
如何在 Python 中从发票 PDF 提取数据
本文将讨论如何使用IronPDF库为Python从发票PDF文件中提取文本数据。
如何在Python中从PDF中提取发票数据
- 安装用于从PDF发票中提取数据的Python库。
- 使用
PdfDocument.FromFile方法打开PDF文件。 - 使用
ExtractAllText方法提取发票中的所有数据。 - 使用
print方法打印从发票中提取的所有数据。 - 从发票数据中提取特定数据。
1. IronPDF
IronPDF for Python是一个强大的库,使用Python作为桥梁连接Python应用程序和PDF文档。 这个多功能工具为开发人员提供了在Python项目中轻松创建、操作和与PDF文件交互的方法。 以下是一些使IronPDF成为有价值工具的突出功能:
- PDF生成: IronPDF支持从头动态生成PDF文件,允许开发人员以编程方式创建具有自定义内容、样式和布局的PDF。
- HTML到PDF转换: 它可以将HTML内容,包括网页,转换为高质量的PDF,保留原始HTML的布局和样式,这对于生成报告和文档特别有用。
- PDF编辑: 开发人员可以通过添加、修改或删除文本、图像和交互元素轻松编辑现有的PDF,使其成为一个强大的文档操作工具。
- PDF合并和拆分: IronPDF允许您将多个PDF文档合并为一个文件或将一个PDF拆分为多个文件,在管理大量PDF时提供灵活性。
- PDF表单: 它支持创建和填写交互式PDF表单,非常适合需要用户输入和数据收集的应用程序。
- 数字签名: 您可以为PDF文档添加数字签名,确保文件的完整性和真实性,这对于法律和安全目的至关重要。
- PDF数据提取: IronPDF提供提取功能以保护PDF中的信息。
2. 环境设置
在Python中设置IronPDF环境需要几个步骤以确保您能有效地使用该库。 以下是分步指南:
- 在PyCharm中创建一个新的Python项目并创建一个虚拟环境或使用现有的解释器。
- 通过运行以下命令在终端中使用命令行终端安装IronPDF:
pip install ironpdf
 从命令行安装IronPDF
从命令行安装IronPDF
3. 使用IronPDF从发票中提取数据
本节将介绍如何使用IronPDF的Python库从发票格式和输出格式中提取数据。 以下代码将从发票中提取所有数据并在控制台中打印出来。
示例发票
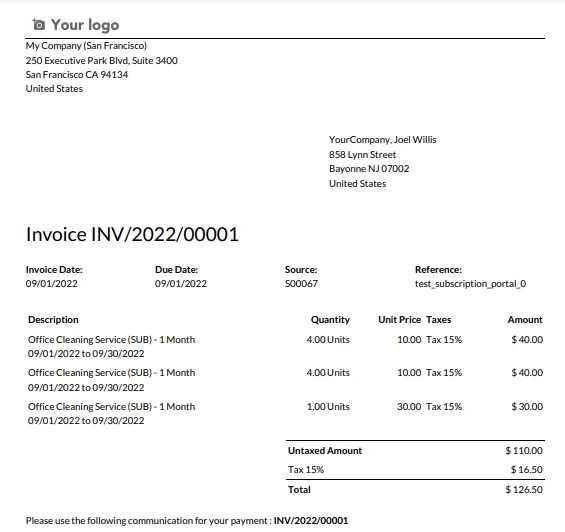 示例发票
示例发票
from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)上述代码使用PdfDocument.FromFile方法加载名为"INV_2022_00001.pdf"的特定PDF文件。 随后,它从加载的PDF文档中提取所有文本内容,并将其存储在变量all_text中。 最后,使用print函数将提取的文本打印到控制台。 本质上,这段代码自动化了从PDF文件中提取结构化和非结构化文本数据的过程,使其可用于在Python环境中的进一步处理或分析。
3.1. 输出
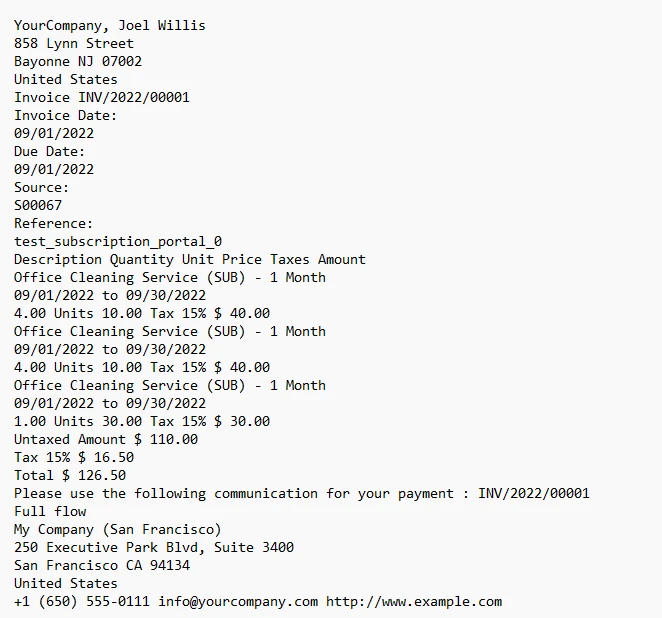 发票中的文本输出到控制台
发票中的文本输出到控制台
4. 从发票中提取特定数据
使用IronPDF提取发票数据是一个相当简单的过程。 从PDF发票数据中提取诸如发票编号和金额等数据可能是一个棘手的过程,但使用IronPDF结合Python开源库re,可以实现。 以下代码将从PDF发票中提取特定数据并在控制台中打印出来。
