ASP.NET MVC'de PDF Nasıl Oluşturulur: IronPDF vs iTextSharp?
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
iText "belgenin sayfası yok" hatası XMLWorker'ın HTML içeriğini işleyememesi durumunda ortaya çıkar, ancak IronPDF'in Chrome tabanlı işleyicisi bu sorunu ortadan kaldırarak, tarayıcılar gibi HTML işleyerek parse hatalarına yol açmadan güvenilir PDF oluşturması sağlar.
.NET uygulamalarında HTML'i PDF'e dönüştürmek yaygın bir gerekliliktir, ancak iText kullanan geliştiriciler sıklıkla "belgenin sayfası yok" hatasıyla karşılaşır. Bu hata, PDF belge oluşturma süreci başarısız olduğunda ortaya çıkar ve geliştiricileri çözüm arayışına yönlendirir. Bu analiz, bunun neden olduğunu ve .NET'nin HTML'den PDF'ye dönüştürme yetenekleri ile nasıl etkili bir şekilde çözülebileceğini keşfeder.
"Belge Sayfa İçermiyor" Hatasına Ne Sebep Olur?
"belgenin sayfası yok" istisnası, iText'in ayrıştırıcısının HTML içeriğini geçerli bir PDF belgesine dönüştürememesi durumunda ortaya çıkar. Bu hata genellikle belge kapatma işlemi sırasında, bu sorunla ilgili birçok Stack Overflow başlığında açıklandığı gibi ortaya çıkar. Kökteki nedeni anlamak, geliştiricilerin ihtiyaçları için doğru PDF kütüphanesini seçmelerine yardımcı olur.
Hata, XMLWorker -- iText'in HTML ayrıştırma bileşeni -- işleyemediği HTML yapıları ile karşılaştığında sessizce başarısız olması nedeniyle ortaya çıkar. Ayrıştırma sırasında bir istisna yükseltmek yerine, boş bir belge üretir. Belge kapandığında, iText hiçbir içerik yazılmadığını tespit eder ve "belgenin sayfası yok" istisnası fırlatır. Bu sessiz hata modu, yığın izlemesinin gerçek ayrıştırma hatası yerine kapanış işlemini işaret etmesi nedeniyle hata ayıklamayı özellikle sinir bozucu hale getirir.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End ModuleBu Hata Meydana Geldiğinde Konsol Çıktısı Ne Gösterir?

Bu kod, HTML'den bir PDF dosyası oluşturmayı deniyor ancak XMLWorker, HTML içeriğini başarıyla ayrıştıramadığı için bir istisna ile karşılaşılıyor. Yazma işlemi tamamlanır, ancak belgeye herhangi bir içerik eklenmez ve sonuçta boş bir dosya oluşur. Bu ayrıştırma hatası, geliştiricilerin ASP.NET uygulamalarında HTML'den PDF'ye dönüşüm yaparken karşılaştığı en yaygın sorunlardan biridir. Özelleştirilmiş CSS stilleri veya JavaScript ile oluşturulan içerikle uğraşırken sorun daha karmaşık hale gelir.
Yerine Geçen Kütüphane Neden Aynı Sorunu Yaşıyor?
Her ne kadar XMLWorker, kullanım dışı bırakılan HTMLWorker'ın yerini almış olsa da, hala belirli HTML yapılarıyla aynı sorunla karşılaşmaktadır. XMLWorker'ın katı ayrıştırma gereksinimleri olduğu için sorun devam ediyor, bu durum iText'in resmi forumlarında belgelenmiştir. Bu sınırlama, modern web uygulamalarında piksel mükemmeliyetinde HTML'den PDF'e dönüştürme yapmaya çalışan veya duyarlı CSS düzenleriyle çalışan geliştiricileri etkiler.
Yaygın bir çözüm, HTML ayrıştırmadan önce belgeyi boş bir paragrafla önceden doldurmaktır. Bu, belge kapandığında en az bir içerik öğesi bulunduğundan emin olarak "sayfa yok" istisnasını önler:
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End SubBu Geçici Çözümle PDF Çıktısı Nasıl Görünür?
