
IronPDF vs PDFSharpCore: Qual biblioteca PDF .NET você deve escolher em 2025?
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Os arquivos PDF (Portable Document Format) são amplamente utilizados para compartilhar e apresentar documentos, e há momentos em que você pode precisar dividir um PDF em vários arquivos. Seja para extrair páginas específicas, dividir um documento grande em seções menores ou criar arquivos individuais para cada capítulo, a divisão de PDFs pode ser uma tarefa valiosa em diversos cenários.
Neste artigo, aprenderemos como dividir PDFs usando C#. C# é uma linguagem versátil e poderosa, e existem diversas bibliotecas disponíveis que tornam a manipulação de PDFs relativamente simples. Vamos explorar as duas bibliotecas a seguir para dividir PDFs em C#.
Como Dividir PDF em C# Usando iText
- Primeiro, instale a biblioteca iText.
- Crie um PdfReader a partir do arquivo PDF de entrada.
- Utilize um PdfDocument para trabalhar com o conteúdo do PDF.
- Calcule o número de páginas para cada arquivo dividido.
- Defina os valores iniciais do intervalo de páginas.
- Utilize um loop para processar cada arquivo dividido.
- Crie um novo documento PdfDocument para o arquivo dividido atual.
- Copie as páginas do documento original para o novo.
- Atualize os valores do intervalo de páginas para a próxima iteração.
- Salve o PDF resultante.
- Repita até que todos os arquivos sejam criados.
- Continue o processo para o número especificado de arquivos divididos.
IronPDF
IronPDF é uma poderosa biblioteca C# projetada para trabalhar com arquivos PDF. It provides features for creating, modifying, and extracting content from PDF documents. Os desenvolvedores podem gerar PDFs do zero, editar PDFs existentes e mesclá-los ou dividi-los. Além disso, o IronPDF se destaca na conversão de conteúdo HTML para o formato PDF, tornando-o útil para gerar relatórios ou documentação. Com suporte para assinaturas digitais, recursos de segurança e saída de alta qualidade, o IronPDF simplifica tarefas relacionadas a PDFs em aplicativos .NET .
iText
iText (iText) é uma biblioteca largamente usada para trabalhar com arquivos PDF no framework .NET. Oferece recursos avançados para criar, modificar e extrair conteúdo de documentos PDF de forma programática. Os desenvolvedores podem usar o iText para adicionar textos, imagens, tabelas e outros elementos gráficos aos PDFs. Além disso, oferece suporte à montagem de documentos, assinaturas digitais e conformidade com padrões de arquivamento e acessibilidade. Originalmente uma biblioteca Java, o iText foi portado para .NET e possui uma comunidade ativa de desenvolvedores e usuários.
Instalando a biblioteca IronPDF
Para instalar o pacote NuGet IronPDF usando o Console do Gerenciador de Pacotes no Visual Studio, siga estas etapas:
- No Visual Studio, acesse Ferramentas -> Gerenciador de Pacotes NuGet -> Console do Gerenciador de Pacotes.
-
Utilize o seguinte comando para instalar o pacote NuGet IronPDF :
Install-Package IronPdf
Isso fará o download e a instalação do pacote IronPDF , juntamente com suas dependências, em seu projeto. Após a conclusão da instalação, você poderá começar a usar o IronPDF em seu projeto C# para tarefas relacionadas a PDFs.
Alternativamente, você pode instalar o IronPDF usando o Gerenciador de Pacotes NuGet no Visual Studio ou adicionar o pacote diretamente ao seu arquivo de projeto. Outra opção é baixar o pacote do site oficial e adicioná-lo manualmente ao seu projeto. Cada método oferece uma maneira simples de integrar o IronPDF ao seu projeto C# para funcionalidades relacionadas a PDF.
Instalando a Biblioteca iText
Para instalar iText usando o Console do Gerenciador de Pacotes no Visual Studio, você pode seguir estas etapas:
- No Visual Studio, acesse Ferramentas -> Gerenciador de Pacotes NuGet -> Console do Gerenciador de Pacotes.
