
Porównanie dzielenia PDF w C# pomiędzy iTextSharp a IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Pliki PDF (Portable Document Format) są powszechnie używane do udostępniania i prezentowania dokumentów, a czasami może zaistnieć potrzeba podzielenia pliku PDF na wiele plików. Niezależnie od tego, czy chcesz wyodrębnić konkretne strony, podzielić duży dokument na mniejsze sekcje, czy też utworzyć osobne pliki dla każdego rozdziału, dzielenie plików PDF może być przydatne w różnych sytuacjach.
W tym artykule dowiemy się, jak dzielić pliki PDF za pomocą języka C#. C# to wszechstronny i potężny język, a dostępnych jest kilka bibliotek, które sprawiają, że manipulowanie plikami PDF jest stosunkowo proste. Przyjrzymy się dwóm poniższym bibliotekom służącym do dzielenia plików PDF w języku C#.
Jak podzielić plik PDF w języku C# przy użyciu iTextSharp
- Najpierw zainstaluj bibliotekę iText7.
- Utwórz obiekt PdfReader na podstawie pliku PDF.
- Użyj obiektu PdfDocument do pracy z zawartością pliku PDF.
- Oblicz liczbę stron dla każdego podzielonego pliku.
- Ustaw początkowe wartości zakresu stron.
- Użyj pętli, aby przetworzyć każdy podzielony plik.
- Utwórz nowy obiekt PdfDocument dla bieżącego pliku podzielonego.
- Skopiuj strony z oryginalnego dokumentu do nowego.
- Zaktualizuj wartości zakresu stron dla następnej iteracji.
- Zapisz gotowy plik PDF.
- Powtarzaj tę czynność, aż wszystkie pliki zostaną utworzone.
- Kontynuuj proces dla określonej liczby podzielonych plików.
IronPDF
IronPDF to potężna biblioteka C# przeznaczona do pracy z plikami PDF. Oferuje funkcje tworzenia, modyfikowania i wyodrębniania treści z dokumentów PDF. Programiści mogą tworzyć pliki PDF od podstaw, edytować istniejące pliki PDF oraz je łączyć lub dzielić. Ponadto IronPDF doskonale radzi sobie z konwersją treści HTML do formatu PDF, co sprawia, że jest przydatny do generowania raportów lub dokumentacji. Dzięki obsłudze podpisów cyfrowych, funkcji bezpieczeństwa i wysokiej jakości wyników, IronPDF upraszcza zadania związane z plikami PDF w aplikacjach .NET.
iTextSharp
iTextSharp (iText 7) to szeroko stosowana biblioteka do pracy z plikami PDF w .NET Framework. Zapewnia zaawansowane funkcje do programowego tworzenia, modyfikowania i wyodrębniania treści z dokumentów PDF. Programiści mogą używać iTextSharp do dodawania tekstu, obrazów, tabel i innych elementów graficznych do plików PDF. Ponadto obsługuje tworzenie dokumentów, podpisy cyfrowe oraz zgodność ze standardami archiwizacji i dostępności. Pierwotnie biblioteka Java, iTextSharp została przeniesiona na platformę .NET i posiada aktywną społeczność programistów oraz użytkowników.
Instalacja biblioteki IronPDF
Aby zainstalować pakiet IronPDF NuGet za pomocą konsoli menedżera pakietów w Visual Studio, wykonaj następujące czynności:
- W programie Visual Studio przejdź do menu Narzędzia -> Menedżer pakietów NuGet -> Konsola menedżera pakietów.
-
Użyj następującego polecenia, aby zainstalować pakiet IronPDF NuGet:
Install-Package IronPdf
Spowoduje to pobranie i zainstalowanie pakietu IronPDF wraz z jego zależnościami w projekcie. Po zakończeniu instalacji możesz zacząć używać IronPDF w swoim projekcie C# do zadań związanych z plikami PDF.
Alternatywnie można zainstalować IronPDF za pomocą menedżera pakietów NuGet w Visual Studio lub dodać pakiet bezpośrednio do pliku projektu. Inną opcją jest pobranie pakietu z oficjalnej strony internetowej i ręczne dodanie go do projektu. Każda z tych metod zapewnia prosty sposób na zintegrowanie IronPDF z projektem C# w celu uzyskania funkcjonalności związanych z plikami PDF.