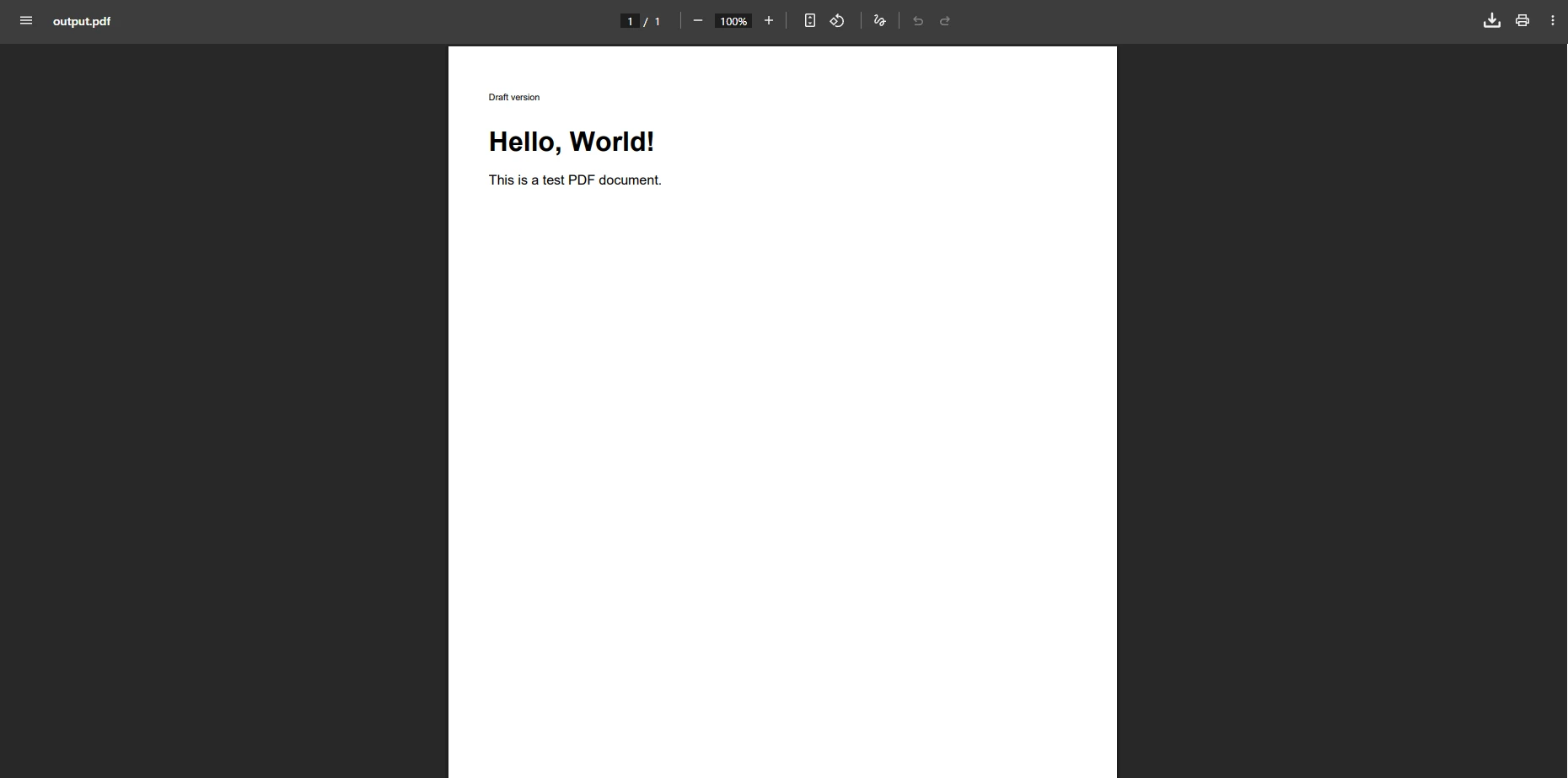
Neden Karmaşık HTML Öğeleri Hâlâ İşlenemiyor?
