Corriger l'erreur iTextSharp « Document sans pages » lors de la conversion HTML en PDF | IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
L'erreur " document sans pages " d'iTextSharp se produit lorsque XMLWorker ne parvient pas à analyser le contenu HTML, mais le moteur de rendu d'IronPDF basé sur Chrome élimine ce problème en traitant le HTML exactement comme le font les navigateurs, fournissant une génération de PDF fiable sans exceptions d'analyse.
La conversion de HTML en PDF est une exigence courante dans les applications .NET , mais les développeurs utilisant iTextSharp rencontrent fréquemment l'erreur " le document n'a pas de pages ". Cette erreur apparaît lorsque le processus de génération de documents PDF échoue, obligeant les développeurs à rechercher des solutions. Cette analyse explore les raisons de ce phénomène et comment le résoudre efficacement grâce aux fonctionnalités HTML vers PDF d'IronPDF .
Qu'est-ce qui provoque l'erreur "Le document n'a pas de pages" ?
L'exception "le document n'a pas de pages" se produit lorsque l'analyseur d'iTextSharp ne parvient pas à traiter le contenu HTML pour en faire un document PDF valide. Cette erreur apparaît généralement lors de la fermeture du document, comme détaillé dans de nombreux fils de discussion Stack Overflow concernant ce problème . Comprendre la cause profonde aide les développeurs à choisir la bibliothèque PDF adaptée à leurs besoins .
L'erreur se produit car XMLWorker, le composant d'analyse HTML d'iTextSharp, échoue silencieusement lorsqu'il rencontre des structures HTML qu'il ne peut pas traiter. Au lieu de générer une exception lors de l'analyse, il produit un document vide. Lorsque le document se ferme, iTextSharp détecte qu'aucun contenu n'a été écrit et génère l'exception " le document ne contient aucune page ". Ce mode de défaillance silencieux rend le débogage particulièrement frustrant, car la trace de la pile pointe vers l'opération de fermeture plutôt que vers l'échec d'analyse réel.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End ModuleQue s'affiche la console lorsque cette erreur se produit ?

Ce code tente de créer un fichier PDF à partir de HTML, mais rencontre une exception car XMLWorker n'a pas pu analyser correctement le contenu HTML. L'opération d'écriture s'achève, mais aucun contenu n'est ajouté au document, ce qui donne un fichier vide. Cet échec d'analyse est l'un des problèmes les plus courants rencontrés par les développeurs lors de la conversion de HTML en PDF dans les applications ASP.NET . Le problème se complexifie lorsqu'il s'agit de styles CSS personnalisés ou de contenu rendu en JavaScript.
Pourquoi la bibliothèque de remplacement rencontre-t-elle le même problème ?
Bien que XMLWorker ait remplacé le HTMLWorker obsolète, il rencontre toujours le même problème avec certaines structures HTML. Le problème persiste car XMLWorker a des exigences d'analyse strictes, comme indiqué dans les forums officiels d'iText . Cette limitation affecte les développeurs qui tentent de mettre en œuvre une conversion HTML vers PDF au pixel près ou qui travaillent avec des mises en page CSS réactives dans les applications Web modernes.
