
iTextSharpの「ドキュメントにページがありません」エラーをHTMLからPDFへの変換で修正 | IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
iTextSharp の"ドキュメントにページがありません"というエラーは、XMLWorker が HTML コンテンツを解析できない場合に発生しますが、 IronPDF の Chrome ベースのレンダラーは、ブラウザーとまったく同じように HTML を処理することでこの問題を解消し、解析例外のない信頼性の高い PDF 生成を実現します。
HTML を PDF に変換することは.NETアプリケーションでは一般的な要件ですが、iTextSharp を使用する開発者は"ドキュメントにページがありません"というエラーに頻繁に遭遇します。 このエラーは、PDF ドキュメントの生成プロセスが失敗したときに表示され、開発者は解決策を探すことになります。 この分析では、なぜこのようなことが起こるのか、またIronPDF の HTML から PDF への機能を使用してこれを効果的に解決する方法を探ります。
"ドキュメントにページがありません"エラーの原因は何ですか?
ドキュメントにはページがありません"例外は、iTextSharpのパーサーがHTMLコンテンツを有効なPDFドキュメントに処理できなかった場合に発生します。 このエラーは通常、ドキュメントを閉じる操作中に表示されます。 この問題に関する多くの Stack Overflow スレッドで詳しく説明されています。 根本原因を理解することで、開発者はニーズに合った適切な PDF ライブラリを選択できるようになります。
このエラーは、iTextSharp の HTML 解析コンポーネントである XMLWorker が、処理できない HTML 構造に遭遇すると、何もせずに失敗するため発生します。 解析中に例外を発生させる代わりに、空のドキュメントを生成します。 ドキュメントが閉じられると、iTextSharp はコンテンツが書き込まれていないことを検出し、"ドキュメントにページがありません"という例外をスローします。 このサイレント障害モードでは、スタック トレースが実際の解析の失敗ではなく、閉じる操作を指し示すため、デバッグが特に困難になります。
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End Moduleこのエラーが発生すると、コンソール出力には何が表示されますか?

このコードは HTML から PDF ファイルを作成しようとしますが、XMLWorker が HTML コンテンツを正常に解析できなかったため例外が発生します。 書き込み操作は完了しましたが、ドキュメントにコンテンツが追加されず、空のファイルが作成されます。この解析エラーは、 ASP.NETアプリケーションでHTMLからPDFへの変換を行う際に開発者が直面する最も一般的な問題の1つです。 カスタム CSS スタイルや JavaScript でレンダリングされたコンテンツを扱う場合、問題はさらに複雑になります。
代替ライブラリでも同じ問題が発生するのはなぜでしょうか?
XMLWorkerは非推奨のHTMLWorkerに取って代わりましたが、特定のHTML構造で同じ問題が発生します。 iText の公式フォーラムに記載されているように、XMLWorker には厳格な解析要件があるため、この問題は解決しません。 この制限は、ピクセルパーフェクトな HTML から PDF への変換を実装しようとしている開発者や、最新の Web アプリケーションでレスポンシブな CSS レイアウトを操作しようとしている開発者に影響します。
一般的な回避策は、HTML を解析する前に、ドキュメントに空の段落を事前に入力することです。 これにより、ドキュメントが閉じるときに少なくとも 1 つのコンテンツ要素が存在することが保証され、"ページなし"例外が防止されます。
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End Subこの回避策では PDF 出力はどのようになりますか?
<img src="/static-assets/pdf/blog/itextsharp-html-to-pdf-no-page/itextsharp-html-to-pdf-no-page-2.webp" alt=""Hello, World!"の見出しと"Draft version"のヘッダー、テストコンテンツを表示するPDFが正常に生成されました。"ドキュメントにページがありません"エラーを防ぐための空の段落の回避策を実装した後、XMLWorkerのHTMLレンダリングが正常に行われたことを示しています。">
複雑な HTML 要素がレンダリングに失敗する理由は何ですか?