Boş bir paragraf eklemek anında hatayı önler, ancak tablo elemanları, resimler veya özel yazı tipleri içeren karmaşık HTML genellikle doğru şekilde işlenemez. İçerik, ortaya çıkan PDF belgesinde eksik veya hatalı olabilir. Geliştiriciler, gömülü stiller, köprü elementleri veya belirli genişlik özellikleri içeren HTML'yi işlerken aynı sorunla karşılaşır. Boş referanslar ve eksik eleman oluşturma, ek çözümler gerektiren ilave sorunlar yaratır.
XMLWorker, HTML 4 ve temel CSS 2'nin bir alt kümesini ele alacak şekilde tasarlanmıştır. Modern web sayfaları bu kapsamın çok ötesinde özellikler kullanır: CSS Grid, Flexbox, CSS değişkenleri, calc() ifadeleri, SVG grafikleri ve JavaScript destekli işleme. Bunlardan herhangi biri "sayfa yok" hatasını tetikleyebilir veya sessizce bozuk çıktı üretebilir -- ve düzeltmeye yönelik açıklayıcı bir hata mesajı olmadan.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Özel yazı tipleri -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Özel yazı tipleri -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}' Common XMLWorker limitations that require manual handling
Public Sub ProcessComplexHTML(ByVal htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Özel yazı tipleri -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End SubAynı Hata Olmadan Modern HTML Nasıl Dönüştürülür?