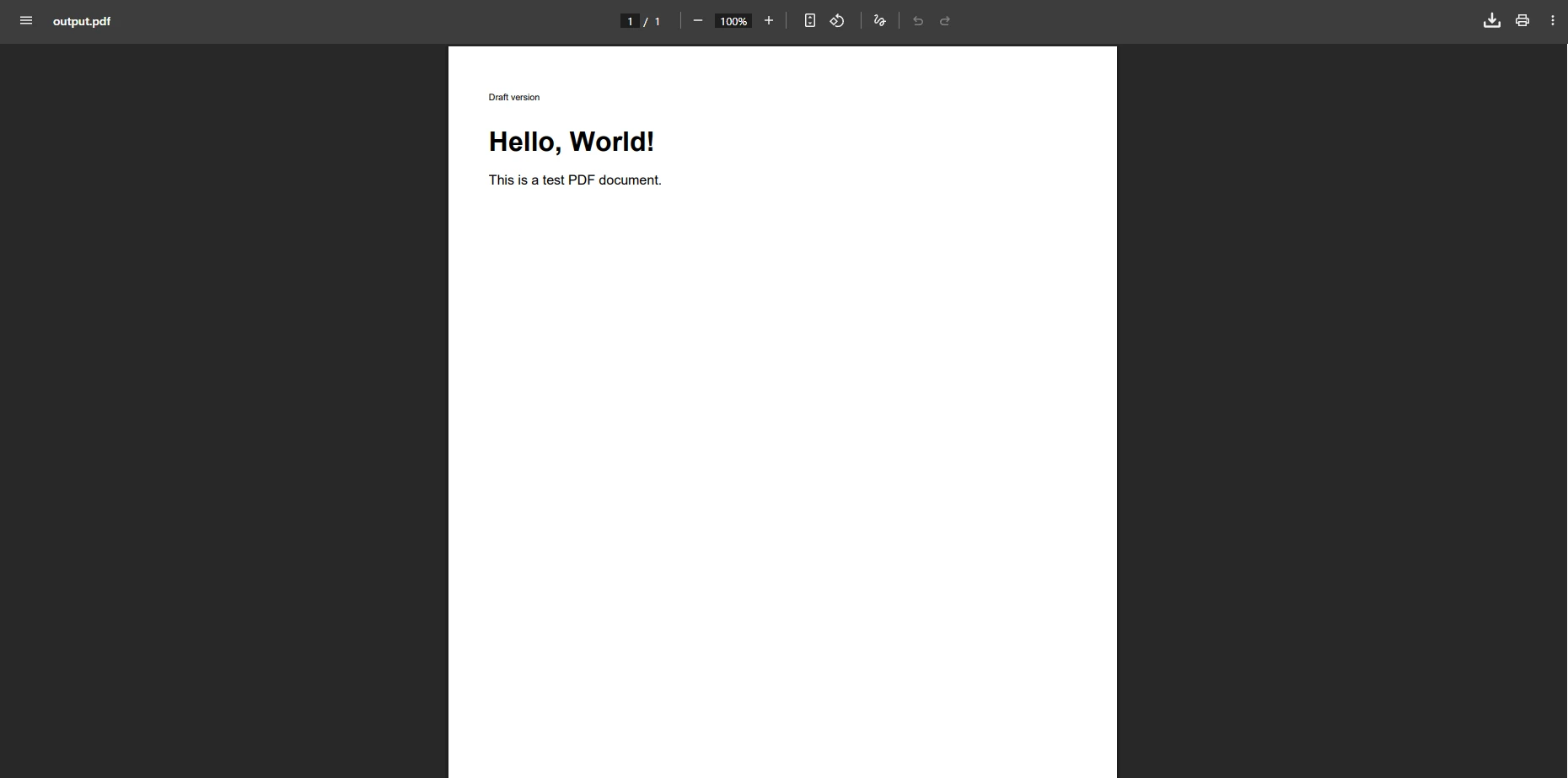
La solution courante consiste à pré-remplir le document avec un paragraphe vide avant d'analyser le code HTML. Cela empêche l'exception " aucune page " en garantissant qu'au moins un élément de contenu existe lors de la fermeture du document :
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End SubÀ quoi ressemble le fichier PDF généré avec cette solution de contournement ?
Pourquoi certains éléments HTML complexes ne s'affichent-ils toujours pas ?
L'ajout d'un paragraphe vide empêche l'erreur immédiate, mais le code HTML complexe contenant des éléments de tableau, des images ou des polices personnalisées ne s'affiche souvent pas correctement. Le contenu du document PDF résultant peut être manquant ou malformé. Les développeurs rencontrent le même problème lors du traitement de code HTML contenant des styles intégrés, des éléments de lien hypertexte ou des propriétés de largeur spécifiques. Les références nulles et le rendu d'éléments manquants créent des problèmes supplémentaires qui nécessitent une résolution plus poussée.
