
Gerando PDFs em C# usando IronPDF
Extrair dados estruturados de tabelas a partir de documentos PDF é uma necessidade frequente para desenvolvedores C#, sendo crucial para análise de dados, geração de relatórios ou integração de informações em outros sistemas. No entanto, os PDFs são projetados principalmente para uma apresentação visual consistente, e não para uma extração de dados direta. Isso pode tornar a leitura programática de tabelas de arquivos PDF em C# uma tarefa desafiadora, especialmente porque as tabelas podem variar bastante — desde grades simples baseadas em texto até layouts complexos com células mescladas, ou mesmo tabelas incorporadas como imagens em documentos digitalizados.
Este guia fornece um tutorial completo em C# sobre como extrair tabelas de PDFs usando o IronPDF . Vamos explorar principalmente como aproveitar os poderosos recursos de extração de texto do IronPDF para acessar e analisar dados tabulares de PDFs baseados em texto. Discutiremos a eficácia desse método, forneceremos estratégias para análise sintática e ofereceremos insights sobre como lidar com as informações extraídas. Além disso, abordaremos estratégias para lidar com cenários mais complexos, incluindo PDFs digitalizados.
Etapas essenciais para extrair dados de tabelas de PDFs em C#
- Instale a biblioteca IronPDF C# ( IronPDF ) para processamento de PDF.
- (Passo opcional do demo) Crie um PDF de exemplo com uma tabela a partir de uma string HTML usando a
RenderHtmlAsPdfdo IronPDF. (Veja a seção: (Passo de Demonstração) Criar um Documento PDF com Dados de Tabela) - Carregue qualquer documento PDF e use o método
ExtractAllTextpara recuperar o conteúdo bruto do texto. (See section: Extract All Text Containing Table Data from the PDF) - Implemente a lógica em C# para analisar o texto extraído e identificar as linhas e células da tabela. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Exiba os dados da tabela estruturada ou salve-os em um arquivo CSV para uso posterior. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Considere técnicas avançadas como OCR para PDFs digitalizados (discutido posteriormente).
IronPDF - Biblioteca PDF em C#
IronPDF é uma biblioteca C# .NET para manipulação de PDFs em .NET ( IronPDF ), que ajuda desenvolvedores a ler, criar e editar documentos PDF facilmente em seus aplicativos de software. Seu robusto mecanismo Chromium renderiza documentos PDF a partir de HTML com alta precisão e velocidade. Permite que os desenvolvedores convertam arquivos de diferentes formatos para PDF e vice-versa de forma integrada. Ele oferece suporte às versões mais recentes do .NET Framework, incluindo .NET 7, .NET 6, 5, 4, .NET Core e Standard.
Além disso, a API IronPDF .NET também permite que os desenvolvedores manipulem e editem PDFs, adicionem cabeçalhos e rodapés e, principalmente, extraiam texto, imagens e (como veremos) dados de tabelas de PDFs com facilidade.
Algumas características importantes incluem:
- Crie arquivos PDF a partir de várias fontes (HTML para PDF, Imagens para PDF)
- Carregar, salvar e imprimir arquivos PDF
- Mesclar e dividir arquivos PDF
- Extrair dados (texto, imagens e dados estruturados, como tabelas) de arquivos PDF
Passos para Extrair Dados de Tabela em C# usando a Biblioteca IronPDF
Para extrair dados de tabelas de documentos PDF, vamos configurar um projeto em C#:
- Visual Studio: Certifique-se de ter o Visual Studio (por exemplo, 2022) instalado. Caso contrário, faça o download no site do Visual Studio ( https://visualstudio.microsoft.com/downloads/ ).
-
Create Project:
-
Abra o Visual Studio 2022 e clique em Criar um novo projeto .
 Tela inicial do Visual Studio
Tela inicial do Visual Studio -
Selecione "Aplicativo de console" (ou o tipo de projeto C# de sua preferência) e clique em Avançar .
 Crie um novo aplicativo de console no Visual Studio.
Crie um novo aplicativo de console no Visual Studio. -
Dê um nome ao seu projeto (por exemplo, "ReadPDFTableDemo") e clique em Avançar .
 Configure o aplicativo recém-criado.
Configure o aplicativo recém-criado. -
Escolha a versão do .NET Framework desejada (por exemplo, .NET 6 ou posterior).
 Selecione uma .NET Framework.
Selecione uma .NET Framework. - Clique em Criar . O projeto do console será criado.
-
-
Instale o IronPDF:
-
Usando o Gerenciador de Pacotes NuGet do Visual Studio:
- Clique com o botão direito do mouse no seu projeto no Solution Explorer e selecione "Gerenciar Pacotes NuGet ..."
