
如何在C#中读取PDF表格
从PDF文档中提取结构化表格数据是C#开发人员的一项常见需求,对于数据分析、报告或将信息集成到其他系统中至关重要。 然而,PDF主要设计用于一致的视觉呈现,而不是直观的数据提取。 这可能使得以编程方式从PDF文件读取表格在C#中成为一项挑战,尤其是因为表格可能差异很大-从简单的文本网格到复杂的合并单元格布局,甚至是在扫描文档中嵌入作为图像的表格。
本指南提供了一个全面的C#教程,介绍如何使用IronPDF进行PDF表格提取。 我们将主要探索利用IronPDF强大的文本提取功能来访问并解析文本PDF中的表格数据。 我们将讨论这种方法的有效性,提供解析策略,并提供处理提取信息的见解。 此外,我们还将涉及更复杂场景的策略,包括扫描的PDF。
在C#中从PDF中提取表格数据的关键步骤
- 安装用于PDF处理的IronPDF C#库(https://nuget.org/packages/IronPdf/)。
2.(可选演示步骤)使用 IronPDF 的RenderHtmlAsPdf从 HTML 字符串创建一个包含表格的示例 PDF。 (请参阅章节:(演示步骤)创建包含表格数据的PDF文档) - 加载任何 PDF 文档,并使用
ExtractAllText方法检索其原始文本内容。 (See section: Extract All Text Containing Table Data from the PDF) - 实现C#逻辑来解析提取的文本并识别表格行和单元格。 (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- 输出结构化的表格数据或将其保存到CSV文件中以供进一步使用。 (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- 考虑用于扫描PDF的OCR等高级技术(稍后讨论)。
IronPDF - C# PDF库
IronPDF是一个用于.NET的C#库解决方案,用于在.NET中操作PDF(https://ironpdf.com/),帮助开发人员在其软件应用程序中轻松读取、创建和编辑PDF文档。 其强大的Chromium引擎以高精度和速度从HTML呈现PDF文档。 它允许开发人员无缝地从不同格式转换为PDF及其反方向。 它支持最新的.NET框架,包括.NET 7、.NET 6、5、4、.NET Core和Standard。
此外,IronPDF 适用于 .NET API还使开发人员能够操作和编辑PDF,添加页眉和页脚,以及轻松地从PDF中提取文本、图像和(如我们将看到的)表格数据。
一些重要功能包括:
使用IronPDF库在C#中提取表格数据的步骤
为了从PDF文档中提取表格数据,我们将设置一个C#项目:
- Visual Studio:确保您已安装 Visual Studio(例如,2022)。 如果没有,从Visual Studio网站下载它(https://visualstudio.microsoft.com/downloads/)。
2.创建项目:- 打开Visual Studio 2022并点击创建新项目。
 Visual Studio的开始屏幕
Visual Studio的开始屏幕
- 选择"控制台应用程序"(或您偏好的C#项目类型),然后点击下一步。
 在Visual Studio中创建一个新控制台应用程序
在Visual Studio中创建一个新控制台应用程序
-
为您的项目命名(例如,"ReadPDFTableDemo")并点击下一步。
 配置新创建的应用程序
配置新创建的应用程序-
选择您希望的.NET框架(例如.NET 6或更高版本)。
 选择一个.NET框架
选择一个.NET框架 - 点击创建。 控制台项目将被创建。
-
3.安装 IronPDF:
*使用 Visual Studio NuGet 包管理器:
- 在解决方案资源管理器中右键单击您的项目并选择"管理NuGet包..."