XMLWorker a été conçu pour gérer un sous-ensemble de HTML 4 et de CSS 2 de base. Les pages Web modernes utilisent couramment des fonctionnalités bien au-delà de cette portée : CSS Grid, Flexbox, variables CSS, expressions calc(), graphiques SVG et rendu piloté par JavaScript. Chacun de ces éléments peut déclencher l'erreur " aucune page " ou produire une sortie corrompue sans message d'erreur explicite, ni autre message descriptif pour guider la correction.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Custom fonts -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Custom fonts -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}' Common XMLWorker limitations that require manual handling
Public Sub ProcessComplexHTML(htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Custom fonts -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End SubComment convertir du HTML moderne sans rencontrer la même erreur ?
Ce scénario concret illustre la conversion d'une facture stylisée du format HTML au format PDF. L'exemple comprend des éléments courants qui causent souvent des problèmes : CSS en ligne, requêtes média, mises en page de tableaux et hyperliens. Voici les types de structures qui déclenchent l'erreur " aucune page " dans XMLWorker :
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>Que se passe-t-il lorsque iTextSharp traite cette facture ?
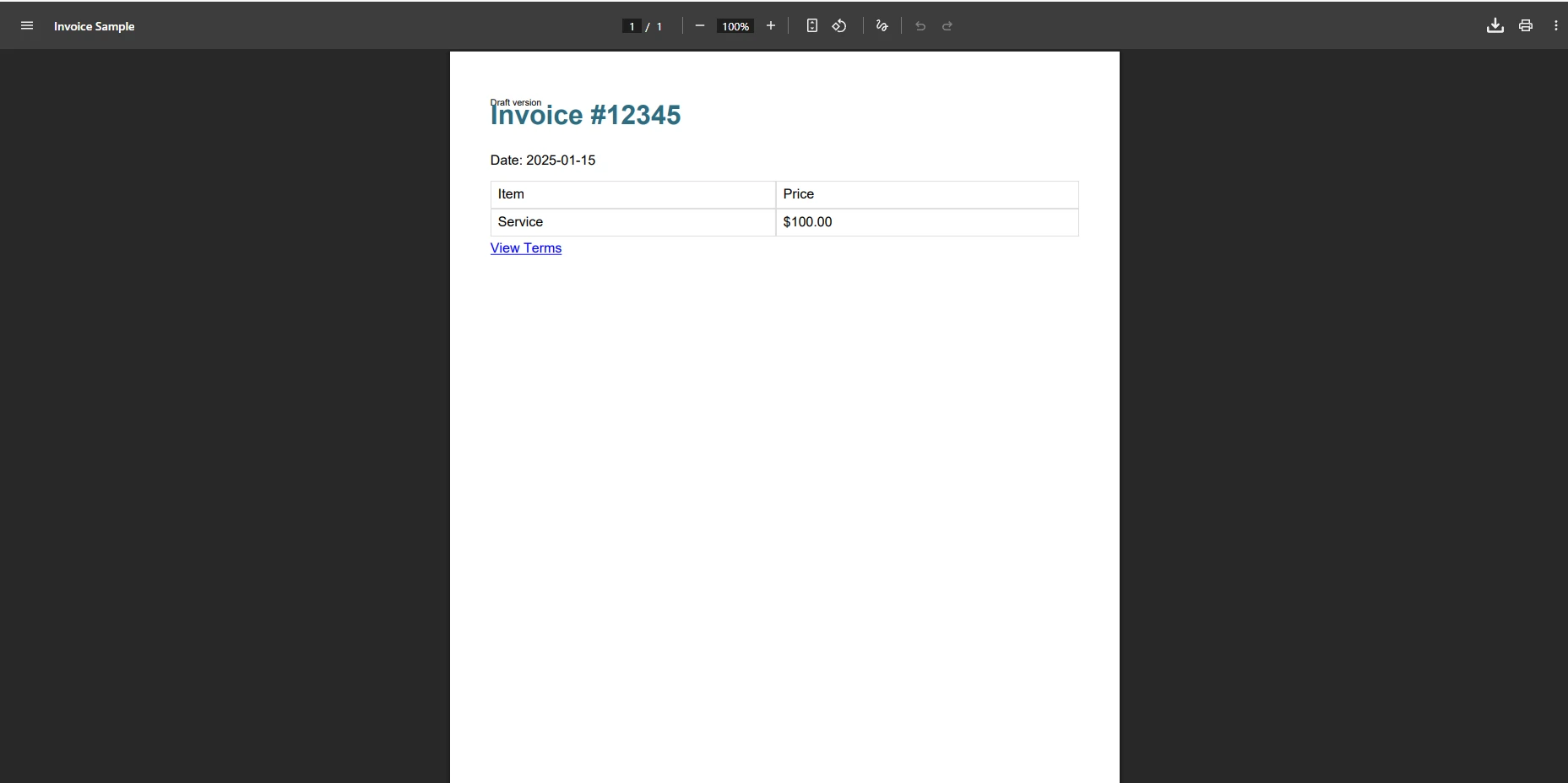
Lorsque iTextSharp traite ce modèle de facture, le résultat est souvent dépourvu de style CSS, les couleurs d'arrière-plan sont manquantes et les bordures de tableau disparaissent. La requête @media print est ignorée, et toute référence à une police Web provoque des erreurs d'analyse silencieuses. Si le code HTML contient une propriété CSS que XMLWorker ne reconnaît pas, le bloc entier risque de ne pas s'afficher, ce qui entraînera un contenu manquant sans qu'aucune erreur ne soit signalée lors de l'analyse.
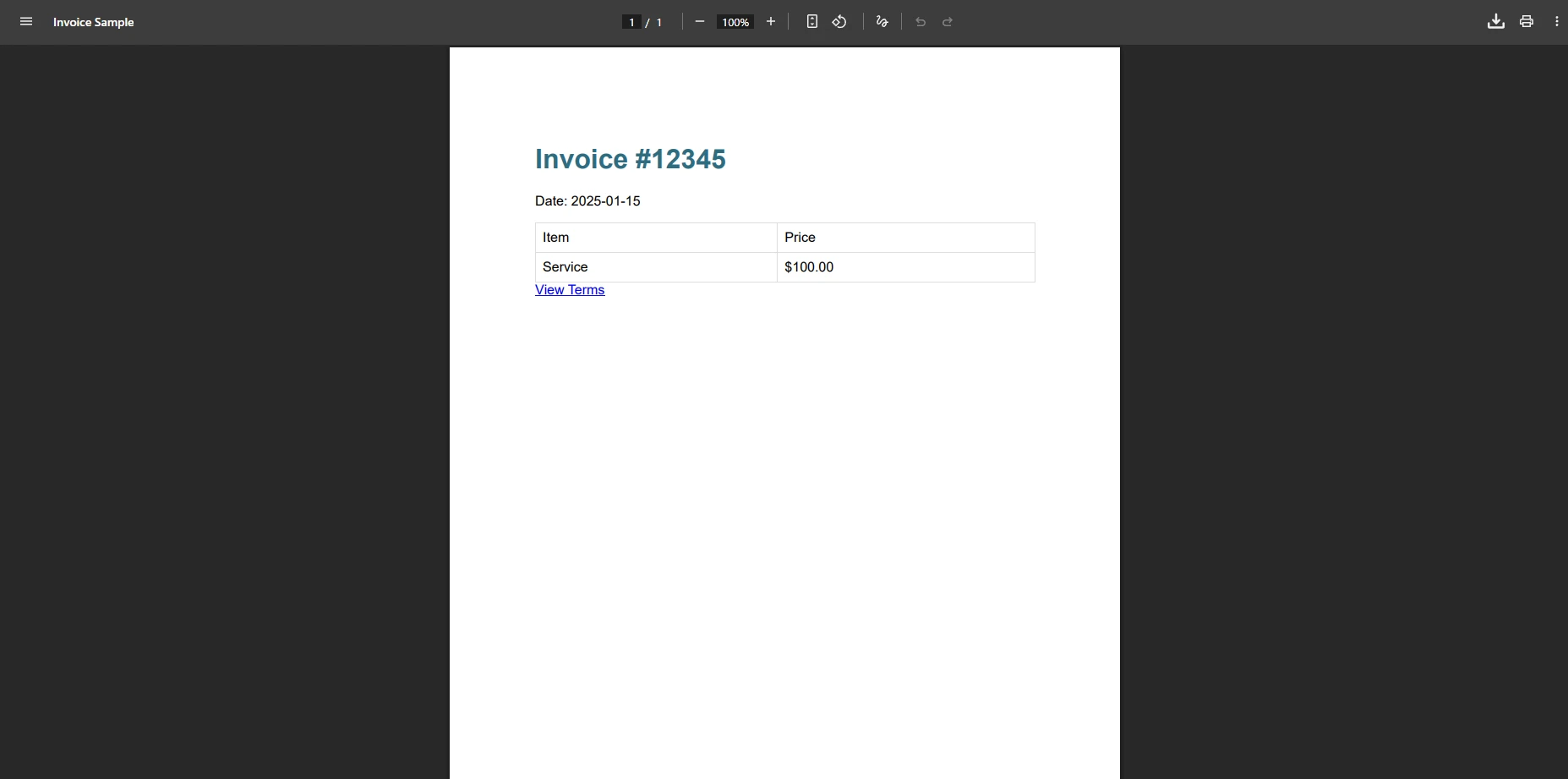
Comment IronPDF génère-t-il la même facture ?
Pourquoi ces éléments HTML posent-ils problème dans iTextSharp ?
Avec XMLWorker d'iTextSharp, cette facture pourrait échouer en raison du style du tableau, des propriétés de largeur ou des spécifications de police. L'erreur " ce document ne comporte aucune page " apparaît souvent lorsque ces éléments ne sont pas pris en charge. Les hyperliens et les références de requêtes média peuvent également ne pas s'afficher correctement. Ces limitations deviennent critiques lors de la mise en œuvre de fonctionnalités PDF avancées telles que les signatures numériques ou la numérotation des pages dans les applications professionnelles.
