
Comment déplacer des pages PDF en C# avec IronPDF

Déplacer des pages au sein d'un document PDF (ou les transférer entre deux documents) est une opération fréquente lors de l'organisation de rapports, de la préparation de bulletins d'information mensuels ou de la restructuration de fichiers à plusieurs sections avant leur livraison. Avec IronPDF, l'opération entière ne nécessite que quelques lignes de code C#.
Cet article décrit quatre scénarios pratiques : le déplacement d'une seule page vers une nouvelle position dans un document, le réarrangement de plusieurs pages à la fois, le transfert de pages entre deux fichiers PDF et la compréhension des cas d'utilisation courants qui sous-tendent ces flux de travail. Chaque scénario comprend un exemple de code fonctionnel et une image de sortie montrant le résultat.
Démarrez votre essai gratuit pour suivre les exemples ci-dessous.
Comment commencer avec IronPDF ?
Ajoutez IronPDF à n'importe quel projet .NET à l'aide de la console du gestionnaire de packages NuGet ou de l'interface de ligne de commande .NET . Ce package cible .NET Standard 2.0 et fonctionne sur .NET Framework 4.6.2+, .NET Core et toutes les versions modernes de .NET , y compris .NET 8 et .NET 10.
dotnet add package IronPdfdotnet add package IronPdfAprès l'installation, ajoutez using IronPdf; en haut de votre fichier C#. Une clé de licence valide débloque l'utilisation commerciale complète ; Une licence d'essai gratuite couvre l'évaluation et le développement. Définissez la clé une seule fois avant d'appeler une API :
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Une fois le paquetage référencé et la licence configurée, chaque exemple de cet article se compilera et s'exécutera sans modification. Le package NuGet IronPDF installe automatiquement toutes les dépendances requises ; Aucun binaire natif supplémentaire ni configuration d'exécution n'est nécessaire sous Windows, Linux ou macOS.
Comment déplacer une seule page dans un document PDF ?
Déplacer une page dans un document PDF à l'aide d' IronPDF implique trois étapes : copier la page cible, l'insérer à la nouvelle position, puis supprimer l'original. La classe PdfDocument fournit CopyPage, InsertPdf et RemovePage pour gérer chaque partie de cette opération.
Le code suivant illustre le déplacement de la dernière page d'un document au début :
using IronPdf;
// Load the PDF document from the file system
var pdf = PdfDocument.FromFile("report.pdf");
// Get the zero-based index of the last page
int lastPageIndex = pdf.PageCount - 1;
// Copy the last page into a standalone PdfDocument
var pageToCopy = pdf.CopyPage(lastPageIndex);
// Insert the copied page at position 0 (the first page slot)
pdf.InsertPdf(pageToCopy, 0);
// The original last page has shifted down by one; remove it
pdf.RemovePage(lastPageIndex + 1);
// Save the reordered document to a new file
pdf.SaveAs("report-reorganized.pdf");using IronPdf;