 工具和管理NuGet包
工具和管理NuGet包
-
在NuGet包管理器中,浏览"IronPDF"并点击"安装"。
 工具和管理NuGet包
工具和管理NuGet包*直接下载 NuGet 包:*访问 IronPDF 的 NuGet 包页面( https://www.nuget.org/packages/IronPdf/ )。 下载 IronPDF .DLL 库:**从 IronPDF 官方网站下载,并在您的项目中引用该 DLL。
(演示步骤)创建包含表格数据的PDF文档
在本教程中,我们将首先从HTML字符串创建一个包含简单表格的示例PDF。 这为我们提供了已知的PDF结构以展示提取过程。 在实际场景中,您将加载已存在的PDF文件。
添加IronPDF命名空间并(可选)设置您的许可证密钥(IronPDF对开发是免费的,但需要许可证才能在不带水印的商业部署中使用):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";这是我们示例表格的HTML字符串:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";现在,使用 ChromePdfRenderer 从以下 HTML 代码创建 PDF:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")SaveAs 方法保存 PDF。 生成的 table_example.pdf 将如下所示(基于 HTML 的概念图):
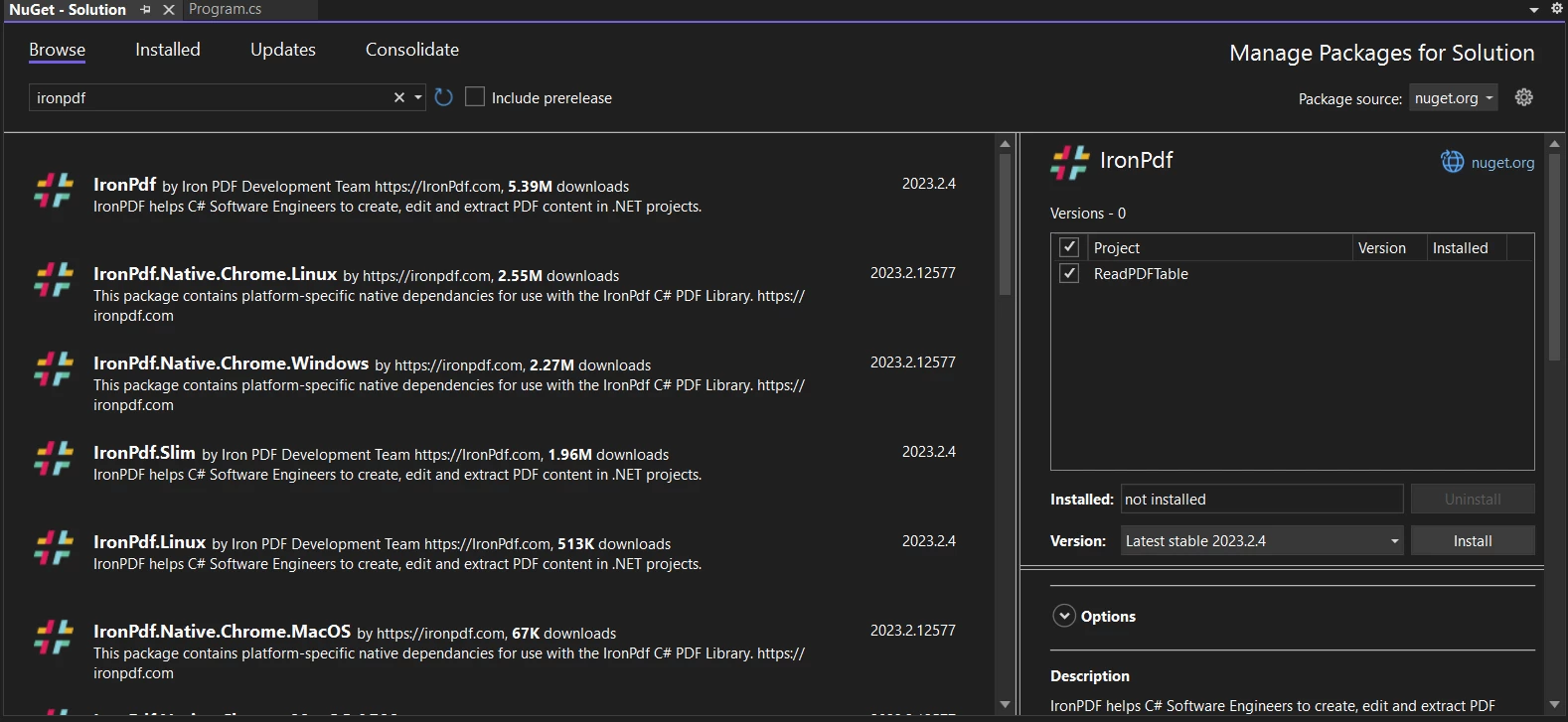 在NuGet包管理器UI中搜索IronPDF
在NuGet包管理器UI中搜索IronPDF
从PDF中提取包含表格数据的所有文本
要提取表格数据,我们首先加载 PDF(可以是刚刚创建的 PDF,也可以是任何现有的 PDF),然后使用 ExtractAllText 方法。 此方法从PDF页面检索所有文本内容。
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()变量 allText 现在保存了 PDF 中的所有文本内容。 您可以显示它以查看原始提取:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)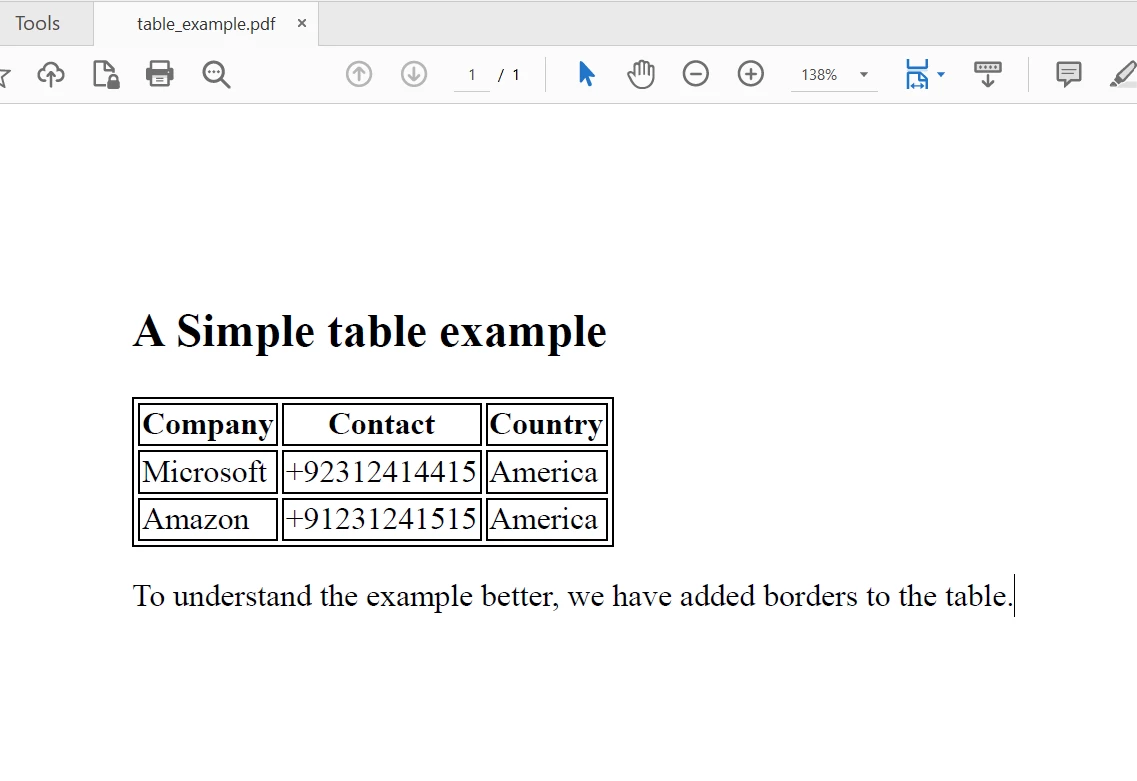 要提取文本的PDF文件
要提取文本的PDF文件
解析提取的文本以在C#中重建表格数据
提取的原始文本后,下一个挑战是解析该字符串以识别和构建表格数据。 这一步高度依赖于PDF中表格的格式和一致性。
一般解析策略:
1.识别行分隔符:换行符(\n 或 \r\n)是常见的行分隔符。
- 识别列分隔符:行中的单元格可能由多个空格、制表符或特定已知字符(如'|"或';')分隔。 有时,如果列是视觉对齐的但缺乏明确的文本分隔符,您可能会根据一致的间距模式推断结构,尽管这更复杂。
3.过滤非表格内容:
ExtractAllText方法获取所有文本。 您需要逻辑来隔离实际形成表格的文本,可能通过寻找标题关键词或跳过前言/后记文本。