Selon la documentation du Mozilla Developer Network sur CSS , le CSS moderne comprend des centaines de propriétés et de valeurs prises en charge nativement par les navigateurs. XMLWorker ne couvre qu'une petite partie de ces cas, ce qui explique pourquoi le contenu web réel provoque systématiquement des erreurs d'analyse.
Comment gérer la conversion HTML vers PDF sans erreurs d'analyse ?
IronPDF utilise un moteur de rendu basé sur Chrome qui traite le HTML exactement comme il apparaît dans un navigateur web. Cette approche élimine les erreurs d'analyse et prend en charge toutes les fonctionnalités HTML et CSS modernes. Vous pouvez consulter la documentation de l'API ChromePdfRenderer pour obtenir la liste complète des options de configuration. Le moteur Chrome prend en charge l'exécution de JavaScript , les polices Web et les mises en page réactives, ce que XMLWorker ne peut pas gérer.
Comment installer IronPDF via NuGet?
Avant d'écrire le moindre code, installez le package NuGet IronPDF . Vous pouvez le faire depuis l'interface de ligne de commande .NET :
dotnet add package IronPdfdotnet add package IronPdfOu depuis la console du gestionnaire de packages NuGet dans Visual Studio :
Install-Package IronPdfInstall-Package IronPdfUne fois installé, vous avez accès à ChromePdfRenderer, qui remplace l'ensemble du pipeline iTextSharp + XMLWorker par un seul appel fiable.
Comment convertir du HTML en PDF avec IronPDF?
