
Comment fusionner des fichiers PDF en C#
Fusionner des fichiers PDF en C# ne nécessite que quelques lignes de code avec IronPDF -- chargez vos PDF à l'aide de PdfDocument.FromFile() et combinez-les avec la méthode Merge(), éliminant ainsi la gestion manuelle des documents et la logique de traitement complexe.
La gestion de fichiers et de rapports séparés peut ralentir n'importe quel flux de travail. Passer du temps à combiner manuellement des fichiers PDF ou à se débattre avec des outils obsolètes représente un gaspillage des efforts des développeurs. Ce tutoriel vous montre comment fusionner des fichiers PDF par programmation en C# à l'aide de la bibliothèque IronPDF . Le processus est simple, même pour les documents présentant une mise en forme complexe, des polices intégrées et des champs de formulaire interactifs.
Que vous développiez des applications ASP.NET , travailliez avec Windows Forms ou créiez des solutions cloud, IronPDF vous offre une solution prête à l'emploi pour la manipulation de fichiers PDF et la gestion de documents. Le moteur de rendu de la bibliothèque, basé sur Chrome, garantit une fidélité parfaite au pixel près lors de la fusion de fichiers PDF , préservant ainsi toute la mise en forme, les polices et les données des formulaires.
Comment installer IronPDF pour C# ?
Téléchargez le package NuGet à l'aide de la console du gestionnaire de packages ou de l'interface de ligne de commande .NET :
Install-Package IronPdfInstall-Package IronPdfdotnet add package IronPdfdotnet add package IronPdfIronPDF est compatible avec .NET Framework, .NET Core et .NET 10, ainsi qu'avec Linux, macOS, Azure et AWS. Cela le rend adapté aux applications multiplateformes modernes ciblant .NET 10. Pour plus de détails, consultez la présentation de l'installation .
Ajoutez l'espace de noms en haut de votre fichier C# pour accéder à tous les contrôles et méthodes PDF :
using IronPdf;using IronPdf;Imports IronPdfComment fusionner deux fichiers PDF ?
L'exemple C# suivant charge deux documents PDF et les fusionne en un seul fichier de sortie :
using IronPdf;
var pdf1 = PdfDocument.FromFile("Report1.pdf");
var pdf2 = PdfDocument.FromFile("Report2.pdf");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
mergedPdf.SaveAs("MergedReport.pdf");using IronPdf;
var pdf1 = PdfDocument.FromFile("Report1.pdf");
var pdf2 = PdfDocument.FromFile("Report2.pdf");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
mergedPdf.SaveAs("MergedReport.pdf");Imports IronPdf
Dim pdf1 = PdfDocument.FromFile("Report1.pdf")
Dim pdf2 = PdfDocument.FromFile("Report2.pdf")
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
mergedPdf.SaveAs("MergedReport.pdf")Cela charge deux fichiers PDF à l'aide de FromFile depuis le disque, les combine avec la méthode statique Merge et enregistre le résultat. La fusion préserve l'intégralité de la mise en forme, des champs de formulaire intégrés, des métadonnées, des signets et des annotations. Cette méthode fonctionne avec les fichiers PDF créés à partir de diverses sources, qu'ils soient convertis à partir de HTML, générés à partir d'URL ou produits à partir d'images.
À quoi ressemble le fichier PDF généré ?

Comment fusionner plusieurs fichiers PDF simultanément ?
Lorsque vous devez combiner plus de deux documents, transmettez un tableau d'objets PdfDocument à la méthode Merge :
using IronPdf;
string[] pdfFiles = { "January.pdf", "February.pdf", "March.pdf", "April.pdf" };
var pdfs = pdfFiles.Select(PdfDocument.FromFile).ToArray();
var merged = PdfDocument.Merge(pdfs);
merged.SaveAs("QuarterlyReport.pdf");using IronPdf;
string[] pdfFiles = { "January.pdf", "February.pdf", "March.pdf", "April.pdf" };
var pdfs = pdfFiles.Select(PdfDocument.FromFile).ToArray();
var merged = PdfDocument.Merge(pdfs);
merged.SaveAs("QuarterlyReport.pdf");Imports IronPdf
Dim pdfFiles As String() = {"January.pdf", "February.pdf", "March.pdf", "April.pdf"}
Dim pdfs = pdfFiles.Select(AddressOf PdfDocument.FromFile).ToArray()
Dim merged = PdfDocument.Merge(pdfs)
merged.SaveAs("QuarterlyReport.pdf")Cela charge plusieurs fichiers PDF dans des objets PdfDocument et les combine en une seule opération. La méthode statique Merge accepte les tableaux pour le traitement par lots. Quelques lignes de code C# suffisent pour traiter plusieurs fichiers PDF simultanément.
Pour améliorer le débit lors du traitement de nombreux fichiers, envisagez des opérations asynchrones ou un traitement parallèle. La prise en charge du multithreading d'IronPDF garantit des performances solides même avec des lots de documents volumineux. Lors de l'exécution d'opérations gourmandes en mémoire, une gestion et une suppression appropriées des ressources des objets PdfDocument sont importantes.
