
Napraw błąd iTextSharp „Dokument nie ma stron” podczas konwersji HTML do PDF | IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Błąd iTextSharp "dokument nie ma stron" występuje, gdy XMLWorker nie może przeanalizować treści HTML, ale renderer IronPDF oparty na przeglądarce Chrome eliminuje ten problem, przetwarzając HTML dokładnie tak samo jak przeglądarki, zapewniając niezawodne generowanie plików PDF bez wyjątków związanych z analizą.
Konwersja HTML do PDF jest częstym wymaganiem w aplikacjach .NET, ale programiści korzystający z iTextSharp często napotykają błąd "dokument nie ma stron". Ten błąd pojawia się, gdy proces generowania dokumentu PDF kończy się niepowodzeniem, co sprawia, że programiści muszą szukać rozwiązań. W niniejszej analizie omówiono przyczyny tego zjawiska oraz sposoby skutecznego rozwiązania tego problemu dzięki funkcjom konwersji HTML na PDF oferowanym przez IronPDF.
Co powoduje błąd "Dokument nie ma stron"?
Wyjątek "dokument nie ma stron" występuje, gdy parser iTextSharp nie jest w stanie przetworzyć treści HTML na poprawny dokument PDF. Ten błąd pojawia się zazwyczaj podczas zamykania dokumentu, co zostało szczegółowo opisane w wielu wątkach na Stack Overflow dotyczących tej kwestii. Zrozumienie przyczyny źródłowej pomaga programistom wybrać bibliotekę PDF odpowiednią do ich potrzeb.
Błąd pojawia się, ponieważ XMLWorker — komponent iTextSharp do analizowania HTML — po cichu zawodzi, gdy napotka struktury HTML, których nie może przetworzyć. Zamiast zgłaszać wyjątek podczas analizowania, generuje pusty dokument. Po zamknięciu dokumentu iTextSharp wykrywa, że nie zapisano żadnej treści, i zgłasza wyjątek "dokument nie ma stron". Ten cichy tryb awarii sprawia, że debugowanie jest szczególnie frustrujące, ponieważ ślad stosu wskazuje na operację zamknięcia, a nie na rzeczywisty błąd parsowania.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End ModuleCo wyświetla konsola, gdy pojawia się ten błąd?

Ten kod próbuje utworzyć plik PDF z HTML, ale napotyka wyjątek, ponieważ XMLWorker nie mógł pomyślnie przeanalizować treści HTML. Operacja zapisu zostaje zakończona, ale do dokumentu nie zostaje dodana żadna treść, co skutkuje powstaniem pustego pliku. Ten błąd parsowania jest jednym z najczęstszych problemów, z jakimi borykają się programiści podczas konwersji HTML do PDF w aplikacjach ASP.NET. Problem staje się bardziej złożony w przypadku niestandardowych stylów CSS lub treści renderowanych przez JavaScript.
Dlaczego biblioteka zastępcza boryka się z tym samym problemem?
Chociaż XMLWorker zastąpił przestarzały HTMLWorker, nadal napotyka ten sam problem w przypadku niektórych struktur HTML. Problem nadal występuje, ponieważ XMLWorker ma surowe wymagania dotyczące parsowania, co zostało udokumentówane na oficjalnych forach iText. Ograniczenie to dotyczy programistów próbujących wdrożyć konwersję HTML do PDF z zachowaniem idealnej zgodności pikselowej lub pracujących z responsywnymi układami CSS w nowoczesnych aplikacjach internetowych.
Typowym rozwiązaniem jest wstępne wypełnienie dokumentu pustym akapitem przed parsowaniem kodu HTML. Zapobiega to wyjątkowi "brak stron", zapewniając, że przy zamknięciu dokumentu istnieje co najmniej jeden element treści:
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End SubJak wygląda plik PDF wygenerowany przy użyciu tego rozwiązania?
