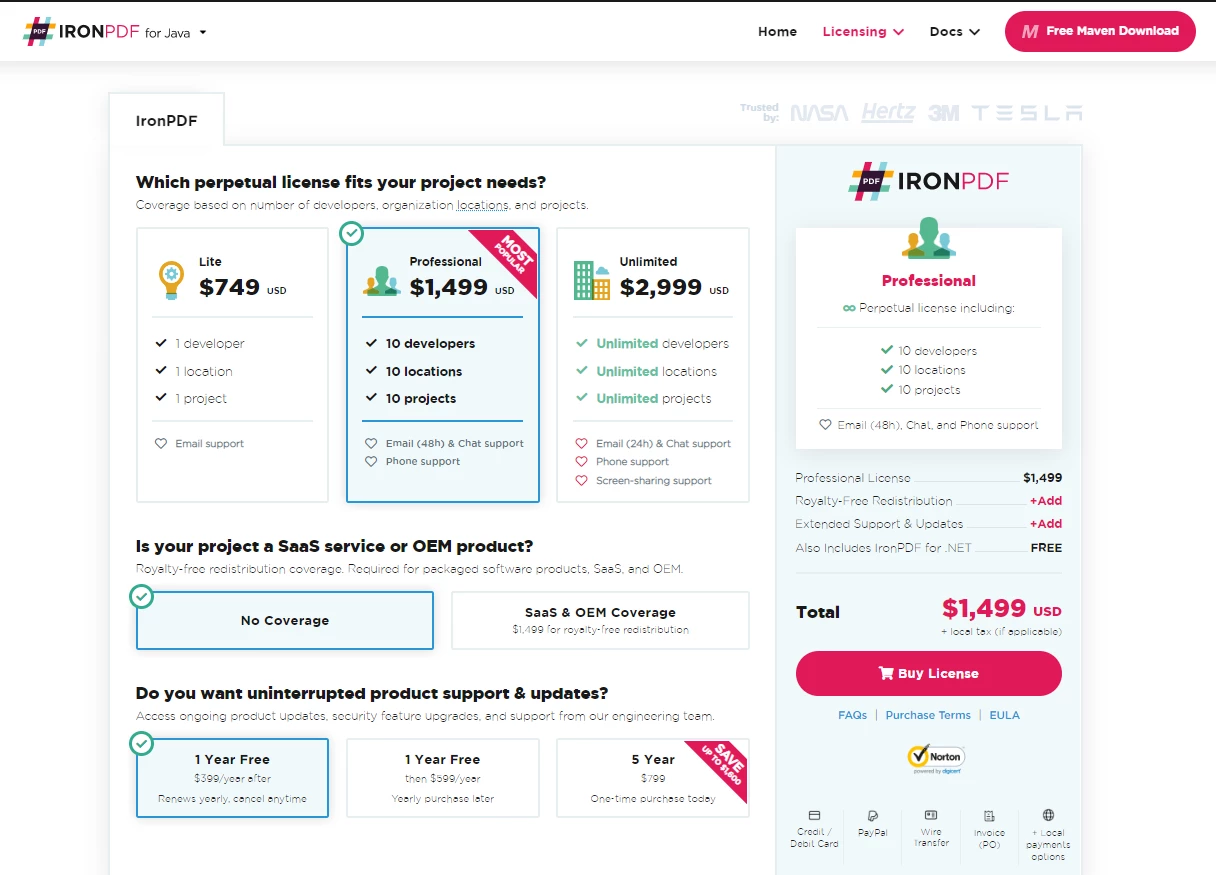
IronPDF Licensing
Apache PDFBox Pricing and Licensing
Apache PDFBox is freely available without any charges. It is free regardless of how it is used, whether for personal, for internal, or for commercial purposes.
You can include the Apache License 2.0 (current version) from the Apache License 2.0 Text. To include the copy of the license, simply include it in your work. You can also attach the following notice as a comment at the top of your source code.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.Conclusion
In comparison, IronPDF has an upper hand over Apache PDFBox in both functionality and product support. It also provides SaaS and OEM support, which is a requirement in modern software development. However, the library is not free for commercial use like Apache PDFBox is.
Companies with large software applications may require continual bug fixes and support from third-party vendors to resolve problems as they arise during software development. This is something that is lacking in many open-source solutions like Apache PDFBox, which relies on voluntary support from its community of developers to keep it maintained. In short, IronPDF is best used for business and market use, while Apache PDFBox is better suited for personal and non-commercial applications.
There is also a free trial to test the functionality of IronPDF. Give it a try or buy IronPDF.
You can now get all Iron Software products in the Iron Suite at a greatly reduced price. Visit this Iron Suite web page for more information about this amazing deal.
Frequently Asked Questions
How can I convert HTML to PDF in Java?
You can use IronPDF's Java library to convert HTML to PDF. The library offers methods for converting HTML strings, files, or URLs into PDFs easily.
What are the advantages of using IronPDF for Java?
IronPDF for Java provides features like HTML to PDF conversion, image conversion, custom paper settings, and support for website logins and custom HTTP headers. It is designed for ease of use and offers commercial support.
Can IronPDF convert an image to PDF?
Yes, IronPDF can convert images to PDF. This feature allows you to generate PDF documents from various image formats with minimal effort.
How does Apache PDFBox differ in functionality from IronPDF?
While Apache PDFBox is good for text extraction, form handling, and digital signing, it lacks direct HTML to PDF conversion. IronPDF, however, offers direct HTML and URL to PDF conversion along with advanced PDF handling features.
Is IronPDF suitable for enterprise use?
Yes, IronPDF is well-suited for enterprise use due to its commercial support, robust features, and licensing options, making it ideal for business applications.
What are some common issues when converting HTML to PDF?
Common issues include incorrect rendering of complex HTML/CSS, missing images, and incorrect page layouts. IronPDF addresses these with features like custom paper settings and image support.
How can I integrate IronPDF into my Java project?
You can integrate IronPDF into your Java project by downloading the JAR file from Maven or adding it as a dependency in your project's pom.xml file.
What is Apache PDFBox used for?
Apache PDFBox is used for creating, editing, and manipulating PDF documents. It supports text extraction, document splitting and merging, form filling, and digital signing.
Are there licensing costs associated with IronPDF?
IronPDF offers a free trial and is free for basic development, but requires a license for commercial use. Various licensing options are available to suit different needs.
Why might someone choose Apache PDFBox over IronPDF?
Someone might choose Apache PDFBox over IronPDF if they need a free, open-source solution for personal or non-commercial use and do not require HTML to PDF conversion.