Comment fusionner un dossier entier de fichiers PDF en gérant les erreurs ?
L'exemple ci-dessous lit tous les fichiers PDF d'un répertoire, les trie par nom pour un ordre cohérent et les fusionne en gérant les erreurs fichier par fichier :
using IronPdf;
using System.IO;
string pdfDirectory = @"C:\Reports\Monthly\";
string[] pdfFiles = Directory.GetFiles(pdfDirectory, "*.pdf");
Array.Sort(pdfFiles);
var pdfs = new List<PdfDocument>();
foreach (var file in pdfFiles)
{
try
{
pdfs.Add(PdfDocument.FromFile(file));
Console.WriteLine($"Loaded: {Path.GetFileName(file)}");
}
catch (Exception ex)
{
Console.WriteLine($"Error loading {file}: {ex.Message}");
}
}
if (pdfs.Count > 0)
{
var merged = PdfDocument.Merge(pdfs.ToArray());
merged.MetaData.Author = "Report Generator";
merged.MetaData.CreationDate = DateTime.Now;
merged.MetaData.Title = "Consolidated Monthly Reports";
merged.SaveAs("ConsolidatedReports.pdf");
Console.WriteLine("Merge completed successfully!");
}using IronPdf;
using System.IO;
string pdfDirectory = @"C:\Reports\Monthly\";
string[] pdfFiles = Directory.GetFiles(pdfDirectory, "*.pdf");
Array.Sort(pdfFiles);
var pdfs = new List<PdfDocument>();
foreach (var file in pdfFiles)
{
try
{
pdfs.Add(PdfDocument.FromFile(file));
Console.WriteLine($"Loaded: {Path.GetFileName(file)}");
}
catch (Exception ex)
{
Console.WriteLine($"Error loading {file}: {ex.Message}");
}
}
if (pdfs.Count > 0)
{
var merged = PdfDocument.Merge(pdfs.ToArray());
merged.MetaData.Author = "Report Generator";
merged.MetaData.CreationDate = DateTime.Now;
merged.MetaData.Title = "Consolidated Monthly Reports";
merged.SaveAs("ConsolidatedReports.pdf");
Console.WriteLine("Merge completed successfully!");
}Imports IronPdf
Imports System.IO
Dim pdfDirectory As String = "C:\Reports\Monthly\"
Dim pdfFiles As String() = Directory.GetFiles(pdfDirectory, "*.pdf")
Array.Sort(pdfFiles)
Dim pdfs As New List(Of PdfDocument)()
For Each file In pdfFiles
Try
pdfs.Add(PdfDocument.FromFile(file))