Bu gerçek dünya senaryosu, biçimlendirilmiş bir faturanın HTML'den PDF'e dönüştürülmesini gösterir. Bu örnek, CSS satır içi, medya sorguları, tablo düzenleri ve köprüler gibi genellikle sorun yaratan ortak unsurları içerir. Bunlar, XMLWorker'da 'hiçbir sayfa yok' hatasını tetikleyen türdeki yapılardır:
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>iText Bu Faturayı İşlediğinde Ne Olur?
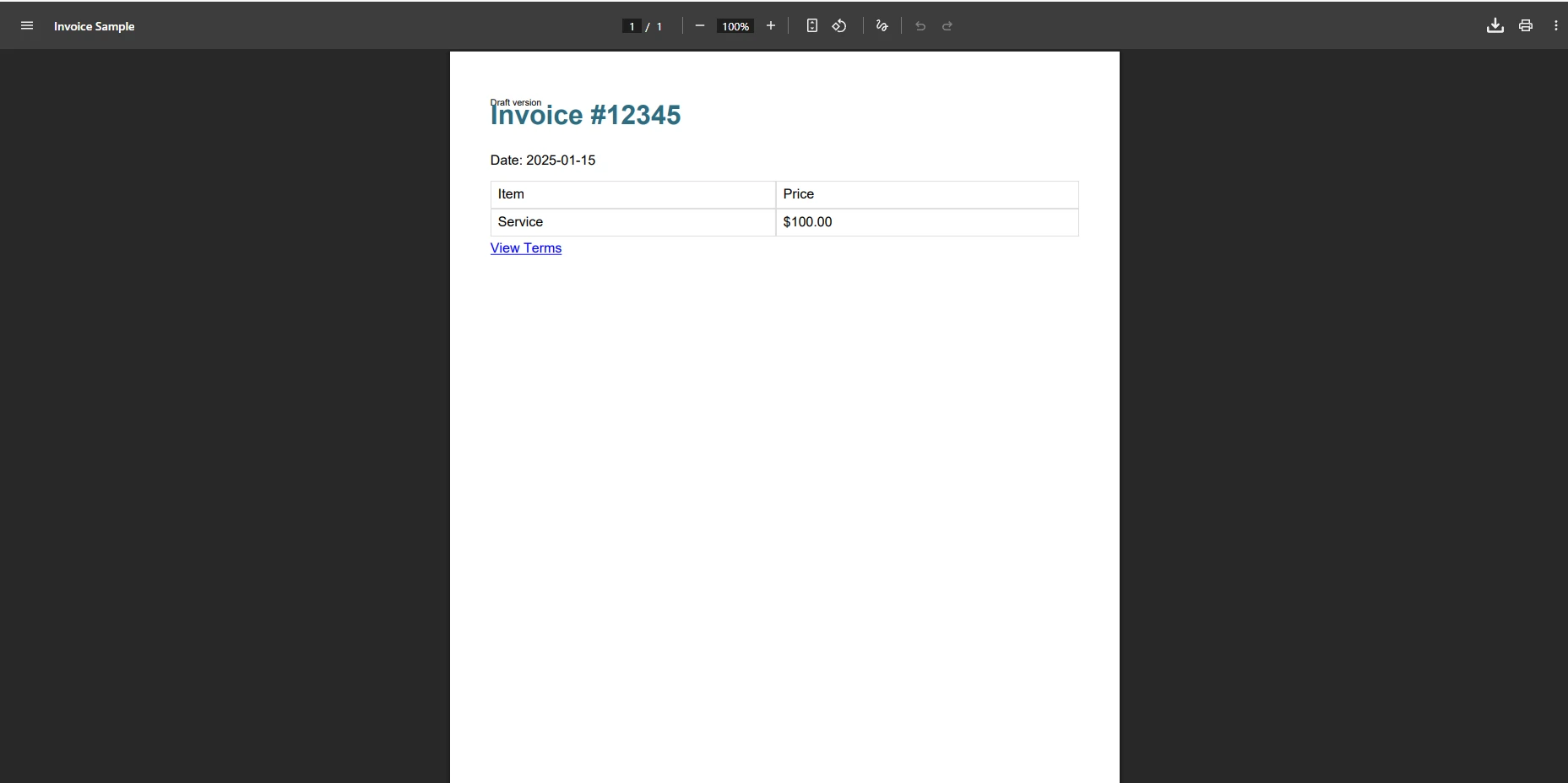
iText bu fatura taslağını işlediğinde, çıktı genellikle CSS stilinden yoksun, arka plan renkleri eksik ve tablo kenarları kaybolmuş olur. @media print sorgusu görmezden gelinir ve herhangi bir web fontu referansı sessiz ayrıştırma hatalarına neden olur. HTML'de XMLWorker'ın tanımadığı bir CSS özelliği varsa, tüm blok işlenemeyebilir - ve bu, hiçbir hata atmadan eksik içerikle sonuçlanabilir.
IronPDF Aynı Faturayı Nasıl İşliyor?
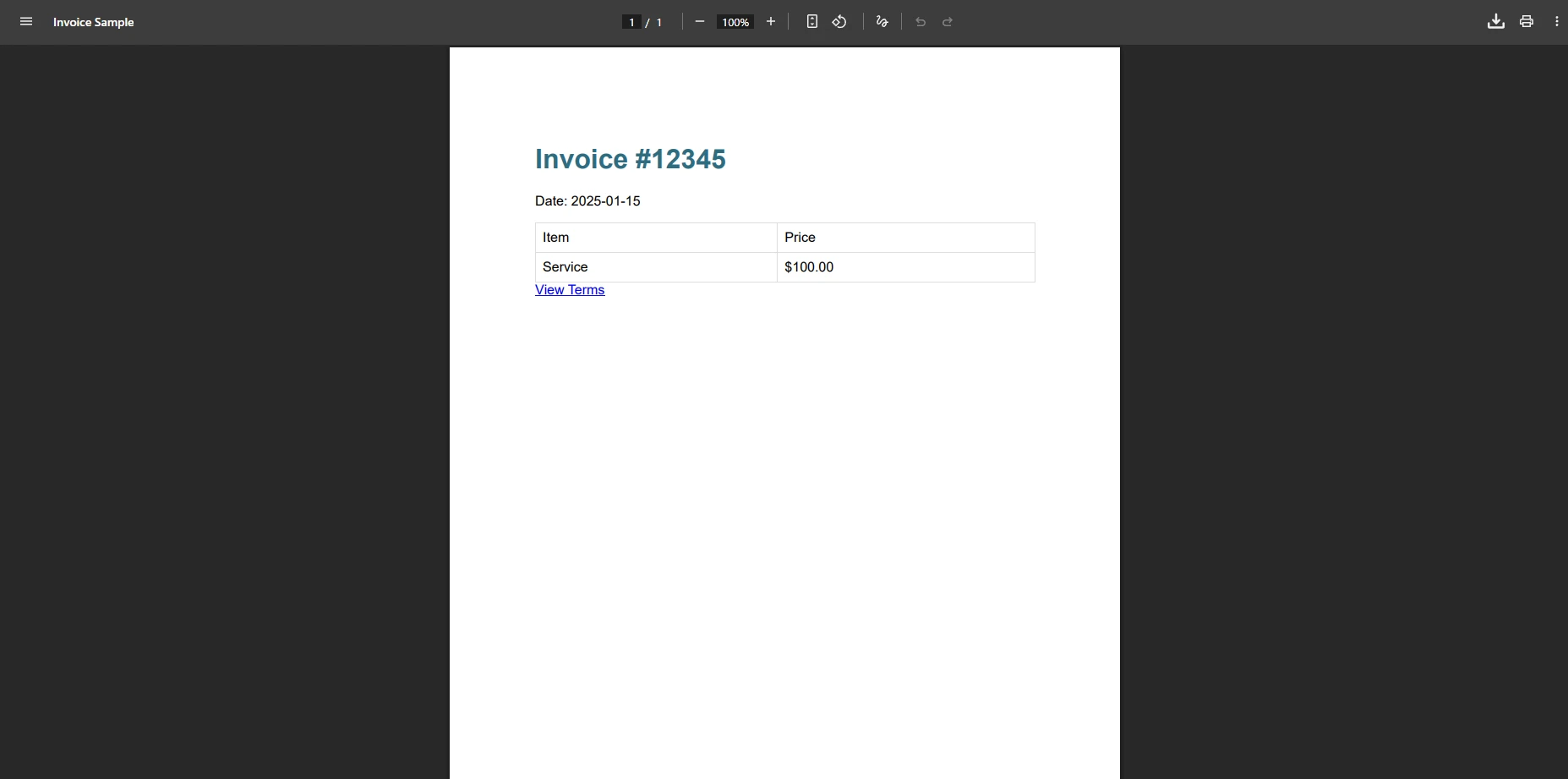
Bu HTML Elemanları iText'te Neden Sorunlara Neden Olur?
iText'in XMLWorker'ı ile bu fatura, tablo stilleri, genişlik özellikleri veya yazı tipi spesifikasyonları nedeniyle başarısız olabilir. 'Belgede sayfa yok' hatası genellikle bu öğeler desteklenmediğinde görünür. Köprüler ve medya sorgusu referansları da doğru şekilde işlenmeyebilir. Bu sınırlamalar, dijital imzalar veya iş uygulamalarında sayfa numaraları gibi ileri düzey PDF özellikleri uygularken kritik hale gelir.
