
Beheben Sie den iTextSharp-Fehler 'Dokument hat keine Seiten' in HTML-zu-PDF-Konvertierung | IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Der iTextSharp-Fehler "Dokument hat keine Seiten" tritt auf, wenn XMLWorker den HTML-Inhalt nicht parsen kann. Der Chrome-basierte Renderer von IronPDF beseitigt dieses Problem jedoch, indem er HTML genau wie Browser verarbeitet und so eine zuverlässige PDF-Generierung ohne Parsing-Ausnahmen ermöglicht.
Die Konvertierung von HTML in PDF ist eine häufige Anforderung in .NET Anwendungen, aber Entwickler, die iTextSharp verwenden, stoßen häufig auf den Fehler "Dokument hat keine Seiten". Dieser Fehler tritt auf, wenn die PDF-Dokumentgenerierung fehlschlägt, sodass Entwickler nach Lösungen suchen müssen. Diese Analyse untersucht, warum dies geschieht und wie man es mit den HTML-zu-PDF-Funktionen von IronPDF effektiv beheben kann.
Was verursacht den Fehler "Dokument hat keine Seiten"?
Die Ausnahme "Dokument hat keine Seiten" tritt auf, wenn der Parser von iTextSharp den HTML-Inhalt nicht in ein gültiges PDF-Dokument verarbeiten kann. Dieser Fehler tritt typischerweise beim Schließen des Dokuments auf, wie in zahlreichen Threads auf Stack Overflow zu diesem Thema detailliert beschrieben wird. Das Verständnis der Ursache hilft Entwicklern, die richtige PDF-Bibliothek für ihre Bedürfnisse auszuwählen.
Der Fehler tritt auf, weil XMLWorker – die HTML-Parsing-Komponente von iTextSharp – stillschweigend abbricht, wenn sie auf HTML-Strukturen stößt, die sie nicht verarbeiten kann. Statt beim Parsen eine Ausnahme auszulösen, wird ein leeres Dokument erzeugt. Beim Schließen des Dokuments erkennt iTextSharp, dass kein Inhalt geschrieben wurde, und löst die Ausnahme "Dokument hat keine Seiten" aus. Dieser stille Fehlermodus macht die Fehlersuche besonders frustrierend, da der Stack-Trace auf die Schließoperation und nicht auf den eigentlichen Parsing-Fehler hinweist.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End ModuleWas zeigt die Konsolenausgabe an, wenn dieser Fehler auftritt?

Dieser Code versucht, aus HTML eine PDF-Datei zu erstellen, stößt aber auf eine Ausnahme, da XMLWorker den HTML-Inhalt nicht erfolgreich parsen konnte. Der Schreibvorgang wird zwar abgeschlossen, aber es werden keine Inhalte in das Dokument eingefügt, sodass die Datei leer bleibt. Dieser Analysefehler ist eines der häufigsten Probleme, mit denen Entwickler bei der HTML-zu-PDF-Konvertierung in ASP.NET -Anwendungen konfrontiert werden. Das Problem wird noch komplexer, wenn es um benutzerdefinierte CSS-Stile oder JavaScript-gerenderte Inhalte geht.
Warum hat die Ersatzbibliothek dasselbe Problem?
XMLWorker hat zwar den veralteten HTMLWorker ersetzt, stößt aber immer noch auf das gleiche Problem mit bestimmten HTML-Strukturen. Das Problem besteht weiterhin, da XMLWorker strenge Parsing-Anforderungen hat, wie in den offiziellen Foren von iText dokumentiert. Diese Einschränkung betrifft Entwickler, die eine pixelgenaue HTML-zu-PDF-Konvertierung implementieren oder mit responsiven CSS-Layouts in modernen Webanwendungen arbeiten.
Die gängige Lösung besteht darin, das Dokument vor dem Parsen des HTML-Codes mit einem leeren Absatz vorzubefüllen. Dadurch wird die Ausnahme "Keine Seiten" verhindert, indem sichergestellt wird, dass beim Schließen des Dokuments mindestens ein Inhaltselement vorhanden ist:
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End SubWie sieht die PDF-Ausgabe mit diesem Workaround aus?
