
如何在 Python 中從 PDF 中提取發票數據
本文將討論如何使用IronPDF程式庫在Python中從發票PDF檔案提取文字數據。
如何在Python中從PDF提取發票數據
- 安裝提取PDF發票數據的Python程式庫。
- 利用
PdfDocument.FromFile方法打開PDF檔案。 - 使用
ExtractAllText方法提取所有發票數據。 - 使用
print方法列印所有提取的發票數據。 - 從發票數據中提取特定數據。
1. IronPDF
IronPDF for Python是一個強大的Python程式庫,用作Python應用程式與PDF文件之間的橋樑。 這款多功能工具為開發者提供了一種輕鬆在其Python專案中創建、操作和互動PDF檔案的方法。 以下是使IronPDF成為有價值資產的一些突出特點:
- PDF產生: IronPDF可從頭動態生成PDF文件,允許開發者以程式化方式創建擁有自定義內容、樣式和佈局的PDF。
- HTML轉PDF文件: 它可以將HTML內容(包括網頁)轉換為高品質PDF,保留原始HTML的佈局和樣式,特別適用於生成報告和文件。
- PDF編輯: 開發者可以輕鬆編輯現有的PDF,通過添加、修改或刪除文本、圖像和互動元素,使其成為一個強大的文件操作工具。
- PDF合併與拆分: IronPDF允許您合併多個PDF文件到一個文件或拆分PDF成多個文件,提供管理大型PDF集的靈活性。
- PDF表單: 它支持創建和填寫互動式PDF表單,非常適合需要用戶輸入和數據收集的應用程式。
- 數位簽名: 您可以向PDF文件添加數位簽名,確保文件的完整性和真實性,這對法律和安全至關重要。
- PDF數據提取: IronPDF提供提取功能來保護PDF中的信息。
2. 環境設置
在Python中設置IronPDF的環境需要幾個步驟,以確保您能有效地使用該程式庫。 這是一個分步指南:
- 在PyCharm中建立一個新的Python專案,並創建一個虛擬環境或使用現有的解釋器。
- 使用命令行終端安裝IronPDF,然後在終端中運行以下命令:
pip install ironpdf
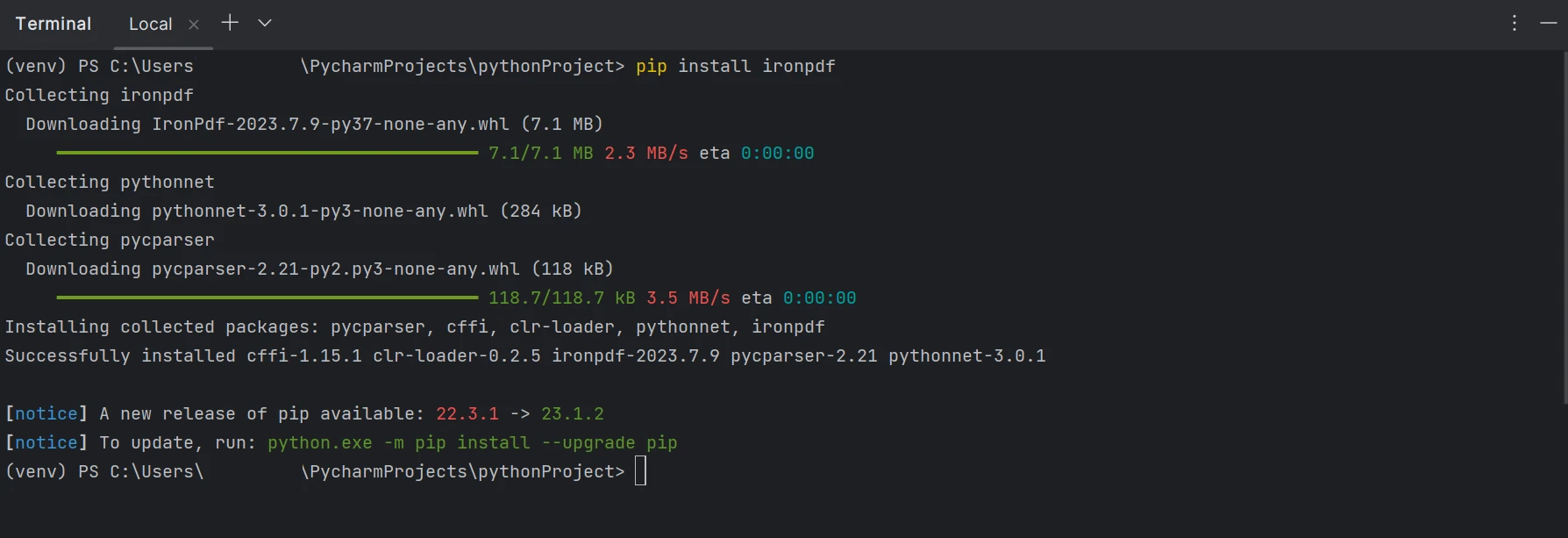 從命令行安裝IronPDF
從命令行安裝IronPDF
3. 使用IronPDF提取發票數據
本節將介紹如何使用IronPDF程式庫在Python中從發票格式和輸出格式中提取數據。 以下代碼將提取發票中的所有數據並在控制台中列印。
示例發票
