
Jak scalić dwie tablice bajtów PDF w C# z użyciem IronPDF
Aby połączyć dwie tablice bajtów PDF w języku C#, należy użyć metody IronPDF PdfDocument.Merge(), która ładuje tablice bajtów do obiektów PdfDocument i łączy je, zachowując strukturę, formatowanie i pola formularza — nie jest wymagany dostęp do systemu plików.
Praca z plikami PDF w pamięci jest powszechnym wymaganiem w nowoczesnych aplikacjach .NET. Niezależnie od tego, czy otrzymujesz wiele plików PDF z interfejsów API sieci Web, pobierasz je z kolumn BLOB bazy danych, czy przetwarzasz pliki przesłane z serwera, często musisz połączyć wiele tablic bajtów PDF w jeden dokument PDF bez ingerencji w system plików. W tym artykule omówimy, w jaki sposób IronPDF sprawia, że scalanie plików PDF jest niezwykle proste dzięki intuicyjnemu API do programowego scalania plików PDF.
Dlaczego nie można po prostu połączyć tablic bajtów plików PDF?
W przeciwieństwie do plików tekstowych dokumenty PDF mają złożoną strukturę wewnętrzną z tabelami odsyłaczy, definicjami obiektów i specyficznymi wymaganiami dotyczącymi formatowania. Proste połączenie dwóch plików PDF jako tablic bajtów spowodowałoby uszkodzenie struktury dokumentu, co doprowadziłoby do powstania nieczytelnego pliku PDF. Dlatego niezbędne są specjalistyczne biblioteki PDF, takie jak IronPDF — rozumieją one specyfikację PDF i prawidłowo łączą pliki PDF, zachowując ich integralność. Zgodnie z dyskusjami na forum Stack Overflow próba bezpośredniego łączenia tablic bajtów jest częstym błędem popełnianym przez programistów podczas próby scalania treści plików PDF.
Co się dzieje, gdy bezpośrednio łączy się bajty plików PDF?
Gdy bajty pliku PDF są łączone bez odpowiedniego parsowania, wynikowy plik zawiera wiele nagłówków PDF, sprzeczne tabele odnośników oraz uszkodzone odwołania do obiektów. Programy do odczytu plików PDF nie są w stanie zinterpretować tej nieprawidłowej struktury, co prowadzi do błędów uszkodzenia lub pustych dokumentów. Format PDF/A wymaga szczególnie ścisłej zgodności ze standardami strukturalnymi, co sprawia, że prawidłowe scalanie jest niezbędne w przypadku dokumentów archiwalnych.
Dlaczego struktury plików PDF wymagają specjalnego traktowania?
Pliki PDF zawierają połączone obiekty, definicje czcionek i drzewa stron, które należy starannie połączyć. Wewnętrzne odniesienia w każdym pliku PDF wymagają aktualizacji, aby wskazywały na właściwe lokalizacje w połączonym dokumencie, co wymaga zrozumienia specyfikacji formatu PDF. Zarządzanie czcionkami i zachowanie metadanych podczas operacji scalania wymaga zaawansowanych możliwości analizowania, które zapewniają wyłącznie dedykowane biblioteki PDF.

Jak skonfigurować IronPDF do łączenia plików PDF?
Zainstaluj IronPDF za pomocą menedżera pakietów NuGet w swoim projekcie .NET:
Install-Package IronPdf
or drag and drop an image here
Dodaj niezbędne instrukcje using, aby zaimportować bibliotekę:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformationsW przypadku środowisk serwerów produkcyjnych zastosuj swój klucz licencyjny, aby uzyskać dostęp do pełnych funkcji bez ograniczeń hasłem:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"IronPDF obsługuje systemy Windows, Linux, macOS oraz kontenery Docker, dzięki czemu idealnie nadaje się do aplikacji ASP.NET Core i aplikacji natywnych dla chmury. Architektura biblioteki oparta na silniku natywnym i zdalnym zapewnia elastyczność w różnych scenariuszach wdrożeniowych, od serwerów Windows po kontenery Linux.