 Ferramentas e gerenciamento de pacotes NuGet
Ferramentas e gerenciamento de pacotes NuGet- No Gerenciador de Pacotes NuGet, procure 'IronPDF' e clique em 'Instalar'.
 Ferramentas e gerenciamento de pacotes NuGet
Ferramentas e gerenciamento de pacotes NuGet
- Baixe o pacote NuGet diretamente: Visite a página do pacote NuGet do IronPDF ( https://www. NuGet.org/packages/IronPDF/ ).
- Baixe a biblioteca IronPDF .DLL: Faça o download no site oficial do IronPDF e adicione uma referência ao arquivo DLL em seu projeto.
-
(Etapa de demonstração) Criar um documento PDF com dados em forma de tabela
Para este tutorial, primeiro criaremos um PDF de exemplo contendo uma tabela simples a partir de uma string HTML. Isso nos fornece uma estrutura de PDF conhecida para demonstrar o processo de extração. Em um cenário real, você carregaria seus arquivos PDF já existentes.
Adicione o namespace IronPDF e, opcionalmente, defina sua chave de licença (o IronPDF é gratuito para desenvolvimento, mas requer uma licença para implantação comercial sem marcas d'água):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Aqui está a string HTML para nossa tabela de exemplo:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Agora, use ChromePdfRenderer para criar um PDF a partir deste HTML:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")O método SaveAs salva o PDF. O table_example.pdf gerado ficará assim (imagem conceitual com base no HTML):
 Pesquise por IronPDF na interface do Gerenciador de Pacotes NuGet.
Pesquise por IronPDF na interface do Gerenciador de Pacotes NuGet.
Extrair todo o texto contendo dados de tabela do PDF
Para extrair dados de tabela, primeiro carregamos o PDF (seja aquele que acabamos de criar ou qualquer PDF existente) e usamos o método ExtractAllText. Este método recupera todo o conteúdo textual das páginas do PDF.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()A variável allText agora contém todo o conteúdo de texto do PDF. Você pode exibi-lo para ver a extração bruta:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)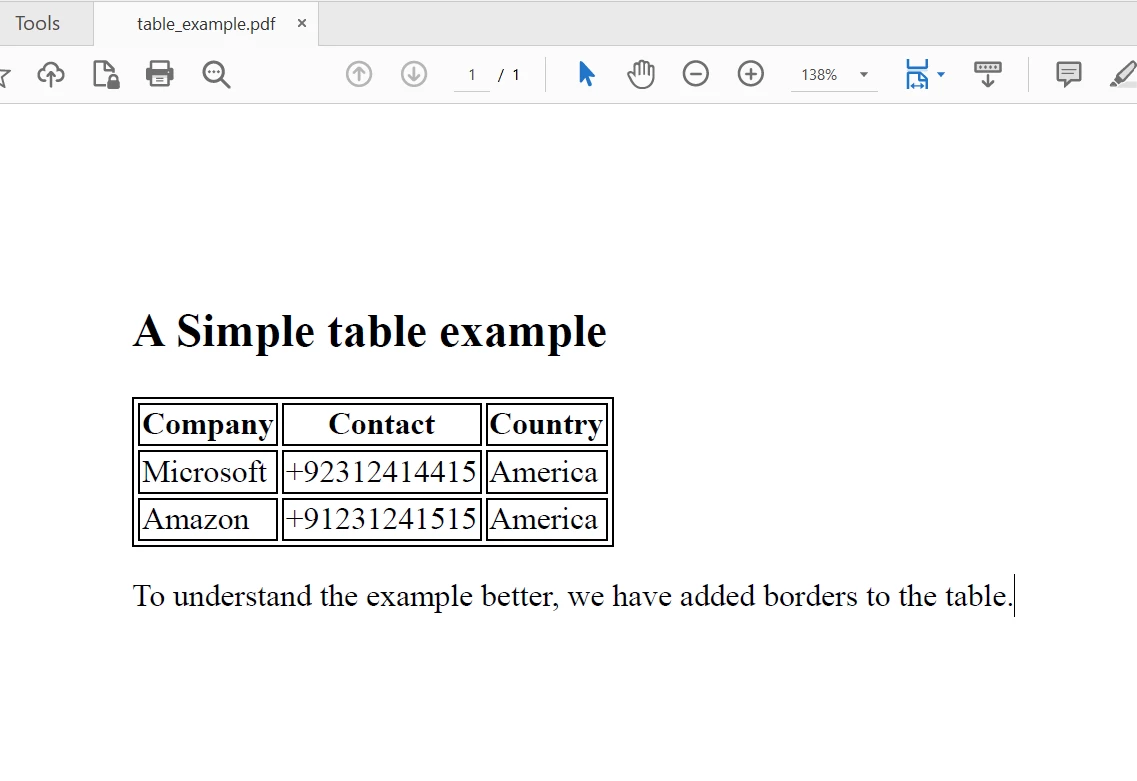 O arquivo PDF para extrair o texto
O arquivo PDF para extrair o texto
Análise de Texto Extraído para Reconstruir Dados de Tabela em C#
Com o texto bruto extraído, o próximo desafio é analisar essa sequência para identificar e estruturar os dados tabulares. Esta etapa depende muito da consistência e do formato das tabelas em seus PDFs.