Mozilla Geliştirici Ağı'nın CSS üzerindeki belgelerine göre, modern CSS tarayıcılar tarafından doğal olarak desteklenen yüzlerce özelliğe ve değere sahiptir. XMLWorker bunların yalnızca küçük bir kısmını kapsar, bu yüzden gerçek dünya web içeriği sürekli olarak çözümleme hatalarını tetikler.
Çözümleme Hatası Olmadan HTML'yi PDF'e Nasıl Dönüştürürsünüz?
IronPDF, HTML'yi web tarayıcısında göründüğü haliyle işleyen bir Chrome tabanlı motor kullanır. Bu yaklaşım, çözümleme hatalarını ortadan kaldırır ve tüm modern HTML ve CSS özelliklerini destekler. Konfigürasyon seçeneklerinin tam listesini görmek için ChromePdfRenderer API referansına göz atabilirsiniz. Chrome motoru, XMLWorker'ın işleyemediği JavaScript çalıştırmayı, web yazı tiplerini ve duyarlı düzenleri destekler.
IronPDF'i NuGet Üzerinden Nasıl Yüklerim?
Kod yazmadan önce .NET NuGet paketini yükleyin. .NET CLI üzerinden bunu yapabilirsiniz:
dotnet add package IronPdf
Veya Visual Studio'daki NuGet Paket Yöneticisi Konsolu'ndan:
Install-Package IronPdf
Yüklendikten sonra, iText + XMLWorker hattını eksiksiz ve güvenilir bir çağrı ile değiştiren ChromePdfRenderer erişiminiz olur.
IronPDF ile HTML'yi PDF'e Nasıl İşlersiniz?
Aşağıdaki örnek, iText'te hatalara neden olan aynı fatura HTML'ini işler. Dikkat edin, hiçbir çözüm yolu, eklemeniz gereken boş paragraflar ya da yönetilecek sessiz hatalar yoktur:
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")IronPDF Çıkışı Nasıl Görünür?
