
Comment lire une table PDF en C#
Extraire des données de table structurées de documents PDF est une nécessité fréquente pour les développeurs C#, crucial pour l'analyse de données, la création de rapports ou l'intégration d'informations dans d'autres systèmes. Cependant, les PDF sont principalement conçus pour une présentation visuelle cohérente, pas pour une extraction de données directe. Cela peut rendre la lecture de tableaux à partir de fichiers PDF par programmation en C# une tâche difficile, en particulier car les tableaux peuvent varier considérablement - des grilles simples basées sur du texte aux mises en page complexes avec des cellules fusionnées, ou même des tableaux intégrés en tant qu'images dans des documents scannés.
Ce guide fournit un tutoriel complet en C# sur la façon d'aborder l'extraction de tableaux PDF à l'aide d'IronPDF. Nous explorerons principalement l'utilisation des puissantes capacités d'extraction de texte d'IronPDF pour accéder puis analyser les données tabulaires à partir de PDF basés sur du texte. Nous discuterons de l'efficacité de cette méthode, fournirons des stratégies pour l'analyse, et offrirons des éclairages sur la gestion des informations extraites. De plus, nous aborderons des stratégies pour traiter des scénarios plus complexes, y compris des PDF numérisés.
Étapes clés pour extraire des données de tableau à partir de PDF en C#
- Installez la bibliothèque C# IronPDF (https://nuget.org/packages/IronPdf/) pour le traitement des PDF.
- (Étape de démonstration facultative) Créez un exemple de PDF avec un tableau à partir d'une chaîne HTML en using IronPDF
RenderHtmlAsPdf. (Voir la section : (Étape de démonstration) Créez un document PDF avec des données de table) - Chargez n'importe quel document PDF et utilisez la méthode
ExtractAllTextpour récupérer son contenu textuel brut. (See section: Extract All Text Containing Table Data from the PDF) - Implémentez une logique C# pour analyser le texte extrait et identifier les lignes et cellules de la table. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Exportez les données de table structurées ou enregistrez-les dans un fichier CSV pour une utilisation ultérieure. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Envisagez des techniques avancées comme l'OCR pour les PDF numérisés (à discuter ultérieurement).
IronPDF - Bibliothèque PDF C
IronPDF est une solution de bibliothèque C# .NET pour la manipulation de PDF en .NET (https://ironpdf.com/), qui aide les développeurs à lire, créer et éditer facilement des documents PDF dans leurs applications logicielles. Son moteur Chromium robuste rend les documents PDF à partir de HTML avec une grande précision et rapidité. Il permet aux développeurs de convertir de différents formats vers le PDF et vice versa de manière transparente. Il prend en charge les derniers frameworks .NET, notamment .NET 7, .NET 6, 5, 4, .NET Core, et Standard.
De plus, l'API .NET d'IronPDF permet également aux développeurs de manipuler et éditer les PDF, d'ajouter des en-têtes et pieds de page, et surtout d'extraire du texte, des images, et (comme nous le verrons) des données de table à partir des PDF avec aisance.
Quelques fonctionnalités importantes incluent :
- Créez des fichiers PDF à partir de diverses sources (HTML en PDF, Images en PDF)
- Charger, Sauvegarder, et Imprimer des fichiers PDF
- Fusionner et diviser des fichiers PDF
- Extraire des données (Texte, Images, et données structurées comme des tables) à partir de fichiers PDF
Étapes pour extraire les données de table en C# en utilisant la bibliothèque IronPDF
Pour extraire des données de table des documents PDF, nous allons mettre en place un projet C# :
- Visual Studio : Assurez-vous d'avoir installé Visual Studio (par exemple, 2022). Si ce n'est pas le cas, téléchargez-le depuis le site de Visual Studio (https://visualstudio.microsoft.com/downloads/).
-
Créer un projet :
-
Ouvrez Visual Studio 2022 et cliquez sur Créer un nouveau projet.
 Écran de démarrage de Visual Studio
Écran de démarrage de Visual Studio
-
-
Sélectionnez "Application Console" (ou votre type de projet C# préféré) et cliquez sur Suivant.
 **Créer une nouvelle application console dans Visual Studio** -
Nommez votre projet (par exemple, "ReadPDFTableDemo") et cliquez sur Suivant.
 Configurez la nouvelle application créée
Configurez la nouvelle application créée-
Choisissez votre framework .NET désiré (par exemple, .NET 6 ou supérieur).
 Sélectionnez un framework .NET
Sélectionnez un framework .NET - Cliquez sur Créer. Le projet console sera créé.
-
- Installez IronPDF:
- Utilisation du gestionnaire de packages NuGet de Visual Studio :
-
Faites un clic droit sur votre projet dans l'Explorateur de solutions et sélectionnez "Gérer les packages NuGet..."