-
Use o seguinte comando para instalar o pacote NuGet iText:
Install-Package itext7Install-Package itext7SHELL
Isso baixará e instalará o pacote iText junto com suas dependências no seu projeto. Assim que a instalação estiver completa, você pode começar a usar o iText em seu projeto C# para trabalhar com PDFs.
Dividir Documentos PDF em C# Usando IronPDF
Podemos dividir um arquivo PDF em vários arquivos PDF usando o IronPDF. Isso proporciona uma maneira simples de alcançar esse objetivo. O código a seguir receberá o arquivo PDF de origem como entrada e o dividirá em vários arquivos PDF.
using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsing IronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsing IronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsing IronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsing IronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}Imports IronPdf
Class Program
Shared Sub Main(args As String())
Dim file As String = "input.pdf"
' The folder to save the split PDFs
Dim outputFolder As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles)
End Sub
Shared Sub SplitPdfUsingIronPDF(inputPdfPath As String, outputFolder As String, numberOfSplitFiles As Integer)
' Load the input PDF
Dim sourceFile As PdfDocument = PdfDocument.FromFile(inputPdfPath)
' Initialize page range values
Dim firstPage As Integer = 1
Dim lastPage As Integer = 2
Dim totalPageInOneFile As Integer = sourceFile.PageCount \ numberOfSplitFiles
For i As Integer = 1 To numberOfSplitFiles
' Copy multiple pages into a new document
Dim newSplitPDF As PdfDocument = sourceFile.CopyPages(firstPage, lastPage)
' Generate the output file path
Dim name As String = $"{outputFolder}\SplitPDF_IronPDF_{i}.pdf"
' Save the new split PDF
newSplitPDF.SaveAs(name)
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next
End Sub
End ClassExplicação do código
O objetivo deste código é dividir um arquivo PDF em vários arquivos PDF menores usando a biblioteca IronPDF . O método SplitPdfUsing IronPDF é definido para alcançar essa funcionalidade.
Parâmetros do método
inputPdfPath: Uma string que representa o caminho para o arquivo PDF de entrada (por exemplo, 'input.pdf').outputFolder: Uma string que representa a pasta de saída onde os arquivos PDF split serão salvos (por exemplo, 'output_split').numberOfSplitFiles: Um inteiro indicando quantos arquivos PDF menores o PDF original será dividido.
Processo de divisão
Dentro do método SplitPdfUsing IronPDF:
- Um objeto
PdfDocumentchamadosourceFileé criado carregando o PDF doinputPdfPathespecificado. - Duas variáveis inteiras,
firstPageelastPage, são inicializadas. Esses valores representam o intervalo de páginas para divisão. totalPageInOneFileé calculado dividindo o número total de páginas do PDF fonte pelonumberOfSplitFilesespecificado.- Um loop itera de 1 a
numberOfSplitFiles: - Um novo objeto
PdfDocumentchamadonewSplitPDFé criado. - Páginas de
firstPagealastPage(inclusive) são copiadas dosourceFileparanewSplitPDF. - O PDF resultante, em tamanho menor, é salvo com um nome de arquivo como "SplitPDF_IronPDF_1.pdf" (para a primeira divisão) na pasta de saída especificada.
- Os valores
firstPageelastPagesão atualizados para a próxima iteração.
Observação
Você deve substituir "input.pdf" pelo caminho real do seu arquivo PDF de entrada. Certifique-se de que a biblioteca IronPDF esteja instalada e referenciada corretamente em seu projeto.