from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)这段代码片段利用Python和IronPDF库从PDF文档中执行数据提取。 它首先导入必要的库并定义正则表达式模式,以识别PDF文本内容中的发票号码和总金额。 然后代码加载目标PDF,提取其所有文本,并继续搜索匹配定义的模式。
如果找到了成功的匹配,它将存储相应的发票号和金额的值; 否则,它将分配"Not found"。 最后,该脚本将提取的发票号码和金额打印到控制台,提供了一种简化的方法来自动化从PDF文档中提取特定数据,这是一种在各种数据处理和会计应用中常见的任务。
4.1. 输出
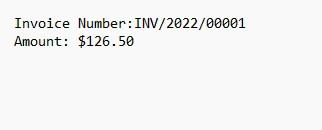 输出文本
输出文本
5. 结论
在当今快节奏的商业环境中,Python作为一种强大的盟友,帮助组织通过自动化从PDF发票中提取重要数据来简化其财务操作。 利用Python的功能和IronPDF库,企业可以显著减少手动数据输入,降低错误,节省时间,并提高管理发票会计流程的整体效率。 IronPDF以其多功能功能,如PDF生成、HTML到PDF转换、PDF编辑、合并、拆分、表单处理、数字签名以及准确的数据提取,成为这些任务的强大工具。
通过遵循简单的设置程序,Python开发人员可以迅速将IronPDF集成到他们的项目中,彻底改变其发票处理工作流程,使从发票中提取数据的流程顺畅而高效。 使用IronPDF进行数据提取的代码示例可在详尽的代码示例中找到。 在IronPDF for Python上使用数据提取的完整教程可以在下面的Python教程中查看,对于使用C#提取发票,请参阅IronOCR教程。
常见问题解答
如何使用Python从PDF发票中提取文本?
您可以使用IronPDF的PdfDocument.FromFile方法加载PDF,并使用ExtractAllText方法从文档中检索所有文本内容。
如何安装 IronPDF for Python?
使用Python包管理器pip通过命令pip install ironpdf安装IronPDF。
我可以用Python从PDF中提取特定数据,比如发票号码吗?
可以,使用IronPDF结合Python的re库,您可以定义正则表达式模式来提取PDF发票中特定的数据,例如发票号码和金额。
IronPDF for Python有哪些功能?
IronPDF提供的功能包括PDF生成、HTML转PDF转换、PDF编辑、合并、分割、表单处理、数字签名和数据提取。
IronPDF可以在Python中将HTML转换为PDF吗?
可以,IronPDF可以将HTML内容(包括网页)转换为高质量的PDF,保留原始HTML的布局和样式。
IronPDF如何提高发票数据提取的生产力?
IronPDF自动提取PDF发票中的数据,减少手动输入和错误,从而节省时间并提高财务操作中的生产力。
IronPDF能够在Python中编辑PDF文档吗?
是的,IronPDF 允许开发人员通过添加、修改或删除文本、图像和交互元素来编辑现有 PDF。
IronPDF可以在Python中合并或分割PDF文档吗?
可以,IronPDF提供将多个PDF文档合并为单个文件或将PDF分割成多个文件的功能。
IronPDF支持在Python中为PDF添加数字签名吗?
可以,IronPDF允许您为PDF文档添加数字签名,确保文件的完整性和真实性。
为什么IronPDF被认为是一个强大的Python开发工具?
IronPDF被认为强大是因为其在处理各种PDF操作(包括生成、转换、编辑和数据提取)方面的全面能力,这对于开发人员来说是必不可少的。
















