
Jak połączyć pliki PDF w języku C#
Łączenie plików PDF w języku C# zajmuje zaledwie kilka wierszy kodu dzięki IronPDF — załaduj swoje pliki PDF za pomocą PdfDocument.FromFile() i połącz je metodą Merge(), eliminując ręczną obsługę dokumentów i skomplikowaną logikę przetwarzania.
Praca z oddzielnymi plikami dokumentów i raportami może spowolnić każdy proces. Poświęcanie czasu na ręczne łączenie plików PDF lub zmaganie się z przestarzałymi narzędziami to strata wysiłku programistów. Ten samouczek pokazuje, jak programowo łączyć pliki PDF w języku C# przy użyciu biblioteki IronPDF. Proces jest prosty — nawet w przypadku dokumentów o złożonym formatowaniu, zawierających czcionki osadzone i interaktywne pola formularzy.
Niezależnie od tego, czy tworzysz aplikacje ASP.NET, pracujesz z Windows Forms, czy też opracowujesz rozwiązania oparte na chmurze, IronPDF zapewnia gotowe do użycia rozwiązanie do obróbki plików PDF i zarządzania dokumentami. Silnik renderujący biblioteki oparty na przeglądarce Chrome zapewnia idealną wierność pikselową podczas scalania plików PDF, zachowując całe formatowanie, czcionki i dane formularzy.
Jak zainstalować IronPDF dla C#?
Pobierz pakiet NuGet za pomocą konsoli menedżera pakietów lub interfejsu CLI platformy .NET:
Install-Package IronPdfInstall-Package IronPdfdotnet add package IronPdfdotnet add package IronPdfIronPDF jest kompatybilny z .NET Framework, .NET Core i .NET 10, a także z systemami Linux, macOS, Azure i AWS. Dzięki temu nadaje się do nowoczesnych aplikacji wieloplatformowych przeznaczonych dla .NET 10. Więcej szczegółów można znaleźć w przeglądzie instalacji.
Dodaj przestrzeń nazw na początku pliku C#, aby uzyskać dostęp do wszystkich elementów sterujących i metod PDF:
using IronPdf;using IronPdf;Imports IronPdf!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101000101111101010011010101000100000101010010010101000100010101000100010111110101011101001001010100010010000101111101010000010100100100111101000100010101010100001101010100010111110101010001010010010010010100000101001100010111110100001001001100010011110100001101001011--}
Jak połączyć dwa pliki PDF?
Poniższy przykład w języku C# ładuje dwa dokumenty PDF i łączy je w jeden plik wyjściowy:
using IronPdf;
var pdf1 = PdfDocument.FromFile("Report1.pdf");
var pdf2 = PdfDocument.FromFile("Report2.pdf");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
mergedPdf.SaveAs("MergedReport.pdf");using IronPdf;
var pdf1 = PdfDocument.FromFile("Report1.pdf");
var pdf2 = PdfDocument.FromFile("Report2.pdf");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
mergedPdf.SaveAs("MergedReport.pdf");Imports IronPdf
Dim pdf1 = PdfDocument.FromFile("Report1.pdf")
Dim pdf2 = PdfDocument.FromFile("Report2.pdf")
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
mergedPdf.SaveAs("MergedReport.pdf")Powoduje to załadowanie dwóch plików PDF przy użyciu FromFile z dysku, połączenie ich za pomocą metody statycznej Merge oraz zapisanie wyniku. Połączenie zachowuje całe formatowanie, osadzone pola formularzy, metadane, zakładki i adnotacje. Metoda ta działa z plikami PDF utworzonymi z różnych źródeł, niezależnie od tego, czy zostały one przekonwertowane z HTML, wygenerowane z adresów URL, czy też utworzone na podstawie obrazów.
Jak wygląda plik PDF z tłumaczeniem?

Jak połączyć wiele plików PDF jednocześnie?
Jeśli chcesz połączyć więcej niż dwa dokumenty, przekaż tablicę obiektów PdfDocument do metody Merge:
using IronPdf;
string[] pdfFiles = { "January.pdf", "February.pdf", "March.pdf", "April.pdf" };
var pdfs = pdfFiles.Select(PdfDocument.FromFile).ToArray();
var merged = PdfDocument.Merge(pdfs);
merged.SaveAs("QuarterlyReport.pdf");using IronPdf;
string[] pdfFiles = { "January.pdf", "February.pdf", "March.pdf", "April.pdf" };
var pdfs = pdfFiles.Select(PdfDocument.FromFile).ToArray();
var merged = PdfDocument.Merge(pdfs);
merged.SaveAs("QuarterlyReport.pdf");Imports IronPdf
Dim pdfFiles As String() = {"January.pdf", "February.pdf", "March.pdf", "April.pdf"}
Dim pdfs = pdfFiles.Select(AddressOf PdfDocument.FromFile).ToArray()
Dim merged = PdfDocument.Merge(pdfs)
merged.SaveAs("QuarterlyReport.pdf")Powoduje to załadowanie wielu plików PDF do obiektów PdfDocument i połączenie ich w ramach jednej operacji. Metoda statyczna Merge przyjmuje tablice do przetwarzania wsadowego. Wystarczy kilka wierszy kodu C#, aby przetworzyć wiele plików PDF jednocześnie.