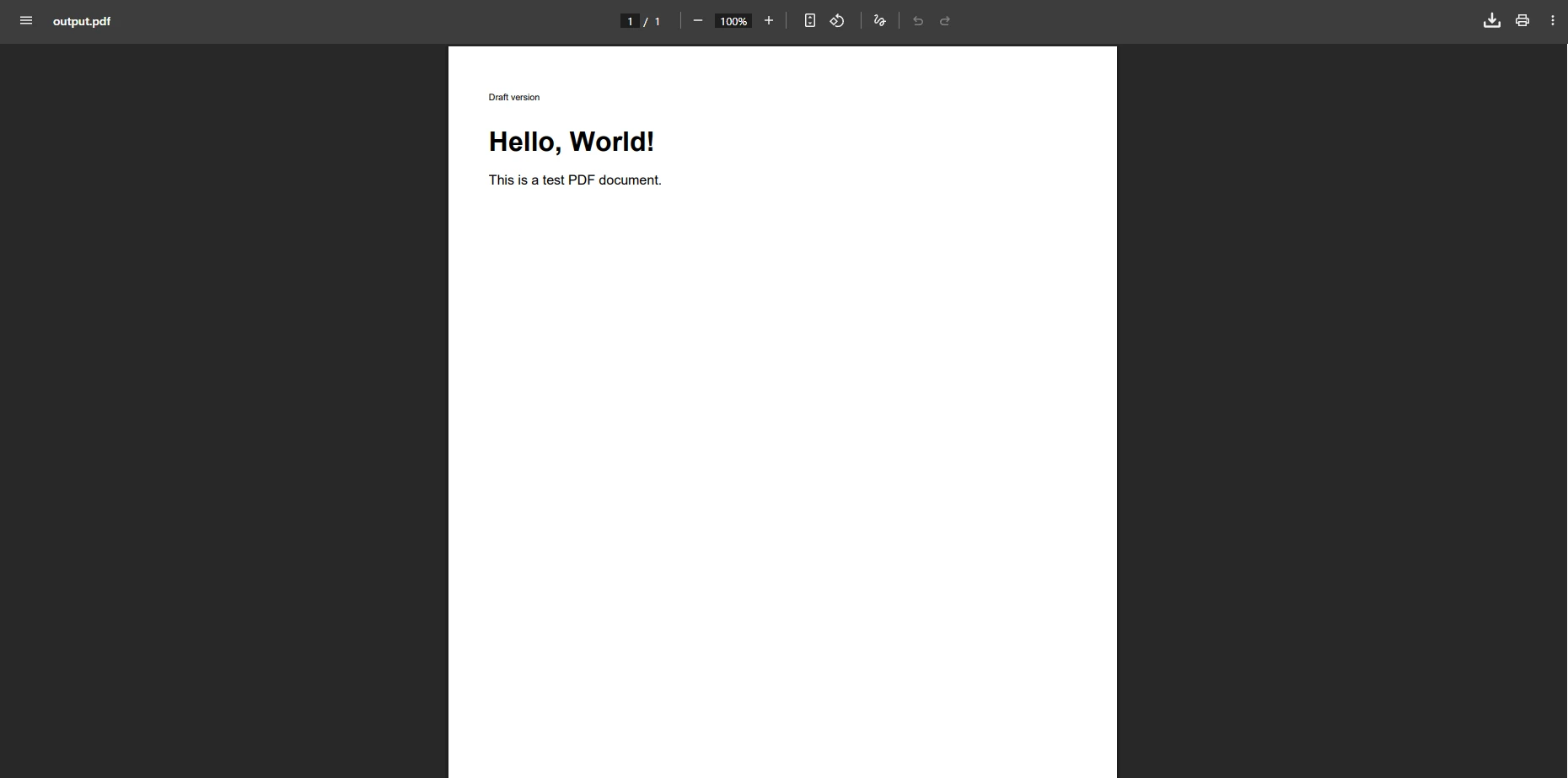
Dlaczego złożone elementy HTML nadal nie wyświetlają się prawidłowo?
Dodanie pustego akapitu zapobiega natychmiastowemu błędowi, ale złożony kod HTML zawierający elementy tabel, obrazy lub niestandardowe czcionki często nie wyświetla się poprawnie. W wynikowym dokumencie PDF treść może być niekompletna lub nieprawidłowa. Programiści napotykają ten sam problem podczas przetwarzania kodu HTML zawierającego osadzone style, elementy hiperłączy lub określone właściwości szerokości. Odwołania do wartości null i brak renderowania elementów powodują dodatkowe problemy, które wymagają dalszego rozwiązania.
