
IronPDF kullanarak C# ile PDF oluşturma
C# geliştiricileri için PDF belgelerinden yapılandırılmış tablo verisi çıkarmak, veri analizi, raporlama veya diğer sistemlere bilgi entegrasyonu için kritik bir gerekliliktir. Ancak, PDF'ler esas olarak tutarlı görsel sunum için tasarlanmış olup, doğrudan veri çıkarımı için değildir. Bu, C#'de PDF dosyalarından tabelalar okumayı programlı olarak zorlu bir görev haline getirebilir, özellikle tablolar basit metin tabanlı ızgaralardan birleşik hücrelerle karmaşık düzenlere kadar farklılık gösterebilir veya taranmış belgelerde görüntü olarak gömülü olabilir.
Bu kılavuz, IronPDF kullanarak PDF tablo çıkarımı için kapsamlı bir C# öğreticisi sağlar. IronPDF'nin güçlü metin çıkarma yeteneklerini kullanarak metin tabanlı PDF'lerden tablo verilerini erişmek ve daha sonra çözümlemek konusunda yoğunlaşacağız. Bu yöntemin etkinliğini tartışacağız, çözümleme stratejileri sunacağız ve çıkarılan bilgilerin işlenmesi hakkında ipuçları sunacağız. Ayrıca, taranmış PDF'ler gibi daha karmaşık senaryolara yönelik stratejilere de değineceğiz.
PDF'lerden C#'de Tablo Verisi Çıkarmanın Temel Adımları
- PDF işleme için IronPDF C# Kütüphanesini yükleyin (https://nuget.org/packages/IronPdf/).
- (İsteğe Bağlı Demo Adımı) IronPDF'nin
RenderHtmlAsPdfkullanarak bir HTML dizesinden bir tablo ile örnek bir PDF oluşturun. (Bakınız: (Demo Adımı) Tablo Verileri ile PDF Belgesi Oluşturma Bölümü) - Herhangi bir PDF belgesini yükleyin ve ham metin içeriğini almak için
ExtractAllTextyöntemini kullanın. (See section: Extract All Text Containing Table Data from the PDF) - Çıkarılan metni çözümlemek ve tablo satırlarını ve hücrelerini tanımak için C# mantığı uygulayın. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Yapılandırılmış tablo verisini çıktı alın veya daha ileri kullanım için bir CSV dosyasına kaydedin. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Tarama PDF'leri için OCR gibi ileri teknikleri düşünün (daha sonra tartışılacak).
IronPDF - C# PDF Kütüphanesi
IronPDF, .NET'te PDF işlemek için bir C# .NET Kütüphanesi çözümüdür (https://ironpdf.com/), geliştiricilerin yazılım uygulamalarında kolayca PDF belgeleri okumasına, oluşturmasına ve düzenlemesine yardımcı olur. Sağlam Chromium Motoru, PDF belgelerini HTML'den yüksek doğruluk ve hızla dönüştürür. Farklı formatlardan PDF'ye ve tersi dönüşümü sorunsuz bir şekilde yapılmasına izin verir. .NET 7, .NET 6, 5, 4, .NET Core ve Standard gibi en son .NET frameworklerini destekler.
Ayrıca, IronPDF .NET API, geliştiricilerin PDF'leri manipüle etmelerine ve düzenlemelerine, başlık ve altbilgi eklemelerine, ve en önemlisi, metin, resimler ve (göreceğimiz gibi) tablo verileri çıkarmalarına olanak tanır.
Bazı Önemli Özellikler şunlardır:
- Çeşitli kaynaklardan PDF dosyaları oluşturun (HTML to PDF, Görüntüler to PDF)
- PDF dosyalarını Yükle, Kaydet ve Yazdır
- PDF dosyalarını birleştirin ve bölün
- PDF dosyalarından Veri (Metin, Görüntüler ve tablolar gibi yapılandırılmış veri) Çıkar
C# kullanarak IronPDF Kütüphanesi ile Tablo Verilerini Çıkarma Adımları
PDF belgelerinden tablo verisi çıkarmak için bir C# projesi kuracağız:
- Visual Studio: Visual Studio'nun (örneğin, 2022) yüklü olduğundan emin olun. Eğer değilse, Visual Studio web sitesinden indirin (https://visualstudio.microsoft.com/downloads/).