Instalacja biblioteki iTextSharp
Aby zainstalować iTextSharp za pomocą konsoli menedżera pakietów w Visual Studio, wykonaj następujące czynności:
- W programie Visual Studio przejdź do menu Narzędzia -> Menedżer pakietów NuGet -> Konsola menedżera pakietów.
-
Użyj następującego polecenia, aby zainstalować pakiet NuGet iTextSharp:
Install-Package itext7Install-Package itext7SHELL
Spowoduje to pobranie i zainstalowanie pakietu iTextSharp wraz z jego zależnościami w projekcie. Po zakończeniu instalacji możesz zacząć używać iTextSharp w swoim projekcie C# do pracy z plikami PDF.
Dzielenie dokumentów PDF w języku C# przy użyciu IronPDF
Za pomocą IronPDF możemy podzielić plik PDF na wiele plików PDF. Zapewnia to prosty sposób na osiągnięcie tego celu. Poniższy kod pobierze źródłowy plik PDF jako dane wejściowe i podzieli go na wiele plików PDF.
using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsingIronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsingIronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}Imports IronPdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim file As String = "input.pdf"
' The folder to save the split PDFs
Dim outputFolder As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles)
End Sub
Private Shared Sub SplitPdfUsingIronPDF(ByVal inputPdfPath As String, ByVal outputFolder As String, ByVal numberOfSplitFiles As Integer)
' Load the input PDF
Dim sourceFile As PdfDocument = PdfDocument.FromFile(inputPdfPath)
' Initialize page range values
Dim firstPage As Integer = 1
Dim lastPage As Integer = 2
'INSTANT VB WARNING: Instant VB cannot determine whether both operands of this division are integer types - if they are then you should use the VB integer division operator:
Dim totalPageInOneFile As Integer = sourceFile.PageCount / numberOfSplitFiles
For i As Integer = 1 To numberOfSplitFiles
' Copy multiple pages into a new document
Dim newSplitPDF As PdfDocument = sourceFile.CopyPages(firstPage, lastPage)
' Generate the output file path
Dim name As String = $"{outputFolder}\SplitPDF_IronPDF_{i}.pdf"
' Save the new split PDF
newSplitPDF.SaveAs(name)
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next i
End Sub
End ClassWyjaśnienie kodu
Celem tego kodu jest podzielenie danego pliku PDF na wiele mniejszych plików PDF przy użyciu biblioteki IronPDF. Aby osiągnąć tę funkcjonalność, zdefiniowano metodę SplitPdfUsingIronPDF.
Parametry metody
inputPdfPath: Ciąg znaków reprezentujący ścieżkę do pliku PDF wejściowego (np. "input.pdf").outputFolder: Ciąg znaków reprezentujący folder wyjściowy, w którym zostaną zapisane podzielone pliki PDF (np. "output_split").numberOfSplitFiles: Liczba całkowita wskazująca, na ile mniejszych plików PDF zostanie podzielony oryginalny plik PDF.
Proces podziału
Wewnątrz metody SplitPdfUsingIronPDF:
- Obiekt
PdfDocumento nazwiesourceFilejest tworzony poprzez załadowanie pliku PDF z określonegoinputPdfPath. - Zainicjowano dwie zmienne całkowitoliczbowe,
firstPageilastPage. Oto zakres stron do podziału. totalPageInOneFileoblicza się, dzieląc całkowitą liczbę stron źródłowego pliku PDF przez określoną wartośćnumberOfSplitFiles.- Pętla iteruje od 1 do
numberOfSplitFiles: - Tworzony jest nowy obiekt
PdfDocumento nazwienewSplitPDF. - Strony od
firstPagedolastPage(włącznie) są skopiowane zsourceFiledonewSplitPDF. - Powstały mniejszy plik PDF jest zapisywany pod nazwą typu "SplitPDF_IronPDF_1.pdf" (dla pierwszego podziału) w określonym folderze wyjściowym.
- Wartości
firstPageilastPagesą aktualizowane na następną iterację.
Uwaga
Należy zastąpić "input.pdf" rzeczywistą ścieżką do pliku PDF, który ma służyć jako dane wejściowe. Należy upewnić się, że biblioteka IronPDF jest prawidłowo zainstalowana i odwołuje się do niej projekt.