XMLWorker został zaprojektowany do obsługi podzbioru HTML 4 i podstawowego CSS 2. Niewoczesne strony internetowe rutynowo wykorzystują funkcje znacznie wykraczające poza ten zakres: CSS Grid, Flexbox, zmienne CSS, wyrażenia calc(), grafikę SVG oraz renderowanie oparte na JavaScript. Każda z tych sytuacji może wywołać błąd "brak stron" lub spowodować ciche wygenerowanie uszkodzonego wyniku — bez opisowego komunikatu o błędzie, który pomógłby w naprawie.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NietSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Czcionki niestandardowe -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NietSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Czcionki niestandardowe -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}Public Sub ProcessComplexHTML(ByVal htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NietSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Czcionki niestandardowe -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End SubJak można konwertować nowoczesny kod HTML bez popełniania tego samego błędu?
Ten rzeczywisty scenariusz pokazuje konwersję sformatowanej faktury z formatu HTML do PDF. Próbka zawiera typowe elementy, które często powodują problemy: wbudowane arkusze CSS, zapytania o media, układy tabel i hiperłącza. Oto rodzaje struktur, które powodują błąd "brak stron" w XMLWorker:
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>Co się dzieje, gdy iTextSharp przetwarza tę fakturę?
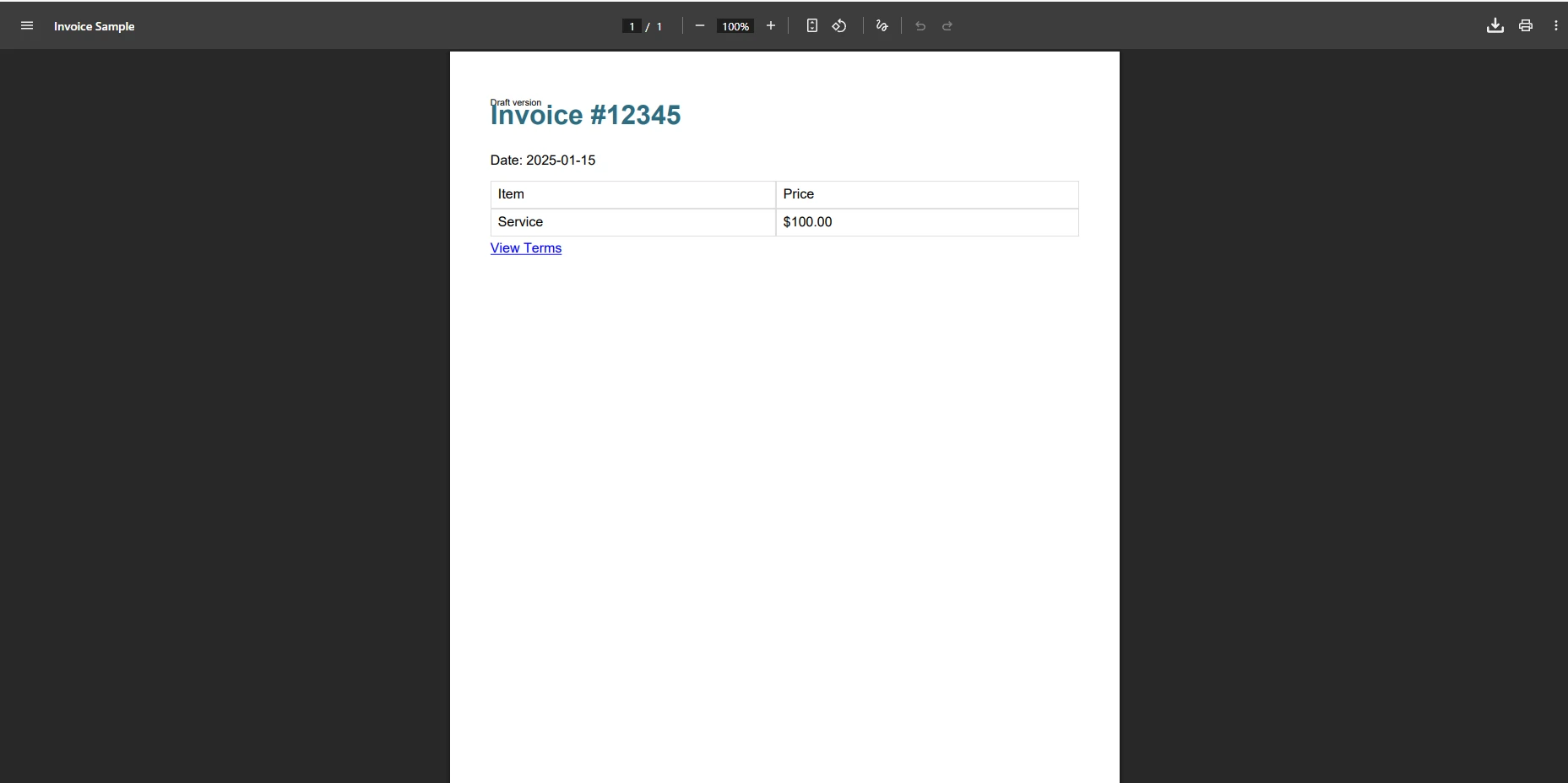
Kiedy iTextSharp przetwarza ten szablon faktury, wynik często jest pozbawiony stylów CSS, brakuje kolorów tła i znikają obramowania tabel. Zapytanie @media print jest ignorowane, a wszelkie odniesienia do czcionek internetowych powodują ciche błędy parsowania. Jeśli kod HTML zawiera właściwość CSS, której XMLWorker nie rozpoznaje, renderowanie całego bloku może się nie powieść — co spowoduje brak treści bez wygenerowania błędu podczas parsowania.
W jaki sposób IronPDF renderuje tę samą fakturę?
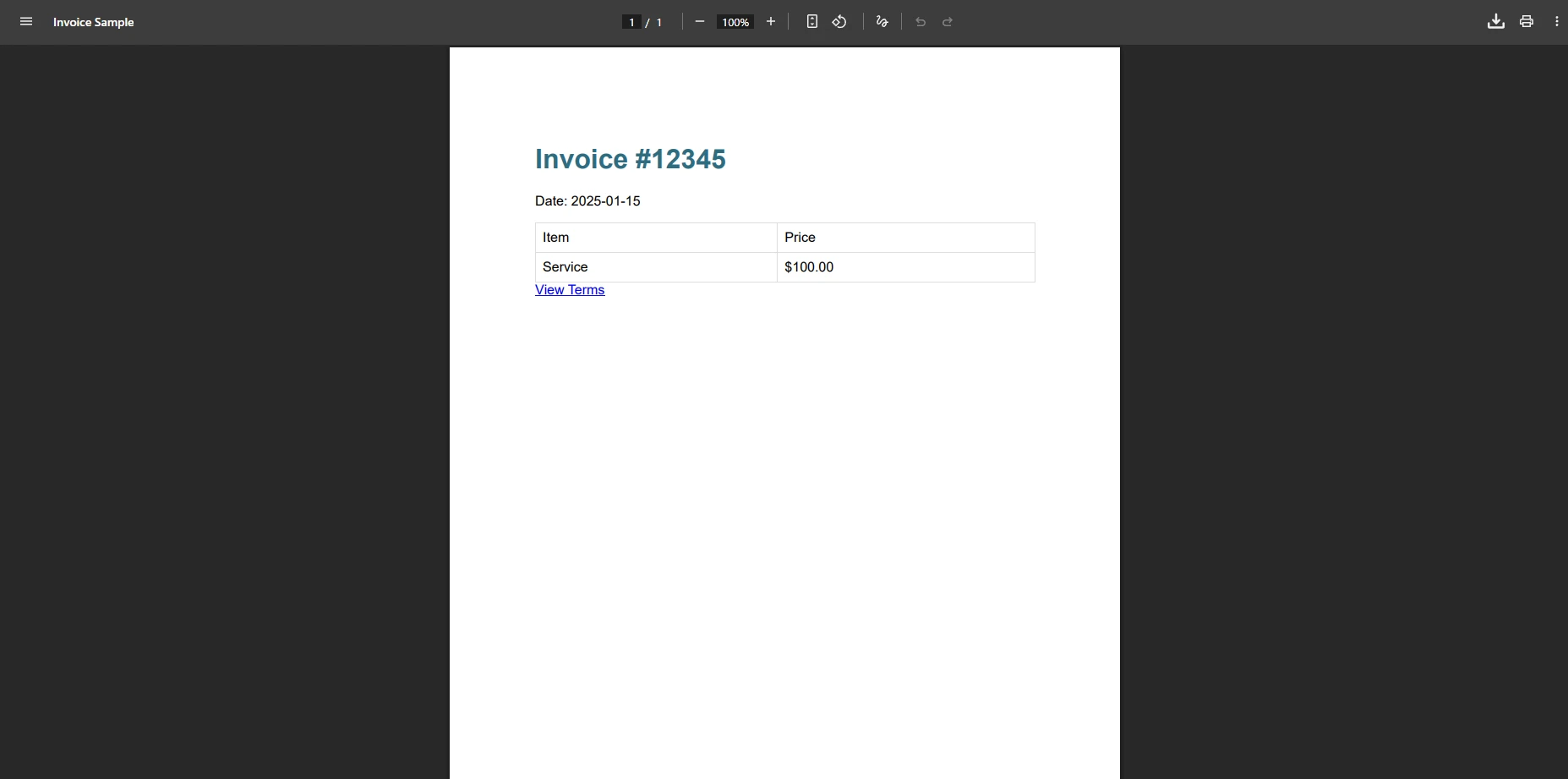
Dlaczego te elementy HTML powodują problemy w iTextSharp?
W przypadku XMLWorker firmy iTextSharp ta faktura może nie zostać przetworzona z powodu stylów tabel, właściwości szerokości lub specyfikacji czcionek. Błąd "dokument nie ma stron" często pojawia się, gdy te elementy nie są obsługiwane. Hiperłącza i odniesienia do zapytań o media również mogą nie wyświetlać się poprawnie. Ograniczenia te stają się krytyczne podczas wdrażania zaawansowanych funkcji PDF, takich jak podpisy cyfrowe lub numery stron w aplikacjach biznesowych.
Zgodnie z dokumentacją Mozilla Developer Network dotyczącą CSS, nowoczesny CSS zawiera setki właściwości i wartości, które przeglądarki obsługują natywnie. XMLWorker obsługuje tylko niewielką część z nich, dlatego rzeczywiste treści internetowe konsekwentnie powodują błędy parsowania.