// Load the PDF document from the file system
var pdf = PdfDocument.FromFile("report.pdf");
// Get the zero-based index of the last page
int lastPageIndex = pdf.PageCount - 1;
// Copy the last page into a standalone PdfDocument
var pageToCopy = pdf.CopyPage(lastPageIndex);
// Insert the copied page at position 0 (the first page slot)
pdf.InsertPdf(pageToCopy, 0);
// The original last page has shifted down by one; remove it
pdf.RemovePage(lastPageIndex + 1);
// Save the reordered document to a new file
pdf.SaveAs("report-reorganized.pdf");Imports IronPdf
' Load the PDF document from the file system
Dim pdf = PdfDocument.FromFile("report.pdf")
' Get the zero-based index of the last page
Dim lastPageIndex As Integer = pdf.PageCount - 1
' Copy the last page into a standalone PdfDocument
Dim pageToCopy = pdf.CopyPage(lastPageIndex)
' Insert the copied page at position 0 (the first page slot)
pdf.InsertPdf(pageToCopy, 0)
' The original last page has shifted down by one; remove it
pdf.RemovePage(lastPageIndex + 1)
' Save the reordered document to a new file
pdf.SaveAs("report-reorganized.pdf")Sortie PDF réorganisée
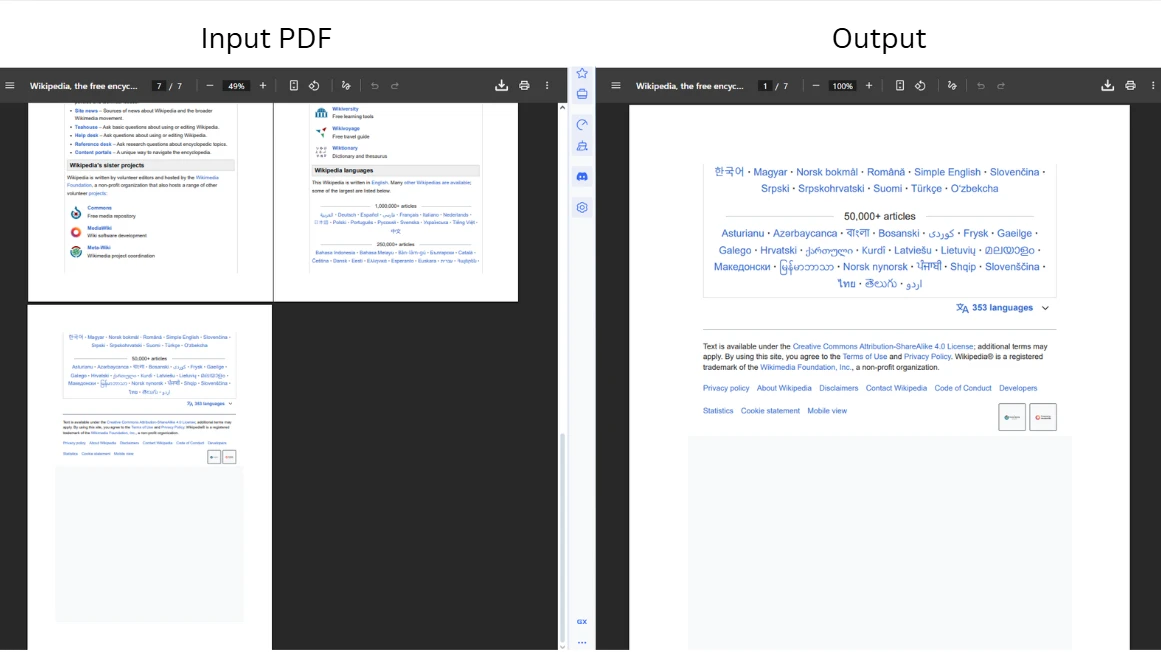
Le code charge un fichier PDF et appelle CopyPage pour extraire la dernière page par son index à base zéro. IronPDF utilise une numérotation de page à partir de zéro dans toute son API, donc la première page est l'index 0 et la dernière est PageCount - 1. Après l'insertion de la copie à la position 0, la page originale se décale d'une position vers le bas dans la séquence d'index ; L'appel de suppression tient compte de cela en ciblant lastPageIndex + 1 plutôt que lastPageIndex. Le passage d'un index hors plage génère une erreur ArgumentOutOfRangeException , vérifiez donc toujours le nombre de pages avant d'opérer sur les positions de bord.
Pour une analyse plus approfondie des opérations de copie et de suppression individuelles, le guide " Ajouter, copier et supprimer des pages PDF " couvre chaque méthode en détail.
Quel est l'impact de l'indexation des pages à base zéro sur l'étape de suppression ?
Comme l'insertion décale d'une position tous les index de page suivants vers le haut, la page originale se retrouve une position plus loin que prévu après une copie et une insertion. Le modèle pdf.RemovePage(lastPageIndex + 1) capture ce Shift. Le même principe s'applique lors du déplacement de pages au milieu d'un document : toute page initialement à l'index N qui se trouve après le point d'insertion se trouvera à l'index N+1 une fois que la copie sera insérée avant elle.
La validation des calculs d'index avant l'enregistrement permet d'éviter les erreurs de tri silencieuses, notamment dans les pipelines par lots où la longueur des documents varie. Une vérification rapide par rapport à pdf.PageCount avant chaque opération permet de maintenir la logique correcte quelle que soit la taille du document.