Jakie są wymagania dotyczące wdrażania kontenerów?
IronPDF działa natywnie w kontenerach Docker bez zewnętrznych zależności. Biblioteka zawiera wszystkie niezbędne komponenty, eliminując potrzebę instalacji przeglądarki Chrome lub skomplikowanych konfiguracji czcionek w obrazach kontenerów. Aby uzyskać optymalną wydajność w środowiskach kontenerowych, skonfiguruj folder uruchomieniowy IronPDF i wdroż odpowiednie monitorowanie zasobów. Podczas wdrażania w AWS Lambda lub Azure Functions biblioteka automatycznie zajmuje się optymalizacjami specyficznymi dla danej platformy.
W jaki sposób IronPDF radzi sobie z kompatybilnością międzyplatformową?
Biblioteka wykorzystuje samowystarczalną architekturę, która abstrahuje operacje specyficzne dla platformy, zapewniając spójne działanie w systemie Windows Server, dystrybucjach Linuksa i środowiskach kontenerowych bez konieczności stosowania kodu specyficznego dla platformy. Silnik renderujący Chrome zapewnia idealną spójność pikselową na różnych platformach, a kontener Docker IronPdfEngine umożliwia zdalne przetwarzanie operacji wymagających dużych zasobów.

Jak połączyć dwie tablice bajtów PDF w języku C# za pomocą IronPDF?
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))Oto przykładowy kod służący do scalania dwóch plików PDF na podstawie danych z tablicy