空の段落を追加すると、即時のエラーは回避されますが、表要素、画像、またはカスタム フォントを含む複雑な HTML は、正しくレンダリングされないことがよくあります。 生成された PDF ドキュメントの内容が欠落しているか、形式が正しくない可能性があります。 開発者は、埋め込みスタイル、ハイパーリンク要素、または特定の幅プロパティを持つ HTML を処理するときにも同じ問題に遭遇します。 null 参照と要素のレンダリングの欠落により、さらなる解決を必要とする追加の問題が発生します。
XMLWorkerは、HTML 4の一部と基本的なCSS 2を処理するように設計されていました。現代のWebページでは、CSS Grid、Flexbox、CSS変数、calc()式、SVGグラフィックス、JavaScriptによるレンダリングなど、この範囲をはるかに超える機能が日常的に使用されています。 これらはいずれも、"ページなし"エラーを引き起こしたり、壊れた出力を黙って生成したりする可能性があります。しかも、修正をガイドする説明的なエラー メッセージは表示されません。
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// カスタムフォント -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// カスタムフォント -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}' Common XMLWorker limitations that require manual handling
Public Sub ProcessComplexHTML(htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' カスタムフォント -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End Sub同じエラーを出さずに最新の HTML を変換するにはどうすればよいでしょうか?
この実際のシナリオでは、スタイル設定された請求書を HTML から PDF に変換する方法を示します。 サンプルには、インライン CSS、メディア クエリ、テーブル レイアウト、ハイパーリンクなど、問題の原因となることが多い一般的な要素が含まれています。 これらは、XMLWorker で"ページなし"エラーをトリガーする種類の構造です。
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>iTextSharp がこの請求書を処理すると何が起こりますか?
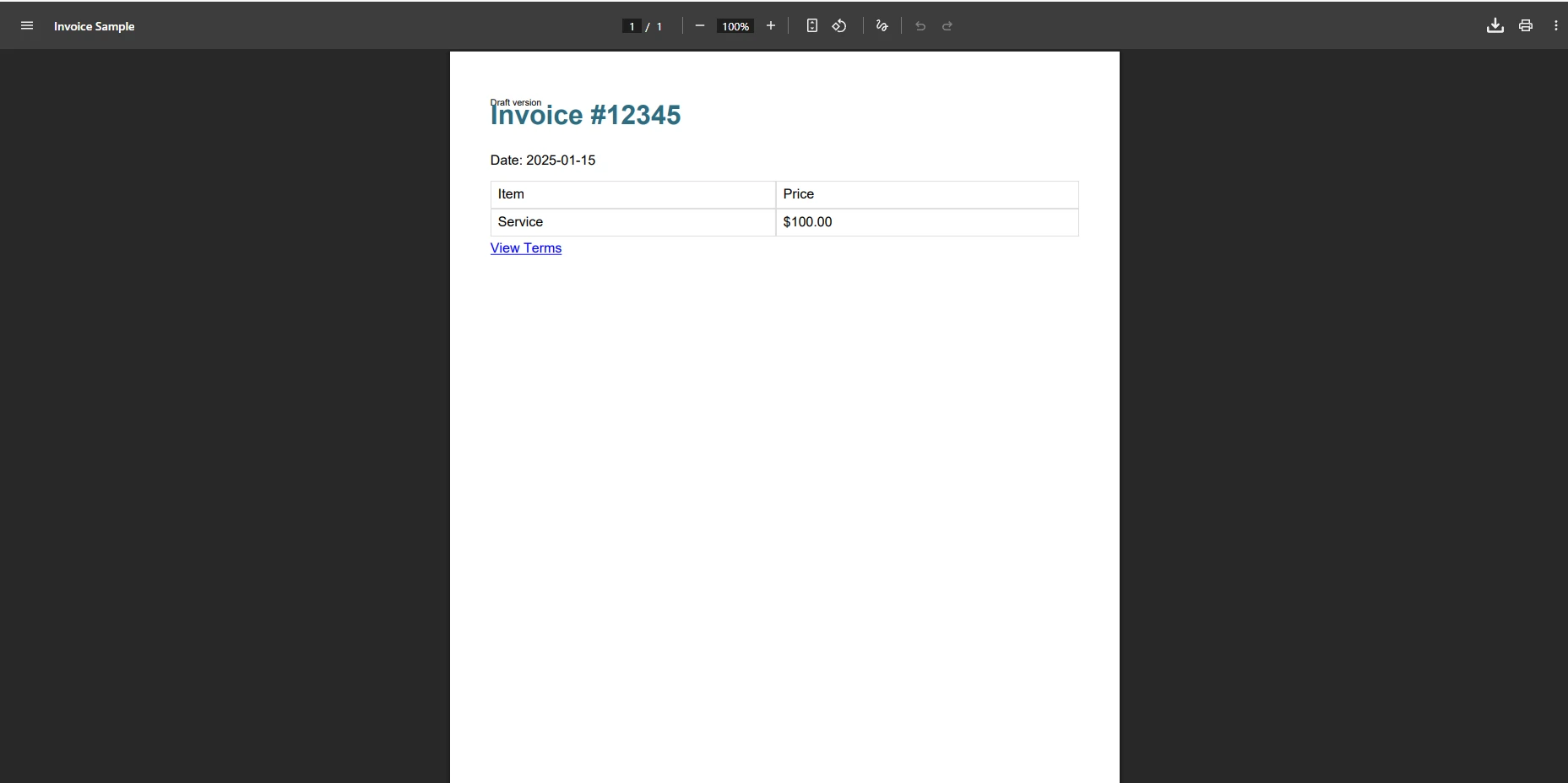
iTextSharp がこの請求書テンプレートを処理すると、出力から CSS スタイルが削除され、背景色が失われ、表の境界線が失われることがよくあります。 @media print クエリは無視され、Web フォントへの参照があると、サイレントな解析エラーが発生します。 HTML に XMLWorker が認識しない CSS プロパティが含まれている場合、ブロック全体のレンダリングに失敗する可能性があります。その結果、解析時にエラーがスローされずにコンテンツが失われます。
IronPDF は同じ請求書をどのようにレンダリングするのでしょうか?
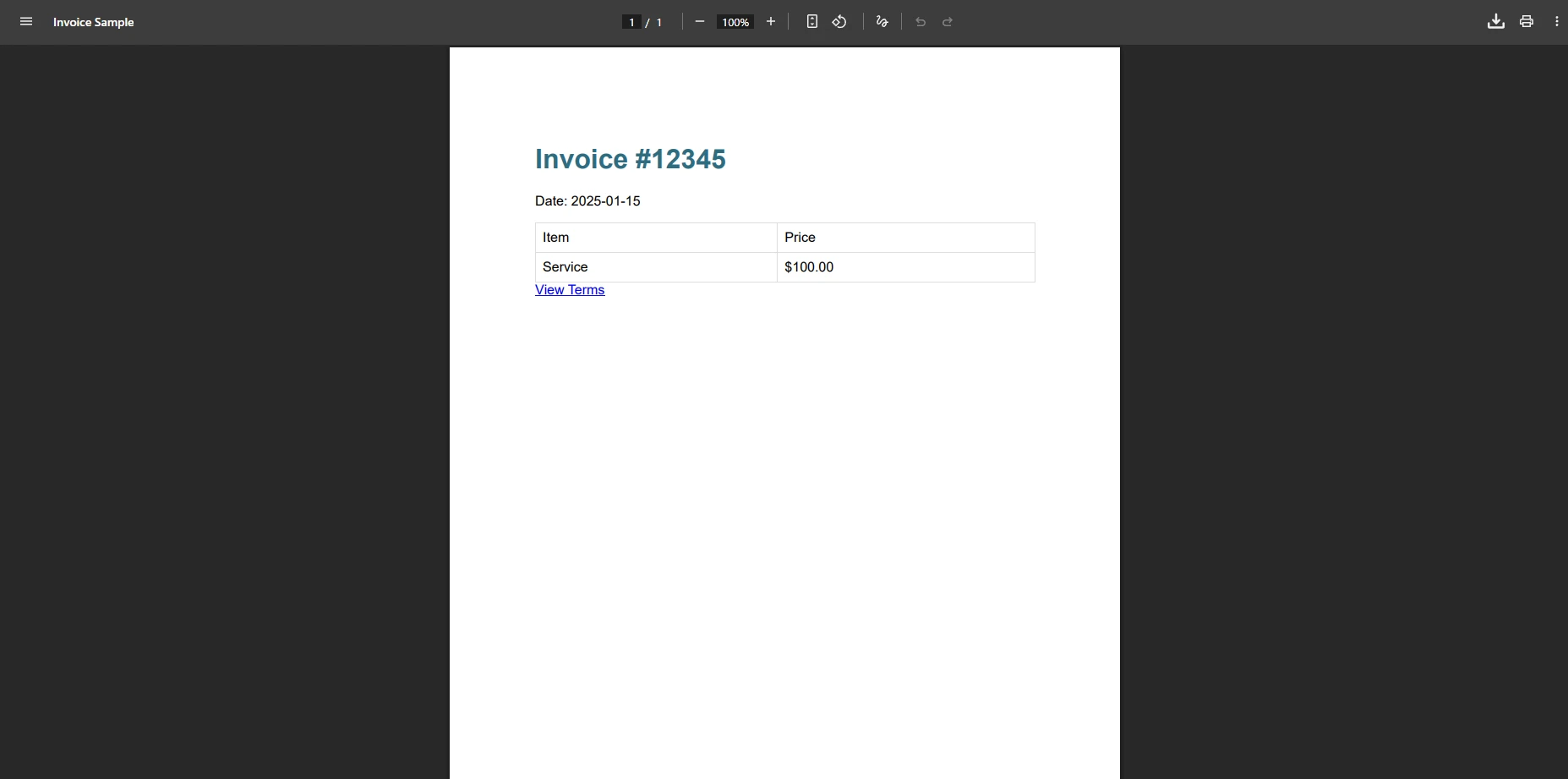