Jak przeprowadzić konwersję HTML do PDF bez błędów parsowania?
IronPDF wykorzystuje silnik renderujący oparty na przeglądarce Chrome, który przetwarza kod HTML dokładnie tak, jak wygląda on w przeglądarce internetowej. Takie podejście eliminuje błędy parsowania i obsługuje wszystkie nowoczesne funkcje HTML i CSS. Pełną listę opcji konfiguracyjnych można znaleźć w dokumentacji API ChromePdfRenderer. Silnik Chrome zapewnia obsługę wykonywania kodu JavaScript, czcionek internetowych oraz responsywnych układów, z którymi XMLWorker nie może sobie poradzić.
Jak zainstalować IronPDF za pomocą NuGet?
Przed napisaniem jakiegokolwiek kodu zainstaluj pakiet IronPDF NuGet. Można to zrobić z poziomu interfejsu CLI platformy .NET:
dotnet add package IronPdfdotnet add package IronPdfLub z konsoli menedżera pakietów NuGet w Visual Studio:
Install-Package IronPdfInstall-Package IronPdfPo zainstalowaniu uzyskasz dostęp do ChromePdfRenderer, który zastępuje cały potok iTextSharp + XMLWorker jednym, niezawodnym wywołaniem.
Jak przekonwertować HTML na PDF za pomocą IronPDF?
Poniższy przykład renderuje ten sam kod HTML faktury, który powodował błędy w iTextSharp. Należy zauważyć, że nie ma żadnych obejść, pustych akapitów do dodania na początku ani cichych błędów do obsługi:
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")Jak wygląda wynik działania IronPDF?
