
Java에서 PDF 파일을 읽는 방법
Java에서 PDF 문서를 읽는 것은 비즈니스 애플리케이션부터 데이터 분석에 이르기까지 모든 프로젝트에서 필수적인 부분이 될 수 있습니다. IronPDF 라이브러리를 사용하면 Java 프로젝트에 PDF 처리 기능을 통합하는 것이 그 어느 때보다 쉬워졌습니다.
Java에서 PDF 파일을 읽는 방법
- Java에서 PDF 파일을 읽으려면 IronPDF 설치하세요.
fromFile메서드를 사용하여 기존 PDF 문서를 불러옵니다.- HTML 문자열, 파일 또는 웹 URL에서 새 PDF를 렌더링합니다.
extractAllText메서드를 사용하여 열려 있는 PDF에서 텍스트를 읽어옵니다.- 추출한 PDF 텍스트를 콘솔에 출력하거나 Java에 저장합니다.
IronPDF: Java PDF 라이브러리 가져오기
IronPDF Java PDF 라이브러리 개요는 HTML에서 고품질의 캡처 가능한 PDF를 신속하게 생성해야 하는 소프트웨어 개발자에게 완벽한 솔루션입니다. 이 라이브러리는 IronPDF 의 페이지 레이아웃 및 서식, 콘텐츠 및 서식을 동적으로 제어할 수 있는 강력한 문서 조작 도구도 제공합니다.
IronPDF 라이브러리를 사용하여 Java 프로그램에서 특정 경로에 저장된 PDF 파일을 읽는 방법을 살펴보겠습니다.
IronPDF 사용하여 PDF 읽기
첫 번째 단계는 Maven을 사용하여 IronPDF 설치하는 것입니다. 자세한 내용은 IronPDF 설치 가이드 에서 확인할 수 있습니다.
Maven을 사용하여 IronPDF 설치합니다.
Maven 프로젝트에 IronPDF 설치하는 단계는 다음과 같습니다.
- 원하는 IDE에서 Maven 프로젝트를 엽니다.
-
pom.xml파일에서dependencies섹션에 IronPDF 라이브러리 의존성을 추가하세요.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>Your_IronPDF_Version_Here</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>Your_IronPDF_Version_Here</version> </dependency>XML pom.xml파일을 저장하고 Maven이 IronPDF 라이브러리를 다운로드하여 설치하도록 하세요.
설치가 완료되면 IronPDF의 클래스를 프로젝트에서 가져와 사용할 수 있어야 합니다.
PDF 문서를 읽는 자바 코드
다음은 IronPDF 라이브러리를 사용하여 표 형식 경계가 있거나 없는 파일을 읽는 데 사용할 수 있는 코드입니다.
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
/**
* This class demonstrates how to read text from a PDF document using the IronPDF library.
*/
public class PdfReader {
public static void main(String[] args) {
try {
// Load the PDF document from the specified file path
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
// Extract all text content from the loaded PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
// Handle exceptions that may occur during file loading or reading.
e.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
/**
* This class demonstrates how to read text from a PDF document using the IronPDF library.
*/
public class PdfReader {
public static void main(String[] args) {
try {
// Load the PDF document from the specified file path
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
// Extract all text content from the loaded PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
// Handle exceptions that may occur during file loading or reading.
e.printStackTrace();
}
}
}이 프로그램에서는 IronPDF의 PdfDocument 클래스가 PDF 파일의 내용을 읽는 데 사용됩니다. main 메서드는 fromFile 메서드를 사용하여 지정된 파일 경로 "C:\sample.pdf"에서 PDF 파일을 로드하여 PdfDocument 객체를 생성합니다. 그 후 이 객체에 대해 extractAllText 메서드를 호출하여 PDF의 모든 텍스트를 String로 추출하고 반환합니다. 추출된 텍스트가 콘솔에 출력됩니다. 프로그램에는 잠재적인 IOException을 관리하기 위해 try-catch 블록을 사용하는 오류 처리가 포함되어 있습니다.