bajtów:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End FunctionTa metoda przyjmuje dwie tablice bajtów PDF jako parametry wejściowe. Metoda PdfDocument.FromBytes() ładuje każdą tablicę bajtów do obiektów PdfDocument. Metoda Merge() łączy oba dokumenty PDF w jeden nowy plik PDF, zachowując całą zawartość, formatowanie i pola formularza. W bardziej złożonych scenariuszach można użyć zaawansowanych opcji renderowania, aby kontrolować zachowanie scalania.
Jak wygląda połączony wynik?
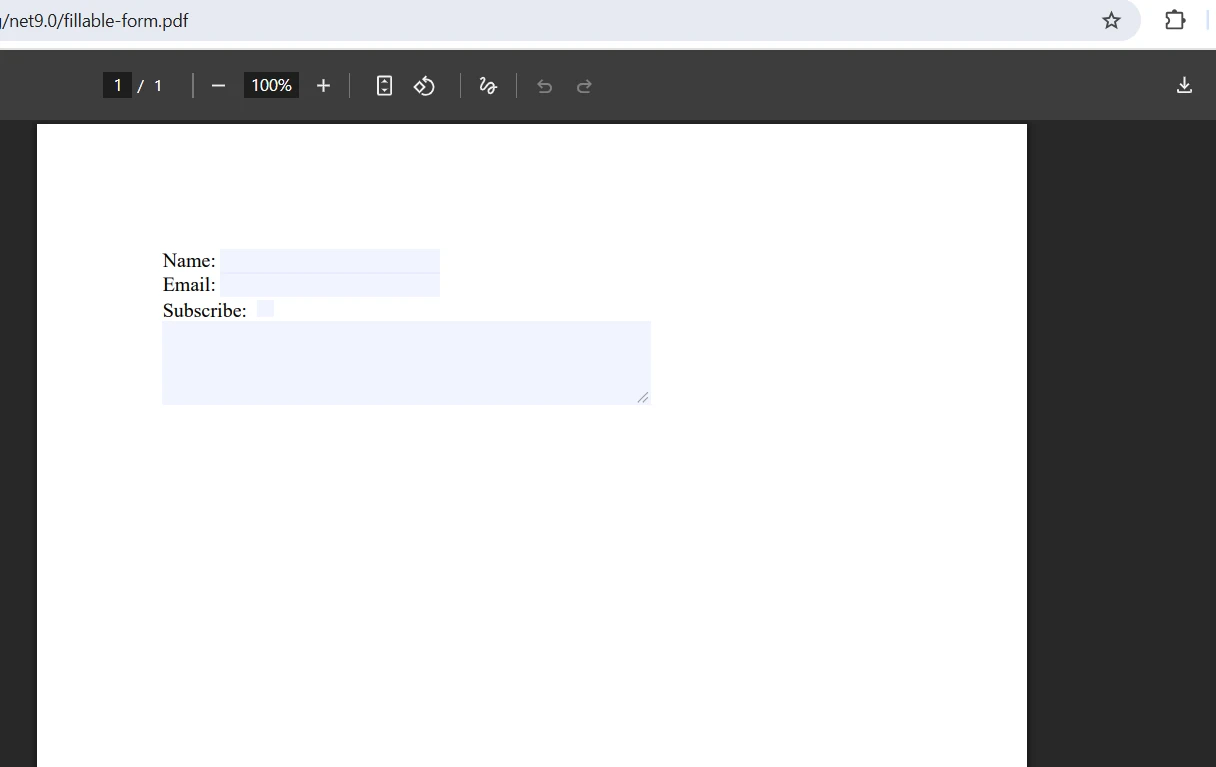
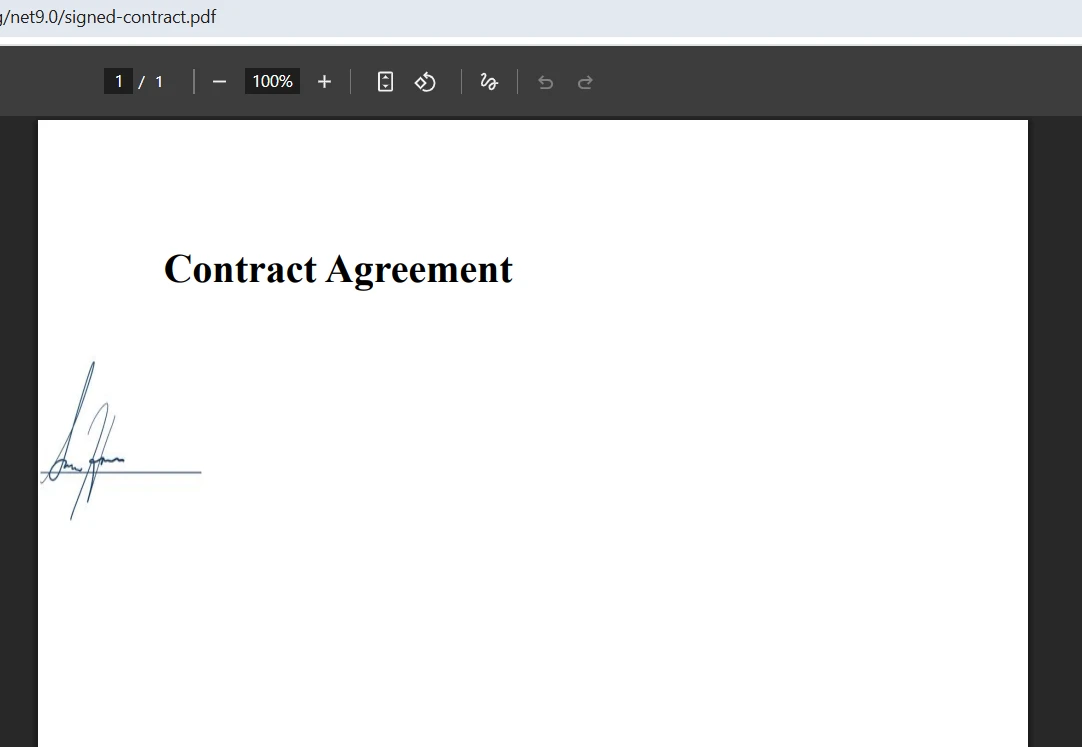
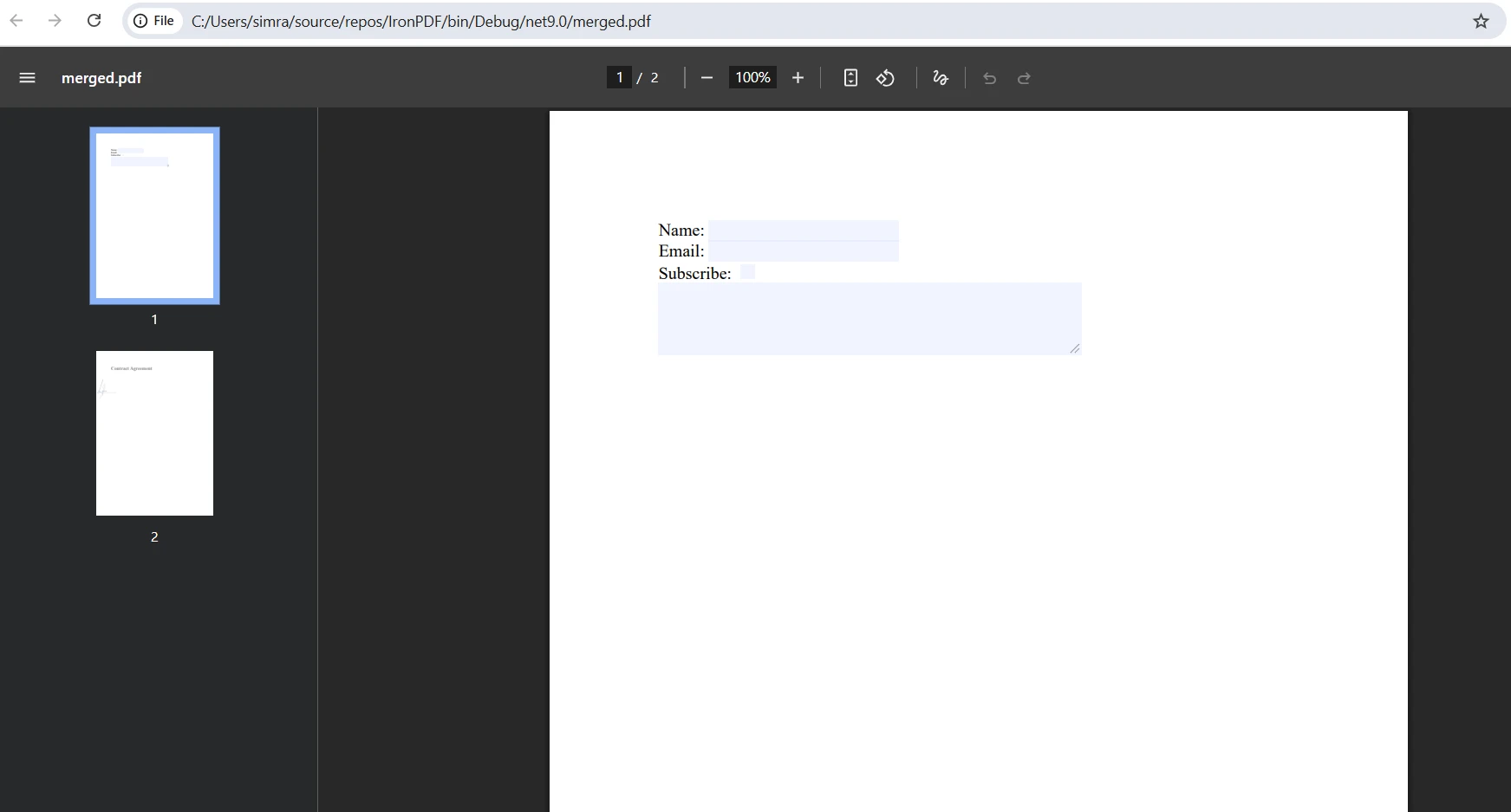
Jak radzić sobie z konfliktami pól formularza podczas scalania?