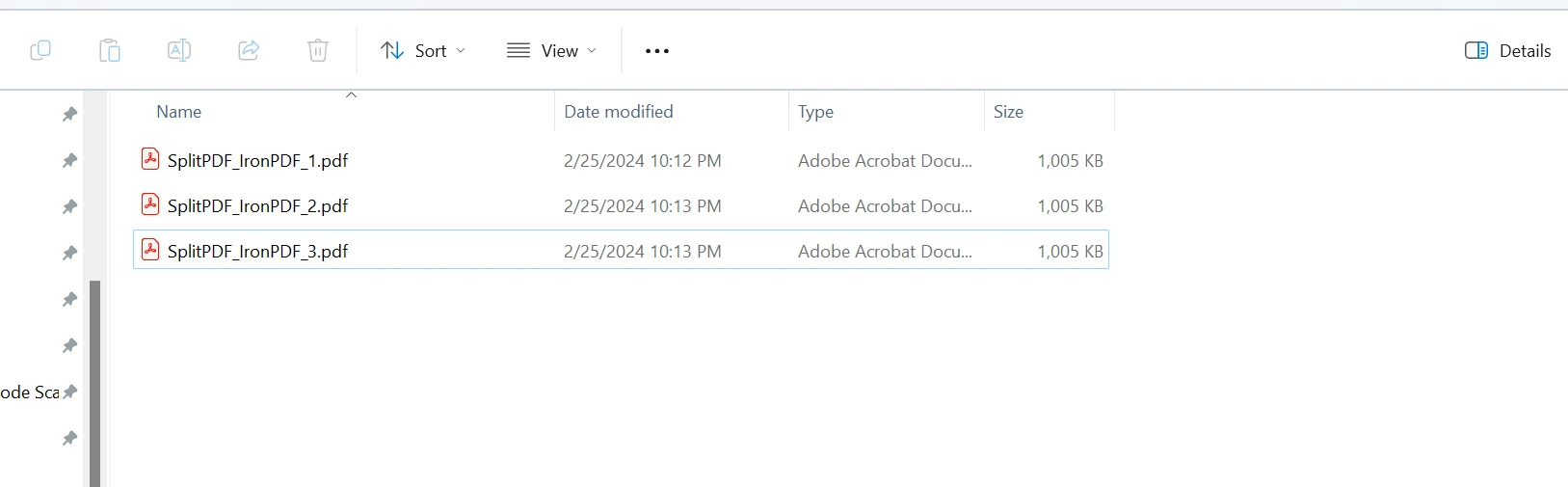
Pliki wyjściowe są tworzone w następujących formatach:
Dzielenie plików PDF w języku C# przy użyciu iTextSharp
Teraz użyjemy iTextSharp do podzielenia naszego dokumentu PDF na wiele plików PDF. Poniższy kod pobierze plik źródłowy jako dane wejściowe i podzieli ten dokument PDF na wiele mniejszych plików.
using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}Imports System
Imports iText.Kernel.Pdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim inputPath As String = "input.pdf"
' Output PDF files path (prefix for the generated files)
Dim outputPath As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles)
End Sub
Private Shared Sub SplitPdfUsingiTextSharp(ByVal inputPdfPath As String, ByVal outputFolder As String, ByVal numberOfSplitFiles As Integer)
Using reader As New PdfReader(inputPdfPath)
Using doc As New PdfDocument(reader)
' Calculate the number of pages for each split file
'INSTANT VB WARNING: Instant VB cannot determine whether both operands of this division are integer types - if they are then you should use the VB integer division operator:
Dim totalPageInOneFile As Integer = doc.GetNumberOfPages() / numberOfSplitFiles
Dim firstPage As Integer = 1
Dim lastPage As Integer = totalPageInOneFile
For i As Integer = 1 To numberOfSplitFiles
' Generate the output file path
Dim filename As String = $"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf"
' Create a new document and attach a writer for the specified output file
Using pdfDocument As New PdfDocument(New PdfWriter(filename))
' Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument)
End Using
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next i
End Using
End Using
End Sub
End ClassWyjaśnienie kodu
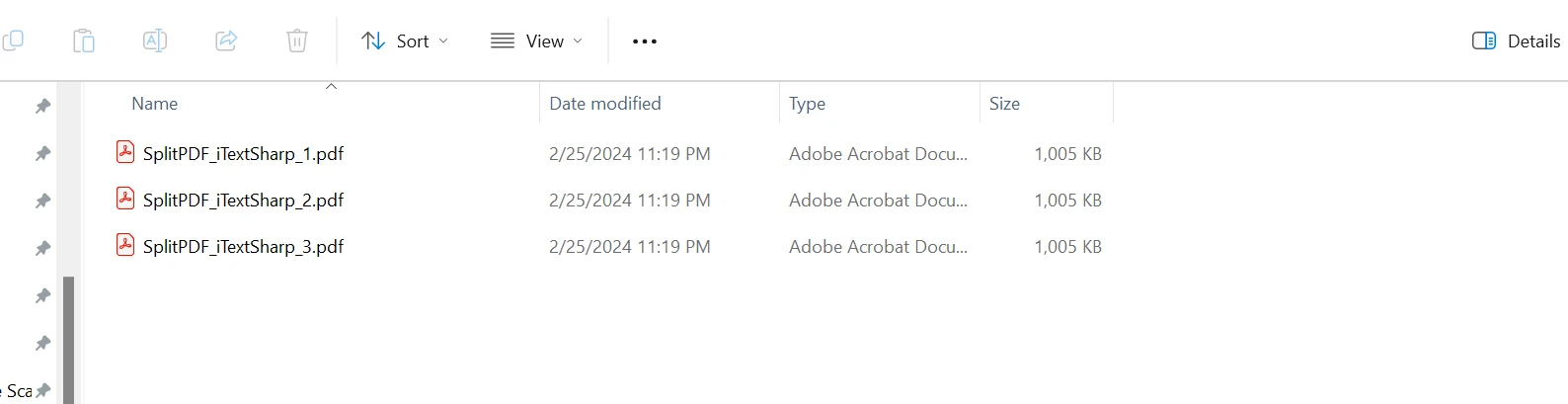
Ten kod pokazuje, jak podzielić duży plik PDF na mniejsze części za pomocą iTextSharp. Każdy mniejszy dokument PDF będzie zawierał fragment oryginalnego dokumentu.
Dzielenie plików PDF za pomocą iTextSharp
- Główna funkcjonalność jest zawarta w metodzie