-
Proje Oluştur:
-
Visual Studio 2022'yi açın ve Yeni bir proje oluştur a tıklayın.
 Visual Studio'nun başlangıç ekranı
Visual Studio'nun başlangıç ekranı -
"Konsol Uygulaması" (yahut tercih ettiğiniz C# proje türü) seçin ve Sonraki ye tıklayın.
 Visual Studio'da yeni bir Konsol Uygulaması oluştur
Visual Studio'da yeni bir Konsol Uygulaması oluştur -
Projenize bir ad verin (örneğin, "ReadPDFTableDemo") ve Sonraki ye tıklayın.
 Yeni oluşturulan uygulamayı yapılandır
Yeni oluşturulan uygulamayı yapılandır -
İstediğiniz .NET Frameworkü seçin (örneğin, .NET 6 veya daha sonrası).
 Bir .NET Framework seçin
Bir .NET Framework seçin - Oluştur a tıklayın. Konsol projesi oluşturulacaktır.
-
-
IronPDF'i Yükleyin:
-
Visual Studio NuGet Paket Yöneticisini Kullanarak:
- Çözüm Gezgini'nde projenize sağ tıklayın ve "NuGet Paketlerini Yönet..." i seçin.
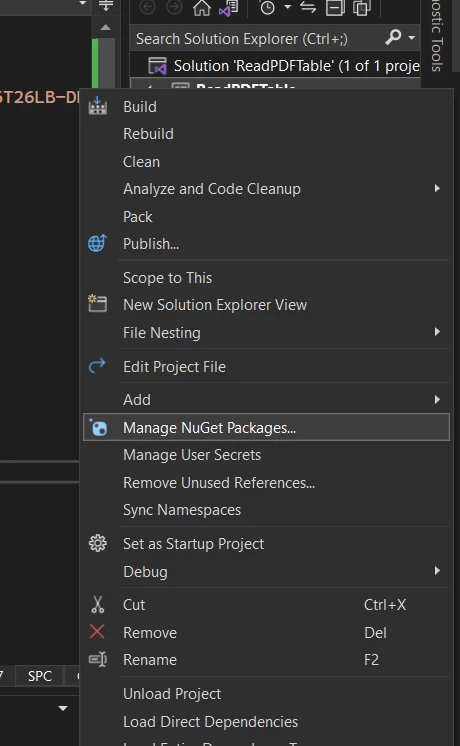 Araçlar & NuGet Paketlerini Yönet
Araçlar & NuGet Paketlerini Yönet
-
-
NuGet Paket Yöneticisinde 'IronPDF' arayın ve 'Yükle'ye tıklayın.
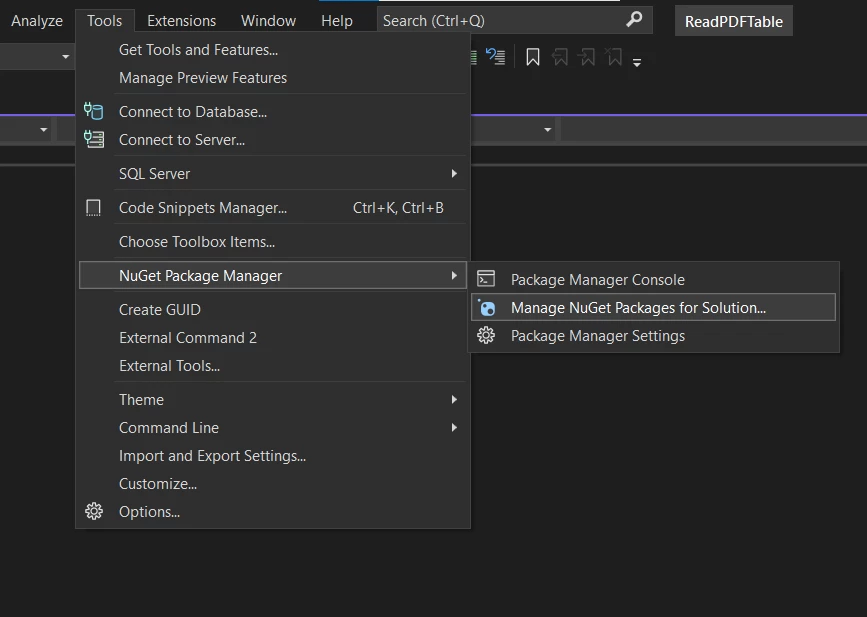 Araçlar & NuGet Paketlerini Yönet
Araçlar & NuGet Paketlerini Yönet- NuGet Paketini doğrudan indirin: IronPDF'nin NuGet paket sayfasını ziyaret edin (https://www.nuget.org/packages/IronPdf/).