Quelle est la procédure à suivre pour déplacer plusieurs pages à la fois ?
Lorsque plusieurs pages doivent être déplacées, CopyPages extrait un ensemble spécifique de pages en un seul appel. La méthode accepte une liste d'index de pages à base zéro et renvoie un nouveau PdfDocument contenant uniquement ces pages, dans l'ordre spécifié. Cette approche convient à des scénarios tels que le déplacement d'un bloc contigu de pages d'annexe à la fin d'un rapport, ou le placement d'un ensemble de pages de résumé au début.
using IronPdf;
using System.Collections.Generic;
// Load the quarterly report
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Copy pages at indexes 1 and 2 (the second and third pages)
var selectedPages = pdf.CopyPages(new List<int> { 1, 2 });
// Append the copied pages to the end of the original document
var result = PdfDocument.Merge(pdf, selectedPages);
// Remove the originals at their former positions (now indexes 1 and 2)
result.RemovePages(new List<int> { 1, 2 });
// Write the reordered result to a new path
result.SaveAs("quarterly-report-reordered.pdf");using IronPdf;
using System.Collections.Generic;
// Load the quarterly report
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Copy pages at indexes 1 and 2 (the second and third pages)
var selectedPages = pdf.CopyPages(new List<int> { 1, 2 });
// Append the copied pages to the end of the original document
var result = PdfDocument.Merge(pdf, selectedPages);
// Remove the originals at their former positions (now indexes 1 and 2)
result.RemovePages(new List<int> { 1, 2 });
// Write the reordered result to a new path
result.SaveAs("quarterly-report-reordered.pdf");Imports IronPdf
Imports System.Collections.Generic
' Load the quarterly report
Dim pdf = PdfDocument.FromFile("quarterly-report.pdf")
' Copy pages at indexes 1 and 2 (the second and third pages)
Dim selectedPages = pdf.CopyPages(New List(Of Integer) From {1, 2})
' Append the copied pages to the end of the original document
Dim result = PdfDocument.Merge(pdf, selectedPages)
' Remove the originals at their former positions (now indexes 1 and 2)
result.RemovePages(New List(Of Integer) From {1, 2})
' Write the reordered result to a new path
result.SaveAs("quarterly-report-reordered.pdf")Sortie de réorganisation de plusieurs pages

Le code copie deux pages du document source, les fusionne à la fin en utilisant PdfDocument.Merge, puis supprime les originaux pour terminer le réordonnancement. La méthode Merge renvoie un nouvel objet PdfDocument qui combine les deux entrées dans l'ordre : le document original suivi des pages extraites. La suppression des originaux désormais dupliqués permet d'obtenir le document final dans l'ordre prévu, sans aucun contenu redondant.
La méthode RemovePages accepte une liste d'index à base zéro et supprime toutes les pages spécifiées en une seule passe. Lors de la suppression de plusieurs pages, fournissez tous les index en un seul appel plutôt que d'appeler RemovePage dans une boucle, car chaque suppression individuelle décale les index restants et peut provoquer des erreurs de décalage d'un.
Le tutoriel " Fusionner ou diviser les PDF " aborde des stratégies supplémentaires pour combiner et diviser des documents, notamment la division par plage de pages.
Comment gérer les groupes de pages non contiguës ?
CopyPages accepte n'importe quel IEnumerable<int>, donc les pages non contiguës sont prises en charge naturellement. Passez new List<int> { 0, 3, 7 } pour copier la première, la quatrième et la huitième page dans un seul document dans cet ordre. Il n'est pas nécessaire de trier la liste d'index, ce qui permet un contrôle total sur la séquence de sortie. Cette flexibilité est utile lors de l'assemblage d'un document personnalisé à partir de pages spécifiques d'un long fichier source, par exemple pour extraire uniquement les pages de résumé d'un rapport à plusieurs chapitres.
Si l'objectif est de réorganiser entièrement un document plutôt que de déplacer un sous-ensemble, la création d'un tableau d'index qui répertorie toutes les positions de page dans l'ordre souhaité et son passage à CopyPages crée le document réorganisé en une seule opération. Le tutoriel C# sur la réorganisation des pages PDF couvre en détail ce modèle de réorganisation de document complet.