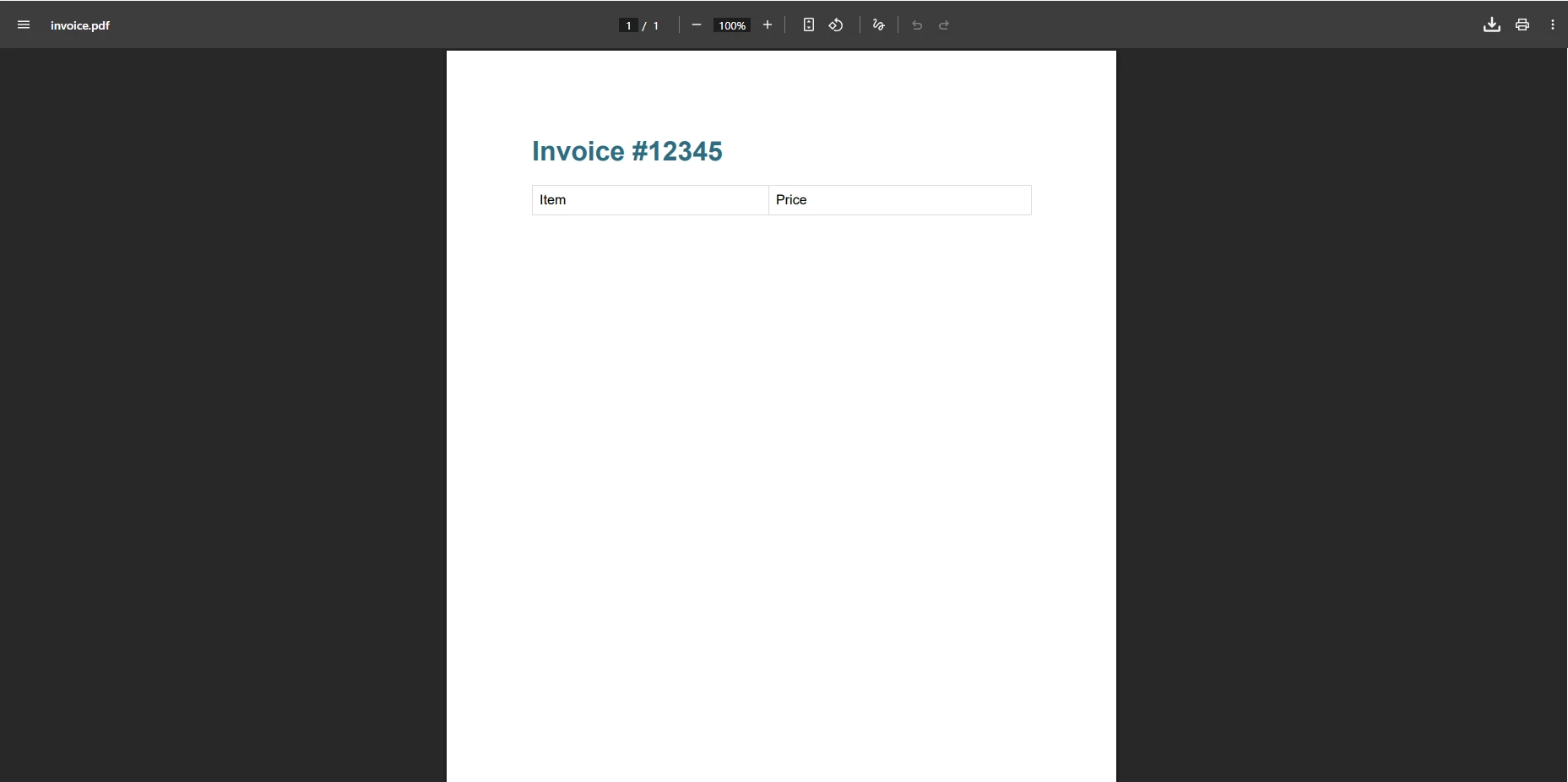
Dlaczego to podejście eliminuje błędy parsowania?