Console.WriteLine($"Loaded: {Path.GetFileName(file)}")
Catch ex As Exception
Console.WriteLine($"Error loading {file}: {ex.Message}")
End Try
Next
If pdfs.Count > 0 Then
Dim merged As PdfDocument = PdfDocument.Merge(pdfs.ToArray())
merged.MetaData.Author = "Report Generator"
merged.MetaData.CreationDate = DateTime.Now
merged.MetaData.Title = "Consolidated Monthly Reports"
merged.SaveAs("ConsolidatedReports.pdf")
Console.WriteLine("Merge completed successfully!")
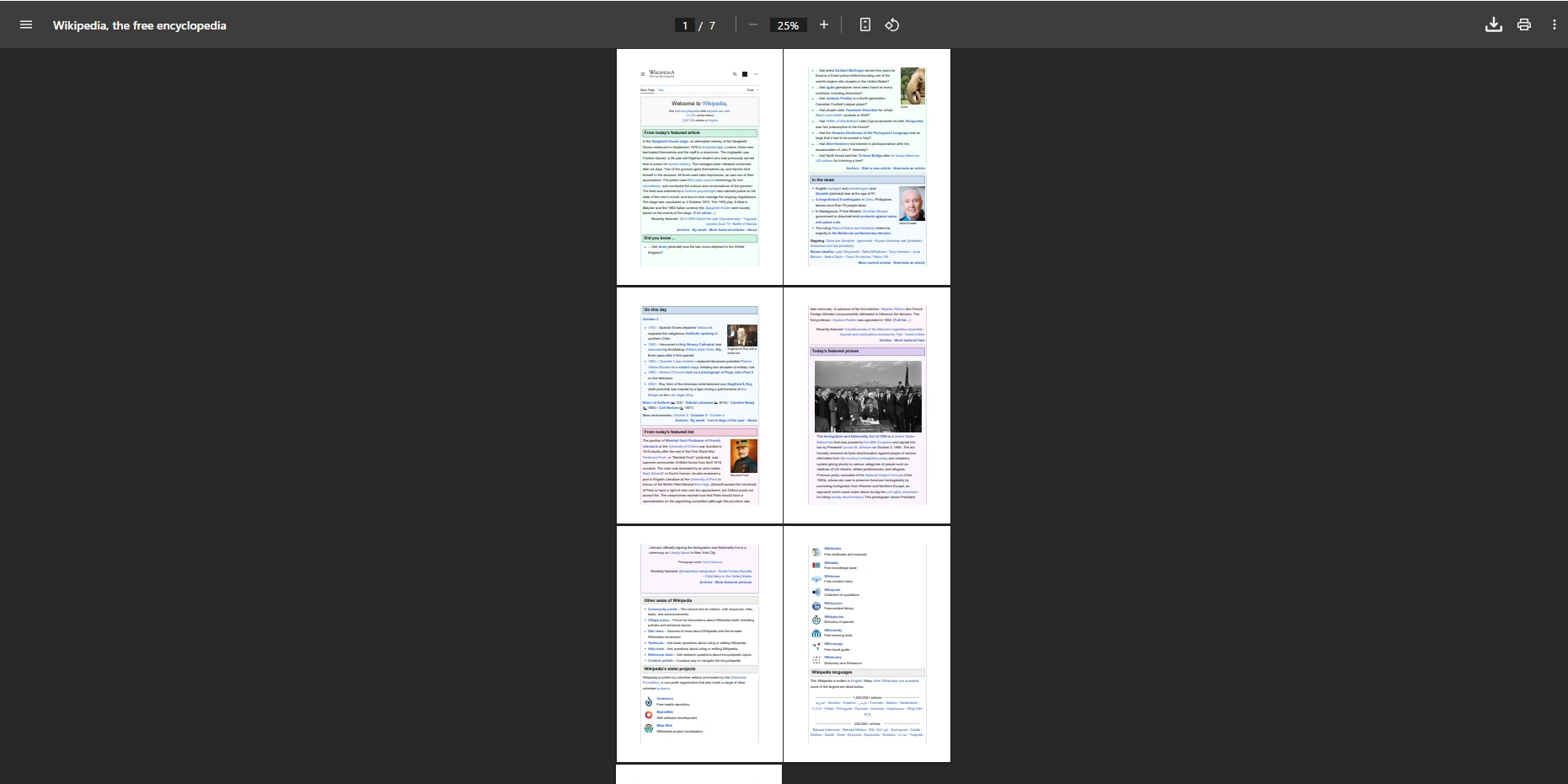
End IfÀ quoi ressemble un PDF fusionné de plusieurs fichiers ?

Comment fusionner des pages spécifiques de documents PDF ?
Vous pouvez extraire des pages individuelles ou des plages de pages avant la fusion. CopyPage extrait une page par index à partir de zéro, tandis que CopyPages extrait une plage :
using IronPdf;
var doc1 = PdfDocument.FromFile("PdfOne.pdf");
var doc2 = PdfDocument.FromFile("PdfTwo.pdf");
var firstPage = doc2.CopyPage(0);
var selectedRange = doc1.CopyPages(2, 4);
var result = PdfDocument.Merge(firstPage, selectedRange);
result.SaveAs("CustomPdf.pdf");using IronPdf;
var doc1 = PdfDocument.FromFile("PdfOne.pdf");
var doc2 = PdfDocument.FromFile("PdfTwo.pdf");
var firstPage = doc2.CopyPage(0);
var selectedRange = doc1.CopyPages(2, 4);
var result = PdfDocument.Merge(firstPage, selectedRange);
result.SaveAs("CustomPdf.pdf");Imports IronPdf
Dim doc1 = PdfDocument.FromFile("PdfOne.pdf")
Dim doc2 = PdfDocument.FromFile("PdfTwo.pdf")
Dim firstPage = doc2.CopyPage(0)
Dim selectedRange = doc1.CopyPages(2, 4)
Dim result = PdfDocument.Merge(firstPage, selectedRange)
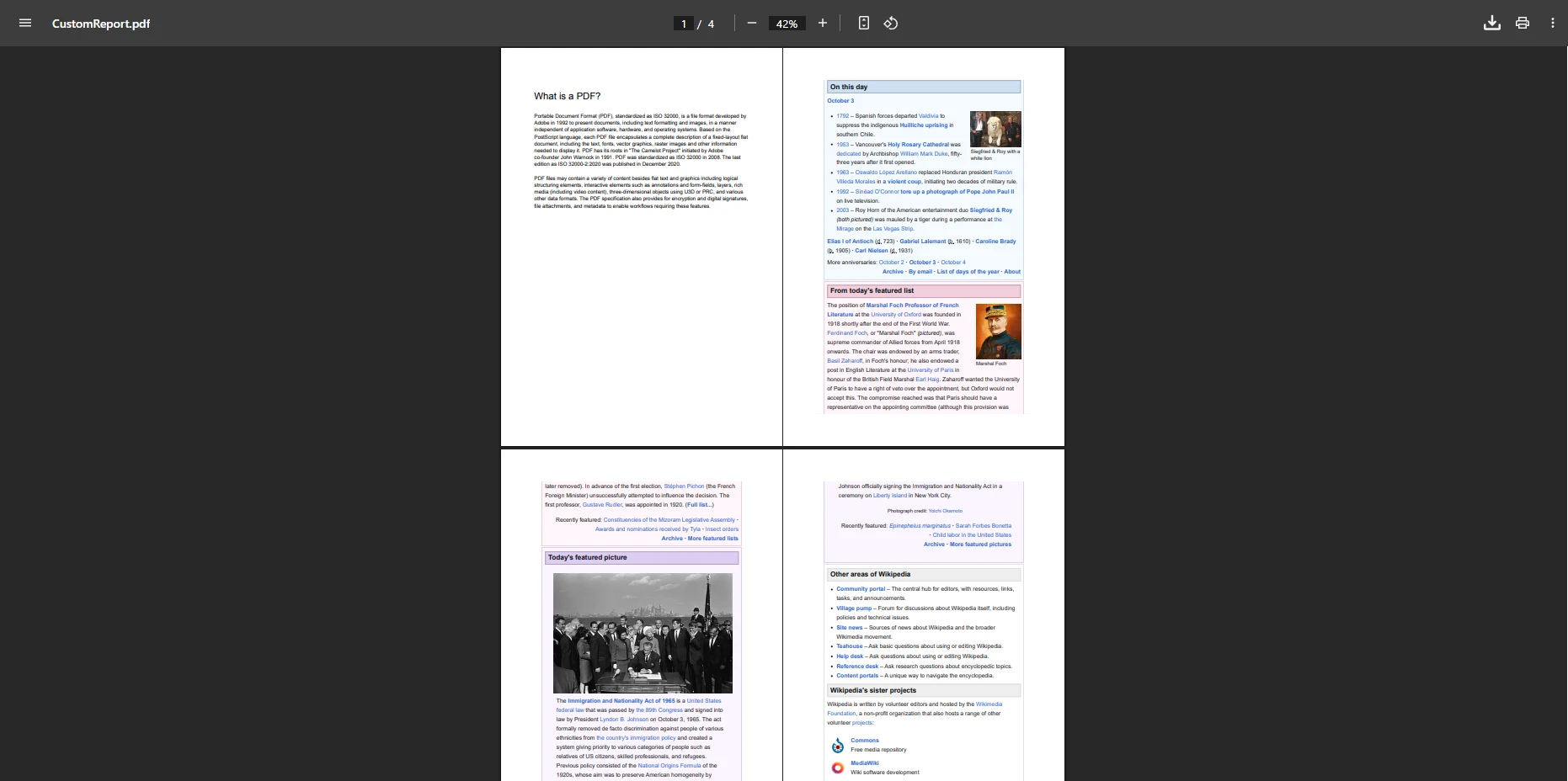
result.SaveAs("CustomPdf.pdf")Cela crée un fichier de sortie contenant uniquement les pages pertinentes des documents sources plus volumineux. L' API de manipulation de pages vous offre un contrôle précis sur la structure du document. Vous pouvez également faire pivoter les pages, ajouter des numéros de page ou insérer des sauts de page selon vos besoins.
Comment créer un document personnalisé à partir de sources multiples ?