Comment déplacer des pages entre deux fichiers PDF ?
Le transfert de pages d'un document PDF à un autre suit le même modèle de copie-insertion, appliqué à deux instances distinctes PdfDocument. Il s'agit de l'approche standard pour consolider le contenu provenant de plusieurs fichiers sources : par exemple, déplacer certaines pages d'approbation d'un brouillon vers le document contractuel final.
using IronPdf;
// Load the source and destination documents
var sourceDoc = PdfDocument.FromFile("source-document.pdf");
var destinationDoc = PdfDocument.FromFile("destination-document.pdf");
// Extract the first page (index 0) from the source document
var pageToMove = sourceDoc.CopyPage(0);
// Insert the extracted page at position 2 in the destination (third page slot)
destinationDoc.InsertPdf(pageToMove, 2);
// Save the updated destination document
destinationDoc.SaveAs("destination-document-updated.pdf");
// Remove the transferred page from the source and save separately
sourceDoc.RemovePage(0);
sourceDoc.SaveAs("source-document-updated.pdf");using IronPdf;
// Load the source and destination documents
var sourceDoc = PdfDocument.FromFile("source-document.pdf");
var destinationDoc = PdfDocument.FromFile("destination-document.pdf");
// Extract the first page (index 0) from the source document
var pageToMove = sourceDoc.CopyPage(0);
// Insert the extracted page at position 2 in the destination (third page slot)
destinationDoc.InsertPdf(pageToMove, 2);
// Save the updated destination document
destinationDoc.SaveAs("destination-document-updated.pdf");
// Remove the transferred page from the source and save separately
sourceDoc.RemovePage(0);
sourceDoc.SaveAs("source-document-updated.pdf");Imports IronPdf
' Load the source and destination documents
Dim sourceDoc = PdfDocument.FromFile("source-document.pdf")
Dim destinationDoc = PdfDocument.FromFile("destination-document.pdf")
' Extract the first page (index 0) from the source document
Dim pageToMove = sourceDoc.CopyPage(0)
' Insert the extracted page at position 2 in the destination (third page slot)
destinationDoc.InsertPdf(pageToMove, 2)
' Save the updated destination document
destinationDoc.SaveAs("destination-document-updated.pdf")
' Remove the transferred page from the source and save separately
sourceDoc.RemovePage(0)
sourceDoc.SaveAs("source-document-updated.pdf")Sortie de transfert inter-documents
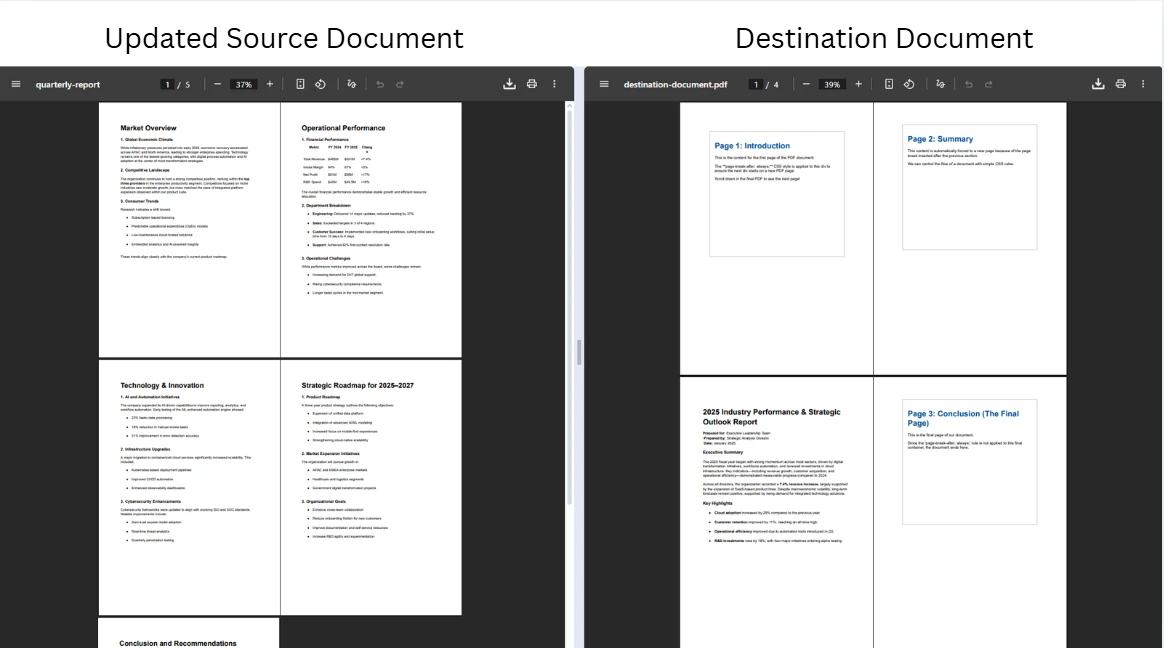
