
Jak analizować pliki PDF w Javie (samouczek dla programistów)
W tym artykule stworzymy parser plików PDF w Javie przy użyciu biblioteki IronPDF w efektywny sposób.
IronPDF — biblioteka PDF dla języka Java
IronPDF for Java to biblioteka Java do obsługi plików PDF, która umożliwia łatwe i dokładne tworzenie, odczytywanie oraz edycję dokumentów PDF. Oparte jest na sukcesie IronPDF for .NET i zapewnia wydajną funkcjonalność na różnych platformach. IronPDF for Java wykorzystuje IronPdfEngine, który jest szybki i zoptymalizowany pod kątem wydajności.
Dzięki IronPDF można wyodrębniać tekst i obrazy z plików PDF, a także tworzyć pliki PDF z różnych źródeł, w tym ciągów znaków HTML, plików, adresów URL i obrazów. Ponadto można łatwo dodawać nowe treści, wstawiać podpisy za pomocą IronPDF oraz osadzać metadane w dokumentach PDF. IronPDF jest specjalnie zaprojektowany dla Java 8+, Scala i Kotlin i jest kompatybilny z platformami Windows, Linux oraz chmurą.
Jak analizować plik PDF w Javie
- Pobierz bibliotekę Java do analizowania plików PDF
- Załaduj istniejący dokument PDF za pomocą metody
fromFile - Wyodrębnij cały tekst z przeanalizowanego pliku PDF za pomocą metody
extractAllText - Użyj metody
renderUrlAsPdf,aby wyrenderować plik PDF z adresu URL - Wyodrębnij obrazy z przeanalizowanego pliku PDF za pomocą metody
extractAllImages
Tworzenie parsera plików PDF przy użyciu IronPDF w programie Java
Wymagania wstępne
Aby stworzyć projekt parsowania plików PDF w Javie, potrzebne będą następujące narzędzia:
- Środowisko IDE dla języka Java: Można używać dowolnego środowiska IDE obsługującego język Java. Do tworzenia oprogramowania dostępnych jest wiele środowisk IDE dla języka Java. W tym samouczku zostanie użyte środowisko IntelliJ IDE. Można używać NetBeans, Eclipse itp.