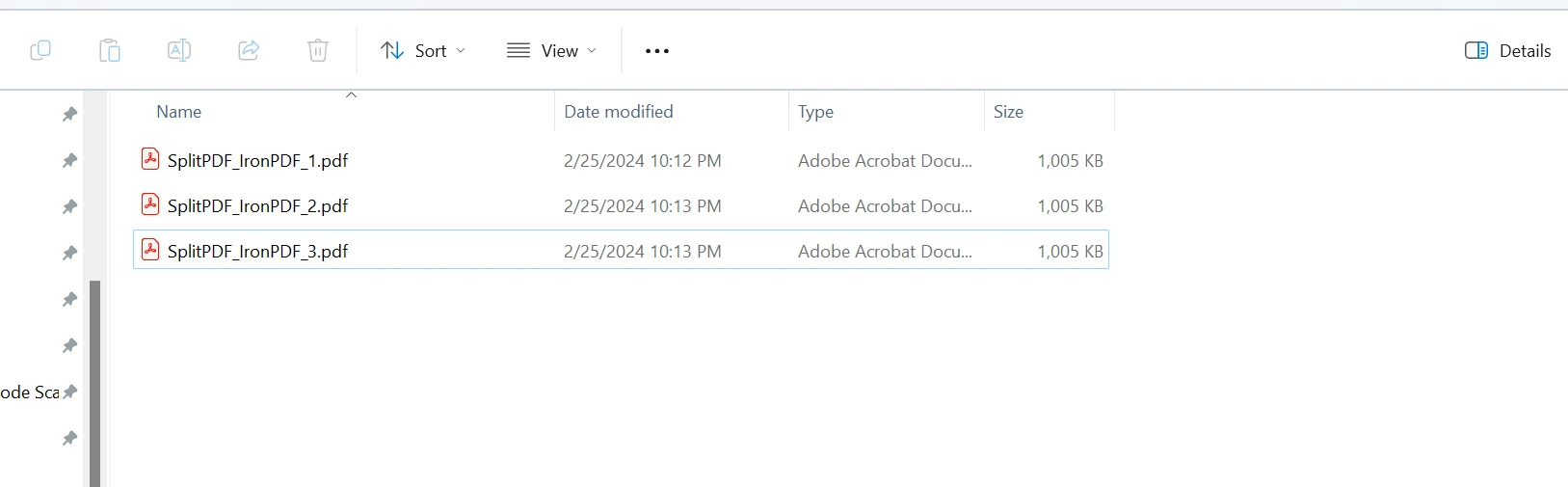
Os arquivos de saída são criados da seguinte forma:
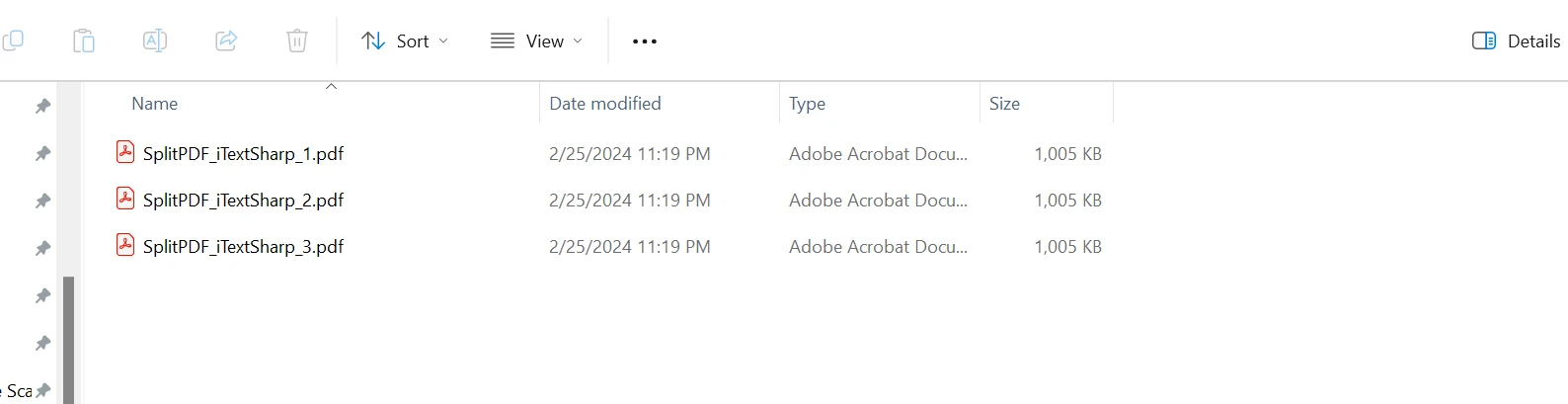
Dividir PDFs em C# Usando iText
Agora, usaremos o iText para dividir nosso documento PDF em múltiplos arquivos PDF. O código a seguir receberá o arquivo de origem como entrada e dividirá esse documento PDF em vários arquivos menores.