 **Outils & Gérer les packages NuGet** -
Dans le gestionnaire de packages NuGet, recherchez "IronPDF" et cliquez sur "Installer".
 Outils & Gérer les packages NuGet
Outils & Gérer les packages NuGet- Téléchargez directement le package NuGet : visitez la page du package NuGet d'IronPDF ( https://www. NuGet.org/packages/ IronPDF/ ).
- Téléchargez la bibliothèque IronPDF .DLL : Téléchargez-la depuis le site Web officiel IronPDF et référencez la DLL dans votre projet.
(Étape de démonstration) Créez un document PDF avec des données de table
Pour ce tutoriel, nous allons d'abord créer un PDF exemple contenant une table simple à partir d'une chaîne HTML. Cela nous donne une structure PDF connue pour démontrer le processus d'extraction. Dans un scénario réel, vous chargeriez vos fichiers PDF préexistants.
Ajoutez l'espace de noms IronPDF et définissez éventuellement votre clé de licence (IronPDF est gratuit pour le développement mais nécessite une licence pour le déploiement commercial sans filigrane) :
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Voici la chaîne HTML pour notre table exemple :
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Utilisez maintenant ChromePdfRenderer pour créer un PDF à partir de ce code HTML :
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")La méthode SaveAs enregistre le PDF. Le code généré table_example.pdf ressemblera à ceci (image conceptuelle basée sur HTML) :
 Rechercher IronPDF dans l'interface utilisateur du Package Manager NuGet
Rechercher IronPDF dans l'interface utilisateur du Package Manager NuGet
Extraire tout le texte contenant des données de table du PDF
Pour extraire les données du tableau, nous chargeons d'abord le PDF (soit celui que nous venons de créer, soit n'importe quel PDF existant) et utilisons la méthode ExtractAllText. Cette méthode récupère tout le contenu textuel des pages PDF.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()La variable allText contient désormais l'intégralité du contenu textuel du PDF. Vous pouvez l'afficher pour voir l'extraction brute :
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)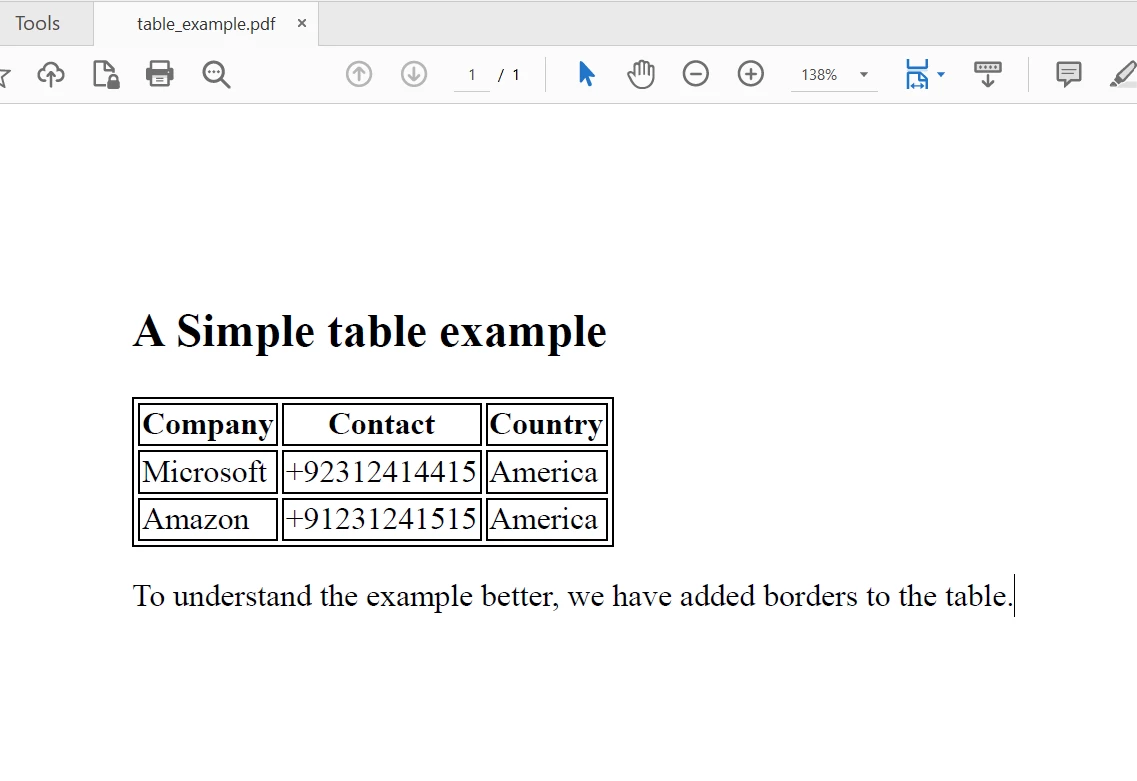 Le fichier PDF à partir duquel extraire du texte
Le fichier PDF à partir duquel extraire du texte
Analyse du texte extrait pour reconstruire les données de tableau en C#
Avec le texte brut extrait, le prochain défi est d'analyser cette chaîne pour identifier et structurer les données tabulaires. Cette étape dépend en grande partie de la cohérence et du format des tables dans vos PDF.