- Projekt Maven: Maven to menedżer zależności, który umożliwia kontrolę nad projektem Java. Maven dla Javy można pobrać z oficjalnej strony internetowej Maven. Środowisko programistyczne IntelliJ Java posiada wbudowaną obsługę Maven.
-
IronPDF for Java — IronPDF for Java można pobrać i zainstalować na wiele sposobów.
-
Dodawanie zależności IronPDF w pliku
pom.xmlw projekcie Maven.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Odwiedź stronę repozytorium Maven, aby uzyskać najnowszy pakiet IronPDF for Java.
- Bezpośrednie pobranie z oficjalnej strony pobierania Iron Software.
- Zainstaluj IronPDF ręcznie, używając pliku JAR w swojej prostej aplikacji Java.
-
-
Slf4j-Simple: Ta zależność jest również wymagana do umieszczania treści w istniejącym dokumencie. Można ją dodać za pomocą menedżera zależności Maven w IntelliJ lub pobrać bezpośrednio ze strony internetowej Maven. Dodaj następującą zależność do pliku
pom.xml:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Dodawanie niezbędnych importów
Po zainstalowaniu wszystkich wymaganych komponentów pierwszym krokiem jest zaimportowanie niezbędnych pakietów IronPDF do pracy z dokumentami PDF. Dodaj następujący kod na początku pliku Main.java:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Klucz licencyjny
Niektóre metody dostępne w IronPDF wymagają licencji do korzystania. Możesz kupić licencję lub wypróbować IronPDF za darmo w ramach bezpłatnej wersji próbnej. Klucz można ustawić w następujący sposób:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Krok 1: Przetworzenie istniejącego dokumentu PDF