L'exemple suivant extrait des sections de trois documents distincts — un contrat, une annexe et un fichier de conditions générales — et les combine dans un package ciblé :
using IronPdf;
var contract = PdfDocument.FromFile("Contract.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
var terms = PdfDocument.FromFile("Terms.pdf");
// Extract specific sections
var contractPages = contract.CopyPages(0, 5); // First 6 pages
var appendixCover = appendix.CopyPage(0); // Cover page only
var termsHighlight = terms.CopyPages(3, 4); // Pages 4-5
// Merge selected pages
var customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight);
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12);
customDoc.SaveAs("ContractPackage.pdf");using IronPdf;
var contract = PdfDocument.FromFile("Contract.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
var terms = PdfDocument.FromFile("Terms.pdf");
// Extract specific sections
var contractPages = contract.CopyPages(0, 5); // First 6 pages
var appendixCover = appendix.CopyPage(0); // Cover page only
var termsHighlight = terms.CopyPages(3, 4); // Pages 4-5
// Merge selected pages
var customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight);
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12);
customDoc.SaveAs("ContractPackage.pdf");Imports IronPdf
Dim contract = PdfDocument.FromFile("Contract.pdf")
Dim appendix = PdfDocument.FromFile("Appendix.pdf")
Dim terms = PdfDocument.FromFile("Terms.pdf")
' Extract specific sections
Dim contractPages = contract.CopyPages(0, 5) ' First 6 pages
Dim appendixCover = appendix.CopyPage(0) ' Cover page only
Dim termsHighlight = terms.CopyPages(3, 4) ' Pages 4-5
' Merge selected pages
Dim customDoc = PdfDocument.Merge(contractPages, appendixCover, termsHighlight)
customDoc.AddTextHeaders(
"Contract Package - {page} of {total-pages}",
IronPdf.Editing.FontFamily.Helvetica, 12)
customDoc.SaveAs("ContractPackage.pdf")À quoi ressemblent les fichiers PDF d'entrée ?