Stratégies de parsing générales :
- Identifier les délimiteurs de lignes : les caractères de nouvelle ligne (
\nou\r\n) sont des séparateurs de lignes courants. - Identifier les délimiteurs de colonnes : Les cellules à l'intérieur d'une ligne peuvent être séparées par plusieurs espaces, tabulations ou caractères connus spécifiques (comme '|' ou ';'). 3. Filtrer le contenu non tabulaire : La méthode ExtractAllText récupère tout le texte.
- Filtrer le contenu non tabulaire : La méthode
ExtractAllTextrécupère tout le texte. La méthode C# String.Split est un outil essentiel.
La méthode C# String.Split est un outil de base pour cela. Ce code divise le texte en lignes.
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineLa condition if est un filtre très basique pour le texte non-tabulaire de cet exemple spécifique. La condition if est un filtre très basique pour le texte non tabulaire de cet exemple spécifique . Dans des scénarios réels, vous auriez besoin d'une logique plus robuste pour identifier et analyser avec précision les lignes et les cellules des tableaux.
Sortie du texte filtré simple :
 La console affiche les textes extraits
La console affiche les textes extraits
-
Idéal pour : PDFs basés sur du texte avec des structures de tables simples et cohérentes et des délimiteurs textuels clairs.
- Limites : Cette méthode peut rencontrer des difficultés avec :
- Limitations : Cette méthode peut rencontrer des difficultés avec :
- Des tables où les colonnes sont définies par l'espacement visuel plutôt que par des délimiteurs textuels.
- Des tables intégrées sous forme d'images (nécessitant un OCR).
- Des variations dans la génération de PDF entraînant un ordre d'extraction de texte incohérent.
- Variations dans la génération de PDF conduisant à un ordre d'extraction de texte incohérent.
Vous pouvez enregistrer les lignes filtrées (qui représentent idéalement des lignes de table) dans un fichier CSV :
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Stratégies pour l'Extraction de Tableaux PDF plus Complexes en C#
IronPDF offre des fonctionnalités qui peuvent aider : IronPDF propose des fonctionnalités qui peuvent aider :
- Utilisation des capacités d'IronOCR pour les tableaux numérisés : si les tableaux se trouvent dans des images (par exemple, des PDF numérisés),
ExtractAllText()seul ne les capturera pas. Pour un guide détaillé, visitez la documentation IronOCR (https://ironsoftware.com/csharp/ocr/).
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingPour des conseils détaillés, consultez la documentation d'IronOCR (https://ironsoftware.com/csharp/ocr/). Après OCR, vous analyserez la chaîne de texte résultante.
-
Extraction de texte basée sur les coordonnées (avancée) : Bien que IronPDF
ExtractAllText()fournisse le flux de texte, certains scénarios pourraient bénéficier de la connaissance des coordonnées x,y de chaque extrait de texte. * Conversion de PDF vers un autre format : IronPDF peut convertir les PDF en formats structurés comme HTML. - Conversion de PDF en un Autre Format : IronPDF peut convertir des PDFs en formats structurés comme HTML. * Reconnaissance de modèles et expressions régulières : Pour les tables avec des modèles très prévisibles mais des délimiteurs incohérents, des expressions régulières complexes appliquées au texte extrait peuvent parfois isoler les données de table.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Reconnaissance de Motifs et Expressions Régulières : Pour les tableaux avec des motifs très prévisibles mais des délimiteurs incohérents, des expressions régulières complexes appliquées au texte extrait peuvent parfois isoler les données du tableau.
Pour de nombreux documents commerciaux courants avec des tables basées sur du texte, l'ExtractAllText d'IronPDF couplé à une logique d'analyse C# intelligente peut être très efficace. Pour les tables basées sur des images, ses capacités d'OCR sont essentielles. Pour de nombreux documents commerciaux courants contenant des tableaux textuels, la technologie IronPDF (ExtractAllText), associée à une logique d'analyse syntaxique C# intelligente, peut s'avérer très efficace. Pour les tableaux d'images, ses capacités de reconnaissance optique de caractères (OCR) sont essentielles.