Aby zwiększyć przepustowość podczas pracy z wieloma plikami, warto rozważyć operacje asynchroniczne lub przetwarzanie równoległe. Obsługa wielowątkowości w IronPDF zapewnia stałą wydajność nawet przy dużych partiach dokumentów. Podczas pracy z operacjami wymagającymi dużej ilości pamięci ważne jest właściwe zarządzanie zasobami i usuwanie obiektów PdfDocument.
Jak scalić cały folder plików PDF z obsługą błędów?
Poniższy przykład odczytuje wszystkie pliki PDF z katalogu, sortuje je według nazwy w celu uzyskania spójnej kolejności i łączy je z obsługą błędów dla poszczególnych plików:
using IronPdf;
using System.IO;
string pdfDirectory = @"C:\Reports\Monthly\";
string[] pdfFiles = Directory.GetFiles(pdfDirectory, "*.pdf");
Array.Sort(pdfFiles);
var pdfs = new List<PdfDocument>();
foreach (var file in pdfFiles)
{
try
{
pdfs.Add(PdfDocument.FromFile(file));
Console.WriteLine($"Loaded: {Path.GetFileName(file)}");
}
catch (Exception ex)
{
Console.WriteLine($"Error loading {file}: {ex.Message}");
}
}
if (pdfs.Count > 0)
{
var merged = PdfDocument.Merge(pdfs.ToArray());
merged.MetaData.Author = "Report Generator";
merged.MetaData.CreationDate = DateTime.Now;
merged.MetaData.Title = "Consolidated Monthly Reports";
merged.SaveAs("ConsolidatedReports.pdf");
Console.WriteLine("Merge completed successfully!");
}using IronPdf;
using System.IO;
string pdfDirectory = @"C:\Reports\Monthly\";
string[] pdfFiles = Directory.GetFiles(pdfDirectory, "*.pdf");
Array.Sort(pdfFiles);
var pdfs = new List<PdfDocument>();
foreach (var file in pdfFiles)
{
try
{
pdfs.Add(PdfDocument.FromFile(file));
Console.WriteLine($"Loaded: {Path.GetFileName(file)}");
}
catch (Exception ex)
{
Console.WriteLine($"Error loading {file}: {ex.Message}");
}
}
if (pdfs.Count > 0)
{
var merged = PdfDocument.Merge(pdfs.ToArray());
merged.MetaData.Author = "Report Generator";
merged.MetaData.CreationDate = DateTime.Now;
merged.MetaData.Title = "Consolidated Monthly Reports";
merged.SaveAs("ConsolidatedReports.pdf");
Console.WriteLine("Merge completed successfully!");
}Imports IronPdf
Imports System.IO
Dim pdfDirectory As String = "C:\Reports\Monthly\"
Dim pdfFiles As String() = Directory.GetFiles(pdfDirectory, "*.pdf")
Array.Sort(pdfFiles)
Dim pdfs As New List(Of PdfDocument)()
For Each file In pdfFiles
Try
pdfs.Add(PdfDocument.FromFile(file))
Console.WriteLine($"Loaded: {Path.GetFileName(file)}")
Catch ex As Exception
Console.WriteLine($"Error loading {file}: {ex.Message}")
End Try
Next
If pdfs.Count > 0 Then
Dim merged As PdfDocument = PdfDocument.Merge(pdfs.ToArray())
merged.MetaData.Author = "Report Generator"
merged.MetaData.CreationDate = DateTime.Now
merged.MetaData.Title = "Consolidated Monthly Reports"
merged.SaveAs("ConsolidatedReports.pdf")
Console.WriteLine("Merge completed successfully!")
End IfJak wygląda połączony plik PDF zawierający wiele plików?