- IronPDF .DLL Kütüphanesini İndir: Resmi IronPDF web sitesinden indirin ve projenize DLL olarak referans verin.
(Demo Adımı) Tablo Verisi ile PDF Belgesi Oluştur
Bu öğretici için, öncelikle bir HTML dizesinden basit bir tablo içeren bir PDF örneği oluşturacağız. Bu, çıkarım sürecini göstermek için bilinen bir PDF yapısı sağlar. Gerçek dünya senaryosunda, var olan PDF dosyalarınızı yükleyeceksiniz.
IronPDF ad alanını ekleyin ve opsiyonel olarak lisans anahtarınızı ayarlayın (IronPDF geliştirme için ücretsizdir ancak ticari dağıtım için lisans gerektirir):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";İşte örnek tablomuz için HTML dizesi:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Şimdi bu HTML'den bir PDF oluşturmak için ChromePdfRenderer kullanın:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")SaveAs yöntemi PDF'yi kaydeder. Oluşturulan table_example.pdf bu şekilde görünecektir (HTML'ye dayalı kavramsal görüntü):
 NuGet Paket Yöneticisi UI'de IronPDF'i arayın
NuGet Paket Yöneticisi UI'de IronPDF'i arayın
Tablo Verilerini İçeren Tüm Metni PDF'den Çıkar
Tablo verilerini çıkarmak için önce PDF'yi (ya yeni oluşturulan ya da mevcut bir PDF) yükleyin ve ExtractAllText yöntemini kullanın. Bu yöntem, PDF sayfalarından tüm metin içeriklerini alır.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()allText değişkeni şimdi PDF'den gelen tüm metin içeriğini tutar. Ham çıkarmayı görmek için görüntüleyebilirsiniz:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)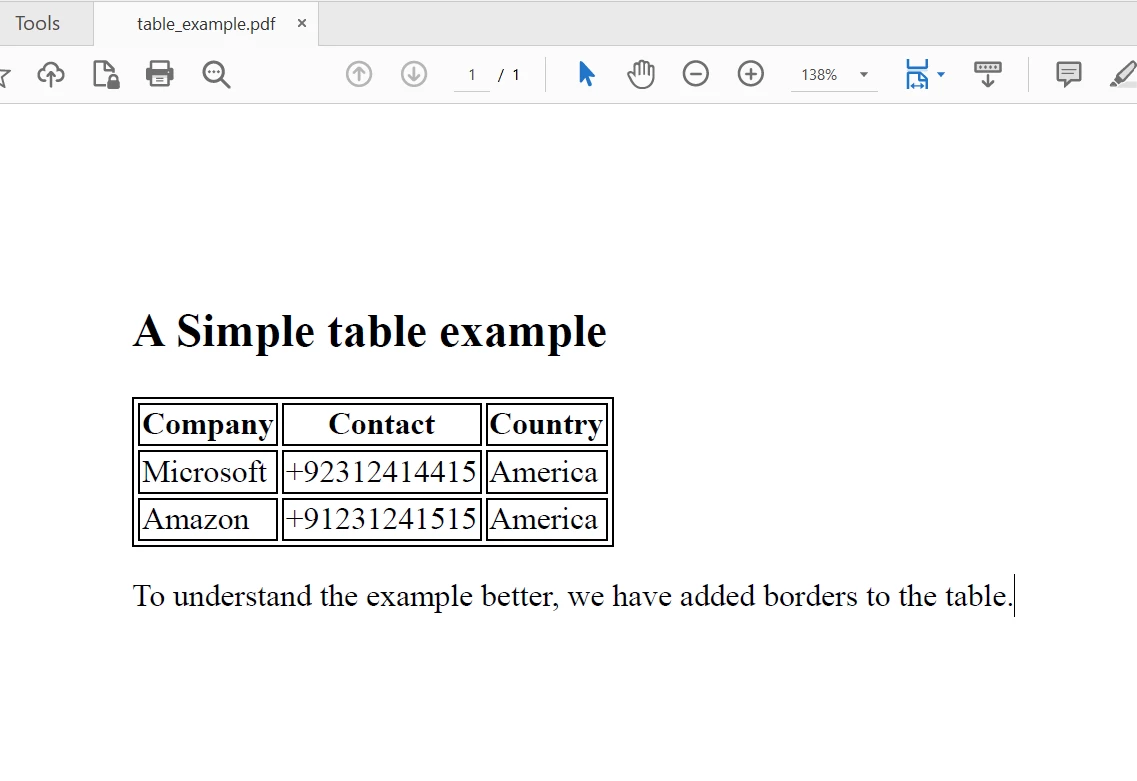 Metin çıkarmak için PDF dosyası
Metin çıkarmak için PDF dosyası
C#'da Tablo Verilerini Yeniden Oluşturmak için Çıkarılan Metni Ayrıştırma