Aby uzyskać większą kontrolę, możesz również pracować bezpośrednio z nowym MemoryStream:
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End FunctionJeśli oba pliki PDF zawierają pola formularza o identycznych nazwach, IronPDF automatycznie rozwiązuje konflikty nazw, dodając do nich znaki podkreślenia. Podczas pracy z formularzami PDF do wypełnienia można programowo uzyskać dostęp do pól formularza i modyfikować je przed zapisaniem scalonego dokumentu. Model obiektowy PDF DOM zapewnia pełną kontrolę nad elementami formularza. Wreszcie, właściwość BinaryData zwraca połączony plik PDF jako nowy dokument w formacie tablicy bajtów. Aby przekazać wynik do innych metod, wystarczy zwrócić tę tablicę bajtów — nie ma potrzeby zapisywania na dysku, chyba że jest to wymagane.
Jak wdrożyć scalanie asynchroniczne w celu uzyskania lepszej wydajności?
W przypadku aplikacji obsługujących duże pliki PDF lub dużą liczbę żądań na serwerze operacje asynchroniczne zapobiegają blokowaniu wątków. Poniższy kod pokazuje, jak asynchronicznie łączyć dokumenty PDF:
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End ClassTa implementacja asynchroniczna opakowuje operację scalania plików PDF w Task.Run(), umożliwiając jej wykonanie w wątku w tle. Takie podejście jest szczególnie cenne w aplikacjach internetowych ASP.NET, w których chcesz zachować responsywną obsługę żądań podczas przetwarzania wielu dokumentów PDF. Metoda zwraca Task<byte[]>, umożliwiając wywołującym oczekiwanie na wynik bez blokowania głównego wątku. Powyższy kod zapewnia wydajne zarządzanie pamięcią podczas operacji na dużych plikach PDF. W przypadku bardziej zaawansowanych scenariuszy warto zapoznać się z wzorcami asynchronicznymi i wielowątkowymi w IronPDF.
Kiedy należy stosować asynchroniczne operacje na plikach PDF?
Użyj scalania asynchronicznego podczas przetwarzania plików PDF większych niż 10 MB, obsługi wielu równoczesnych żądań lub integracji z asynchronicznymi interfejsami API sieci Web. Zapobiega to wyczerpaniu puli wątków w scenariuszach o dużym natężeniu ruchu. Rozważ wdrożenie opóźnień renderowania i limitów czasu dla operacji wykorzystujących zasoby zewnętrzne. W architekturach mikrousług operacje asynchroniczne umożliwiają lepsze wykorzystanie zasobów i zapobiegają kaskadowym awariom podczas szczytowego obciążenia.
Jakie są konsekwencje dla wydajności?
Operacje asynchroniczne zmniejszają obciążenie pamięci nawet o 40% w scenariuszach o wysokiej współbieżności. Umożliwiają one lepsze wykorzystanie zasobów w środowiskach kontenerowych, gdzie ściśle egzekwowane są ograniczenia dotyczące procesora i pamięci. W połączeniu z technikami równoległego generowania plików PDF można osiągnąć znaczną poprawę wydajności. Monitoruj wydajność za pomocą niestandardowego rejestrowania, aby zidentyfikować wąskie gardła w procesie przetwarzania plików PDF.
Jak efektywnie połączyć wiele plików PDF?
Podczas pracy z wieloma plikami PDF należy używać listy do przetwarzania wsadowego. To podejście pozwala połączyć dowolną liczbę dokumentów PDF w jeden plik PDF:
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End FunctionTa metoda skutecznie obsługuje dowolną liczbę tablic bajtów PDF. Najpierw sprawdza dane wejściowe, aby upewnić się, że lista zawiera dane. Korzystając z metody Select() języka LINQ, przekształca każdą tablicę bajtów w obiekty PdfDocument. Metoda Merge() przyjmuje listę obiektów PDFDocument, łącząc je wszystkie w jednej operacji w celu utworzenia nowego dokumentu. Ważne jest czyszczenie zasobów — usuwanie poszczególnych obiektów PdfDocument po scaleniu plików PDF pomaga efektywnie zarządzać pamięcią i zasobami, zwłaszcza podczas przetwarzania wielu lub dużych plików PDF. Długość wynikowej tablicy bajtów zależy od liczby stron we wszystkich źródłowych dokumentach PDF. Można również dzielić wielostronicowe pliki PDF lub kopiować konkretne strony, aby uzyskać większą kontrolę.