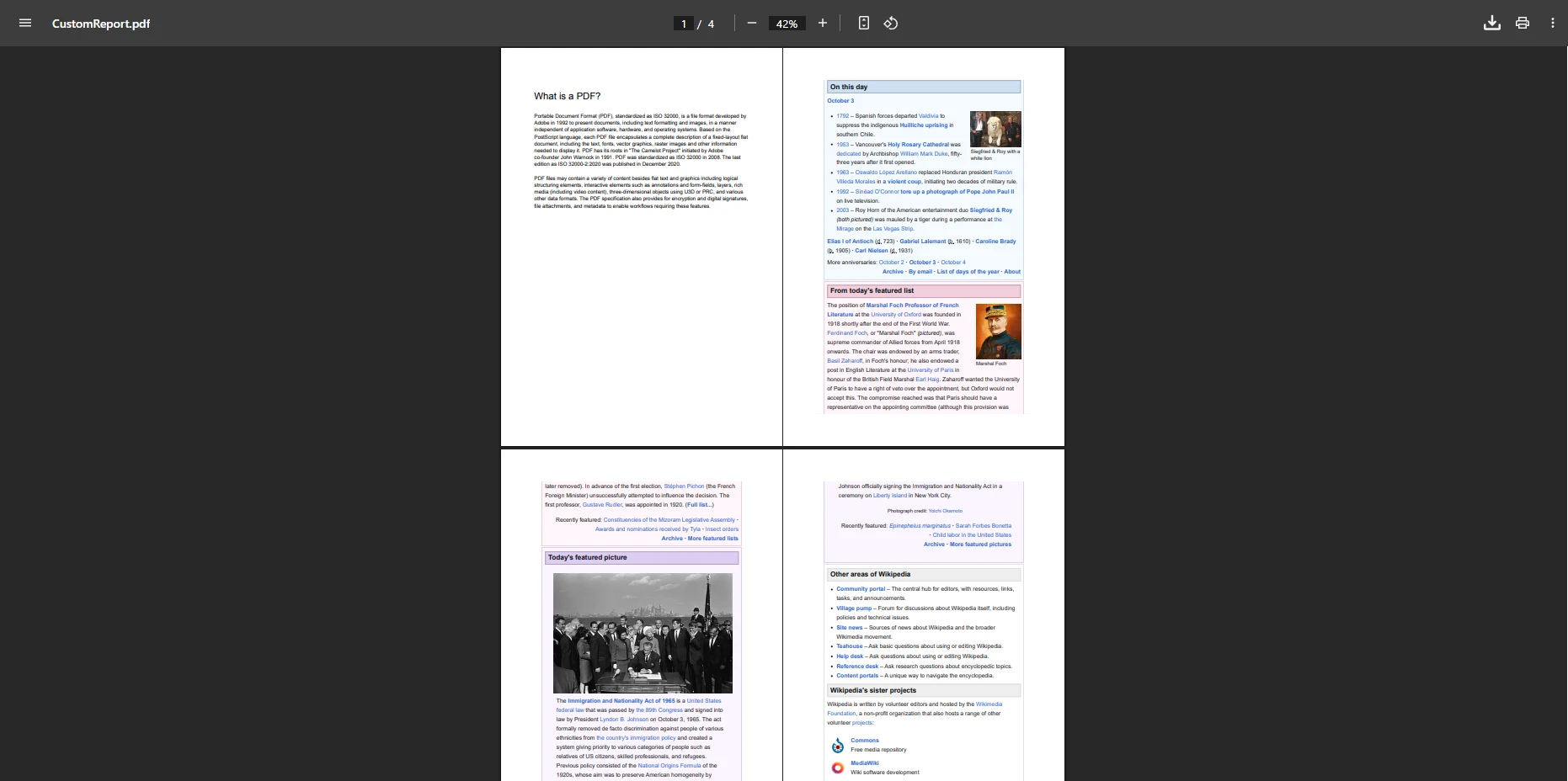
Jak połączyć określone strony z dokumentów PDF?
Przed scaleniem można wyodrębnić pojedyncze strony lub zakresy stron. CopyPage pobiera jedną stronę według indeksu zaczynającego się od zera, podczas gdy CopyPages pobiera zakres:
using IronPdf;
var doc1 = PdfDocument.FromFile("PdfOne.pdf");
var doc2 = PdfDocument.FromFile("PdfTwo.pdf");
var firstPage = doc2.CopyPage(0);
var selectedRange = doc1.CopyPages(2, 4);
var result = PdfDocument.Merge(firstPage, selectedRange);
result.SaveAs("CustomPdf.pdf");using IronPdf;
var doc1 = PdfDocument.FromFile("PdfOne.pdf");
var doc2 = PdfDocument.FromFile("PdfTwo.pdf");
var firstPage = doc2.CopyPage(0);
var selectedRange = doc1.CopyPages(2, 4);
var result = PdfDocument.Merge(firstPage, selectedRange);
result.SaveAs("CustomPdf.pdf");Imports IronPdf
Dim doc1 = PdfDocument.FromFile("PdfOne.pdf")
Dim doc2 = PdfDocument.FromFile("PdfTwo.pdf")
Dim firstPage = doc2.CopyPage(0)
Dim selectedRange = doc1.CopyPages(2, 4)
Dim result = PdfDocument.Merge(firstPage, selectedRange)
result.SaveAs("CustomPdf.pdf")W ten sposób powstaje plik wyjściowy zawierający wyłącznie istotne strony z większych dokumentów źródłowych. API do manipulacji stronami zapewnia precyzyjną kontrolę nad strukturą dokumentu. W razie potrzeby można również obracać strony, dodawać numery stron lub wstawiać podziały stron.
Jak złożyć niestandardowy dokument z wielu źródeł?