Ham metin çıkarıldıktan sonra, bir sonraki zorluk bu dizeyi ayrıştırarak tablo verisini tanımlamak ve yapılandırmaktır. Bu adım, PDF'lerinizdeki tabloların tutarlılığı ve yapısına büyük ölçüde bağlıdır.
Genel Ayrıştırma Stratejileri:
- Satır Ayırıcılarını Belirleyin: Yeni satır karakterleri (
\nveya\r\n) yaygın satır ayırıcılarıdır. - Sütun Ayraçlarını Tanıma: Bir satır içindeki hücreler genellikle birden fazla boşluk, sekme veya belirli bilinen karakterlerle (örneğin '|' veya ';') ayrılır. Bazen, sütunlar görsel olarak hizalandığında ancak belirgin metin ayraçları olmadığında, yapıyı tutarlı boşluk örüntülerine dayanarak tahmin edebilirsiniz, bu daha karmaşık olsa da.
- Tablo Dışı İçeriği Filtreleyin:
ExtractAllTextyöntemi tüm metni alır. Tablonuzu gerçekten oluşturan metni izole edecek mantığa ihtiyacınız olacaktır, muhtemelen başlık anahtar kelimelerini arayarak veya önsöz/sonsöz metni atlayarak.
C# String.Split yöntemi bu iş için temel bir araçtır. İşte örnek tablolardan yalnızca tablo satırlarını çıkartmaya çalışan, noktalarla (bu özel örnek için basit bir sezgi) satırları filtreleyen bir örnek:
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineBu kod metni satırlara böler. if koşulu, bu özel örneğin tablo dışı metinleri için çok basit bir filtredir. Gerçek dünya senaryolarında, tablo satırlarını ve hücrelerini doğru bir şekilde tanımlayıp ayrıştırmak için daha sağlam bir mantığa ihtiyacınız olacaktır.
Basit filtrelenmiş metnin çıktısı:
 Konsol çıkarılan metinleri görüntüler
Konsol çıkarılan metinleri görüntüler
Metin-Ayrıştırma Yöntemi için Önemli Hususlar:
- En Uygun Olduğu Durumlar: Metin tabanlı PDF'ler, basit, tutarlı tablo yapıları ve net metin ayraçları olan belgeler.
- Sınırlamalar: Bu yöntem şu konularda zorlanabilir:
- Birleşik hücreler veya karmaşık iç içe yapılar içeren tablolar.