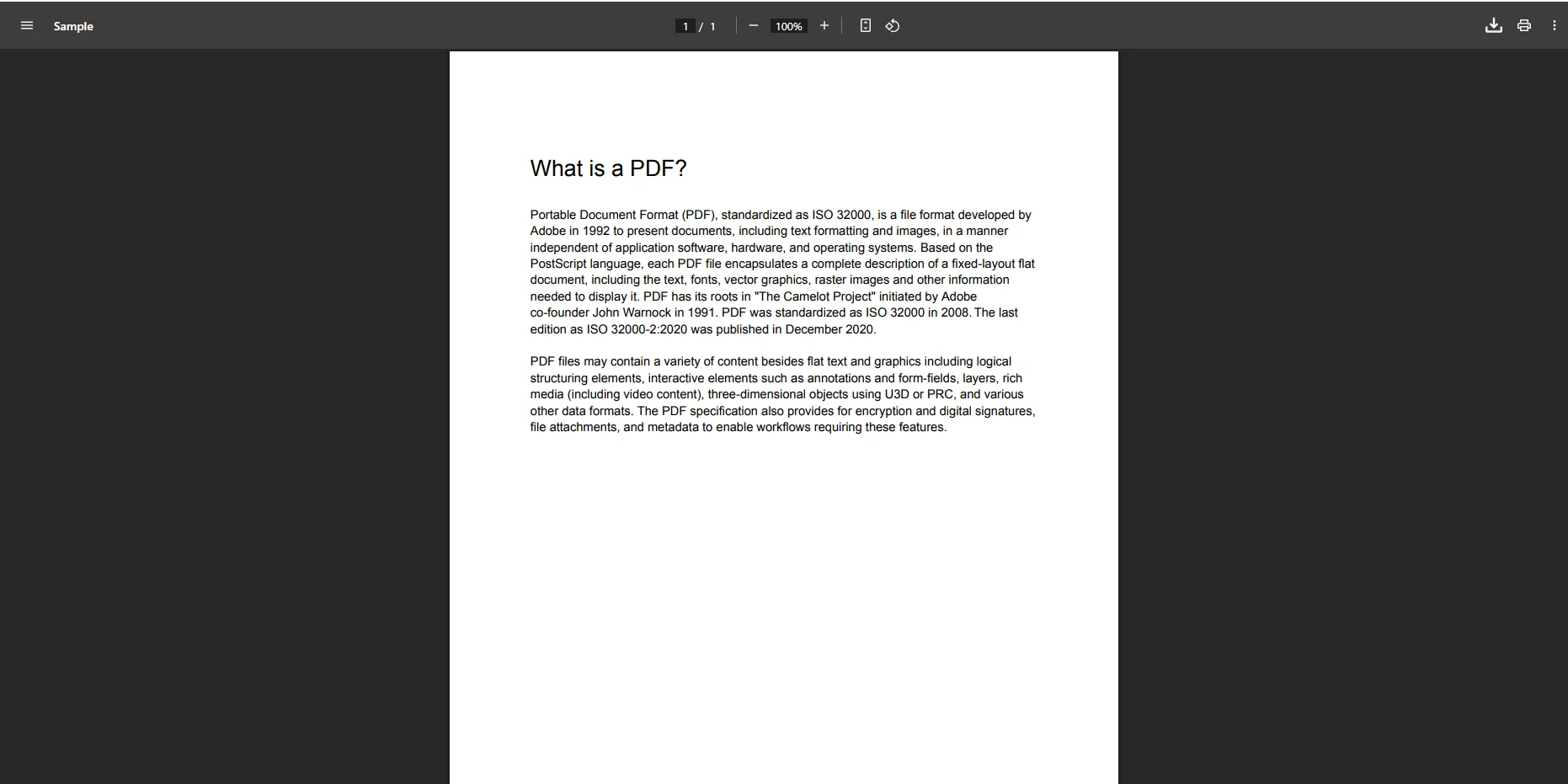
Quel est l'impact de la fusion spécifique à une page sur le résultat ?
Comment fusionner des documents PDF provenant de flux de mémoire ?