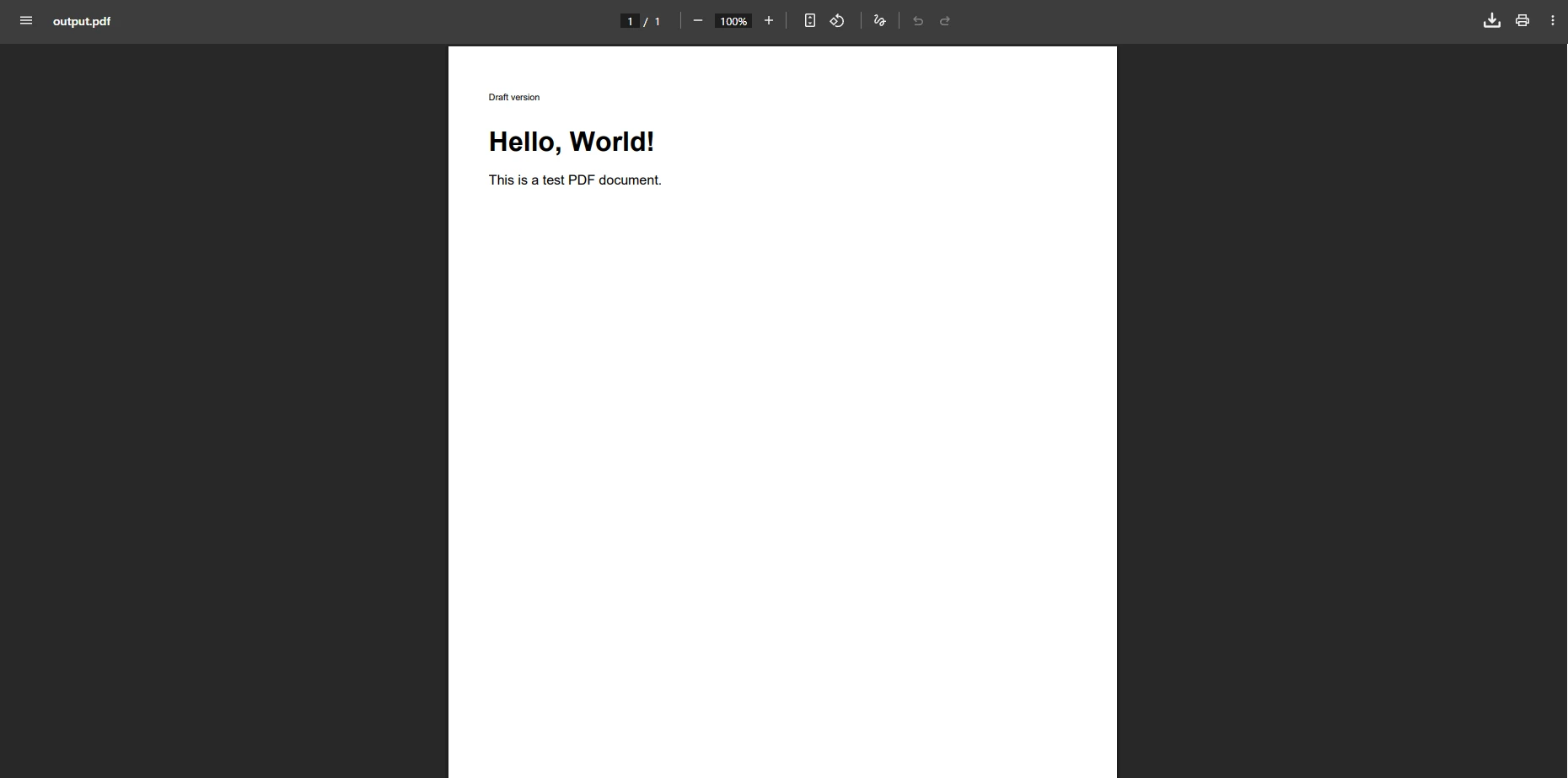
Warum werden komplexe HTML-Elemente immer noch nicht korrekt dargestellt?
Das Einfügen eines leeren Absatzes verhindert zwar den unmittelbaren Fehler, aber komplexes HTML mit Tabellenelementen, Bildern oder benutzerdefinierten Schriftarten wird oft nicht korrekt dargestellt. Im resultierenden PDF-Dokument kann der Inhalt fehlen oder fehlerhaft sein. Entwickler stoßen auf dasselbe Problem bei der Verarbeitung von HTML mit eingebetteten Stilen, Hyperlink-Elementen oder spezifischen Breiteneigenschaften. Nullreferenzen und fehlende Elementdarstellung erzeugen zusätzliche Probleme, die einer weiteren Lösung bedürfen.
XMLWorker wurde für die Verarbeitung einer Teilmenge von HTML 4 und grundlegendem CSS 2 entwickelt. Moderne Webseiten nutzen routinemäßig Funktionen, die weit über diesen Rahmen hinausgehen: CSS Grid, Flexbox, CSS-Variablen, calc()-Ausdrücke, SVG-Grafiken und JavaScript-gesteuertes Rendering. Jeder dieser Faktoren kann den Fehler "Keine Seiten" auslösen oder stillschweigend fehlerhafte Ausgaben erzeugen – und zwar ohne beschreibende Fehlermeldung, die zur Behebung des Problems auffordert.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Benutzerdefinierte Schriftarten -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Benutzerdefinierte Schriftarten -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}Public Sub ProcessComplexHTML(ByVal htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Benutzerdefinierte Schriftarten -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End SubWie kann man modernes HTML konvertieren, ohne denselben Fehler zu erhalten?