Ten kod z powodzeniem tworzy plik PDF bez żadnych wyjątków. Metoda ta automatycznie obsługuje złożony kod HTML i CSS, eliminując potrzebę stosowania obejść. Treść wyświetla się idealnie, zgodnie z podglądem w przeglądarce. IronPDF obsługuje również renderowanie asynchroniczne, niestandardowe marginesy oraz kompresję plików PDF w celu optymalizacji rozmiarów plików.
W scenariuszach obejmujących treści oparte w dużej mierze na JavaScript lub aplikacje jednostronicowe opcja RenderDelay programu IronPDF pozwala na wykonanie kodu JavaScript przed przechwyceniem pliku PDF — czego XMLWorker w ogóle nie potrafi. Poniższy przykład dodaje nagłówki, stopki i ustawienia zabezpieczeń w gotowym do produkcji wzorcu asynchronicznym:
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End ClassJakie jest najlepsze rozwiązanie do niezawodnego generowania plików PDF?
Porównując te dwie biblioteki do konwersji HTML na PDF, różnice w możliwościach bezpośrednio wpływają na jakość plików PDF i niezawodność wdrożenia:
| Funkcja | iTextSharp + XMLWorker | IronPDF |
|---|---|---|
| Współczesna obsługa HTML/CSS | Ograniczone (HTML 4, CSS 2) | Pełna (silnik renderujący Chrome) |
| Wykonanie kodu JavaScript | Nie | Tak |
| Obsługa błędów | Analiza typowych wyjątków | Wiarygodne odwzorowanie |
| Złożone tabele | Często się nie udaje | Pełne wsparcie |
| Czcionki niestandardowe | Wymagane ręczne osadzenie | Automatyczna obsługa |
| Obsługa SVG | Nie | Tak |
| Renderowanie asynchroniczne | Nie | Tak |
| Obsługa Docker/Linux | Ograniczone | Pełna obsługa języków ojczystych |
| Typy mediów CSS | Podstawowe | Ekran i PRINT |
| Narzędzia do debugowania | Ograniczone | Integracja z Chrome DevTools |
Jak przeprowadzić migrację z iTextSharp do IronPDF?
Dla programistów, którzy napotykają błąd "dokument nie ma stron", przejście na IronPDF stanowi natychmiastowe rozwiązanie. Proces konwersji jest prosty, a IronPDF oferuje kompletną dokumentację i przykłady kodu. Poniższe porównanie "przed i po" pokazuje zmniejszenie złożoności:
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassCo sprawia, że API IronPDF jest bardziej przyjazne dla programistów?
Uproszczony interfejs API oznacza mniej kodu do utrzymania i brak błędów parsowania do debugowania. IronPDF oferuje również funkcje dodawania nagłówków i stopek, łączenia plików PDF oraz stosowania podpisów cyfrowych bez skomplikowanych obejść. Dla zespołów pracujących w środowiskach Docker lub wdrażających rozwiązania na serwerach Linux, IronPDF zapewnia spójne działanie na różnych platformach.
Rozpocznij bezpłatny okres próbny, aby doświadczyć bezbłędnej konwersji HTML do PDF.
Jakie są Twoje kolejne kroki?
Błąd "dokument nie ma stron" wynika z podstawowych ograniczeń parsowania wbudowanych w XMLWorker biblioteki iTextSharp. Chociaż istnieją rozwiązania alternatywne — takie jak wstępne wypełnienie dokumentu pustym akapitem — nie rozwiązują one podstawowego problemu związanego ze złożonym przetwarzaniem kodu HTML. Renderowanie oparte na przeglądarce Chrome firmy IronPDF zapewnia niezawodne rozwiązanie, które obsługuje nowoczesne treści internetowe bez wyjątków związanych z parsowaniem.
W przypadku aplikacji produkcyjnych wymagających spójnego generowania plików PDF z HTML, IronPDF eliminuje frustrację związaną z debugowaniem błędów parsera i zapewnia profesjonalne wyniki. Silnik obsługuje wszystkie elementy HTML, style CSS i JavaScript, zapewniając prawidłowe renderowanie dokumentów za każdym razem. Niezależnie od tego, czy tworzysz faktury, raporty, czy dowolne dokumenty zawierające tekst, tabele i obrazy, IronPDF zapewnia rozwiązanie, którego potrzebujesz.