Estratégias gerais de análise sintática:
- Identificar Delimitadores de Linha: Caracteres de nova linha (
\nou\r\n) são separadores de linha comuns. - Identificar delimitadores de coluna: As células dentro de uma linha podem ser separadas por múltiplos espaços, tabulações ou caracteres específicos conhecidos (como '|' ou ';'). Às vezes, se as colunas estiverem visualmente alinhadas, mas não tiverem delimitadores de texto claros, você pode inferir a estrutura com base em padrões de espaçamento consistentes, embora isso seja mais complexo.
- Filtrar Conteúdo Não-Tabular: O método
ExtractAllTextobtém todo o texto. Você precisará de lógica para isolar o texto que realmente compõe sua tabela, possivelmente procurando por palavras-chave no cabeçalho ou ignorando o texto do preâmbulo/posâmbolo.
O método C# String.Split é uma ferramenta básica para isso. Aqui está um exemplo que tenta extrair apenas as linhas da tabela da nossa amostra, filtrando as linhas com pontos (uma heurística simples para este exemplo específico):
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineEste código divide o texto em linhas. A condição if é um filtro muito básico para este exemplo específico de texto não-tabular. Em cenários reais, você precisaria de uma lógica mais robusta para identificar e analisar linhas e células da tabela com precisão.
Resultado do texto filtrado simples:
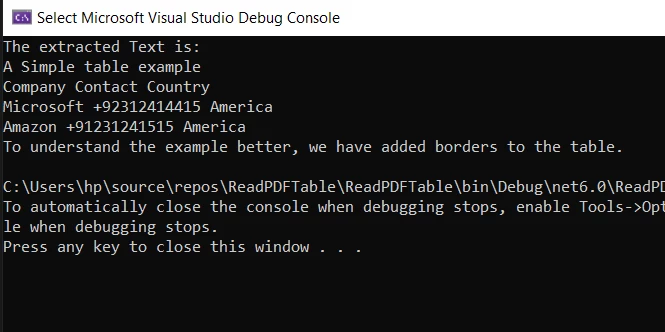 O Console exibe os textos extraídos.
O Console exibe os textos extraídos.
Considerações importantes para o método de análise de texto:
- Ideal para: PDFs baseados em texto com estruturas de tabela simples e consistentes e delimitadores de texto claros.
- Limitações: Este método pode ter dificuldades com:
- Tabelas com células mescladas ou estruturas aninhadas complexas.
- Tabelas onde as colunas são definidas por espaçamento visual em vez de delimitadores de texto.
- Tabelas incorporadas como imagens (requerendo OCR).
- Variações na geração do PDF resultam em ordem inconsistente de extração de texto.
Você pode salvar as linhas filtradas (que idealmente representam as linhas da tabela) em um arquivo CSV:
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Estratégias para Extração de Tabelas em PDF Mais Complexas em C#
Extrair dados de tabelas PDF complexas ou baseadas em imagens geralmente requer técnicas mais avançadas do que a simples análise de texto. O IronPDF oferece recursos que podem ajudar:
- Usando as Capacidades do IronOCR para Tabelas Escaneadas: Se as tabelas estiverem dentro de imagens (por exemplo, PDFs escaneados), apenas
ExtractAllText()não as capturará. A funcionalidade de detecção de texto do IronOCR pode primeiro converter essas imagens em texto.
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingPara obter orientações detalhadas, visite a documentação do IronOCR (https://ironsoftware.com/csharp/ocr/ ). Após o OCR, você analisaria a sequência de texto resultante.
-
Extração de Texto Baseada em Coordenadas (Avançado): Embora o
ExtractAllText()do IronPDF forneça o fluxo de texto, alguns cenários podem se beneficiar de conhecer as coordenadas x,y de cada fragmento de texto. Se o IronPDF oferecer APIs para obter texto com suas informações de caixa delimitadora (verifique a documentação atual), isso poderá permitir uma análise espacial mais sofisticada para reconstruir tabelas com base no alinhamento visual. - Converter PDF para outro formato: O IronPDF pode converter PDFs para formatos estruturados como HTML. Muitas vezes, analisar uma tabela HTML é mais simples do que analisar o texto bruto de um PDF.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Reconhecimento de padrões e expressões regulares: Para tabelas com padrões muito previsíveis, mas delimitadores inconsistentes, expressões regulares complexas aplicadas ao texto extraído podem, por vezes, isolar os dados da tabela.