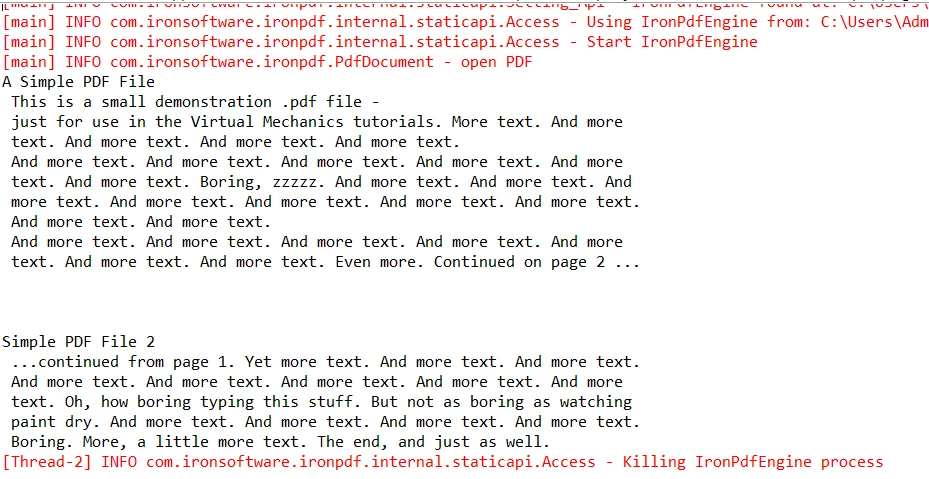 프로그램 출력
프로그램 출력
결론
IronPDF 자바 환경에서 동일 경로 또는 여러 다른 경로에 있는 PDF 파일을 읽는 데 매우 유용한 솔루션입니다. 뛰어난 성능과 다양한 기능을 제공하여 PDF 개발을 간편하게 해줍니다. 구문이 직관적이고 사용하기 쉽습니다. 이 API를 통해 개발자는 프로젝트에 필요한 코드를 신속하게 작성할 수 있습니다.
IronPDF Licensing Options 플랜은 $999에서 시작하여 예산이 제한된 사용자에게도 접근 가능합니다. 전반적으로 IronPDF 애플리케이션에서 PDF를 사용하려는 모든 Java 개발자에게 훌륭한 선택지를 제공합니다.
자주 묻는 질문
자바에서 PDF 파일을 읽는 방법은 무엇인가요?
IronPDF 라이브러리를 사용하면 Java에서 PDF 파일을 읽을 수 있습니다. 먼저 `pom.xml` 파일에 필요한 종속성을 추가하여 Maven을 통해 IronPDF를 설치합니다. 그런 다음 `PdfDocument.fromFile` 메서드를 사용하여 PDF 파일을 불러오고 `extractAllText` 메서드를 사용하여 내용을 읽습니다.
Java 프로젝트에 IronPDF를 설치하는 과정은 무엇인가요?
Java 프로젝트에 IronPDF를 설치하려면 Maven 프로젝트를 열고 `pom.xml` 파일의 `dependencies` 섹션에 IronPDF 종속성을 추가하세요. 파일을 저장하면 Maven이 다운로드 및 설치를 처리합니다.
자바에서 HTML을 PDF로 렌더링할 수 있나요?
네, IronPDF를 사용하면 Java에서 HTML을 PDF로 렌더링할 수 있습니다. IronPDF의 렌더링 기능을 이용하여 HTML 문자열, 파일 또는 웹 URL을 PDF로 변환할 수 있습니다.
IronPDF를 사용하여 Java로 PDF에서 텍스트를 추출하는 방법은 무엇입니까?
IronPDF를 사용하여 Java에서 PDF에서 텍스트를 추출하려면 `PdfDocument.fromFile`을 사용하여 PDF를 불러온 다음 `extractAllText` 메서드를 사용하여 문서에서 텍스트 내용을 가져옵니다.
Java에서 PDF를 읽을 때 IOException이 발생하면 어떻게 해야 하나요?
Java에서 IronPDF를 사용하여 PDF를 읽을 때 `IOException`이 발생하는 경우, 파일 로드 또는 읽기 중에 발생하는 예외를 처리하기 위해 try-catch 블록을 사용하여 적절한 오류 처리를 구현했는지 확인하십시오.
Java 환경에서 IronPDF를 사용하여 PDF를 처리하는 것의 장점은 무엇입니까?
IronPDF는 뛰어난 성능, 사용자 친화적인 구문, 그리고 강력한 문서 조작 도구를 제공합니다. 텍스트 추출 및 HTML을 PDF로 변환하는 기능과 같이 강력한 PDF 처리 기능이 필요한 Java 애플리케이션에 이상적입니다.
Java에서 IronPDF를 사용할 때 서로 다른 PDF 파일 경로를 어떻게 처리할 수 있나요?
IronPDF를 사용하면 다양한 경로에 저장된 PDF 파일을 처리할 수 있습니다. 필요에 따라 특정 파일 경로와 함께 `PdfDocument.fromFile` 메서드를 사용하여 PDF 파일을 불러오고 처리하십시오.
IronPDF는 PDF 기능을 필요로 하는 비즈니스 애플리케이션에 적합한 옵션일까요?
네, IronPDF는 PDF 기능을 필요로 하는 비즈니스 애플리케이션에 적합합니다. 강력한 처리 기능을 제공하여 비즈니스 솔루션부터 데이터 분석에 이르기까지 다양한 애플리케이션에 탁월한 선택입니다.

