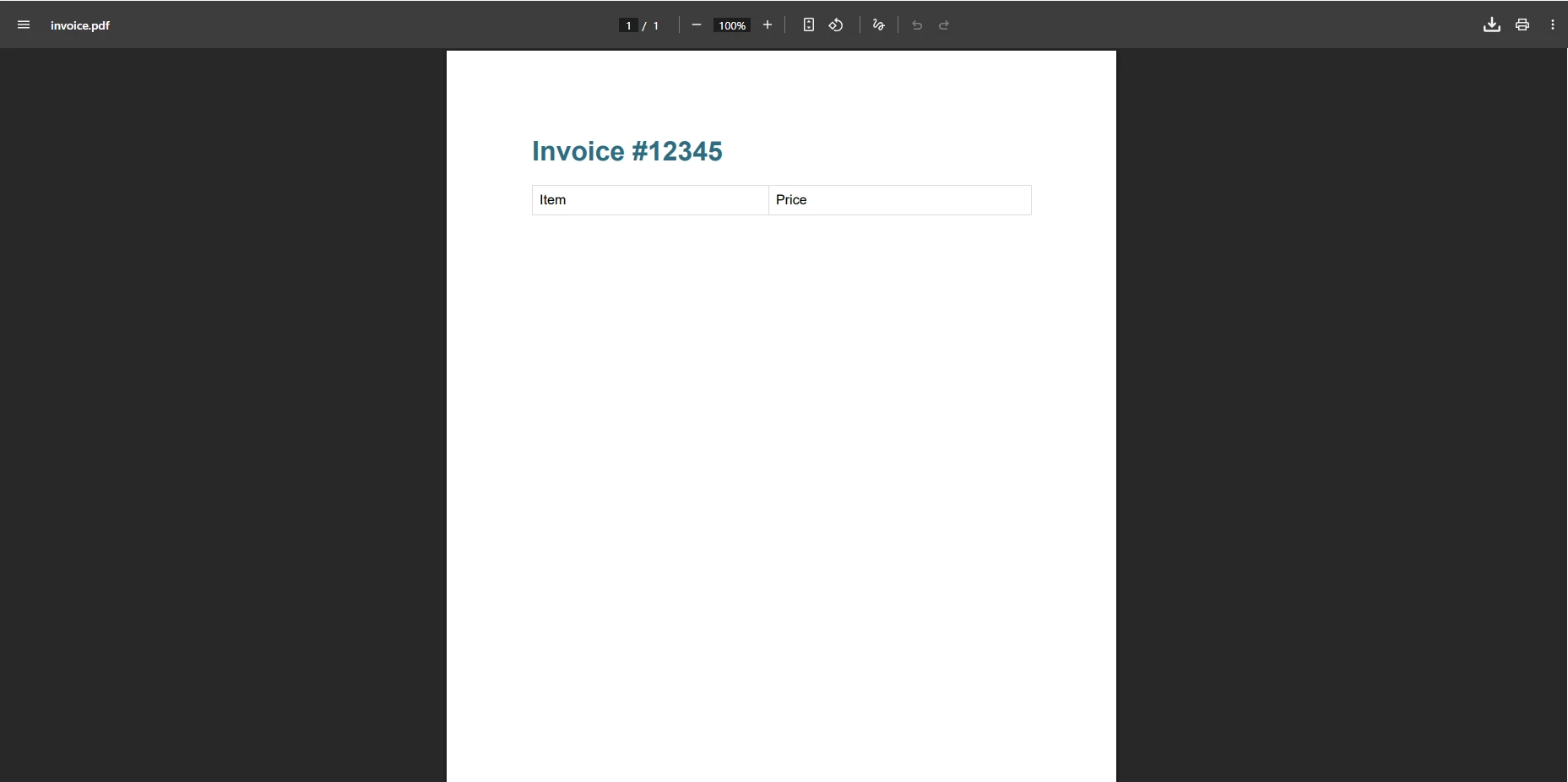
Bu Yaklaşım Çözümleme Hatalarını Neden Ortadan Kaldırır?