using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}Imports System
Imports iText.Kernel.Pdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim inputPath As String = "input.pdf"
' Output PDF files path (prefix for the generated files)
Dim outputPath As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles)
End Sub
Private Shared Sub SplitPdfUsingiTextSharp(ByVal inputPdfPath As String, ByVal outputFolder As String, ByVal numberOfSplitFiles As Integer)
Using reader As New PdfReader(inputPdfPath)
Using doc As New PdfDocument(reader)
' Calculate the number of pages for each split file
'INSTANT VB WARNING: Instant VB cannot determine whether both operands of this division are integer types - if they are then you should use the VB integer division operator:
Dim totalPageInOneFile As Integer = doc.GetNumberOfPages() / numberOfSplitFiles
Dim firstPage As Integer = 1
Dim lastPage As Integer = totalPageInOneFile
For i As Integer = 1 To numberOfSplitFiles
' Generate the output file path
Dim filename As String = $"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf"
' Create a new document and attach a writer for the specified output file
Using pdfDocument As New PdfDocument(New PdfWriter(filename))
' Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument)
End Using
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next i
End Using
End Using
End Sub
End ClassExplicação do código
Este código demonstra como dividir um arquivo PDF grande em pedaços menores usando iText. Cada documento PDF menor conterá uma parte do documento original.
Dividindo PDF Usando iText
- A funcionalidade principal está encapsulada no método
SplitPdfUsingiTextSharp. - O método acima recebe três parâmetros:
inputPdfPath,outputFolderenumberOfSplitFiles.
Usando PdfReader e PdfDocument
Dentro do método SplitPdfUsingiTextSharp:
- Um objeto
PdfReaderchamadoreaderé criado ao carregar o PDF doinputPdfPathespecificado. - Um objeto
PdfDocumentchamadodocé inicializado usando oreader. - O número total de páginas no PDF fonte é dividido por
numberOfSplitFilespara determinar quantas páginas cada PDF menor deve conter.
Processo de divisão
Um loop itera de 1 a numberOfSplitFiles:
- Um novo arquivo PDF menor é criado com um nome de arquivo como 'SplitPDF_iText_1.pdf' (para a primeira divisão) na pasta de saída especificada.
- Dentro deste novo documento PDF (
pdfDocument), as páginas são copiadas dodocoriginal: firstPageparalastPage(inclusive) são copiadas.- O PDF menor é salvo.
- Os valores
firstPageelastPagesão atualizados para a próxima iteração.
Observação
Certifique-se de que a biblioteca iText esteja devidamente instalada e referenciada em seu projeto. Substitua "input.pdf" pelo caminho real do seu arquivo PDF de entrada.
Comparação
Para comparar os dois métodos de divisão usando iText e IronPDF, vamos avaliá-los com base em vários fatores:
- Facilidade de uso:
- iText: O método iText envolve criar um PdfReader, PdfDocument e PdfWriter. Ele calcula intervalos de páginas e copia as páginas para um novo documento. Esta abordagem requer o entendimento da API do iText.
- IronPDF: O método IronPDF envolve a criação de um documento PDF a partir do arquivo de origem, a cópia das páginas e o salvamento em um novo arquivo. Possui uma API mais simples.
- Legibilidade do código:
- iText: O código envolve mais passos, tornando-o ligeiramente mais longo e potencialmente mais complexo de ler.