SplitPdfUsingiTextSharp. - Powyższa metoda przyjmuje trzy parametry:
inputPdfPath,outputFolderoraznumberOfSplitFiles.
Korzystanie z PdfReader i PdfDocument
Wewnątrz metody SplitPdfUsingiTextSharp:
- Obiekt
PdfReadero nazwiereaderjest tworzony poprzez załadowanie pliku PDF z określonegoinputPdfPath. - Obiekt
PdfDocumento nazwiedocjest inicjowany przy użyciureader. - Całkowita liczba stron w pliku PDF źródłowym jest dzielona przez
numberOfSplitFilesw celu ustalenia, ile stron powinien zawierać każdy mniejszy plik PDF.
Proces podziału
Pętla iteruje od 1 do numberOfSplitFiles:
- W określonym folderze wyjściowym tworzony jest nowy, mniejszy plik PDF o nazwie "SplitPDF_iTextSharp_1.pdf" (dla pierwszego podziału).
- W tym nowym dokumencie PDF (
pdfDocument) strony zostały skopiowane z oryginałudoc: - Skopiowano fragment od
firstPagedolastPage(włącznie). - Zapisano plik PDF o mniejszym rozmiarze.
- Wartości
firstPageilastPagesą aktualizowane na następną iterację.
Uwaga
Upewnij się, że biblioteka iTextSharp jest poprawnie zainstalowana i odwołuje się do niej w Twoim projekcie. Zastąp "input.pdf" rzeczywistą ścieżką do pliku PDF, który chcesz przetworzyć.
Porównanie
Aby porównać dwie metody dzielenia plików przy użyciu iTextSharp i IronPDF, oceńmy je na podstawie kilku czynników:
- Łatwość użytkowania:
- iTextSharp: Metoda iTextSharp polega na utworzeniu obiektów PdfReader, PdfDocument i PdfWriter. Oblicza zakres stron i kopiuje je do nowego dokumentu. Takie podejście wymaga zrozumienia interfejsu API iTextSharp.
- IronPDF: Metoda IronPDF polega na utworzeniu obiektu PdfDocument na podstawie pliku źródłowego, skopiowaniu stron i zapisaniu ich w nowym pliku. Posiada bardziej przejrzysty interfejs API.
- Czytelność kodu:
- iTextSharp: Kod zawiera więcej kroków, przez co jest nieco dłuższy i potencjalnie trudniejszy do odczytania.
- IronPDF: Kod jest zwięzły i bardziej czytelny dzięki mniejszej liczbie kroków i wywołań metod.
- Wydajność:
- iTextSharp: Na wydajność może wpływać wielokrotne tworzenie i usuwanie instancji PdfDocument.