これらの HTML 要素が iTextSharp で問題を引き起こすのはなぜですか?
iTextSharp の XMLWorker では、テーブルのスタイル、幅のプロパティ、またはフォントの仕様により、この請求書は失敗する可能性があります。 これらの要素がサポートされていない場合、"ドキュメントにページがありません"というエラーがよく表示されます。 ハイパーリンクやメディアクエリ参照も正しくレンダリングされない可能性があります。 これらの制限は、ビジネス アプリケーションでデジタル署名やページ番号などの高度な PDF 機能を実装するときに重要になります。
Mozilla Developer Network の CSS に関するドキュメントによると、最新の CSS には、ブラウザーがネイティブにサポートする数百のプロパティと値が含まれています。 XMLWorker はこれらのほんの一部しかカバーしていないため、実際の Web コンテンツでは解析エラーが頻繁に発生します。
解析エラーなしで HTML から PDF への変換を処理するにはどうすればよいでしょうか?
IronPDF は、Web ブラウザに表示されるとおりに HTML を処理する Chrome ベースのレンダリング エンジンを使用します。 このアプローチにより、解析エラーが排除され、最新の HTML および CSS 機能がすべてサポートされます。 構成オプションの完全なリストについては、 ChromePdfRenderer API リファレンスを参照してください。 Chrome エンジンは、XMLWorker では処理できないJavaScript実行、Web フォント、レスポンシブ レイアウトのサポートを提供します。
NuGet経由でIronPDFをインストールするにはどうすればいいですか?