Résumé
Cet article a démontré comment extraire des données de tableau d'un document PDF en C# en using IronPDF , en se concentrant principalement sur l'utilisation de la méthode ExtractAllText() et l'analyse de chaîne subséquente. IronPDF fournit un ensemble d'outils polyvalents pour les développeurs .NET, simplifiant de nombreuses tâches liées aux PDF, de la création et l'édition à l'extraction complète de données.
IronPDF fournit une boîte à outils polyvalente pour les développeurs .NET, simplifiant de nombreuses tâches liées aux PDF, de la création et de l'édition à l'extraction de données complète. Il offre des méthodes comme ExtractTextFromPage pour l'extraction spécifique à la page et prend en charge les conversions de formats comme markdown ou DOCX vers PDF.
IronPDF est gratuit pour le développement et propose une licence d'essai gratuite pour tester toutes ses fonctionnalités commerciales. Pour le déploiement en production, diverses options de licence sont disponibles.
Pour plus de détails et des cas d'utilisation avancés, explorez la documentation et les exemples officiels d'IronPDF (https://ironpdf.com/)
Questions Fréquemment Posées
Comment puis-je lire des tableaux à partir de fichiers PDF par programmation en C# ?
Vous pouvez utiliser la méthode `ExtractAllText` de IronPDF pour extraire le texte brut des documents PDF. Une fois extrait, vous pouvez analyser ce texte en C# pour identifier les lignes et cellules de table, permettant ainsi l'extraction de données structurées.
Quelles étapes sont impliquées dans l'extraction de données de table à partir d'un PDF en utilisant C# ?
Le processus implique l'installation de la bibliothèque IronPDF, l'utilisation de la méthode `ExtractAllText` pour récupérer le texte, l'analyse de ce texte pour identifier les tables, et éventuellement l'enregistrement des données structurées dans un format comme CSV.
Comment puis-je traiter les PDF scannés avec tables en C# ?
Pour les PDF scannés, IronPDF peut utiliser OCR (reconnaissance optique de caractères) pour convertir les images de tables en texte, qui peut ensuite être analysé pour extraire les données tabulaires.
IronPDF peut-il convertir des PDF en d'autres formats pour une extraction de table plus facile ?
Oui, IronPDF peut convertir des PDF en HTML, ce qui peut simplifier l'extraction de tables en permettant aux développeurs d'utiliser des techniques d'analyse HTML.
IronPDF est-il adapté à l'extraction de données à partir de tableaux PDF complexes ?
IronPDF offre des capacités avancées comme l'OCR et l'extraction de texte basée sur les coordonnées, qui peuvent être employées pour gérer des mises en page complexes de tableaux, y compris celles avec des cellules fusionnées ou des délimiteurs incohérents.
Comment puis-je intégrer IronPDF dans une application .NET Core ?
IronPDF est compatible avec les applications .NET Core. Vous pouvez l'intégrer en installant la bibliothèque via le gestionnaire de packages NuGet de Visual Studio.
Quels sont les avantages d'utiliser IronPDF pour la manipulation de PDF en C# ?
IronPDF offre une gamme polyvalente de fonctionnalités pour créer, éditer et extraire des données à partir de PDF, y compris le support de l'OCR et la conversion vers divers formats, en faisant un outil puissant pour les développeurs .NET.
Quels sont les défis courants lors de l'extraction de données de tableau à partir de PDF ?
Les défis incluent la gestion de mises en page complexes de tableaux, comme les cellules fusionnées, les tableaux intégrés comme images et les délimiteurs incohérents, ce qui peut nécessiter des stratégies d'analyse avancées ou l'OCR.
Comment commencer à utiliser IronPDF pour le traitement des PDF ?
Commencez par installer la bibliothèque IronPDF via le gestionnaire de packages NuGet ou en la téléchargeant depuis le site web d'IronPDF. Cette configuration est essentielle pour utiliser ses capacités de traitement de PDF dans vos projets C#.
L'utilisation d'IronPDF nécessite-t-elle une licence ?
IronPDF est gratuit pour le développement, mais une licence est requise pour un déploiement commercial afin de supprimer les filigranes. Une licence d'essai gratuite est disponible pour tester ses fonctionnalités complètes.
IronPDF est-il compatible avec .NET 10 pour l'extraction de tableaux à partir de fichiers PDF ?
Oui. IronPDF prend en charge .NET 10 (ainsi que .NET 9, 8, 7, 6, Core, Standard et Framework), donc toutes les fonctionnalités d'extraction de tableaux fonctionnent sans modification dans les applications .NET 10.