Bu kod herhangi bir istisna olmadan PDF dosyasını başarıyla oluşturur. Yöntem karmaşık HTML ve CSS'yi otomatik olarak ele alır, dolayısıyla geçici çözümlere gerek kalmaz. İçerik piksel mükemmelliğiyle, tarayıcı önizlemesiyle uyumlu olarak işlenir. IronPDF ayrıca asenkron işleme desteği, özel marjinler ve PDF sıkıştırma özellikleri sunarak optimize edilmiş dosya boyutları sağlar.
JavaScript ağırlıklı içerik veya tek sayfalı uygulamalar içeren senaryolar için, IronPDF'in RenderDelay seçeneği, PDF yakalanmadan önce JavaScript'in çalışmasına izin verir -- XMLWorker'ın bunu yapması mümkün değildir. Aşağıdaki örnek, üretime hazır asenkron bir modelde üstbilgiler, altbilgiler ve güvenlik ayarlarını ekler:
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End ClassGüvenilir PDF Oluşturma İçin En İyi Çözüm Nedir?
HTML'yi PDF'e dönüştürmek için kullanılan iki kütüphaneyi karşılaştırırken, yetenek farklılıkları doğrudan PDF kalitesini ve dağıtım güvenilirliğini etkiler:
| Özellik | iText + XMLWorker | IronPDF |
|---|---|---|
| Modern HTML/CSS desteği | Sınırlı (HTML 4, CSS 2) | Tam (Chrome işleme motoru) |
| JavaScript yürütme | Hayır | Evet |
| Hata işleme | Çözümleme hataları yaygın | Güvenilir işleme |
| Karmaşık tablolar | Genellikle başarısız | Tam destek |
| Özel yazı tipleri | Elle gömülmesi gerekli | Otomatik işleme |
| SVG desteği | Hayır | Evet |
| Asenkron işleme | Hayır | Evet |
| Docker/Linux desteği | Sınırlı | Tam doğal destek |
| CSS medya türleri | Temel | Ekran ve Baskı |
| Hata ayıklama araçları | Sınırlı | Chrome DevTools entegrasyonu |
iText'ten IronPDF'e Nasıl Geçiş Yaparsınız?
'Belgede sayfa yok' hatası yaşayan geliştiriciler için IronPDF'e geçiş, anında bir çözüm sunar. Dönüşüm süreci basittir ve IronPDF tam belgeleme ve kod örnekleri sunar. Aşağıdaki öncesi ve sonrası karşılaştırması, karmaşıklıkta azalmayı gösterir:
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassIronPDF'in API'sini Daha Geliştirici Dostu Yapan Nedir?
Basitleştirilmiş API, daha az kod bakımı ve çözümleme hatası ayıklaması gerektirmediği anlamına gelir. IronPDF ayrıca üstbilgiler ve altbilgiler ekleme , PDF'leri birleştirme, ve dijital imza uygulama gibi özellikler sunar ve karmaşık geçici çözümler gerektirmez. Docker ortamlarında çalışan veya Linux sunucularına dağıtım yapan ekipler için, IronPDF platformlar arasında tutarlı davranış sergiler.
Ücretsiz denemenizi başlatın ve hatasız HTML'den PDF'e dönüşüm tecrübesi yaşayın.
Sonraki Adımlarınız Neler?
"belgenin sayfası yok" hatası, iText'in XMLWorker'ına yapılandırılmış temel parsing sınırlamalarından kaynaklanır. Çözüm yolları var olsa da - belgelere boş bir paragrafla önceden dolum yapmak gibi - karmaşık HTML işleme ile altta yatan sorunu çözmezler. IronPDF'in Chrome tabanlı işleme motoru, modern web içeriğini çözümleme hataları olmadan ele alan güvenilir bir çözüm sunar.
HTML'den tutarlı şekilde PDF oluşturması gerektiren üretim uygulamaları için, IronPDF çözümleyici hatalarını ayıklama sıkıntısını ortadan kaldırır ve profesyonel sonuçlar sunar. Motor, tüm HTML öğeleri, CSS stillerini ve JavaScript'i işler ve belgelerin her seferinde doğru şekilde işlenmesini sağlar. İster faturalar, raporlar veya metin, tablolar ve görüntüler içeren herhangi bir belge oluşturuyor olun, IronPDF ihtiyaç duyduğunuz çözümü sunar.