L'exemple suivant génère le même code HTML de facture qui provoquait des erreurs dans iTextSharp. Notez qu'il n'y a pas de solution de contournement, pas de paragraphes vides à ajouter en début de document, ni d'erreurs silencieuses à gérer :
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")À quoi ressemble le résultat IronPDF ?
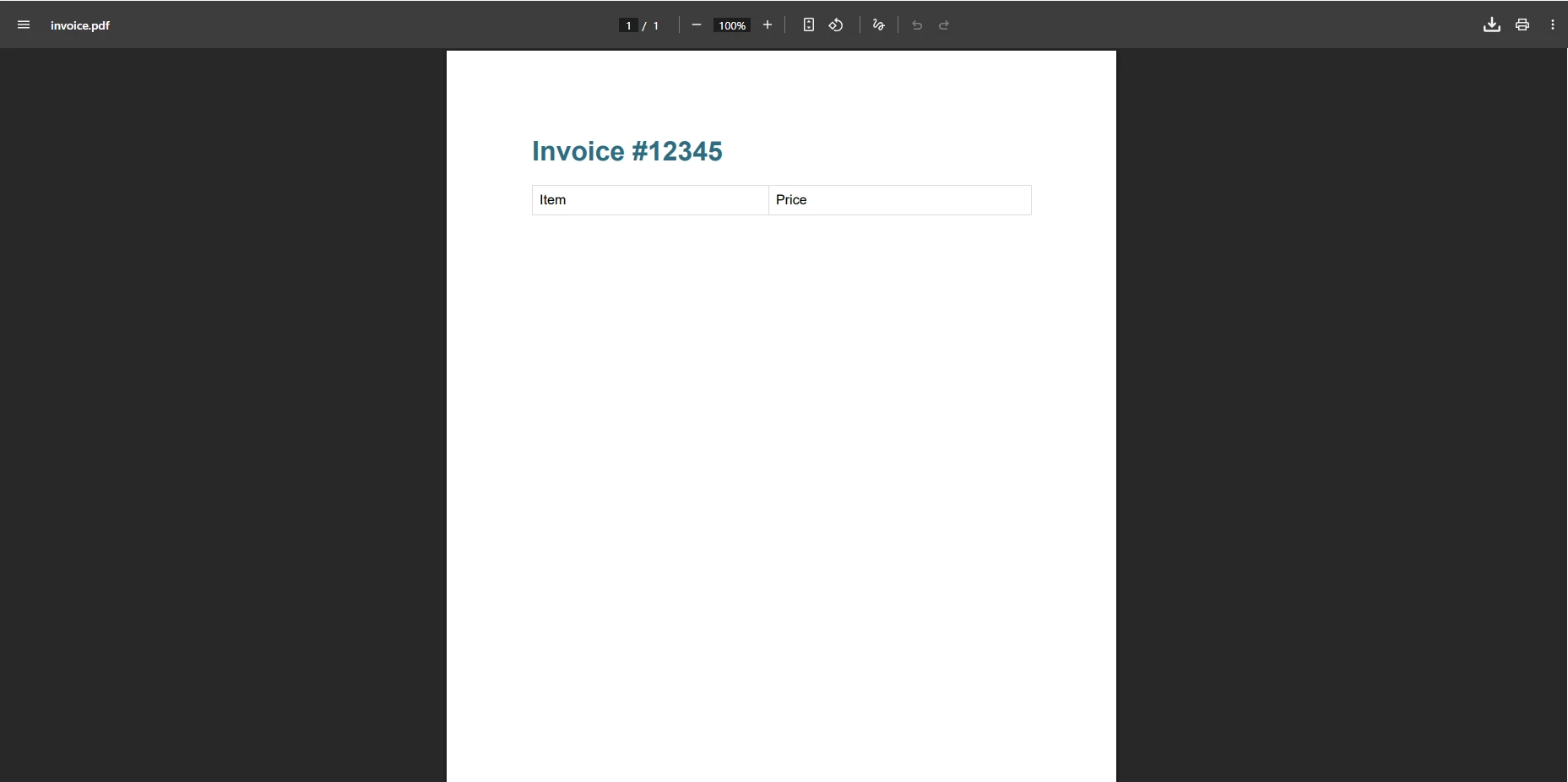
Pourquoi cette approche élimine-t-elle les erreurs d'analyse syntaxique ?