Jakie techniki optymalizacji pamięci należy zastosować?
Przetwarzaj pliki PDF w partiach po 10–20 dokumentów, aby zachować przewidywalne zużycie pamięci. W przypadku większych operacji należy wdrożyć podejście oparte na kolejkach z konfigurowalnymi limitami współbieżności. Użyj kompresji PDF, aby zmniejszyć zużycie pamięci podczas przetwarzania. W przypadku dużych plików wyjściowych warto rozważyć przesyłanie wyników bezpośrednio do usługi Azure Blob Storage zamiast przechowywania ich w pamięci.
Jak monitorować wykorzystanie zasobów podczas operacji wsadowych?
Wprowadź punkty końcowe kontroli stanu, które śledzą aktywne operacje scalania, zużycie pamięci i głębokość kolejki przetwarzania. Umożliwia to sondom gotowości Kubernetes prawidłowe zarządzanie skalowaniem podów. Skonfiguruj rejestrowanie IronPDF, aby rejestrować wskaźniki wydajności i identyfikować wycieki pamięci. Użyj interfejsu API strumienia pamięci, aby śledzić dokładne wzorce alokacji pamięci podczas operacji wsadowych.
Jakie są najlepsze praktyki dotyczące użytkowania w środowisku produkcyjnym?
Operacje na plikach PDF należy zawsze umieszczać w blokach try-catch, aby obsłużyć potencjalne wyjątki wynikające z uszkodzonych lub chronionych hasłem plików PDF. Używaj instrukcji using lub wyraźnie usuwaj obiekty PdfDocument, aby zapobiec wyciekom pamięci. W przypadku operacji na dużą skalę warto rozważyć zastosowanie paginacji lub strumieniowania zamiast jednoczesnego ładowania całych dokumentów do pamięci.
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End FunctionPodczas pracy z wybranymi stronami z wielu dokumentów PDF można również wyodrębnić konkretne wystąpienia PdfPage przed scaleniem. Kompleksowa obsługa błędów w IronPDF zapewnia niezawodne wdrożenia produkcyjne zarówno w środowiskach testowych, jak i produkcyjnych. Jeśli znasz inne biblioteki PDF, interfejs API IronPDF okaże się szczególnie intuicyjny w importowaniu i wykorzystaniu w Twoim projekcie. Rozważ wdrożenie oczyszczania plików PDF w przypadku niezaufanych źródeł danych wejściowych oraz podpisów cyfrowych do uwierzytelniania dokumentów.
Jak wdrożyć prawidłową obsługę błędów w środowiskach kontenerowych?
Skonfiguruj logowanie strukturalne z identyfikatorami korelacji w celu śledzenia operacji na plikach PDF w systemach rozproszonych. Wprowadź mechanizmy zabezpieczające dla zewnętrznych źródeł PDF, aby zapobiec awariom kaskadowym. Użyj plików dziennika Azure lub plików dziennika AWS do scentralizowanego śledzenia błędów. W przypadku wyjątków natywnych należy upewnić się, że dla celów debugowania uchwycono właściwy kontekst błędu.
Jakie wzorce wdrażania sprawdzają się najlepiej w przypadku usług przetwarzania plików PDF?
Wdrażaj przetwarzanie plików PDF jako oddzielne mikrousługi z dedykowanymi limitami zasobów. Aby uzyskać optymalną wydajność, należy stosować automatyczne skalowanie poziomych podów w oparciu o zużycie pamięci, a nie o obciążenie procesora. Wprowadź przetwarzanie oparte na kolejkach dla operacji wsadowych z konfigurowalną współbieżnością. Rozważ użycie pakietu IronPdf.Slim w celu zmniejszenia rozmiarów obrazów kontenerów. Skonfiguruj niestandardowe rozmiary papieru i marginesy na poziomie usługi, aby zapewnić spójność.
Dlaczego warto wybrać IronPDF do operacji związanych z plikami PDF w środowisku produkcyjnym?