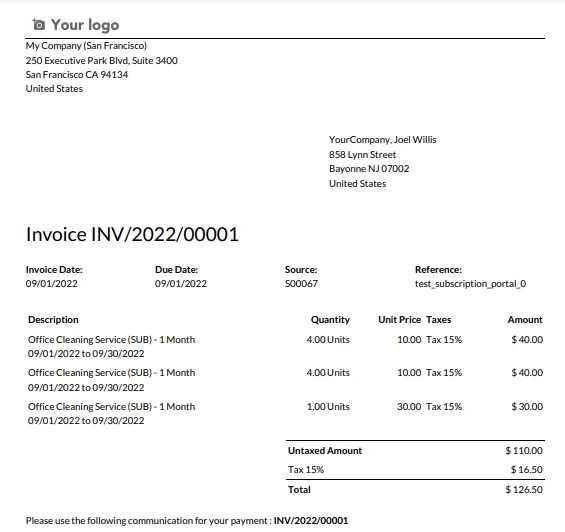 示例發票
示例發票
from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)上述代碼使用PdfDocument.FromFile方法加載名為"INV_2022_00001.pdf"的特定PDF文件。 隨後,它從加載的PDF文件中提取所有文本內容並將其存儲在變數all_text中。 最後,使用print函數將提取的文字列印到控制台。 實質上,此代碼自動化了從PDF文件中提取結構化和非結構化文本數據的過程,並使其可在Python環境中進一步處理或分析。
3.1. 輸出
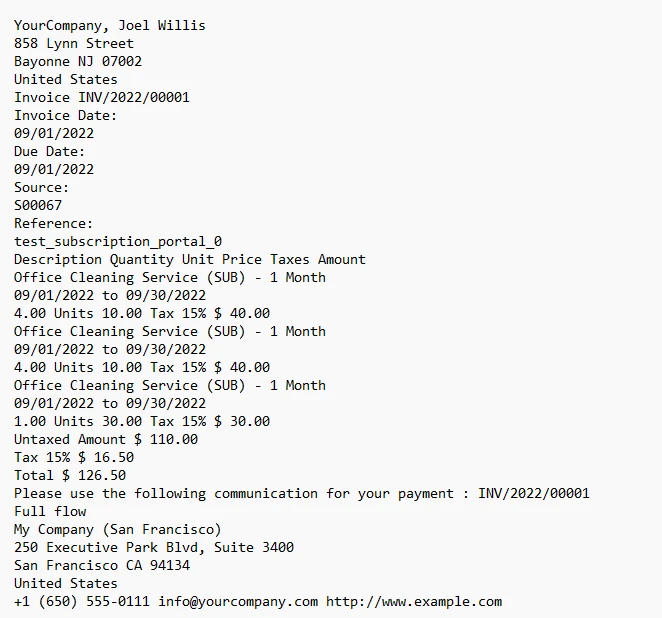 發票文字輸出至控制台
發票文字輸出至控制台
4. 從發票中提取特定數據
使用IronPDF提取發票數據是一個相當簡單的過程。 從PDF發票數據中提取指例如發票號碼和金額等數據可能是一個棘手的過程,但是將IronPDF與Python開源程式庫re結合使用,可以實現。 以下代碼將從PDF發票中提取特定數據並在控制台中列印它們。
from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)此代碼片段使用Python和IronPDF程式庫從PDF文件中提取數據。 它首先導入必要的程式庫並定義正則表達式模式以識別PDF文本內容中的發票號碼和總金額。 然後,代碼載入目標PDF,提取所有文本並開始搜尋與定義模式匹配的內容。
如果找到了成功的匹配項,則存儲對應的發票號碼和金額; 否則,它將賦值為"未找到"。 最後,該腳本列印提取的發票號碼和金額到控制台,提供了一種簡化的方法來自動化從PDF文檔中提取特定數據的過程,這在各種數據處理和會計應用中常見。
4.1. 輸出
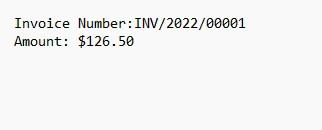 輸出文字
輸出文字
5. 結論
在今天的快節奏商業環境中,Python作為組織尋求通過自動化從PDF發票中提取重要數據來精簡財務運營的一個強大盟友。 利用Python的能力和IronPDF程式庫企業可以顯著減少手動數據輸入,降低錯誤,節省時間,提高會計過程中管理發票的整體生產力。 IronPDF以其多才多藝的功能,如PDF生成,HTML到PDF轉換,PDF編輯,合併,拆分,表單處理,數位簽名和準確的數據提取,在這些任務中脫穎而出。