Ce code crée avec succès le fichier PDF sans aucune exception. La méthode traite automatiquement les fichiers HTML et CSS complexes, éliminant ainsi la nécessité de recourir à des solutions de contournement. Le contenu est rendu au pixel près, correspondant à la prévisualisation du navigateur. IronPDF prend également en charge le rendu asynchrone , les marges personnalisées et la compression PDF pour des fichiers de taille optimisée.
Pour les scénarios impliquant un contenu riche en JavaScript ou des applications monopages, l'option RenderDelay d'IronPDF permet l'exécution du JavaScript avant la capture du PDF, chose que XMLWorker ne peut pas faire du tout. L'exemple suivant ajoute des en-têtes, des pieds de page et des paramètres de sécurité selon un modèle asynchrone prêt pour la production :
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End ClassQuelle est la meilleure solution pour générer des PDF fiables ?
Lorsqu'on compare les deux bibliothèques de conversion HTML vers PDF, les différences de fonctionnalités affectent directement la qualité du PDF et la fiabilité du déploiement :
| Caractéristique | iTextSharp + XMLWorker | IronPDF |
|---|---|---|
| Prise en charge moderne du HTML/CSS | Limité (HTML 4, CSS 2) | Complet (moteur de rendu Chrome) |
| Exécution JavaScript | Non | Oui |
| Gestion des erreurs | Exceptions d'analyse courantes | Rendu fiable |
| Tables complexes | Échoue souvent | Prise en charge complète |
| Polices personnalisées | Intégration manuelle requise | Gestion automatique |
| Support SVG | Non | Oui |
| rendu asynchrone | Non | Oui |
| Prise en charge de Docker/Linux | Limitée | Prise en charge native complète |
| types de médias CSS | Basique | Sérigraphie et impression |
| Outils de débogage | Limitée | Intégration des outils de développement Chrome |
Comment migrer d'iTextSharp vers IronPDF?
Pour les développeurs qui rencontrent l'erreur "le document n'a pas de pages", la migration vers IronPDF offre une solution immédiate. Le processus de conversion est simple et IronPDF propose une documentation complète ainsi que des exemples de code . La comparaison avant-après suivante illustre la réduction de la complexité :
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassQu'est-ce qui rend l'API d'IronPDF plus conviviale pour les développeurs ?
L'API simplifiée signifie moins de code à maintenir et pas d'erreurs d'analyse à déboguer. IronPDF offre également des fonctionnalités permettant d' ajouter des en-têtes et des pieds de page , de fusionner des PDF et d'appliquer des signatures numériques sans solutions de contournement complexes. Pour les équipes travaillant dans des environnements Docker ou déployant sur des serveurs Linux, IronPDF offre un comportement cohérent sur toutes les plateformes.
Démarrez votre essai gratuit pour bénéficier d'une conversion HTML vers PDF sans erreur.
Quelles sont vos prochaines étapes ?
L'erreur " le document n'a pas de pages " provient de limitations fondamentales d'analyse intégrées à XMLWorker d'iTextSharp. Bien qu'il existe des solutions de contournement — comme le pré-remplissage du document avec un paragraphe vide —, elles ne résolvent pas le problème sous-jacent lié au traitement complexe du HTML. Le rendu d'IronPDF basé sur Chrome offre une solution fiable qui gère le contenu web moderne sans exceptions d'analyse.