A escolha da estratégia correta depende da complexidade e da consistência dos seus PDFs de origem. Para muitos documentos empresariais comuns com tabelas baseadas em texto, o ExtractAllText do IronPDF em combinação com lógica de análise inteligente em C# pode ser muito eficaz. Para tabelas baseadas em imagem, suas capacidades de OCR são essenciais.
Resumo
Este artigo demonstrou como extrair dados de tabela de um documento PDF em C# usando o IronPDF, focando principalmente em alavancar o método ExtractAllText() e a subsequente análise de strings. Observamos que, embora essa abordagem seja eficaz para tabelas baseadas em texto, cenários mais complexos, como tabelas baseadas em imagens, podem ser resolvidos usando os recursos de OCR do IronPDF ou convertendo os PDFs para outros formatos primeiro.
O IronPDF oferece um conjunto de ferramentas versátil para desenvolvedores .NET , simplificando muitas tarefas relacionadas a PDFs, desde a criação e edição até a extração completa de dados. Ele oferece métodos como ExtractTextFromPage para extração específica de páginas e suporta conversões de formatos como markdown ou DOCX para PDF.
O IronPDF é gratuito para desenvolvimento e oferece uma licença de avaliação gratuita para testar todos os seus recursos comerciais. Para implantação em produção, estão disponíveis diversas opções de licenciamento.
Para obter mais detalhes e casos de uso avançados, explore a documentação e os exemplos oficiais do IronPDF (https://ironpdf.com/ )
Perguntas frequentes
Como posso ler tabelas de arquivos PDF programaticamente em C#?
Você pode usar o método `ExtractAllText` do IronPDF para extrair texto bruto de documentos PDF. Uma vez extraído, você pode analisar esse texto em C# para identificar linhas e células de tabelas, permitindo a extração de dados estruturados.
Quais são os passos envolvidos na extração de dados de uma tabela a partir de um PDF usando C#?
O processo envolve a instalação da biblioteca IronPDF, o uso do método `ExtractAllText` para recuperar o texto, a análise desse texto para identificar tabelas e, opcionalmente, o salvamento dos dados estruturados em um formato como CSV.
Como posso manipular PDFs digitalizados com tabelas em C#?
Para PDFs digitalizados, o IronPDF pode utilizar OCR (Reconhecimento Óptico de Caracteres) para converter imagens de tabelas em texto, que pode então ser analisado para extrair os dados tabulares.
O IronPDF consegue converter PDFs para outros formatos para facilitar a extração de tabelas?
Sim, o IronPDF pode converter PDFs em HTML, o que pode simplificar a extração de tabelas, permitindo que os desenvolvedores usem técnicas de análise sintática de HTML.
O IronPDF é adequado para extrair dados de tabelas PDF complexas?
O IronPDF oferece recursos avançados como OCR e extração de texto baseada em coordenadas, que podem ser usados para lidar com layouts de tabelas complexos, incluindo aqueles com células mescladas ou delimitadores inconsistentes.
Como posso integrar o IronPDF em uma aplicação .NET Core?
O IronPDF é compatível com aplicações .NET Core. Você pode integrá-lo instalando a biblioteca através do Gerenciador de Pacotes NuGet no Visual Studio.
Quais são os benefícios de usar o IronPDF para manipulação de PDFs em C#?
O IronPDF oferece uma gama versátil de recursos para criar, editar e extrair dados de PDFs, incluindo suporte para OCR e conversão para vários formatos, tornando-se uma ferramenta poderosa para desenvolvedores .NET.
Quais são os desafios comuns ao extrair dados de tabelas de PDFs?
Os desafios incluem lidar com layouts de tabelas complexos, como células mescladas, tabelas incorporadas como imagens e delimitadores inconsistentes, o que pode exigir estratégias avançadas de análise sintática ou OCR.
Como faço para começar a usar o IronPDF para processamento de PDFs?
Comece instalando a biblioteca IronPDF através do Gerenciador de Pacotes NuGet ou baixando-a do site da IronPDF. Essa configuração é essencial para utilizar seus recursos de processamento de PDF em seus projetos C#.
É necessário ter uma licença para usar o IronPDF?
O IronPDF é gratuito para fins de desenvolvimento, mas é necessária uma licença para uso comercial para remover marcas d'água. Uma licença de avaliação gratuita está disponível para testar todos os seus recursos.
O IronPDF é compatível com o .NET 10 para extrair tabelas de PDFs?
Sim. O IronPDF é compatível com o .NET 10 (assim como com o .NET 9, 8, 7, 6, Core, Standard e Framework), portanto, todas as funcionalidades de extração de tabelas funcionam sem modificações em aplicações .NET 10.