Le code charge deux documents indépendamment, copie une page de la source en utilisant CopyPage, et l'insère dans la destination à l'index spécifié en utilisant InsertPdf. La source et la destination sont enregistrées dans des fichiers distincts, à des emplacements différents, de sorte qu'aucun n'écrase l'autre pendant l'opération. Il est sûr d'enregistrer d'abord la destination et ensuite la source car CopyPage produit une copie indépendante ; le document source n'est pas modifié tant que RemovePage n'est pas appelé.
Les deux appels SaveAs écrivent dans le système de fichiers, mais IronPDF prend également en charge les flux de travail en mémoire via les méthodes de sortie BinaryData et Stream sur PdfDocument. Ceci est utile dans les applications web où un PDF modifié doit être renvoyé en tant que réponse HTTP sans être écrit sur le disque. Le guide " Transformer les pages PDF " aborde des modèles de manipulation en mémoire supplémentaires.
Comment conserver ses signets et annotations lors du déplacement de pages ?
Lorsqu'une page est copiée avec CopyPage, IronPDF préserve le contenu visuel de la page, y compris le texte, les images, les champs de formulaire et les propriétés de rendu. Les signets (ou listes de liens) qui ne font référence qu'à la page déplacée sont conservés dans la copie, mais les hiérarchies de signets inter-documents qui font référence à plusieurs pages ne sont pas mises à jour automatiquement. Pour les documents comportant des arborescences de signets complexes, vérifiez le résultat dans un lecteur PDF après avoir déplacé les pages afin de vous assurer que les liens de navigation internes pointent vers les destinations correctes.
Les annotations et les données des champs de formulaire intégrées directement dans la couche page sont préservées lors de l'opération de copie. Si le document source utilise des destinations nommées pour les liens internes, ces destinations conservent leurs noms dans la page copiée, mais les liens dans d'autres parties du document de destination ne les résoudront pas à moins que les destinations nommées ne soient enregistrées dans le catalogue du document de destination.
Quels sont les cas d'utilisation courants pour la réorganisation des pages PDF ?
Les développeurs doivent déplacer et réorganiser des pages PDF dans un large éventail de scénarios pratiques. Le modèle de page PDF défini dans la spécification PDF représente chaque page comme un objet indépendant dans l'arborescence des pages du document, c'est pourquoi les opérations de copie-insertion-suppression sur des pages individuelles sont toujours valides quelle que soit la longueur du document. Comprendre ces modèles est utile pour concevoir des chaînes de traitement de documents capables de gérer des structures d'entrée variées.