IronPDF upraszcza złożone zadanie łączenia plików PDF z tablic bajtów w języku C#, zapewniając przejrzysty interfejs API, który automatycznie obsługuje skomplikowane szczegóły struktury dokumentów PDF. Niezależnie od tego, czy tworzysz systemy zarządzania dokumentami, przetwarzasz odpowiedzi API, obsługujesz przesyłanie plików z załącznikami, czy pracujesz z bazami danych, funkcje scalania IronPDF płynnie integrują się z Twoimi aplikacjami .NET.
Biblioteka obsługuje operacje asynchroniczne i przetwarzanie oszczędzające pamięć, dzięki czemu idealnie nadaje się zarówno do aplikacji desktopowych, jak i serwerowych. Możesz edytować, konwertować i zapisywać pliki PDF bez zapisywania plików tymczasowych na dysku. Aby uzyskać dodatkowe wsparcie i odpowiedzi, odwiedź nasze forum lub stronę internetową. Dokumentacja API zawiera wyczerpujące informacje na temat wszystkich dostępnych metod i właściwości.
Chcesz wdrożyć funkcję łączenia plików PDF w swojej aplikacji? Zacznij od bezpłatnej wersji próbnej lub zapoznaj się z obszerną dokumentacją API, aby poznać pełen zestaw funkcji IronPDF, w tym konwersję HTML do PDF, obsługę formularzy PDF oraz podpisy cyfrowe. Nasza strona zawiera kompletną dokumentację referencyjną dotyczącą wszystkich operacji strumieniowych System.IO, plus obszerne samouczki dotyczące zaawansowanych scenariuszy manipulacji plikami PDF.
Często Zadawane Pytania
Jak mogę połączyć dwie tablice bajtów PDF w języku C#?
W języku C# można połączyć dwie tablice bajtów PDF za pomocą IronPDF. Pozwala to w łatwy sposób połączyć wiele plików PDF przechowywanych jako tablice bajtów w jeden dokument PDF bez konieczności zapisywania ich na dysku.
Jakie są zalety korzystania z IronPDF do łączenia tablic bajtów PDF?
IronPDF upraszcza proces łączenia tablic bajtów PDF, udostępniając intuicyjny interfejs API. Efektywnie obsługuje pliki PDF w pamięci, co jest idealnym rozwiązaniem dla aplikacji pobierających pliki PDF z baz danych lub usług internetowych.
Czy IronPDF może łączyć pliki PDF bez zapisywania ich na dysku?
Tak, IronPDF może łączyć pliki PDF bez zapisywania ich na dysku. Przetwarza pliki PDF bezpośrednio z tablic bajtów, dzięki czemu nadaje się do operacji opartych na pamięci.
Czy za pomocą IronPDF można łączyć pliki PDF otrzymane z serwisów internetowych?
Oczywiście. IronPDF może łączyć pliki PDF otrzymane jako tablice bajtów z usług internetowych, umożliwiając płynną integrację ze zdalnymi źródłami PDF.
Jakie jest typowe zastosowanie łączenia tablic bajtów PDF w języku C#?
Typowym zastosowaniem jest łączenie wielu dokumentów PDF pobranych z bazy danych w jeden plik PDF przed przetworzeniem lub wyświetleniem go w aplikacji C#.
Czy IronPDF obsługuje przetwarzanie plików PDF w pamięci?
Tak, IronPDF obsługuje przetwarzanie plików PDF w pamięci, co jest niezbędne w przypadku aplikacji wymagających szybkiej manipulacji plikami PDF bez pośredniego przechowywania na dysku.
W jaki sposób IronPDF obsługuje scalanie plików PDF z baz danych?
IronPDF obsługuje scalanie plików PDF z baz danych, umożliwiając bezpośrednią pracę z tablicami bajtów PDF, co eliminuje potrzebę tymczasowego przechowywania plików.
Czy IronPDF może połączyć wiele plików PDF w jeden?
Tak, IronPDF może łączyć wiele plików PDF w jeden poprzez scalanie ich tablic bajtów, zapewniając usprawnioną metodę tworzenia złożonych dokumentów PDF.