Do analizowania istniejącego dokumentu w celu wyodrębnienia treści służy klasa PdfDocument. Jej statyczna metoda fromFile służy do analizowania pliku PDF z określonej ścieżki o określonej nazwie w programie Java. Kod wygląda następująco:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));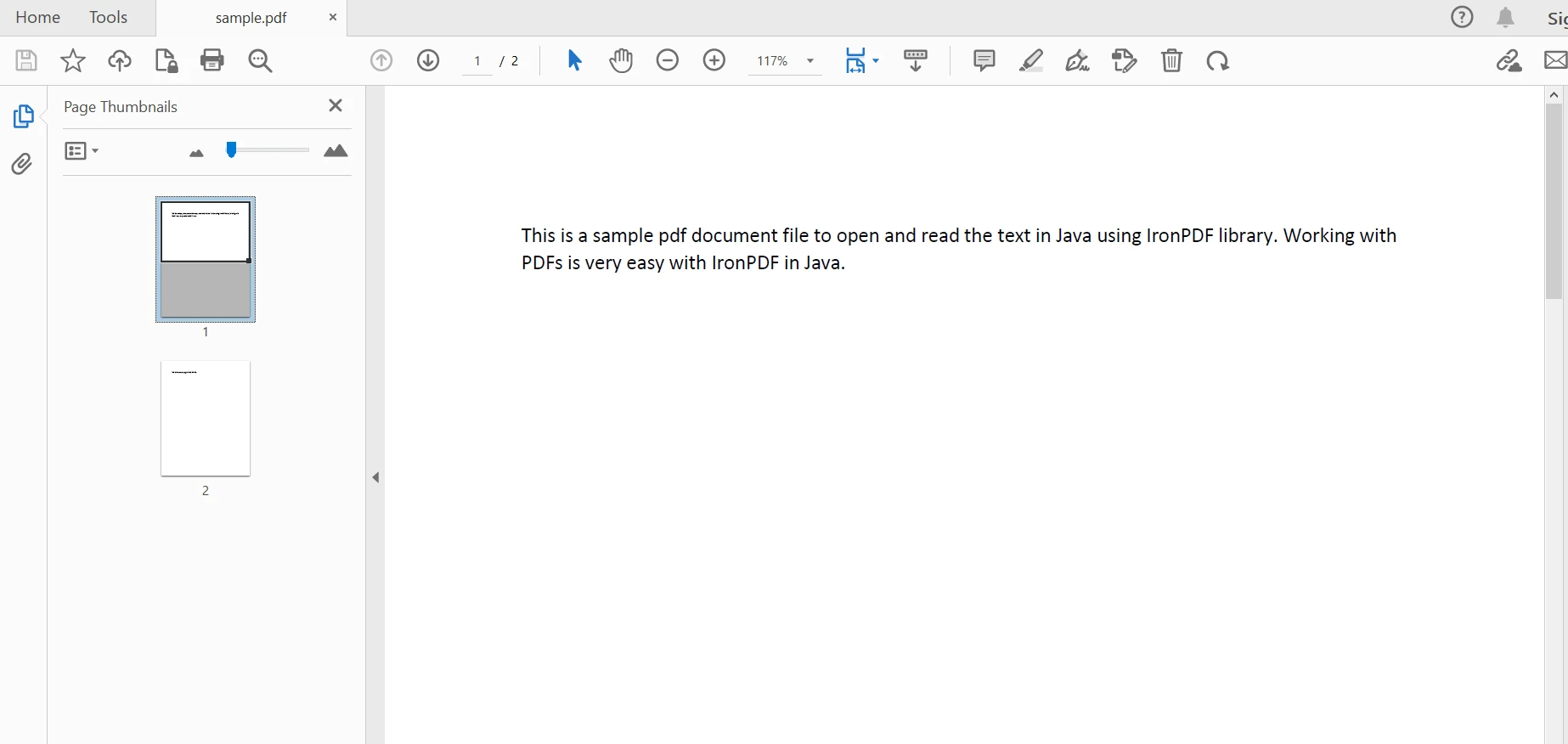 Przeanalizowany dokument
Przeanalizowany dokument
Krok 2: Wyodrębnij dane tekstowe z przeanalizowanego pliku PDF
IronPDF for Java zapewnia łatwą metodę wyodrębniania tekstu z dokumentów PDF. Poniżej znajduje się fragment kodu służący do wyodrębniania danych tekstowych z pliku PDF:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();Powyższy kod generuje poniższy wynik:
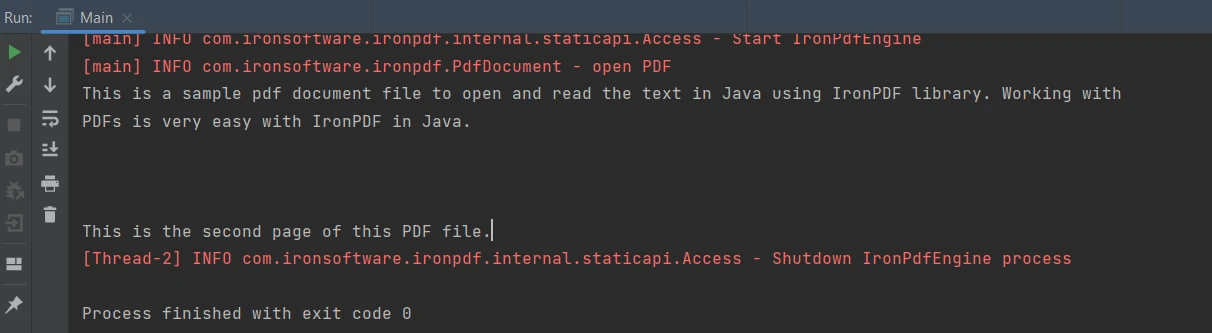 Wynik
Wynik
Krok 3: Wyodrębnianie danych tekstowych z adresów URL lub ciągów HTML
Możliwości IronPDF for Java nie ograniczają się tylko do istniejących plików PDF, ale obejmują również tworzenie i analizowanie nowych plików w celu wyodrębnienia treści. W tym samouczku utworzymy plik PDF na podstawie adresu URL i wyodrębnimy z niego treść. Poniższy przykład pokazuje, jak wykonać to zadanie:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}Oto wynik:
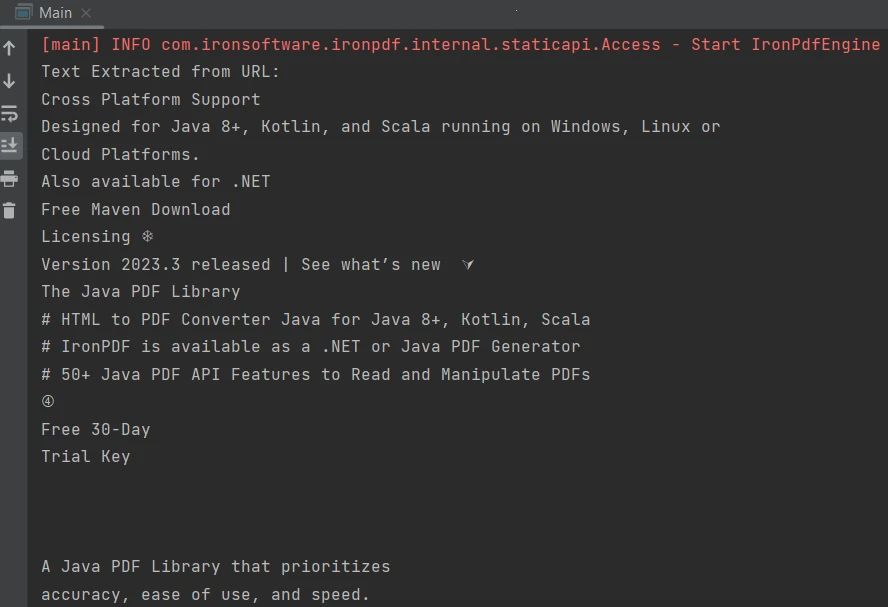 Wynik
Wynik
Krok 4: Wyodrębnij obrazy z przeanalizowanego dokumentu PDF
IronPDF oferuje również łatwą opcję wyodrębniania wszystkich obrazów z przetworzonych dokumentów. W tym samouczku wykorzystamy poprzedni przykład, aby pokazać, jak łatwo można wyodrębnić obrazy z plików PDF.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}Metoda [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages()) zwraca listę BufferedImages. Każdy BufferedImage można następnie zapisać jako obraz PNG w wybranej lokalizacji za pomocą metody ImageIO.write. W przeanalizowanym pliku PDF znajduje się 34 obrazów, a każdy z nich został idealnie wyodrębniony.