İleri hareket etmek için önerilen bir sonraki adımlar şunlardır:
- IronPDF'i NuGet (
dotnet add package IronPdf) aracılığıyla yükleyin ve hızlı başlangıç kılavuzunu çalıştırın - HTML'den PDF'e dönüşüm eğitimine tam bir işleme seçenekleri yürüyüşü göz atın
- ChromePdfRenderer API referansını, marjinleri konfigüre etmek, üstbilgiler, JavaScript bekleme süreleri ve güvenlik ayarları için inceleyin
- Kütüphane farklarının ayrıntılı dökümünü almak için iText vs. IronPDF karşılaştırmasını kontrol edin
- hata ayıklama kılavuzlarını gözden geçirin ve yüksek hacimli iş yükleri için çıktıyı optimize edin
- bulut dağıtımları için, Azure ve Docker kurulum kılavuzlarına bakın
Sıkça Sorulan Sorular
iTextSharp HTML'den PDF'ye 'belge sayfası yok' hatasına ne sebep olur?
iTextSharp'ta 'belge sayfası yok' hatası, HTML'den PDF'ye dönüştürme sürecinde, genellikle HTML içeriği veya desteklenmeyen özelliklerle ilgili sorunlar nedeniyle çözümleme başarısız olduğunda meydana gelir.
HTML'den PDF'ye dönüştürme için iTextSharp'a alternatif var mı?
Evet, IronPDF .NET uygulamalarında HTML'den PDF'ye dönüştürme için iTextSharp'ta bulunan birçok sınırlamayı aşarak güvenilir bir çözüm sunar.
IronPDF, HTML'den PDF'ye dönüştürmeyi iTextSharp'tan farklı olarak nasıl ele alır?
IronPDF, daha kapsamlı çözümleme yetenekleri sunar ve daha geniş bir HTML ve CSS özellik yelpazesini destekleyerek 'sayfa yok' gibi dönüştürme hatalarının olasılığını azaltır.
IronPDF karmaşık HTML belgelerini PDF'ye dönüştürebilir mi?
IronPDF, karmaşık CSS, JavaScript ve multimedya unsurları içeren karmaşık HTML belgelerini işleyebilmek üzere tasarlanmıştır ve doğru PDF çıktısı sağlar.
Geliştiriciler neden iTextSharp yerine IronPDF kullanmayı düşünmelidir?
Geliştiricilerin, kullanım kolaylığı, HTML ve CSS için tam destek sağlaması ve yaygın hatalar olmadan yüksek kaliteli PDF'ler üretebilmesi nedeniyle IronPDF'i iTextSharp'a tercih edebilirler.
IronPDF, PDF dönüşüm sürecinde JavaScript ve CSS'i destekliyor mu?
Evet, IronPDF, JavaScript, CSS ve modern HTML5'i tam olarak destekler, bu da orijinal HTML'nin görsel bütünlüğünün PDF çıktısında sürdürüldüğü anlamına gelir.
HTML'den PDF'ye dönüştürme için IronPDF ile nasıl başlayabilirim?
IronPDF ile başlamak için, web sitesinde bulunan ayrıntılı eğitimleri ve belgeleri keşfedebilirsiniz, bunlar uygulama için adım adım kılavuzlar sunar.
.NET geliştiricileri için IronPDF kullanmanın faydaları nelerdir?
IronPDF, karmaşık HTML içeriği desteği, kolay entegrasyon ve güvenilir performans gibi avantajlarla .NET geliştiricileri için esnek bir PDF üretim aracı sunar.
IronPDF, PDF dönüştürme hatalarının giderilmesi için herhangi bir destek sunuyor mu?
Evet, IronPDF, PDF dönüştürme sırasında karşılaşılan sorunların giderilmesine yardımcı olacak geniş çaplı destek kaynakları, belgeler ve bir destek ekibi sunar.
Satın almadan önce IronPDF'in yeteneklerini test etmenin bir yolu var mı?
IronPDF, geliştiricilerin özelliklerini test etmesine ve satın alma kararı vermeden önce performansını değerlendirmesine olanak tanıyan bir ücretsiz deneme sürümü sunar.