- Sütunların metin ayraçları yerine görsel boşluklarla tanımlandığı tablolar.
- Görüntü olarak gömülü tablolar (OCR gerektirir).
- PDF oluşturma kaynaklı metin çıkartım sıralamalarında tutarsızlıklar.
Filtrelenmiş satırları (ki bunlar ideal olarak tablo satırlarını temsil eder) bir CSV dosyasına kaydedebilirsiniz:
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Daha Karmaşık PDF Tablo Çıkarma İçin Stratejiler C#'da
Karmaşık veya görüntü bazlı PDF tablolarından veri çıkarmak, basit metin ayrıştırmadan daha gelişmiş teknikler gerektirebilir. IronPDF, yardımcı olabilecek özellikler sunar:
- Tarama Tabloları için IronOCR'nin Yeteneklerini Kullanma: Tablolar görüntüler içerisindeyse (örneğin, taranmış PDF'ler),
ExtractAllText()bunları yakalayamaz. IronOCR'nin metin tespiti işlevi, bu görüntüleri öncelikle metne dönüştürebilir.
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingDetaylı rehberlik için IronOCR dokümanlarına bakın (https://ironsoftware.com/csharp/ocr/). OCR sonrası, elde edilen metin dizgisini ayrıştırırdınız.
-
Koordinat Tabanlı Metin Çıkarması (Gelişmiş): IronPDF'nin
ExtractAllText()metin akışını sağlarken, bazı senaryolar her bir metin parçasının x,y koordinatlarını bilmekten fayda görebilir. IronPDF mevcut belgelerde metni ve sınırlayıcı kutu bilgileriyle sunma API'leri sunuyorsa, görsel hizalamaya dayalı tabloları yeniden inşa etmek için daha sofistike bir uzamsal ayrıştırma yapılabilir. - PDF'yi Başka Bir Formata Dönüştürme: IronPDF, PDF'leri HTML gibi yapılandırılmış formatlara dönüştürebilir. Çoğu zaman, HTML tablosunu ayrıştırmak, ham PDF metnini ayrıştırmaktan daha kolaydır.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Düzensiz Tablo Düzenine Sahip Tablolar İçin Kalıp Tanıma ve Düzenli İfadeler: Çok öngörülebilir kalıplara sahip tablolar, ancak tutarsız ayraçlarla, karmaşık düzenli ifadeler çıkarılan metne uygulanarak bazen tablo verilerini izole edebilir.
Doğru stratejiyi seçmek, kaynak PDF'lerin karmaşıklığına ve tutarlılığına bağlıdır. Metin tabanlı tablolara sahip birçok yaygın iş belgesi için, IronPDF'nin ExtractAllText ve akıllı C# ayrıştırma mantığı çok etkili olabilir. Görüntü tabanlı tablolar için, OCR yetenekleri esastır.
Özet
Bu makale, IronPDF kullanarak C#'da bir PDF belgesinden tablo verilerini nasıl çıkaracağınızı gösterdi, esas olarak ExtractAllText() yöntemini ve sonrasında string ayrıştırmasını kullanmayı odaklanarak. Bu yaklaşımın metin tabanlı tablolar için güçlü olduğunu gördük, daha karmaşık senaryolar ise IronPDF'nin OCR özellikleri kullanılarak veya öncelikle PDF'yi başka formatlara dönüştürerek ele alınabilir.
IronPDF, .NET geliştiricileri için çok yönlü bir araç kiti sunar ve PDF ile ilgili birçok görevi, oluşturmadan ve düzenlemeden kapsamlı veri çıkarmasına kadar basitleştirir. ExtractTextFromPage gibi sayfa bazlı çıkarma yöntemleri sunar ve markdown veya DOCX formatlarından PDF'ye dönüşümleri destekler.
IronPDF, geliştirme için ücretsizdir ve tam ticari özelliklerini test etmek için bir ücretsiz deneme lisansı sunar. Üretim dağıtımı için çeşitli lisanslama seçenekleri mevcuttur.