- IronPDF: Metoda ta wymaga mniej kroków i zapewnia lepszą wydajność dzięki wydajnemu kopiowaniu stron.
- Wykorzystanie pamięci:
- iTextSharp: Utworzenie wielu instancji PdfDocument spowoduje większe zużycie pamięci.
- IronPDF: Metoda ta jest bardziej wydajna pod względem pamięci dzięki uproszczonemu podejściu.
Wnioski
Podsumowując, zarówno iTextSharp, jak i IronPDF oferują solidne rozwiązania do dzielenia plików PDF w języku C#, a każde z nich ma swoje zalety. IronPDF wyróżnia się prostotą, czytelnością i potencjalnie lepszą wydajnością dzięki bardziej bezpośredniemu podejściu.
Programiści poszukujący równowagi między wszechstronnością a łatwością użytkowania mogą uznać IronPDF za atrakcyjny wybór. Ponadto IronPDF oferuje bezpłatną wersję próbną. Ostatecznie wybór między iTextSharp a IronPDF zależy od indywidualnych wymagań projektu i preferowanego stylu programowania.
Często Zadawane Pytania
Jak podzielić plik PDF w języku C#, zachowując oryginalne formatowanie?
Możesz użyć IronPDF do podzielenia pliku PDF w języku C# przy zachowaniu jego formatowania. IronPDF zapewnia proste API, które pozwala załadować plik PDF i określić zakresy stron do podziału, zapewniając zachowanie oryginalnego formatowania w wynikowych plikach PDF.
Jakie są główne różnice między iTextSharp a IronPDF w zakresie dzielenia plików PDF w języku C#?
Główne różnice dotyczą łatwości użytkowania i wydajności. IronPDF oferuje prostsze API z mniejszą liczbą kroków, co ułatwia dzielenie plików PDF bez utraty formatowania. Z drugiej strony iTextSharp wymaga utworzenia wielu instancji, takich jak PdfReader, PdfDocument i PdfWriter, co może być bardziej skomplikowane.
Czy mogę wyodrębnić konkretne strony z pliku PDF za pomocą języka C#?
Tak, korzystając z IronPDF, można łatwo wyodrębnić określone strony z pliku PDF w języku C#. Po załadowaniu pliku PDF i określeniu żądanych numerów stron IronPDF umożliwia wyodrębnienie i zapisanie tych stron jako nowego dokumentu PDF.
W jaki sposób IronPDF poprawia czytelność kodu w porównaniu z innymi bibliotekami PDF?
IronPDF poprawia czytelność kodu, oferując przejrzysty i zwięzły interfejs API, co zmniejsza potrzebę stosowania wielu klas i obiektów. Upraszcza to kod potrzebny do zadań związanych z manipulacją plikami PDF, takich jak dzielenie, co prowadzi do czystszego i łatwiejszego w utrzymaniu kodu.
Czy przed zakupem biblioteki można przetestować funkcję dzielenia plików PDF w języku C#?
Tak, IronPDF oferuje bezpłatną wersję próbną, która pozwala programistom przetestować funkcję dzielenia plików PDF oraz inne funkcje. Okres próbny umożliwia ocenę możliwości i wydajności oprogramowania przed podjęciem decyzji o zakupie.
Jakie czynniki należy wziąć pod uwagę przy wyborze biblioteki PDF do dzielenia dokumentów?
Wybierając bibliotekę PDF, weź pod uwagę takie czynniki, jak łatwość obsługi, prostota API, wydajność oraz możliwość zachowania oryginalnego formatowania dokumentu. IronPDF jest często preferowany ze względu na przyjazne dla użytkownika API i wysoką wydajność.
Jak zainstalować IronPDF w projekcie Visual Studio C#?
Aby zainstalować IronPDF w projekcie Visual Studio C#, należy użyć konsoli NuGet Package Manager Console i wpisać polecenie Install-Package IronPdf. Można go również dodać za pomocą interfejsu użytkownika NuGet Package Manager lub pobrać z oficjalnej strony internetowej IronPDF.
Czy podział pliku PDF może wpłynąć na jego jakość lub formatowanie?
Podział pliku PDF za pomocą IronPDF gwarantuje zachowanie jakości i formatowania oryginalnego dokumentu. Wydajne przetwarzanie IronPDF pozwala zachować integralność oryginalnej treści.