- IronPDF: O código é conciso e mais legível devido ao menor número de etapas e chamadas de método.
- Desempenho:
- iText: O desempenho pode ser afetado pela criação e descarte repetido de instâncias de PdfDocument.
- IronPDF: Este método envolve menos etapas e oferece melhor desempenho devido à cópia eficiente de páginas.
- Utilização de memória:
- iText: Criar múltiplas instâncias de PdfDocument consumirá mais memória.
- IronPDF: O método é mais eficiente em termos de memória devido à sua abordagem simplificada.
Conclusão
Em conclusão, tanto o iText quanto o IronPDF oferecem soluções robustas para dividir arquivos PDF em C#, cada um com seu próprio conjunto de vantagens. O IronPDF se destaca por sua simplicidade, legibilidade e desempenho potencialmente melhor devido a uma abordagem mais direta.
Desenvolvedores que buscam um equilíbrio entre versatilidade e facilidade de uso podem achar o IronPDF uma escolha atraente. Além disso, o IronPDF oferece um período de teste gratuito . Em última análise, a escolha entre o iText e o IronPDF depende dos requisitos individuais do projeto e do estilo de desenvolvimento preferido.
Perguntas frequentes
Como posso dividir um PDF em C# mantendo a formatação original?
Você pode usar o IronPDF para dividir um PDF em C# preservando sua formatação. O IronPDF oferece uma API simples que permite carregar um PDF e especificar os intervalos de páginas a serem divididos, garantindo que a formatação original seja mantida nos PDFs resultantes.
Quais são as principais diferenças entre iTextSharp e IronPDF para dividir PDFs em C#?
As principais diferenças residem na facilidade de uso e no desempenho. O IronPDF oferece uma API mais direta, com menos etapas, facilitando a divisão de PDFs sem perda de formatação. Por outro lado, o iTextSharp exige a criação de múltiplas instâncias, como PdfReader , PdfDocument e PdfWriter , o que pode ser mais complexo.
É possível extrair páginas específicas de um PDF usando C#?
Sim, usando o IronPDF, você pode extrair facilmente páginas específicas de um PDF em C#. Ao carregar o PDF e especificar os números de página desejados, o IronPDF permite extrair e salvar essas páginas como um novo documento PDF.
Como o IronPDF melhora a legibilidade do código em comparação com outras bibliotecas PDF?
O IronPDF melhora a legibilidade do código ao oferecer uma API clara e concisa, reduzindo a necessidade de múltiplas classes e objetos. Isso simplifica o código necessário para tarefas de manipulação de PDF, como divisão, resultando em um código mais limpo e de fácil manutenção.
É possível testar a funcionalidade de divisão de PDF em C# antes de adquirir uma biblioteca?
Sim, o IronPDF oferece um período de teste gratuito que permite aos desenvolvedores testar sua funcionalidade de divisão de PDFs e outros recursos. Esse período de teste permite avaliar suas capacidades e desempenho antes de tomar uma decisão de compra.
Que fatores devem ser considerados ao escolher uma biblioteca de PDF para dividir documentos?
Ao selecionar uma biblioteca de PDF, considere fatores como facilidade de uso, simplicidade da API, desempenho e a capacidade de manter a formatação original do documento. O IronPDF costuma ser a opção preferida devido à sua API amigável e desempenho eficiente.
Como posso instalar o IronPDF em um projeto C# do Visual Studio?
Para instalar o IronPDF em um projeto C# do Visual Studio, use o Console do Gerenciador de Pacotes NuGet com o comando Install-Package IronPDF . Você também pode adicioná-lo pela interface do Gerenciador de Pacotes NuGet ou baixá-lo do site oficial do IronPDF.
Dividir um PDF pode afetar sua qualidade ou formatação?
Dividir um PDF com o IronPDF garante que a qualidade e a formatação do documento original sejam preservadas. O processamento eficiente do IronPDF mantém a integridade do conteúdo original.