Lorsque votre application reçoit des données PDF sous forme de tableaux d'octets (provenant de fichiers téléchargés, d'enregistrements de base de données ou de réponses de services Web), vous pouvez les fusionner directement en mémoire sans accéder au système de fichiers :
using IronPdf;
using System.IO;
using var stream1 = new MemoryStream(File.ReadAllBytes("Doc1.pdf"));
using var stream2 = new MemoryStream(File.ReadAllBytes("Doc2.pdf"));
var pdf1 = new PdfDocument(stream1);
var pdf2 = new PdfDocument(stream2);
var merged = PdfDocument.Merge(pdf1, pdf2);
merged.SaveAs("Output.pdf");using IronPdf;
using System.IO;
using var stream1 = new MemoryStream(File.ReadAllBytes("Doc1.pdf"));
using var stream2 = new MemoryStream(File.ReadAllBytes("Doc2.pdf"));
var pdf1 = new PdfDocument(stream1);
var pdf2 = new PdfDocument(stream2);
var merged = PdfDocument.Merge(pdf1, pdf2);
merged.SaveAs("Output.pdf");Imports IronPdf
Imports System.IO
Using stream1 As New MemoryStream(File.ReadAllBytes("Doc1.pdf"))
Using stream2 As New MemoryStream(File.ReadAllBytes("Doc2.pdf"))
Dim pdf1 = New PdfDocument(stream1)
Dim pdf2 = New PdfDocument(stream2)
Dim merged = PdfDocument.Merge(pdf1, pdf2)
merged.SaveAs("Output.pdf")
End Using
End UsingCe modèle est parfaitement adapté aux applications ASP.NET qui traitent des fichiers téléchargés et aux déploiements cloud où l'accès direct au système de fichiers est restreint. La même approche fonctionne lors de la récupération de fichiers depuis Azure Blob Storage ou lors de l'appel de services Web externes qui renvoient des octets PDF bruts.
Quand faut-il utiliser les flux de mémoire pour la fusion de fichiers PDF ?
Les flux de mémoire sont bien adaptés lorsque :
- Utilisation de fichiers téléchargés dans des applications web
- Traitement des fichiers PDF extraits des champs BLOB de la base de données
- Fonctionnement dans des environnements conteneurisés sans système de fichiers accessible en écriture
- Mise en œuvre d'une gestion sécurisée des documents sans création de fichiers temporaires sur le disque
- Création de microservices qui traitent les fichiers PDF de bout en bout en mémoire
Qu'est-ce qu'un flux de travail concret de compilation de rapports PDF ?
L'exemple suivant génère une page de couverture HTML dynamique, charge les sections de rapport existantes, applique un filigrane de confidentialité, fusionne tous les éléments dans l'ordre et sécurise le résultat :
using IronPdf;
using System;
var reportDate = DateTime.Now;
var quarter = $"Q{(int)Math.Ceiling(reportDate.Month / 3.0)}";
var coverHtml = $@"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>";
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
var dynamicCover = renderer.RenderHtmlAsPdf(coverHtml);
var executive = PdfDocument.FromFile("ExecutiveSummary.pdf");
var financial = PdfDocument.FromFile("FinancialData.pdf");
var charts = PdfDocument.FromFile("Charts.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>");
var fullReport = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix);
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}";
fullReport.MetaData.Author = "Finance Department";
fullReport.MetaData.Subject = "Quarterly Financial Performance";
fullReport.MetaData.CreationDate = reportDate;
fullReport.AddTextHeaders(
$"{quarter} Financial Report",
IronPdf.Editing.FontFamily.Arial, 10);
fullReport.AddTextFooters(
"Page {page} of {total-pages} | Confidential",
IronPdf.Editing.FontFamily.Arial, 8);
fullReport.SecuritySettings.UserPassword = "reader123";
fullReport.SecuritySettings.OwnerPassword = "admin456";
fullReport.SecuritySettings.AllowUserPrinting = true;
fullReport.SecuritySettings.AllowUserCopyPasteContent = false;
fullReport.CompressImages(90);
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf");
Console.WriteLine($"Report generated: {fullReport.PageCount} pages");using IronPdf;
using System;
var reportDate = DateTime.Now;
var quarter = $"Q{(int)Math.Ceiling(reportDate.Month / 3.0)}";
var coverHtml = $@"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>";
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
var dynamicCover = renderer.RenderHtmlAsPdf(coverHtml);
var executive = PdfDocument.FromFile("ExecutiveSummary.pdf");
var financial = PdfDocument.FromFile("FinancialData.pdf");
var charts = PdfDocument.FromFile("Charts.pdf");
var appendix = PdfDocument.FromFile("Appendix.pdf");
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>");
var fullReport = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix);
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}";
fullReport.MetaData.Author = "Finance Department";
fullReport.MetaData.Subject = "Quarterly Financial Performance";
fullReport.MetaData.CreationDate = reportDate;
fullReport.AddTextHeaders(
$"{quarter} Financial Report",
IronPdf.Editing.FontFamily.Arial, 10);
fullReport.AddTextFooters(
"Page {page} of {total-pages} | Confidential",
IronPdf.Editing.FontFamily.Arial, 8);
fullReport.SecuritySettings.UserPassword = "reader123";
fullReport.SecuritySettings.OwnerPassword = "admin456";
fullReport.SecuritySettings.AllowUserPrinting = true;