Poniższy przykład wyodrębnia fragmenty z trzech oddzielnych dokumentów — umowy, załącznika i pliku warunków — i łączy je w pakiet docelowy:
using IronPdf;
var contract = PdfDocument.FromFile("Contract.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
var terms = PdfDocument.FromFile("Terms.pdf");
// Extract specific sections
var contractPages = contract.CopyPages(0, 5); // First 6 pages
var appendixCover = appendix.CopyPage(0); // Cover page only
var termsHighlight = terms.CopyPages(3, 4); // Pages 4-5
// Merge selected pages
var customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight);
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12);
customDoc.SaveAs("ContractPackage.pdf");using IronPdf;
var contract = PdfDocument.FromFile("Contract.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
var terms = PdfDocument.FromFile("Terms.pdf");
// Extract specific sections
var contractPages = contract.CopyPages(0, 5); // First 6 pages
var appendixCover = appendix.CopyPage(0); // Cover page only
var termsHighlight = terms.CopyPages(3, 4); // Pages 4-5
// Merge selected pages
var customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight);
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12);
customDoc.SaveAs("ContractPackage.pdf");Imports IronPdf
Dim contract = PdfDocument.FromFile("Contract.pdf")
Dim appendix = PdfDocument.FromFile("Appendix.pdf")
Dim terms = PdfDocument.FromFile("Terms.pdf")
' Extract specific sections
Dim contractPages = contract.CopyPages(0, 5) ' First 6 pages
Dim appendixCover = appendix.CopyPage(0) ' Cover page only
Dim termsHighlight = terms.CopyPages(3, 4) ' Pages 4-5
' Merge selected pages
Dim customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight)
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12)
customDoc.SaveAs("ContractPackage.pdf")Jak wyglądają pliki PDF, z których pochodzi tekst?
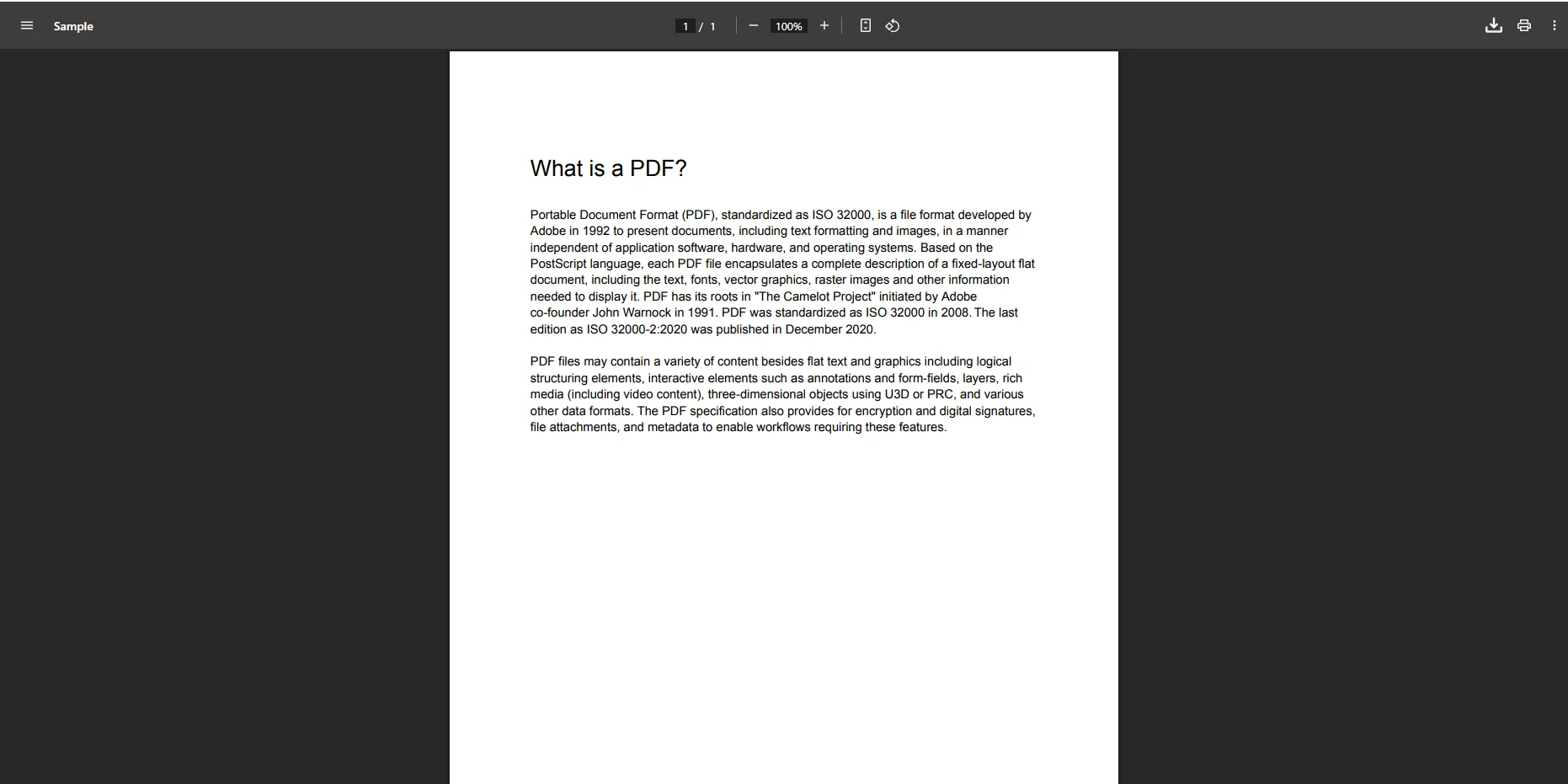
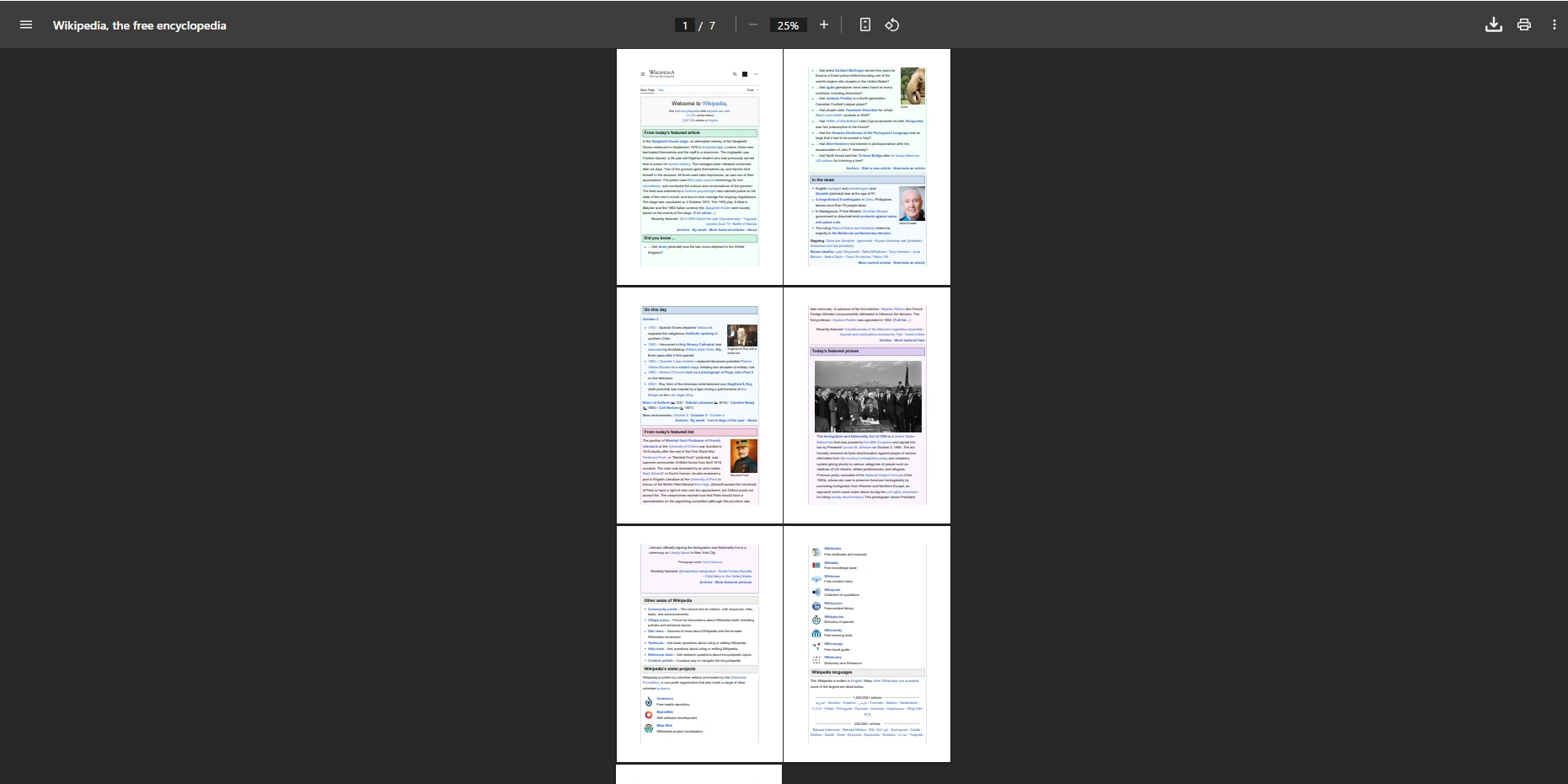
Jak scalanie poszczególnych stron wpływa na wynik?
Jak scalic dokumenty PDF ze strumieni pamięci?