Pour les applications de production nécessitant une génération cohérente de PDF à partir de HTML, IronPDF élimine la frustration liée au débogage des erreurs d'analyseur syntaxique et fournit des résultats professionnels. Le moteur gère tous les éléments HTML, les styles CSS et JavaScript, garantissant ainsi un affichage correct des documents à chaque fois. Que vous créiez des factures , des rapports ou tout autre document contenant du texte, des tableaux et des images, IronPDF vous offre la solution idéale.
Pour aller de l'avant, voici les prochaines étapes recommandées :
- Installez IronPDF via NuGet (
dotnet add package IronPdf) et exécutez le guide de démarrage rapide - Consultez le tutoriel HTML vers PDF pour une présentation complète des options de rendu.
- Consultez la documentation de l'API ChromePdfRenderer pour configurer les marges, les en-têtes, les délais d'attente JavaScript et les paramètres de sécurité.
- Consultez la comparaison entre iTextSharp et IronPDF pour une analyse détaillée des différences entre les bibliothèques.
- Consultez les guides de dépannage pour optimiser le rendement en cas de charges de travail importantes.
- Pour les déploiements dans le cloud, consultez les guides d'installation d'Azure et de Docker.
Questions Fréquemment Posées
Quelle est la cause de l'erreur iTextSharp HTML to PDF "le document n'a pas de pages" ?
L'erreur "le document n'a pas de pages" dans iTextSharp se produit lorsque le processus d'analyse échoue lors de la conversion de HTML en PDF, souvent en raison de problèmes liés au contenu HTML ou à des fonctionnalités non prises en charge.
Existe-t-il une alternative à iTextSharp pour la conversion de HTML en PDF ?
Oui, IronPDF offre une solution fiable pour la conversion de HTML en PDF dans les applications .NET, en surmontant de nombreuses limitations trouvées dans iTextSharp.
En quoi IronPDF gère-t-il la conversion de HTML en PDF différemment d'iTextSharp ?
IronPDF offre des capacités de parsing plus complètes et prend en charge un plus large éventail de fonctionnalités HTML et CSS, réduisant ainsi la probabilité d'erreurs de conversion telles que l'erreur 'pas de pages'.
IronPDF peut-il convertir des documents HTML complexes en PDF ?
IronPDF est conçu pour traiter des documents HTML complexes, notamment ceux contenant des éléments CSS, JavaScript et multimédias avancés, en garantissant une sortie PDF précise.
Pourquoi les développeurs devraient-ils envisager d'utiliser IronPDF plutôt qu'iTextSharp ?
Les développeurs pourraient préférer IronPDF à iTextSharp en raison de sa facilité d'utilisation, son support complet pour HTML et CSS, et sa capacité à produire des PDFs de haute qualité sans erreurs courantes.
IronPDF prend-il en charge JavaScript et CSS pendant le processus de conversion PDF ?
Oui, IronPDF prend entièrement en charge JavaScript, CSS et HTML5 moderne, ce qui garantit que l'intégrité visuelle du HTML d'origine est maintenue dans la sortie PDF.
Comment puis-je commencer à utiliser IronPDF pour la conversion de HTML en PDF ?
Pour commencer à utiliser IronPDF, vous pouvez explorer leurs tutoriels détaillés et la documentation disponible sur leur site web, qui fournissent des guides étape par étape pour la mise en œuvre.
Quels sont les avantages d'utiliser IronPDF pour les développeurs .NET ?
IronPDF offre aux développeurs .NET un outil flexible pour la génération de PDF, avec des avantages tels que la prise en charge de contenu HTML complexe, la facilité d'intégration et des performances fiables.
IronPDF offre-t-il une assistance pour le dépannage des erreurs de conversion PDF ?
Oui, IronPDF fournit des ressources d'assistance étendues, notamment de la documentation et une équipe d'assistance, pour aider à dépanner et à résoudre les problèmes rencontrés lors de la conversion PDF.
Existe-t-il un moyen de tester les capacités d'IronPDF avant de l'acheter ?
IronPDF propose une version d'essai gratuite qui permet aux développeurs de tester ses fonctionnalités et d'évaluer ses performances avant de prendre une décision d'achat.