Aby kontynuować, oto zalecane kolejne kroki:
- Zainstaluj IronPDF za pomocą NuGet (
dotnet add package IronPdf) i uruchom przewodnik szybkiego startu - Zapoznaj się z samouczkiem dotyczącym konwersji HTML do PDF, aby uzyskać pełny opis opcji renderowania
- Zapoznaj się z dokumentacją API ChromePdfRenderer, aby skonfigurować marginesy, nagłówki, czasy oczekiwania JavaScript oraz ustawienia zabezpieczeń
- Sprawdź porównanie iTextSharp vs. IronPDF, aby uzyskać szczegółowy opis różnic między bibliotekami
- Zapoznaj się z przewodnikami dotyczącymi rozwiązywania problemów, aby zoptymalizować wydajność przy dużych obciążeniach
- W przypadku wdrożeń w chmurze zapoznaj się z przewodnikami konfiguracji platform Azure i Docker
Często Zadawane Pytania
Co powoduje błąd „dokument nie ma stron” w iTextSharp HTML do PDF?
Błąd „dokument nie ma stron” w iTextSharp występuje, gdy proces parsowania kończy się niepowodzeniem podczas konwersji HTML do PDF, często z powodu problemów z treścią HTML lub nieobsługiwanych funkcji.
Czy istnieje alternatywa dla iTextSharp do konwersji HTML na PDF?
Tak, IronPDF oferuje niezawodne rozwiązanie do konwersji HTML na PDF w aplikacjach .NET, pokonując wiele ograniczeń występujących w iTextSharp.
Czym różni się sposób konwersji HTML na PDF w IronPDF od iTextSharp?
IronPDF zapewnia bardziej szczegółowe możliwości analizowania i obsługuje szerszy zakres funkcji HTML i CSS, co zmniejsza prawdopodobieństwo wystąpienia błędów konwersji, takich jak błąd „brak stron”.
Czy IronPDF może konwertować złożone dokumenty HTML do formatu PDF?
IronPDF jest zaprojektowany do obsługi złożonych dokumentów HTML, w tym tych z zaawansowanym CSS, JavaScriptem i elementami multimedialnymi, zapewniając dokładny wynik w formacie PDF.
Dlaczego programiści powinni rozważyć użycie IronPDF zamiast iTextSharp?
Programiści mogą preferować IronPDF zamiast iTextSharp ze względu na łatwość obsługi, pełną obsługę HTML i CSS oraz możliwość tworzenia wysokiej jakości plików PDF bez typowych błędów.
Czy IronPDF obsługuje JavaScript i CSS podczas procesu konwersji do formatu PDF?
Tak, IronPDF w pełni obsługuje JavaScript, CSS i nowoczesny HTML5, zapewniając zachowanie wizualnej integralności oryginalnego kodu HTML w pliku PDF.
Jak rozpocząć korzystanie z IronPDF do konwersji HTML na PDF?
Aby rozpocząć pracę z IronPDF, możesz zapoznać się ze szczegółowymi samouczkami i dokumentacją dostępną na stronie internetowej, które zawierają przewodniki krok po kroku dotyczące wdrażania.
Jakie są korzyści z używania IronPDF for .NET dla programistów .NET?
IronPDF oferuje programistom .NET elastyczne narzędzie do generowania plików PDF, którego zalety obejmują obsługę złożonej zawartości HTML, łatwość integracji oraz niezawodną wydajność.
Czy IronPDF oferuje wsparcie w zakresie rozwiązywania problemów związanych z błędami konwersji plików PDF?
Tak, IronPDF zapewnia obszerne zasoby pomocy technicznej, w tym dokumentację i zespół wsparcia, aby pomóc w diagnozowaniu i rozwiązywaniu wszelkich problemów napotkanych podczas konwersji plików PDF.
Czy istnieje możliwość przetestowania możliwości IronPDF przed zakupem?
IronPDF oferuje bezpłatną wersję próbną, która pozwala programistom przetestować funkcje i ocenić wydajność oprogramowania przed podjęciem decyzji o zakupie.