コードを記述する前に、 IronPDF NuGetパッケージをインストールします。 これは.NET CLI から実行できます。
dotnet add package IronPdfdotnet add package IronPdfまたは、Visual Studio のNuGetパッケージ マネージャー コンソールから:
Install-Package IronPdfInstall-Package IronPdfインストールが完了すると、ChromePdfRenderer にアクセスできるようになります。これは、iTextSharp + XMLWorker パイプライン全体を、単一の信頼性の高い呼び出しに置き換えます。
IronPDFを使用して HTML を PDF に変換するにはどうすればよいでしょうか?
以下の例は、iTextSharp でエラーを引き起こした同じ請求書 HTML をレンダリングしたものです。回避策はなく、先頭に空の段落を追加する必要もなく、対処すべきサイレントエラーも発生していないことに注意してください。
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
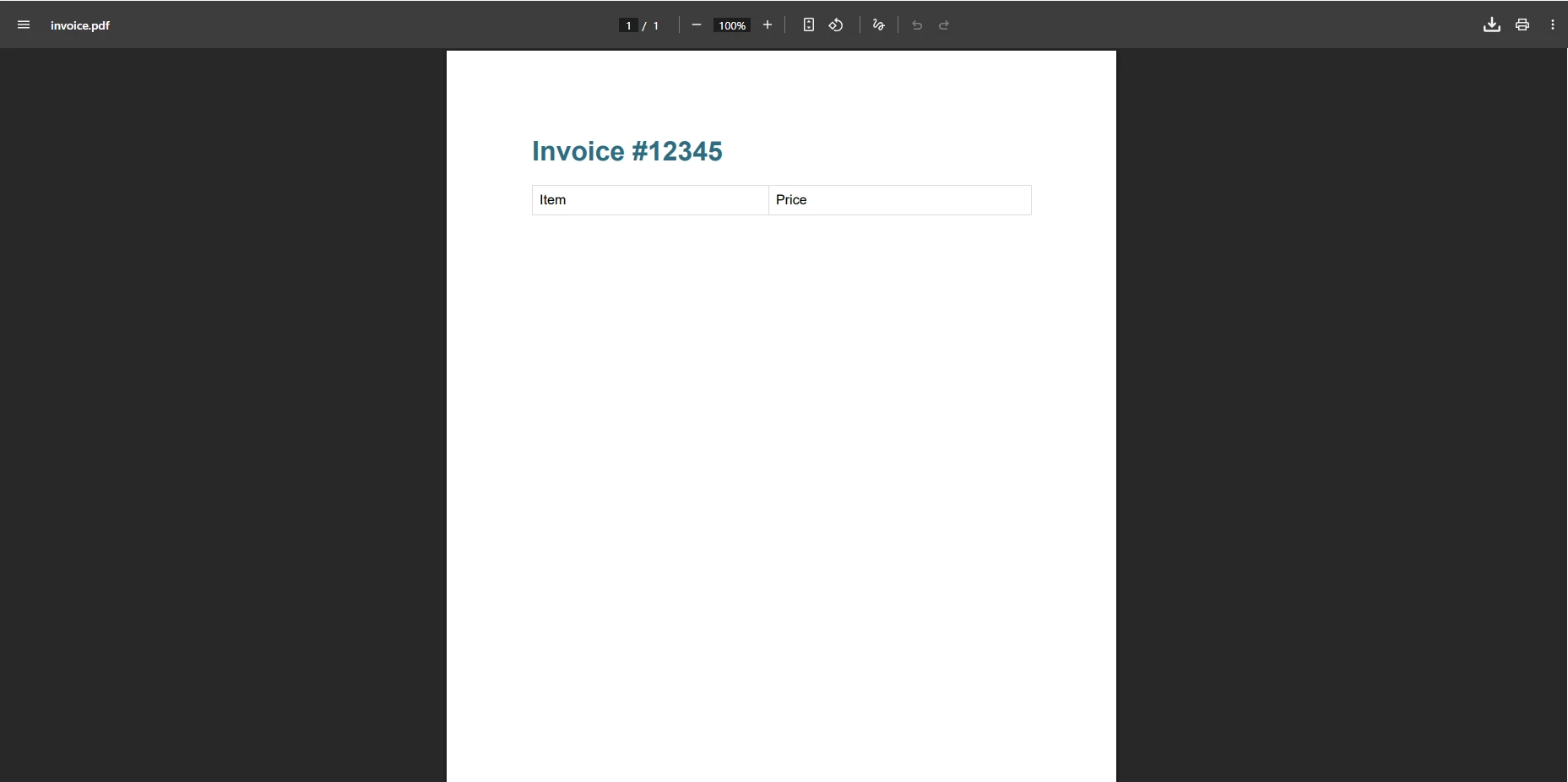
pdf.SaveAs("invoice.pdf")IronPDF の出力はどのようになりますか?