| Scénario | Fonctionnement typique | Méthodes IronPDF |
|---|---|---|
| Assemblage du bulletin d'information mensuel | Déplacer la page de couverture ou la table des matières au début | `CopyPage` , `InsertPdf` , `RemovePage` |
| Génération de rapports | Repositionner les pages de résumé ou insérer des séparateurs de section | `CopyPages` , `Merge` , `RemovePages` |
| Consolidation de documents | Extraire les pages sélectionnées de plusieurs fichiers sources dans un seul fichier de sortie | `CopyPage` , `InsertPdf` , `SaveAs` |
| réorganisation des archives | Réorganiser les pages par ordre chronologique ou catégoriel pour les fichiers de référence | `CopyPages` , `Merge` , `RemovePages` |
| Préparation des contrats | Déplacez les pages d'approbation ou de signature à l'emplacement requis. | `CopyPage` , `InsertPdf` , `RemovePage` |
Au-delà de la simple manipulation de pages, IronPDF prend en charge l'ensemble des opérations sur les documents au sein d'un même processus. L'ajout d'en-têtes et de pieds de page , l'application de filigranes et l'ajout de signatures numériques sont autant d'opérations possibles via la même API (PdfDocument), permettant ainsi d'enchaîner plusieurs transformations avant l'enregistrement final. La page des fonctionnalités IronPDF offre un aperçu de toutes les capacités disponibles.
Pour les scénarios d'automatisation où les positions des pages sont déterminées par le contenu du document (par exemple, l'insertion d'une page d'approbation après avoir trouvé une section spécifique), le tutoriel Modifier les fichiers PDF couvre les techniques de recherche de texte et de manipulation axées sur le contenu qui peuvent être combinées avec le réordonnancement des pages.
Comment gérez-vous les performances lors du déplacement de pages dans des documents volumineux ?
La manipulation des pages dans IronPDF s'effectue sur la représentation du document en mémoire, les performances sont donc proportionnelles à la taille du document et au nombre d'opérations appliquées. Pour les fichiers PDF volumineux, quelques modèles permettent d'optimiser le traitement.
Travailler avec le nombre minimal de pages nécessaires réduit la consommation de mémoire. Au lieu de charger un document de 500 pages pour déplacer deux pages, divisez d'abord le document en sections à l'aide de CopyPages, effectuez le réordonnancement sur le plus petit ensemble, puis réassemblez avec Merge. L' exemple des pages PDF fractionnées illustre ce modèle de décomposition et de réassemblage.
Pour les pipelines de traitement par lots qui déplacent des pages à travers de nombreux documents, supprimez les instances PdfDocument après chaque enregistrement pour libérer rapidement la mémoire. PdfDocument implémente IDisposable , donc envelopper chaque instance dans une instruction using garantit un nettoyage déterministe même lorsque des exceptions surviennent au milieu du pipeline.
using IronPdf;
// Use 'using' declarations to ensure deterministic disposal
using var source = PdfDocument.FromFile("source-large.pdf");
using var destination = PdfDocument.FromFile("destination-large.pdf");
var pageToTransfer = source.CopyPage(0);
destination.InsertPdf(pageToTransfer, 0);
destination.SaveAs("destination-updated.pdf");
source.RemovePage(0);
source.SaveAs("source-updated.pdf");using IronPdf;
// Use 'using' declarations to ensure deterministic disposal
using var source = PdfDocument.FromFile("source-large.pdf");
using var destination = PdfDocument.FromFile("destination-large.pdf");
var pageToTransfer = source.CopyPage(0);
destination.InsertPdf(pageToTransfer, 0);
destination.SaveAs("destination-updated.pdf");
source.RemovePage(0);
source.SaveAs("source-updated.pdf");Imports IronPdf
' Use 'Using' blocks to ensure deterministic disposal
Using source = PdfDocument.FromFile("source-large.pdf")
Using destination = PdfDocument.FromFile("destination-large.pdf")
Dim pageToTransfer = source.CopyPage(0)
destination.InsertPdf(pageToTransfer, 0)
destination.SaveAs("destination-updated.pdf")
source.RemovePage(0)
source.SaveAs("source-updated.pdf")
End Using
End UsingLes déclarations using ici garantissent que les deux objets PdfDocument sont supprimés après la fin des appels SaveAs, libérant immédiatement les tampons de mémoire sous-jacents. Ce modèle est particulièrement important dans les applications ASP.NET Core où de nombreuses requêtes peuvent traiter des documents simultanément sur le même serveur. Pour plus de détails sur l'API concernant la gestion sécurisée des documents en mémoire, consultez la référence de l'API IronPDF .
Quelles sont vos prochaines étapes ?