通過遵循簡單的設置程序,Python開發者可以迅速將IronPDF整合到他們的專案中,改造其發票處理工作流程,使從發票中提取數據的過程變得無縫且高效。 關於使用IronPDF進行數據提取的程式碼示例可以從詳盡的程式碼示例中找到。 使用IronPDF進行數據提取的完整教程可以在以下Python教程中找到,關於使用C#提取發票的教程請訪問IronOCR教程。
常見問題解答
如何使用 Python 從 PDF 發票中提取文本?
您可以使用 IronPDF 的 PdfDocument.FromFile 方法加載 PDF,並使用 ExtractAllText 方法檢索文檔中的所有文本內容。
如何安裝 IronPDF for Python?
使用 Python 包管理器 pip 安裝 IronPDF,命令為 pip install ironpdf。
我可以用 Python 從 PDF 中提取特定數據,例如發票號嗎?
是的,通過將 IronPDF 與 Python 的 re 庫結合使用,您可以定義正則表達式模式來從 PDF 發票中提取特定數據,例如發票號碼和金額。
IronPDF for Python 的功能是什麼?
IronPDF 提供功能包括 PDF 生成、HTML 到 PDF 轉換、PDF 編輯、合併、分割、表單處理、電子簽名和數據提取。
IronPDF 可以在 Python 中將 HTML 轉換為 PDF 嗎?
是的,IronPDF 可以將 HTML 內容(包括網頁)轉換為高質量的 PDF,保留原始 HTML 的佈局和樣式。
IronPDF 如何提高發票數據提取的生產力?
IronPDF 自動提取 PDF 發票中的數據,減少手動輸入和錯誤,從而節省時間並提高財務操作的生產力。
可以使用 IronPDF 在 Python 中編輯 PDF 文檔嗎?
是的,IronPDF 允許開發人員通過添加、修改或刪除文本、圖像和互動元素來編輯現有的 PDF。
IronPDF 可以在 Python 中合併或分割 PDF 文檔嗎?
是的,IronPDF 提供功能,可以將多個 PDF 文檔合併為一個文件,或將 PDF 分割為多個文件。
IronPDF 是否支持在 Python 中向 PDF 添加電子簽名?
是的,IronPDF 允許您向 PDF 文檔添加電子簽名,確保文件的完整性和真實性。
為什麼 IronPDF 被認為是 Python 開發人員的強大工具?
IronPDF 被認為功能強大,因為它能夠全面處理各種 PDF 操作,包括生成、轉換、編輯和數據提取,這對於開發人員來說至關重要。
