このアプローチによって解析エラーが排除されるのはなぜですか?
このコードは、例外なくPDFファイルの作成に成功しています。 この方法では、複雑なHTMLとCSSが自動的に処理されるため、回避策が不要になります。 コンテンツは、ブラウザのプレビューと一致するように、ピクセルパーフェクトでレンダリングされます。 IronPDF は、非同期レンダリング、カスタム マージン、および最適化されたファイル サイズのための PDF 圧縮もサポートしています。
JavaScriptを多用するコンテンツやシングルページアプリケーションを扱うシナリオでは、IronPDFのRenderDelayオプションを使用すると、PDFがキャプチャされる前にJavaScriptを実行できます。これはXMLWorkerでは全くできないことです。 次の例では、本番環境対応の非同期パターンでヘッダー、フッター、およびセキュリティ設定を追加します。
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End Class信頼性の高い PDF 生成に最適なソリューションは何ですか?
HTML から PDF への変換用の 2 つのライブラリを比較すると、機能の違いが PDF の品質と展開の信頼性に直接影響します。
| 特徴 | iTextSharp + XMLWorker | IronPDF |
|---|---|---|
| 最新のHTML/CSSサポート | 限定版(HTML 4、CSS 2) | フル(Chrome レンダリング エンジン) |
| JavaScript 実行 | なし | はい |
| エラー処理 | 解析例外は一般的 | 信頼性の高いレンダリング |
| 複雑なテーブル | 失敗することが多い | フルサポート |
| カスタムフォント | 手動での埋め込みが必要 | 自動処理 |
| SVGサポート | なし | はい |
| 非同期レンダリング | なし | はい |
| Docker/Linux サポート | 制限あり | 完全なネイティブサポート |
| CSSメディアタイプ | 基本 | スクリーンと印刷 |
| デバッグツール | 制限あり | Chrome DevToolsの統合 |
iTextSharp からIronPDFに移行するにはどうすればいいですか?
ドキュメントにページがありません "というエラーを経験した開発者にとって、IronPDFへの移行は即座に解決策を提供します。 変換プロセスは簡単で、 IronPDFは完全なドキュメントとコード例を提供しています。 次の前後の比較は、複雑さの軽減を示しています。
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassIronPDF の API が開発者にとってより使いやすいのはなぜですか?
簡素化されたAPIは、保守するコードが少なく、デバッグのための解析エラーがないことを意味します。 IronPDF には、複雑な回避策なしでヘッダーとフッターを追加したり、 PDF を結合したり、デジタル署名を適用したりする機能も用意されています。 Docker 環境で作業したり Linux サーバーにデプロイしたりするチームにとって、 IronPDF はプラットフォーム間で一貫した動作を提供します。
無料トライアルを開始して、エラーのないHTML から PDF への変換を体験してください。
次のステップは何ですか?