C# String.Split 方法是一个用于此的基本工具。 以下代码示例尝试仅从我们的示例中提取表格行,过滤掉带圆点的行(对于此具体示例的简单启发法):
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next line此代码将文本拆分为行。 if 条件是针对此特定示例中的非表格文本的一个非常基本的过滤器。 在现实场景中,您需要更健壮的逻辑来准确识别和解析表格行和单元格。
简单过滤文本的输出:
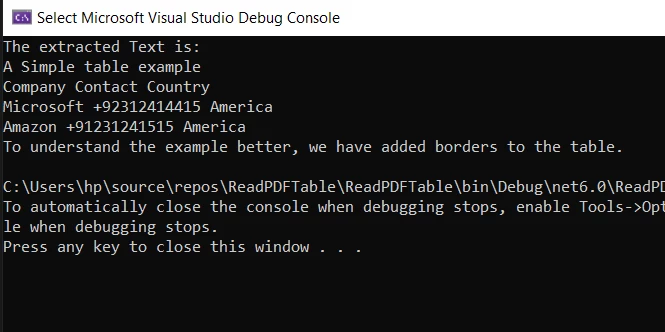 控制台显示提取的文本
控制台显示提取的文本
文本解析方法的重要考虑因素:
- 最佳适用场合: 适用于具有简单、一致的表格结构和明确文本分隔符的文本型PDF。
- 局限性:此方法可能在以下情况下遇到挑战:
- 具有合并单元格或复杂嵌套结构的表格。
- 列由视觉间距而非文本分隔符定义的表格。
- 作为图像嵌入的表格(需要OCR)。
- PDF生成的变化导致文本提取顺序不一致。
您可以将过滤后的行(理想地表示表格行)保存到CSV文件中:
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")在C#中提取更复杂PDF表格的策略
从复杂或基于图像的PDF表格中提取数据通常需要比简单文本解析更高级的技术。 IronPDF提供的功能可以帮助:
*使用 IronOCR 对扫描表格的功能:如果表格位于图像中(例如,扫描的 PDF),则仅使用 ExtractAllText() 无法捕获它们。 IronOCR的文本检测功能可以首先将这些图像转换为文本。
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End Using有关详细指导,请访问IronOCR文档(https://ironsoftware.com/csharp/ocr/)。 进行OCR后,您需要解析得到的文本字符串。
*基于坐标的文本提取(高级):虽然 IronPDF 的 ExtractAllText() 提供了文本流,但在某些情况下,了解每个文本片段的 x、y 坐标可能会有所帮助。 如果IronPDF提供获取文本及其边界框信息的API(请查看当前文档),这可能允许基于视觉对齐进行更复杂的空间解析以重建表格。
- 将PDF转换为其他格式: IronPDF可以将PDF转换为结构化格式,如HTML。 通常,解析HTML表格比解析原始PDF文本更简单。
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- 模式识别和正则表达式:对于具有非常可预测模式但分隔符不一致的表格,应用于提取文本的复杂正则表达式有时可以隔离表格数据。
选择正确的策略取决于您源PDF的复杂性和一致性。 对于许多包含文本表格的常见商务文档,IronPDF 的 ExtractAllText 功能结合其智能的 C# 解析逻辑非常有效。而对于图像表格,其 OCR 功能则至关重要。
总结
本文演示了如何使用 IronPDF 从 C# 中的 PDF 文档中提取表格数据,主要侧重于利用 ExtractAllText() 方法和后续的字符串解析。 我们已经看到,虽然这种方法对于基于文本的表格非常有效,但像基于图像的表格这样更复杂的情况可以使用IronPDF的OCR功能或通过先将PDF转换为其他格式来处理。