Gdy aplikacja odbiera dane PDF jako tablice bajtów — z przesłanych plików, rekordów bazy danych lub odpowiedzi usług internetowych — można je scalić bezpośrednio z pamięci bez ingerencji w system plików:
using IronPdf;
using System.IO;
using var stream1 = new MemoryStream(File.ReadAllBytes("Doc1.pdf"));
using var stream2 = new MemoryStream(File.ReadAllBytes("Doc2.pdf"));
var pdf1 = new PdfDocument(stream1);
var pdf2 = new PdfDocument(stream2);
var merged = PdfDocument.Merge(pdf1, pdf2);
merged.SaveAs("Output.pdf");using IronPdf;
using System.IO;
using var stream1 = new MemoryStream(File.ReadAllBytes("Doc1.pdf"));
using var stream2 = new MemoryStream(File.ReadAllBytes("Doc2.pdf"));
var pdf1 = new PdfDocument(stream1);
var pdf2 = new PdfDocument(stream2);
var merged = PdfDocument.Merge(pdf1, pdf2);
merged.SaveAs("Output.pdf");Imports IronPdf
Imports System.IO
Using stream1 As New MemoryStream(File.ReadAllBytes("Doc1.pdf"))
Using stream2 As New MemoryStream(File.ReadAllBytes("Doc2.pdf"))
Dim pdf1 = New PdfDocument(stream1)
Dim pdf2 = New PdfDocument(stream2)
Dim merged = PdfDocument.Merge(pdf1, pdf2)
merged.SaveAs("Output.pdf")
End Using
End UsingTen wzorzec doskonale nadaje się do aplikacji ASP.NET przetwarzających przesłane pliki oraz do wdrożeń w chmurze, gdzie bezpośredni dostęp do systemu plików jest ograniczony. To samo podejście sprawdza się podczas pobierania plików z Azure Blob Storage lub wywoływania zewnętrznych usług internetowych, które zwracają surowe bajty PDF.
Kiedy należy używać strumieni pamięci do łączenia plików PDF?
Strumienie pamięci sprawdzają się w następujących sytuacjach:
- Praca z plikami przesłanymi do aplikacji internetowych
- Przetwarzanie plików PDF pobranych z pól BLOB bazy danych
- Działanie w środowiskach kontenerowych bez systemu plików z prawem do zapisu
- Wdrażanie bezpiecznego przetwarzania dokumentów bez tworzenia plików tymczasowych na dysku
- Tworzenie mikrousług przetwarzających pliki PDF od początku do końca w pamięci
Jak wygląda rzeczywisty proces tworzenia raportów w formacie PDF?
Poniższy przykład generuje dynamiczną stronę tytułową HTML, ładuje istniejące sekcje raportu, nakłada poufny znak wodny, łączy wszystko w odpowiedniej kolejności i zabezpiecza wynik:
using IronPdf;
using System;
var reportDate = DateTime.Now;
var quarter = $"Q{(int)Math.Ceiling(reportDate.Month / 3.0)}";
var coverHtml = $@"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>";
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
var dynamicCover = renderer.RenderHtmlAsPdf(coverHtml);
var executive = PdfDocument.FromFile("ExecutiveSummary.pdf");
var financial = PdfDocument.FromFile("FinancialData.pdf");
var charts = PdfDocument.FromFile("Charts.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>");
var fullReport = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix);
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}";
fullReport.MetaData.Author = "Finance Department";
fullReport.MetaData.Subject = "Quarterly Financial Performance";
fullReport.MetaData.CreationDate = reportDate;
fullReport.AddTextHeaders(
$"{quarter} Financial Report",
IronPdf.Editing.FontFamily.Arial, 10);
fullReport.AddTextFooters(
"Page {page} of {total-pages} | Confidential",
IronPdf.Editing.FontFamily.Arial, 8);
fullReport.SecuritySettings.UserPassword = "reader123";
fullReport.SecuritySettings.OwnerPassword = "admin456";
fullReport.SecuritySettings.AllowUserPrinting = true;
fullReport.SecuritySettings.AllowUserCopyPasteContent = false;
fullReport.CompressImages(90);
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf");
Console.WriteLine($"Report generated: {fullReport.PageCount} pages");using IronPdf;
using System;
var reportDate = DateTime.Now;
var quarter = $"Q{(int)Math.Ceiling(reportDate.Month / 3.0)}";
var coverHtml = $@"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>";
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
var dynamicCover = renderer.RenderHtmlAsPdf(coverHtml);
var executive = PdfDocument.FromFile("ExecutiveSummary.pdf");
var financial = PdfDocument.FromFile("FinancialData.pdf");
var charts = PdfDocument.FromFile("Charts.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>");
var fullReport = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix);
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}";
fullReport.MetaData.Author = "Finance Department";
fullReport.MetaData.Subject = "Quarterly Financial Performance";
fullReport.MetaData.CreationDate = reportDate;
fullReport.AddTextHeaders(
$"{quarter} Financial Report",
IronPdf.Editing.FontFamily.Arial, 10);
fullReport.AddTextFooters(
"Page {page} of {total-pages} | Confidential",
IronPdf.Editing.FontFamily.Arial, 8);
fullReport.SecuritySettings.UserPassword = "reader123";
fullReport.SecuritySettings.OwnerPassword = "admin456";
fullReport.SecuritySettings.AllowUserPrinting = true;
fullReport.SecuritySettings.AllowUserCopyPasteContent = false;
fullReport.CompressImages(90);
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf");