 Wyodrębnione obrazy
Wyodrębnione obrazy
Krok 5: Wyodrębnianie danych z tabeli w plikach PDF
Wyodrębnianie treści z granic tabel w pliku PDF jest łatwe dzięki zaledwie jednej linii kodu przy użyciu [metody](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() [extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()). Poniższy fragment kodu pokazuje, jak wyodrębnić tekst z tabeli w pliku PDF:
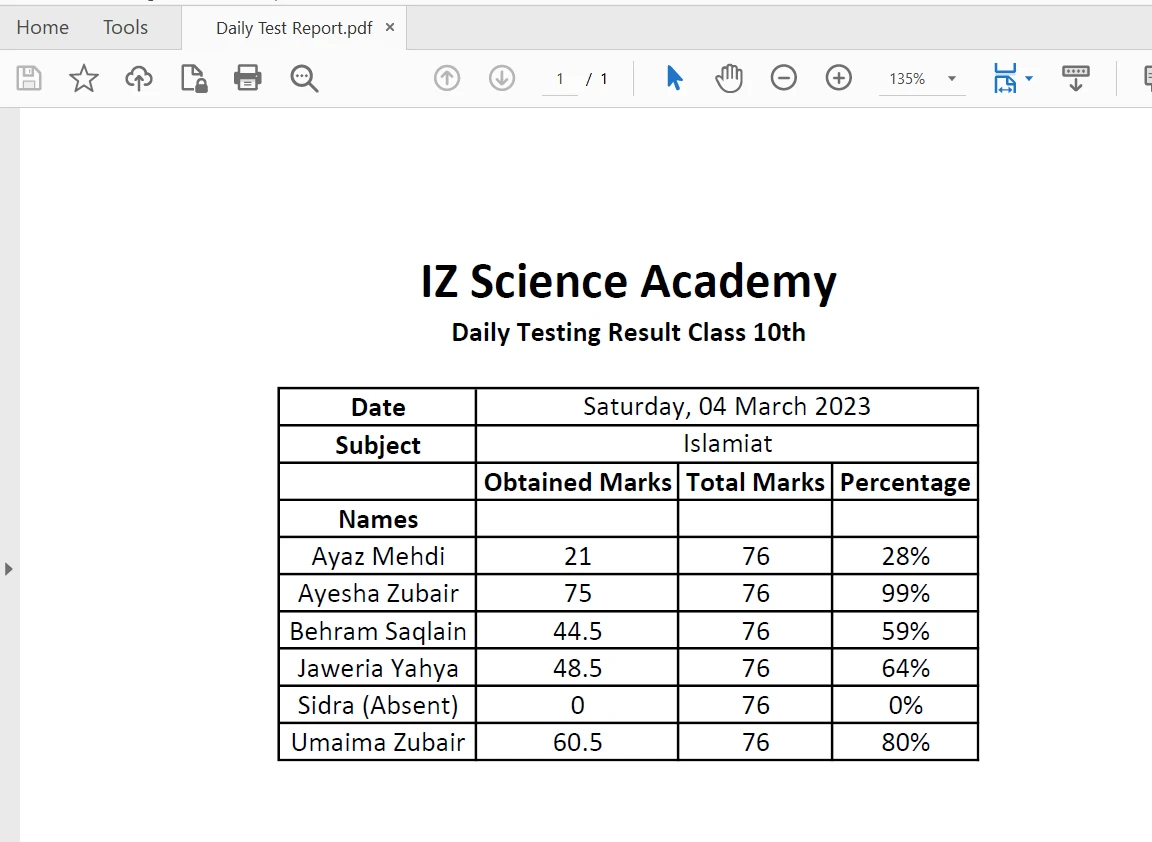 Tabela w formacie PDF
Tabela w formacie PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);Oto wynik:
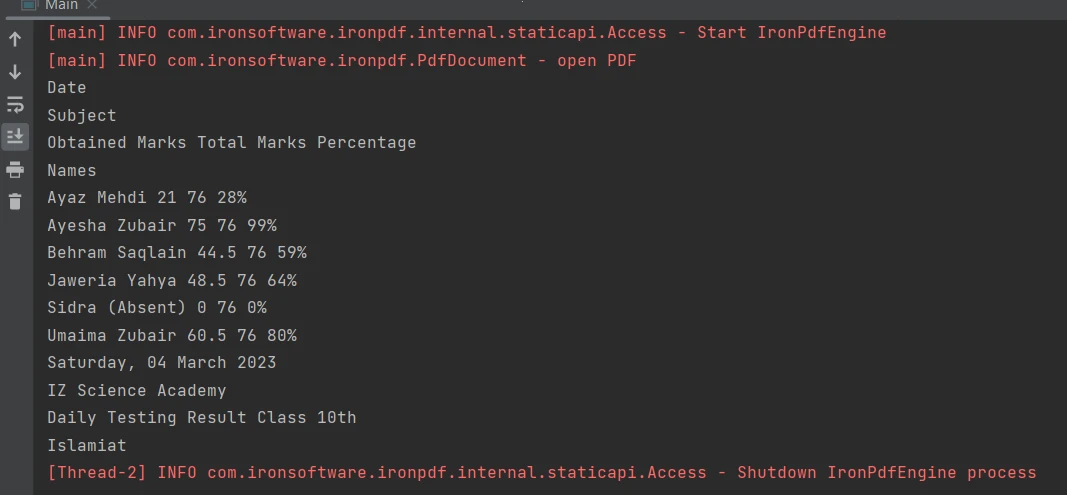 Wynik
Wynik
Wnioski
W tym artykule pokazano, jak analizować istniejący dokument PDF lub utworzyć nowy plik parsera PDF na podstawie adresu URL w celu wyodrębnienia z niego danych w języku Java przy użyciu IronPDF. Po otwarciu pliku może wyodrębnić dane tabelaryczne, obrazy i tekst z pliku PDF, a także dodać wyodrębniony tekst do pliku tekstowego do późniejszego wykorzystania.
Aby uzyskać bardziej szczegółowe informacje na temat programowego przetwarzania plików PDF w języku Java, zapoznaj się z przykładami tworzenia plików PDF.
Biblioteka IronPDF for Java jest bezpłatna do celów programistycznych, a dostępna jest również bezpłatna wersja próbna. Jednakże w celu wykorzystania komercyjnego można uzyskać licencję za pośrednictwem IronSoftware, zaczynając od $799.
Często Zadawane Pytania
Jak stworzyć parser PDF w Javie?
Aby stworzyć parser plików PDF w Javie, możesz użyć biblioteki IronPDF. Zacznij od pobrania i zainstalowania IronPDF, a następnie załaduj dokument PDF za pomocą metody fromFile. Tekst i obrazy możesz wyodrębnić odpowiednio za pomocą metod extractAllText i extractAllImages.