fullReport.SecuritySettings.AllowUserCopyPasteContent = false;
fullReport.CompressImages(90);
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf");
Console.WriteLine($"Report generated: {fullReport.PageCount} pages");Imports IronPdf
Imports System
Module Program
Sub Main()
Dim reportDate As DateTime = DateTime.Now
Dim quarter As String = $"Q{CInt(Math.Ceiling(reportDate.Month / 3.0))}"
Dim coverHtml As String = $"
<html>
<body style='text-align: center; padding-top: 200px;'>
<h1>Financial Report {quarter} {reportDate.Year}</h1>
<h2>{reportDate:MMMM yyyy}</h2>
<p>Confidential -- Internal Use Only</p>
</body>
</html>"
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
Dim dynamicCover As PdfDocument = renderer.RenderHtmlAsPdf(coverHtml)
Dim executive As PdfDocument = PdfDocument.FromFile("ExecutiveSummary.pdf")
Dim financial As PdfDocument = PdfDocument.FromFile("FinancialData.pdf")
Dim charts As PdfDocument = PdfDocument.FromFile("Charts.pdf")
Dim appendix As PdfDocument = PdfDocument.FromFile("Appendix.pdf")
financial.ApplyWatermark("<h2 style='color: red; opacity: 0.5;'>CONFIDENTIAL</h2>")
Dim fullReport As PdfDocument = PdfDocument.Merge(dynamicCover, executive, financial, charts, appendix)
fullReport.MetaData.Title = $"Financial Report {quarter} {reportDate.Year}"
fullReport.MetaData.Author = "Finance Department"
fullReport.MetaData.Subject = "Quarterly Financial Performance"
fullReport.MetaData.CreationDate = reportDate
fullReport.AddTextHeaders($"{quarter} Financial Report", IronPdf.Editing.FontFamily.Arial, 10)
fullReport.AddTextFooters("Page {page} of {total-pages} | Confidential", IronPdf.Editing.FontFamily.Arial, 8)
fullReport.SecuritySettings.UserPassword = "reader123"
fullReport.SecuritySettings.OwnerPassword = "admin456"
fullReport.SecuritySettings.AllowUserPrinting = True
fullReport.SecuritySettings.AllowUserCopyPasteContent = False
fullReport.CompressImages(90)
fullReport.SaveAs($"Financial_Report_{quarter}_{reportDate.Year}.pdf")
Console.WriteLine($"Report generated: {fullReport.PageCount} pages")
End Sub
End ModuleCeci démontre la fusion de documents dans un ordre spécifique, l'ajout de métadonnées PDF, l'application de filigranes et la sécurisation du résultat par une protection par mot de passe . La gestion des métadonnées est importante pour l'organisation et la conformité des documents. Pour une sortie conforme aux normes d'archivage, consultez le guide de conformité PDF/A .
Pourquoi l'ordre des documents est-il important lors d'une fusion ?
L'ordre des documents influe directement sur l'expérience du lecteur et sur la structure technique :
- La fluidité de la navigation et la précision de la table des matières dépendent de l'ordre des sections.
- La continuité de la numérotation des pages exige que toutes les sections apparaissent dans l'ordre prévu.
- La cohérence des en-têtes et des pieds de page dans les sections fusionnées repose sur un ordre correct.
- La hiérarchie des signets et la navigation du lecteur suivent la séquence de fusion
- L'ordre de tabulation des champs de formulaire dans les PDF interactifs hérite de la position du document
Définissez toujours un ordre de section clair avant d'appeler Merge afin que la sortie se lise logiquement de la couverture à l'annexe.
Quelles sont les meilleures pratiques pour fusionner des fichiers PDF en C# ?
Le respect de quelques règles simples garantit la fiabilité des PDF fusionnés en production :
| Pratique | Pourquoi c'est important | Conseils |
|---|---|---|
| Validez les fichiers d'entrée avant le chargement. | Empêche les exceptions de référence nulle sur les fichiers manquants | Utilisez `File.Exists()` avant d'appeler `FromFile()` |
| Libérez les objets PdfDocument après utilisation | Libère la mémoire native détenue par le moteur de rendu | Enveloppez-le `using` de blocs ou appelez `.Dispose()` |
| Utilisez le traitement par lots pour les grandes collections | Évite les erreurs de mémoire insuffisante sur les grands ensembles de fichiers | Fusionnez les fichiers par groupes de 10 à 20, puis fusionnez les résultats par lots. |
| Compresser les images après fusion | Réduit la taille du fichier de sortie sans perte de qualité visible. | Appelez `CompressImages(85)` sur le document fusionné |
| Incorporer les polices dans les documents sources | Empêche la substitution de polices dans le résultat fusionné | Vérifiez que les fichiers PDF sources contiennent des polices incorporées avant la fusion. |
| Renommez les champs du formulaire avant la fusion. | Évite les conflits de noms de champs entre les documents sources | Énumérer et renommer par programmation les noms de champs en double |
Pour connaître les normes industrielles relatives à la structure et à l'échange de fichiers PDF, consultez le site de la PDF Association . Des réponses de la communauté et des exemples de code sont disponibles sur Stack Overflow . La page NuGet Gallery pour IronPDF répertorie toutes les versions disponibles et les notes de version. Pour les options de configuration avancées et les licences de production, consultez la page relative aux licences IronPDF .
Comment gérez-vous les erreurs de fusion courantes ?