Console.WriteLine($"Report generated: {fullReport.PageCount} pages");Imports IronPdf
Imports System
Module Program
Sub Main()
Dim reportDate As DateTime = DateTime.Now
Dim quarter As String = $"Q{CInt(Math.Ceiling(reportDate.Month / 3.0))}"
Dim coverHtml As String = $"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>"
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
Dim dynamicCover As PdfDocument = renderer.RenderHtmlAsPdf(coverHtml)
Dim executive As PdfDocument = PdfDocument.FromFile("ExecutiveSummary.pdf")
Dim financial As PdfDocument = PdfDocument.FromFile("FinancialData.pdf")
Dim charts As PdfDocument = PdfDocument.FromFile("Charts.pdf")
Dim appendix As PdfDocument = PdfDocument.FromFile("Appendix.pdf")
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>")
Dim fullReport As PdfDocument = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix)
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}"
fullReport.MetaData.Author = "Finance Department"
fullReport.MetaData.Subject = "Quarterly Financial Performance"
fullReport.MetaData.CreationDate = reportDate
fullReport.AddTextHeaders($"{quarter} Financial Report", IronPdf.Editing.FontFamily.Arial, 10)
fullReport.AddTextFooters("Page {page} of {total-pages} | Confidential", IronPdf.Editing.FontFamily.Arial, 8)
fullReport.SecuritySettings.UserPassword = "reader123"
fullReport.SecuritySettings.OwnerPassword = "admin456"
fullReport.SecuritySettings.AllowUserPrinting = True
fullReport.SecuritySettings.AllowUserCopyPasteContent = False
fullReport.CompressImages(90)
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf")
Console.WriteLine($"Report generated: {fullReport.PageCount} pages")
End Sub
End ModulePokazuje to scalanie dokumentów w określonej kolejności, dodawanie metadanych PDF, stosowanie znaków wodnych oraz zabezpieczanie wyników hasłem. Zarządzanie metadanymi jest ważne dla organizacji dokumentów i zgodności z przepisami. Aby uzyskać informacje na temat wyników zgodnych ze standardami archiwizacji, zapoznaj się z przewodnikiem dotyczącym zgodności z PDF/A.
Dlaczego kolejność dokumentów ma znaczenie podczas scalania?
Kolejność dokumentów ma bezpośredni wpływ na wrażenia czytelnika i strukturę techniczną:
- Płynność nawigacji i dokładność spisu treści zależą od kolejności sekcji
- Aby zachować ciągłość numeracji stron, wszystkie sekcje muszą pojawiać się w zamierzonej kolejności
- Spójność nagłówków i stopek w połączonych sekcjach zależy od właściwego porządku
- Hierarchia zakładek i nawigacja czytelnika są zgodne z sekwencją scalania
- Kolejność tabulatorów w polach formularzy w interaktywnych plikach PDF dziedziczy pozycję w dokumencie
Zawsze należy określić jasną kolejność sekcji przed wywołaniem Merge, tak aby tekst był logiczny od początku do końca.
Jakie są najlepsze praktyki dotyczące łączenia plików PDF w języku C#?
Przestrzeganie kilku wytycznych gwarantuje, że połączone pliki PDF będą niezawodne w środowisku produkcyjnym:
| Ćwiczenie | Dlaczego to ma znaczenie | Wytyczne |
|---|---|---|
| Sprawdź poprawność plików wejściowych przed ich załadowaniem | Zapobiega wyjątkom odwołania do wartości null w przypadku brakujących plików | Użyj File.Exists() przed wywołaniem FromFile() |
| Usuń obiekty PdfDocument po użyciu | Uwalnia pamięć natywną zajmowaną przez silnik renderujący | Zakończ używając bloków lub wywołaj .Dispose() |
| W przypadku dużych zbiorów należy stosować przetwarzanie wsadowe | Zapobiega błędom braku pamięci w przypadku dużych zbiorów plików | Połącz w grupy po 10–20 plików, a następnie połącz wyniki partii |
| Kompresuj obrazy po scaleniu | Zmniejsza rozmiar pliku wyjściowego bez widocznej utraty jakości | Wywołaj funkcję CompressImages(85) na scalonym dokumencie |
| Osadź czcionki w dokumentach źródłowych | Zapobiega zastępowaniu czcionek w scalonym wyniku | Przed scaleniem sprawdź, czy pliki PDF źródłowe zawierają osadzone czcionki |
| Zmień nazwy pól formularza przed scaleniem | Należy unikać kolizji nazw pól w dokumentach źródłowych | Wymień i zmień nazwy zduplikowanych nazw pól programowo |
Aby zapoznać się ze standardami branżowymi dotyczącymi struktury i wymiany plików PDF, odwiedź stronę PDF Association. Odpowiedzi społeczności i przykłady kodu są dostępne na Stack Overflow. Strona NuGet Gallery poświęcona IronPDF zawiera listę wszystkich dostępnych wersji oraz informacje o wydaniach. Aby uzyskać informacje na temat zaawansowanych opcji konfiguracyjnych i licencji produkcyjnych, zapoznaj się z sekcją Licencjonowanie IronPDF.
Jak radzisz sobie z typowymi błędami scalania?
Pięć najczęstszych problemów i ich rozwiązania:
- Problemy z pamięcią przy dużych plikach — użyj strumieni pamięci i przetwarzania wsadowego, aby utrzymać zużycie sterty na rozsądnym poziomie. Należy usunąć każdy element
PdfDocument, gdy nie jest już potrzebny. - Problemy z czcionkami w scalonym pliku wyjściowym — przed scaleniem upewnij się, że czcionki są osadzone w źródłowych plikach PDF. Brakujące czcionki powodują zastępowanie lub brak znaków w wyniku.