"ドキュメントにページがありません"というエラーは、iTextSharp の XMLWorker に組み込まれている基本的な解析制限によって発生します。 ドキュメントに空の段落を事前に入力するなどの回避策は存在しますが、複雑な HTML 処理の根本的な問題は解決されません。 IronPDF の Chrome ベースのレンダリングは、例外を解析せずに最新の Web コンテンツを処理する信頼性の高いソリューションを提供します。
HTMLから一貫したPDF生成を必要とするプロダクションアプリケーションのために、IronPDFはパーサーエラーのデバッグのフラストレーションを解消し、プロフェッショナルな結果を提供します。 エンジンはすべてのHTML要素、CSSスタイル、 JavaScriptを処理し、ドキュメントが常に正しくレンダリングされることを保証します。請求書、レポート、テキスト、表、画像を含むあらゆるドキュメントを作成する場合でも、 IronPDFは必要なソリューションを提供します。
先に進むには、次の手順を実行することをお勧めします。
- NuGet (
dotnet add package IronPdf)経由でIronPDFをインストールし、クイックスタートガイドを実行します。 - レンダリング オプションの完全なウォークスルーについては、 HTML から PDF へのチュートリアルを参照してください。
- ChromePdfRenderer API リファレンスを参照して、余白、ヘッダー、 JavaScript の待機時間、セキュリティ設定を構成します。
- ライブラリの違いの詳細については、 iTextSharpとIronPDFの比較を参照してください。 -トラブルシューティング ガイドを確認して、大量のワークロードの出力を最適化します。
- クラウド展開については、 AzureおよびDocker のセットアップ ガイドを参照してください。
よくある質問
iTextSharp HTML to PDFの「ドキュメントにページがありません」エラーの原因は何ですか?
iTextSharpの「ドキュメントにページがありません」エラーは、HTMLからPDFへの変換中に解析プロセスが失敗したときに発生します。
iTextSharpに代わるHTMLからPDFへの変換ツールはありますか?
IronPDFは.NETアプリケーションのHTMLからPDFへの変換において、iTextSharpに見られる多くの制限を克服し、信頼できるソリューションを提供します。
IronPDFはiTextSharpとどのようにHTMLからPDFへの変換を行うのですか?
IronPDFはより徹底した解析能力を提供し、変換エラーの可能性を減らすHTMLおよびCSS機能の範囲をサポートします。
IronPDFは複雑なHTMLドキュメントをPDFに変換できますか?
IronPDFは高度なCSS、JavaScript、マルチメディア要素を含む複雑なHTMLドキュメントを扱うように設計されており、正確なPDF出力を保証します。
なぜ開発者はiTextSharpよりもIronPDFの使用を検討すべきなのでしょうか?
使いやすさ、HTMLおよびCSSの完全サポート、高品質なPDFを一般的なエラーなしで生成できる能力のため、開発者はIronPDFをiTextSharpよりも好ましく思うかもしれません。
IronPDFはPDF変換の過程でJavaScriptとCSSをサポートしていますか?
IronPDFはJavaScript、CSS、モダンHTML5を完全にサポートし、元のHTMLのビジュアルインテグリティがPDF出力で維持されることを保証します。
HTMLからPDFへの変換をIronPDFで始めるにはどうすればいいですか?
IronPDFを使い始めるには、詳細なチュートリアルとドキュメントをウェブサイトでご覧ください。
IronPDFを.NET開発者が使用する利点は何ですか?
IronPDFは、複雑なHTMLコンテンツのサポート、統合の容易さ、および信頼性のあるパフォーマンスといった利点を持つ柔軟なPDF生成ツールを.NET開発者に提供します。
IronPDFはPDF変換エラーのトラブルシューティングをサポートしていますか?
はい、IronPDFはPDF変換中に発生した問題のトラブルシューティングと解決のために、ドキュメントやサポートチームを含む広範なサポートリソースを提供します。
購入前にIronPDFの機能を試す方法はありますか?
IronPDFは無料のトライアルバージョンを提供しており、開発者は購入の前にその機能をテストし、パフォーマンスを評価することができます。