Daha fazla detay ve ileri düzey kullanım örnekleri için, resmi IronPDF dokümantasyonu ve örnekleri inceleyin (https://ironpdf.com/)
Sıkça Sorulan Sorular
C# dilinde PDF dosyalarından programatik olarak tabloları nasıl okuyabilirim?
IronPDF'un `ExtractAllText` metodunu kullanarak PDF belgelerinden ham metini çıkarabilirsiniz. Çıkarılan metin sonrasında tablo satırlarını ve hücrelerini tanımlamak için C# dilinde ayrıştırılabilir, bu da yapılandırılmış veri çıkarımını mümkün kılar.
C# kullanarak PDF'den tablo verilerini çıkarmada hangi adımlar yer alır?
Süreç, IronPDF kütüphanesini kurmayı, `ExtractAllText` metodunu kullanarak metin almayı, bu metni tabloları tanımlamak için ayrıştırmayı içerir ve opsiyonel olarak yapılandırılmış verileri CSV gibi bir biçime kaydeder.
C# diliyle tablolara sahip taranmış PDF'leri nasıl işleyebilirim?
Taranmış PDF'ler için IronPDF, tablo görüntülerini metne dönüştürmek için OCR (Optik Karakter Tanıma) kullanabilir ve bu metin daha sonra tablosal verileri çıkartmak için ayrıştırılabilir.
IronPDF diකğer formatlarda tablo çıkarımını kolaylaştırmak için PDF'leri dönüştürebilir mi?
Evet, IronPDF PDF'leri HTML'ye dönüştürebilir, bu da geliştiricilerin HTML ayrıştırma tekniklerini kullanmasını sağlayarak tablo çıkarımını kolaylaştırabilir.
IronPDF, karmaşık PDF tablolarından veri çıkarmak için uygun mu?
IronPDF, birleştirilmiş hücreler veya tutarsız ayraçlar içeren karmaşık tablo düzenlemelerini işlemek için OCR ve koordinat tabanlı metin çıkarma gibi gelişmiş özellikler sunar.
.NET Core uygulamasına IronPDF'u nasıl entegre edebilirim?
IronPDF, .NET Core uygulamaları ile uyumludur. Visual Studio'da NuGet Paket Yöneticisi aracılığıyla kütüphaneyi yükleyerek entegre edebilirsiniz.
C#'ta PDF manipülasyonu için IronPDF kullanmanın faydaları nelerdir?
IronPDF, PDF'lerden veri oluşturma, düzenleme ve çıkarım için çeşitli özellikler sunar ve OCR ve diğer formatlara dönüşüm desteği ile .NET geliştiricileri için güçlü bir araç haline gelir.
PDF'lerden tablo verisi çıkarırken yaygın sorunlar nelerdir?
Sorunlar, birleştirilmiş hücreler, resim olarak gömülü tablolar ve tutarsız ayraçlar gibi karmaşık tablo yapılarıyla uğraşmayı içerir ve bu, gelişmiş ayrıştırma stratejileri veya OCR gerektirebilir.
PDF işleme için IronPDF kullanmaya nasıl başlayabilirim?
IronPDF kütüphanesini NuGet Paket Yöneticisi aracılığıyla kurarak veya IronPDF web sitesinden indirerek başlayın. Bu kurulum, C# projelerinizde PDF işleme yeteneklerini kullanmak için önemlidir.
IronPDF kullanmak lisans gerektirir mi?
IronPDF, geliştirme amaçları için ücretsizdir ancak ticari dağıtım için lisans gereklidir ve filigranların kaldırılması bu lisansla mümkündür. Tüm özelliklerini test etmek için ücretsiz deneme lisansı mevcuttur.
IronPDF, PDF'lerden tablolar çıkarırken .NET 10 ile uyumlu mu?
Evet. IronPDF .NET 10'u (ayrıca .NET 9, 8, 7, 6, Core, Standard ve Framework ile uyumlu) destekler, bu nedenle tüm tablo çıkarma işlevleri .NET 10 uygulamalarında değişiklik gerektirmeksizin çalışır.