- Konflikty pól formularza — zmień nazwy zduplikowanych pól programowo przed wywołaniem
Merge. Pola o tej samej nazwie w różnych dokumentach będą miały wspólne wartości. - Wąskie gardła wydajności przy dużych partiach — przejdź na metody asynchroniczne i przetwarzaj pliki równolegle, jeśli pozwalają na to zależności. Przykłady można znaleźć w dokumentacji IronPDF async.
- Ograniczenia bezpieczeństwa w plikach PDF źródłowych — przed próbą odczytania i scalania dokumentów chronionych hasłem należy podać hasła właściciela. Zobacz dokumentację dotyczącą uprawnień do plików PDF.
Jak bezpłatnie rozpocząć korzystanie z IronPDF?
IronPDF pozwala zredukować scalanie plików PDF w języku C# do zaledwie kilku wierszy kodu. Niezależnie od tego, czy łączysz dwa pliki, czy przetwarzasz całe drzewa folderów, biblioteka radzi sobie ze złożonością, podczas gdy Ty skupiasz się na swojej aplikacji .NET 10. Pełen zestaw funkcji obejmuje konwersję HTML do PDF, edycję plików PDF, obsługę formularzy oraz podpisy cyfrowe.
Prosty interfejs API eliminuje skomplikowaną obsługę plików PDF, co czyni go właściwym wyborem dla programistów, którzy potrzebują niezawodnego narzędzia do łączenia plików bez konieczności posiadania dogłębnej wiedzy na temat formatów dokumentów. Od prostych połączeń dwóch plików po wybór na poziomie stron z dziesiątek źródeł — IronPDF zapewnia wszystkie narzędzia do profesjonalnego zarządzania dokumentami. Obsługa wielu platform gwarantuje, że Twoje rozwiązanie będzie działać w systemach Windows, Linux, macOS oraz na platformach chmurowych.
Do użytku produkcyjnego IronPDF oferuje elastyczne licencje z przejrzystymi cenami. W razie potrzeby dostępny jest zespół wsparcia technicznego działający 24 godziny na dobę, 5 dni w tygodniu, oraz obszerna dokumentacja. Porównaj IronPDF z innymi bibliotekami PDF, aby przekonać się, dlaczego zespoły programistów wybierają to rozwiązanie do generowania dokumentów w przedsiębiorstwach.
Rozpocznij bezpłatny okres próbny, aby przetestować scalanie w swoim projekcie — nie jest wymagana karta kredytowa.
Często Zadawane Pytania
Jaki jest najlepszy sposób na scalanie plików PDF w VB.NET?
Najlepszym sposobem na scalanie plików PDF w VB.NET jest użycie biblioteki IronPDF, która zapewnia prostą i wydajną metodę programowego łączenia wielu dokumentów PDF.
W jaki sposób IronPDF może uprościć proces łączenia plików PDF?
IronPDF upraszcza ten proces, oferując potężny interfejs API, który pozwala programistom łatwo łączyć pliki PDF za pomocą zaledwie kilku wierszy kodu VB.NET, oszczędzając czas i zmniejszając złożoność.
Czy w VB.NET mogę łączyć pliki PDF bez utraty formatowania?
Tak, dzięki IronPDF można łączyć pliki PDF przy zachowaniu oryginalnego formatowania, co gwarantuje, że połączony dokument zachowa zamierzony układ i styl.
Czy za pomocą IronPDF można połączyć konkretne strony z różnych plików PDF?
Tak, IronPDF pozwala wybrać konkretne strony z różnych plików PDF do połączenia, co daje elastyczność w tworzeniu niestandardowego, połączonego dokumentu.
Jakie są zalety korzystania z IronPDF do łączenia plików PDF?
IronPDF oferuje wiele zalet, w tym łatwość obsługi, możliwość zachowania integralności dokumentów oraz obsługę szerokiego zakresu operacji na plikach PDF, wykraczających poza ich scalanie.
Czy potrzebuję zaawansowanych umiejętności programistycznych, aby używać IronPDF do łączenia plików PDF?
Nie, nie potrzebujesz zaawansowanych umiejętności programistycznych. IronPDF został zaprojektowany tak, aby był dostępny dla programistów na każdym poziomie zaawansowania, z przejrzystą dokumentacją i prostymi przykładami kodu.
W jaki sposób IronPDF radzi sobie z dużymi plikami PDF podczas scalania?
IronPDF efektywnie obsługuje duże pliki PDF poprzez optymalizację wykorzystania pamięci i szybkości przetwarzania, zapewniając płynne i niezawodne scalanie nawet w przypadku obszernych dokumentów.
Czy istnieje przewodnik krok po kroku dotyczący scalania plików PDF w VB.NET przy użyciu IronPDF?
Tak, samouczek na stronie internetowej IronPDF zawiera szczegółowy przewodnik krok po kroku wraz z przykładami, który pomoże Ci płynnie łączyć pliki PDF w VB.NET.