Les cinq problèmes les plus fréquents et leurs solutions :
- Problèmes de mémoire avec les fichiers volumineux -- Utilisez les flux de mémoire et le traitement par lots pour maintenir une utilisation du tas gérable. Supprimez chaque
PdfDocumentaprès qu'il ne soit plus nécessaire. - Problèmes de polices dans le résultat fusionné -- Assurez-vous que les polices sont incorporées dans les PDF sources avant la fusion. L'absence de polices de caractères entraîne des substitutions ou des caractères manquants dans le résultat.
- Conflits de champs de formulaire -- Renommez les noms de champs en double par programmation avant d'appeler
Merge. Les champs portant le même nom dans plusieurs documents partageront les mêmes valeurs. - Goulots d'étranglement des performances sur les grands lots -- Passez aux méthodes asynchrones et traitez les fichiers en parallèle lorsque les dépendances le permettent. Consultez la documentation asynchrone IronPDF pour des exemples.
- Restrictions de sécurité sur les fichiers PDF sources -- Fournissez les mots de passe des propriétaires avant de tenter de lire et de fusionner des documents protégés par mot de passe. Consultez la documentation relative aux autorisations PDF .
Comment débuter avec IronPDF gratuitement ?
IronPDF réduit la fusion de fichiers PDF en C# à quelques lignes de code. Qu'il s'agisse de combiner deux fichiers ou de traiter des arborescences de dossiers entières, la bibliothèque gère la complexité pendant que vous vous concentrez sur votre application .NET 10. L' ensemble des fonctionnalités comprend la conversion HTML vers PDF, l'édition de PDF, la gestion des formulaires et les signatures numériques.
Son API simple élimine les manipulations complexes de PDF, ce qui en fait le choix idéal pour les développeurs qui ont besoin d'une fusion fiable sans expertise approfondie des formats de documents. De la simple combinaison de deux fichiers à la sélection page par page parmi des dizaines de sources, IronPDF fournit tous les outils nécessaires à une gestion documentaire Professional . La compatibilité multiplateforme garantit que votre solution fonctionne sous Windows, Linux, macOS et sur les plateformes cloud.
Pour une utilisation en production, IronPDF propose des licences flexibles avec une tarification transparente. L' équipe d'assistance est disponible 24 h/24 et 5 j/7 , et une documentation complète est à votre disposition en cas de besoin. Comparez IronPDF aux autres bibliothèques PDF pour découvrir pourquoi les équipes de développement le choisissent pour la génération de documents Enterprise .
Démarrez un essai gratuit pour tester la fusion dans votre projet – aucune carte de crédit n'est requise.
Questions Fréquemment Posées
Quelle est la meilleure façon de fusionner des fichiers PDF en VB.NET ?
La meilleure façon de fusionner des fichiers PDF en VB.NET est d'utiliser la bibliothèque IronPDF, qui fournit une méthode simple et efficace pour combiner plusieurs documents PDF de manière programmatique.
Comment IronPDF simplifie-t-il le processus de fusion des PDFs ?
IronPDF simplifie le processus en proposant une API puissante qui permet aux développeurs de fusionner facilement des fichiers PDF avec seulement quelques lignes de code VB.NET, ce qui permet de gagner du temps et de réduire la complexité.
Puis-je fusionner des PDFs sans perdre le formatage en VB.NET ?
Oui, avec IronPDF, vous pouvez fusionner des PDFs tout en préservant le formatage d'origine, garantissant que le document combiné maintient sa mise en page et son style prévus.
Est-il possible de fusionner des pages spécifiques de différents PDFs en using IronPDF ?
Oui, IronPDF vous permet de sélectionner des pages spécifiques de différents PDFs à fusionner, vous offrant ainsi une flexibilité pour créer un document combiné personnalisé.
Quels sont les avantages de l'utilisation d'IronPDF pour fusionner des fichiers PDF ?
IronPDF offre de nombreux avantages, notamment la facilité d'utilisation, la capacité de préserver l'intégrité des documents et le support pour une large gamme de manipulations de PDF au-delà de la fusion.
Ai-je besoin de compétences avancées en programmation pour utiliser IronPDF pour fusionner des PDFs ?
Non, vous n'avez pas besoin de compétences avancées en programmation. IronPDF est conçu pour être accessible aux développeurs de tous niveaux, avec une documentation claire et des exemples de code simples.
Comment IronPDF gère-t-il les grands fichiers PDF lors de la fusion ?
IronPDF gère efficacement les grands fichiers PDF en optimisant l'utilisation de la mémoire et la vitesse de traitement, assurant une fusion fluide et fiable même avec des documents étendus.
Existe-t-il un guide étape par étape pour fusionner des PDFs en VB.NET en using IronPDF ?
Oui, le tutoriel sur le site Web d'IronPDF fournit un guide détaillé étape par étape, accompagné d'exemples, pour vous aider à fusionner des PDFs en VB.NET sans problème.