IronPDF为.NET开发人员提供多功能的工具包,简化了许多与PDF相关的任务,从创建和编辑到全面的数据提取。 它提供了诸如ExtractTextFromPage之类的页面特定提取方法,并支持将markdown或DOCX等格式转换为 PDF。
IronPDF对开发是免费的,并提供免费试用许可证用于测试其完整的商业功能。 针对生产部署,提供多种许可选项。
欲了解更多详细信息和高级用例,探索官方IronPDF文档和示例(https://ironpdf.com/)
常见问题解答
如何在 C# 中以编程方式从 PDF 文件中读取表格?
您可以使用 IronPDF 的 `ExtractAllText` 方法从 PDF 文档中提取原始文本。提取后,您可以在 C# 中解析此文本以识别表格行和单元格,从而实现结构化数据提取。
使用 C# 从 PDF 中提取表格数据涉及哪些步骤?
该过程包括安装 IronPDF 库,使用 `ExtractAllText` 方法检索文本,解析此文本以识别表格,并选择保存结构化数据到类似 CSV 的格式。
如何在 C# 中处理带表格的扫描 PDF?
对于扫描的 PDF,IronPDF 可以利用 OCR(光学字符识别)将表格图像转换为文本,然后对其进行解析以提取表格数据。
IronPDF 能否将 PDF 转换为其他格式以便更轻松地提取表格?
是的,IronPDF 可以将 PDF 转换为 HTML,这可以通过允许开发人员使用 HTML 解析技术来简化表格提取。
IronPDF 是否适合从复杂的 PDF 表格中提取数据?
IronPDF 提供了高级功能,如 OCR 和基于坐标的文本提取,可以用于处理具有合并单元格或不一致分隔符的复杂表格布局。
如何将 IronPDF 集成到 .NET Core 应用程序中?
IronPDF 与 .NET Core 应用程序兼容。您可以通过在 Visual Studio 中使用 NuGet 包管理器安装该库来集成它。
使用 IronPDF 进行 PDF 操作有什么好处?
IronPDF 提供了一系列多功能的功能用于创建、编辑和从 PDF 中提取数据,包括支持 OCR 和转换为各种格式,成为 .NET 开发人员的强大工具。
从 PDF 中提取表格数据的常见挑战是什么?
挑战包括处理复杂的表格布局,如合并单元格、嵌入为图像的表格和不一致的分隔符,这可能需要高级解析策略或 OCR。
如何开始使用 IronPDF 进行 PDF 处理?
首先通过 NuGet 包管理器或从 IronPDF 网站下载来安装 IronPDF 库。此设置对于在 C# 项目中利用其 PDF 处理功能至关重要。
使用 IronPDF 是否需要许可证?
IronPDF 免费用于开发目的,但需要商业部署许可证才能去除水印。免费试用许可证可用于测试其全部功能。
IronPDF 在从 PDF 中提取表格时是否兼容 .NET 10?
是的。IronPDF 支持 .NET 10(以及 .NET 9、8、7、6、Core、Standard 和 Framework),因此所有表格提取功能在 .NET 10 应用程序中无需修改即可运行。