Czy IronPDF może być używany z Javą 8+?
Tak, IronPDF jest kompatybilny z Javą 8 i nowszymi wersjami, a także ze Scalą i Kotlinem. Obsługuje wiele platform, w tym systemy Windows, Linux oraz środowiska chmurowe.
Jakie są kluczowe kroki analizowania plików PDF przy użyciu IronPDF w Javie?
Kluczowe kroki obejmują skonfigurowanie projektu Maven, dodanie zależności IronPDF, załadowanie dokumentu PDF za pomocą fromFile, wyodrębnienie tekstu za pomocą extractAllText oraz wyodrębnienie obrazów za pomocą extractAllImages.
Jak przekonwertować adres URL na plik PDF w Javie?
W Javie można przekonwertować adres URL na plik PDF za pomocą metody renderUrlAsPdf biblioteki IronPDF. Pozwala to na wydajne renderowanie stron internetowych jako dokumentów PDF.
Czy IronPDF nadaje się do aplikacji Java opartych na chmurze?
Tak, IronPDF został zaprojektowany z myślą o wszechstronności i obsługuje środowiska chmurowe, dzięki czemu nadaje się do tworzenia aplikacji Java, które wymagają funkcji PDF w chmurze.
Jak zarządzać zależnościami w projekcie parsowania plików PDF w Javie?
Do zarządzania zależnościami w projekcie Java można użyć Mavena. Dodaj bibliotekę IronPDF do pliku pom.xml swojego projektu, aby uwzględnić ją jako zależność.
Jakie opcje licencyjne są dostępne dla IronPDF?
IronPDF oferuje bezpłatną wersję próbną do celów programistycznych. Jednak do użytku komercyjnego wymagana jest licencja. Zapewnia ona dostęp do wszystkich funkcji oraz priorytetową pomoc techniczną.

