Le déplacement et le réordonnancement des pages PDF en C# nécessitent trois méthodes IronPDF : CopyPage, InsertPdf et RemovePage, appliquées dans une séquence copie-insertion-suppression. Le même principe s'applique aussi bien au déplacement d'une seule page au sein d'un document qu'au transfert de lots de pages entre plusieurs fichiers. IronPDF fonctionne également en VB .NET avec la même API, et les méthodes de manipulation de page sont disponibles sur toutes les plateformes .NET prises en charge, y compris .NET 8 et .NET 10.
Pour explorer les fonctionnalités connexes, le guide Ajouter, copier et supprimer des pages PDF couvre en détail chaque méthode au niveau de la page. Pour réorganiser l'intégralité d'un document à l'aide d'un tableau d'index de page, l' article " Réorganiser les pages dans un PDF en C# " décrit cette approche.
Prêt à ajouter la manipulation de pages PDF à votre projet ? Démarrez un essai gratuit pour accéder à toutes les fonctionnalités IronPDF pendant le développement, ou achetez une licence pour un déploiement en production dès aujourd'hui.
Questions Fréquemment Posées
Comment déplacer une page à une position différente dans un PDF en utilisant C# ?
Utilisez le modèle en trois étapes d'IronPDF : appelez CopyPage(pageIndex) pour extraire la page, appelez InsertPdf(copiedPage, targetIndex) pour la placer à la nouvelle position, puis appelez RemovePage(originalIndex + 1) pour supprimer l'original (en ajoutant 1 pour tenir compte du décalage d'index causé par l'insertion).
Comment déplacez-vous plusieurs pages à la fois dans IronPDF ?
Appelez CopyPages(new List pour extraire des pages spécifiques par index, puis utilisez PdfDocument.Merge(original, copiedPages) pour les ajouter et RemovePages(new List pour supprimer les originaux de leurs positions antérieures.
Comment transférez-vous une page d'un fichier PDF à un autre en C# ?
Chargez les deux documents avec PdfDocument.FromFile, appelez CopyPage(index) sur le document source, appelez InsertPdf(page, position) sur le document de destination, puis enregistrez chacun avec SaveAs. Supprimez éventuellement la page transférée de la source en utilisant RemovePage.
Pourquoi la suppression d'une page nécessite-t-elle d'ajouter 1 à l'index d'origine après une insertion ?
Lorsqu'une page est insérée à une position avant l'index de la page d'origine, chaque page suivante se décale d'un indice vers le haut. Si la page d'origine était à l'index N et que vous avez inséré avant elle, l'original est maintenant à l'index N+1. Tenez toujours compte de ce décalage lors de l'appel à RemovePage après InsertPdf.
IronPDF utilise-t-il un index de page basé sur zéro ?
Oui. IronPDF utilise l'indexation basée sur zéro dans toute son API. La première page est à l'index 0, la seconde à l'index 1, et ainsi de suite. L'index de la dernière page est PdfDocument.PageCount - 1. Passer un index en dehors de cette plage déclenche une ArgumentOutOfRangeException.
Pouvez-vous déplacer des pages non contiguës avec IronPDF ?
Oui. La méthode CopyPages accepte n'importe quel IEnumerable, vous pouvez donc passer des index non contigus comme new List. Les pages sont retournées dans l'ordre que vous spécifiez, et non dans l'ordre du document.
Les signets et annotations sont-ils préservés lors du déplacement des pages avec IronPDF ?
Le contenu visuel au niveau de la page (texte, images, champs de formulaire) est préservé lors de l'utilisation de CopyPage. Les signets qui référencent uniquement la page déplacée voyagent avec la copie. Les hiérarchies de signets entre documents référencées à plusieurs pages ne sont pas mises à jour automatiquement, alors vérifiez les liens de navigation dans le résultat après avoir déplacé les pages.
Comment éliminer correctement les objets PdfDocument dans un pipeline en lot ?
Utilisez des déclarations using var pdf = PdfDocument.FromFile(path); pour garantir l'élimination déterministe après que l'appel à SaveAs soit terminé. Cela libère immédiatement les tampons en mémoire plutôt que d'attendre la collecte des ordures, ce qui est essentiel dans les applications ASP.NET Core à haut débit.