Dieses Praxisbeispiel veranschaulicht die Konvertierung einer formatierten Rechnung von HTML in PDF. Das Beispiel enthält häufige Elemente, die oft Probleme verursachen: Inline-CSS, Media Queries, Tabellenlayouts und Hyperlinks. Dies sind die Arten von Strukturen, die den Fehler "Keine Seiten" in XMLWorker auslösen:
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>Was geschieht, wenn iTextSharp diese Rechnung verarbeitet?
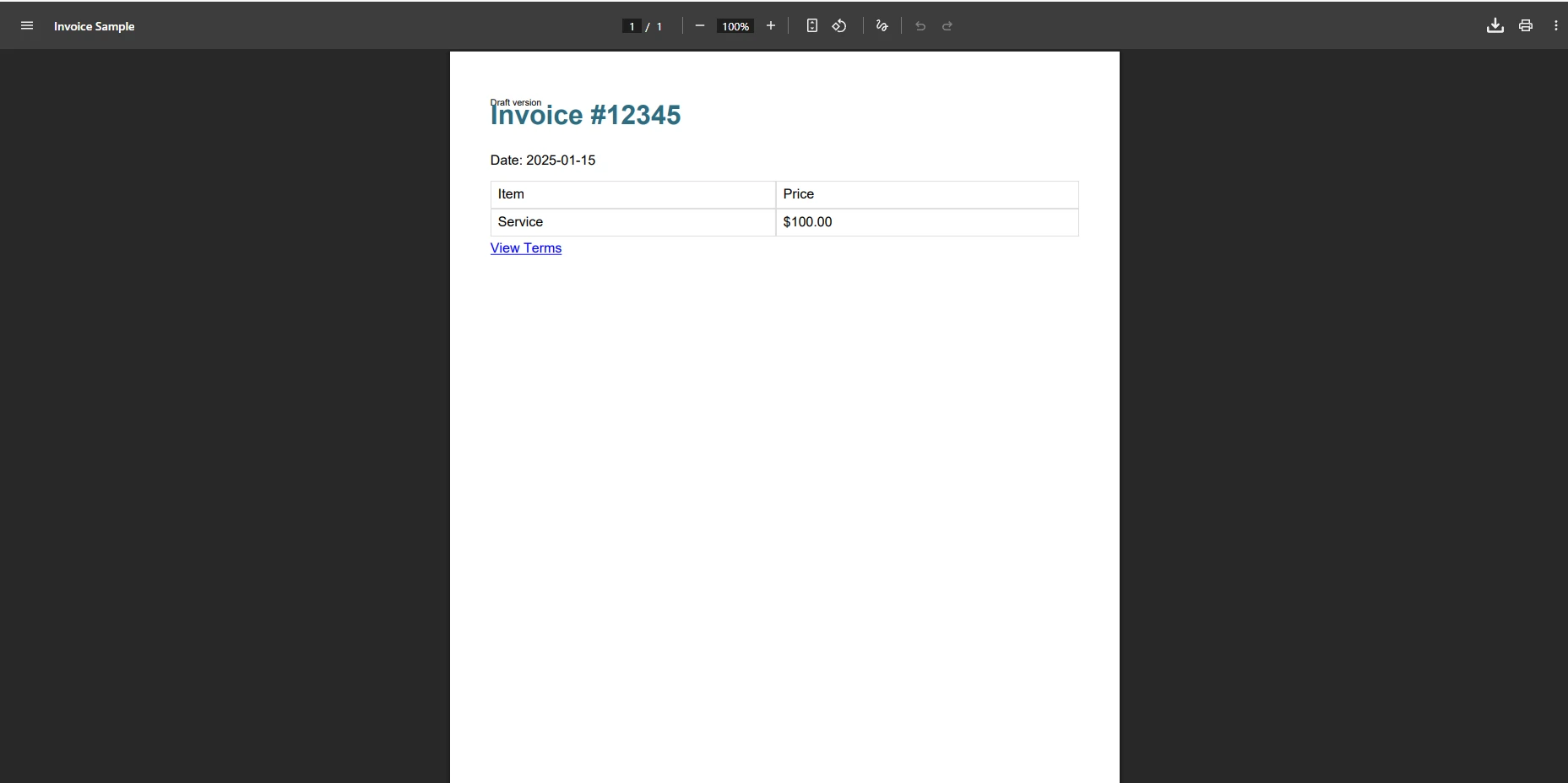
Bei der Verarbeitung dieser Rechnungsvorlage durch iTextSharp kommt es häufig vor, dass die Ausgabe ohne CSS-Formatierung, Hintergrundfarben und Tabellenrahmen auskommt. Die Abfrage @media print wird ignoriert, und alle Verweise auf Webfonts führen zu stillen Parsing-Fehlern. Wenn der HTML-Code eine CSS-Eigenschaft enthält, die XMLWorker nicht erkennt, kann der gesamte Block möglicherweise nicht gerendert werden – was dazu führt, dass Inhalte fehlen, ohne dass beim Parsen ein Fehler ausgelöst wird.
Wie rendert IronPDF dieselbe Rechnung?
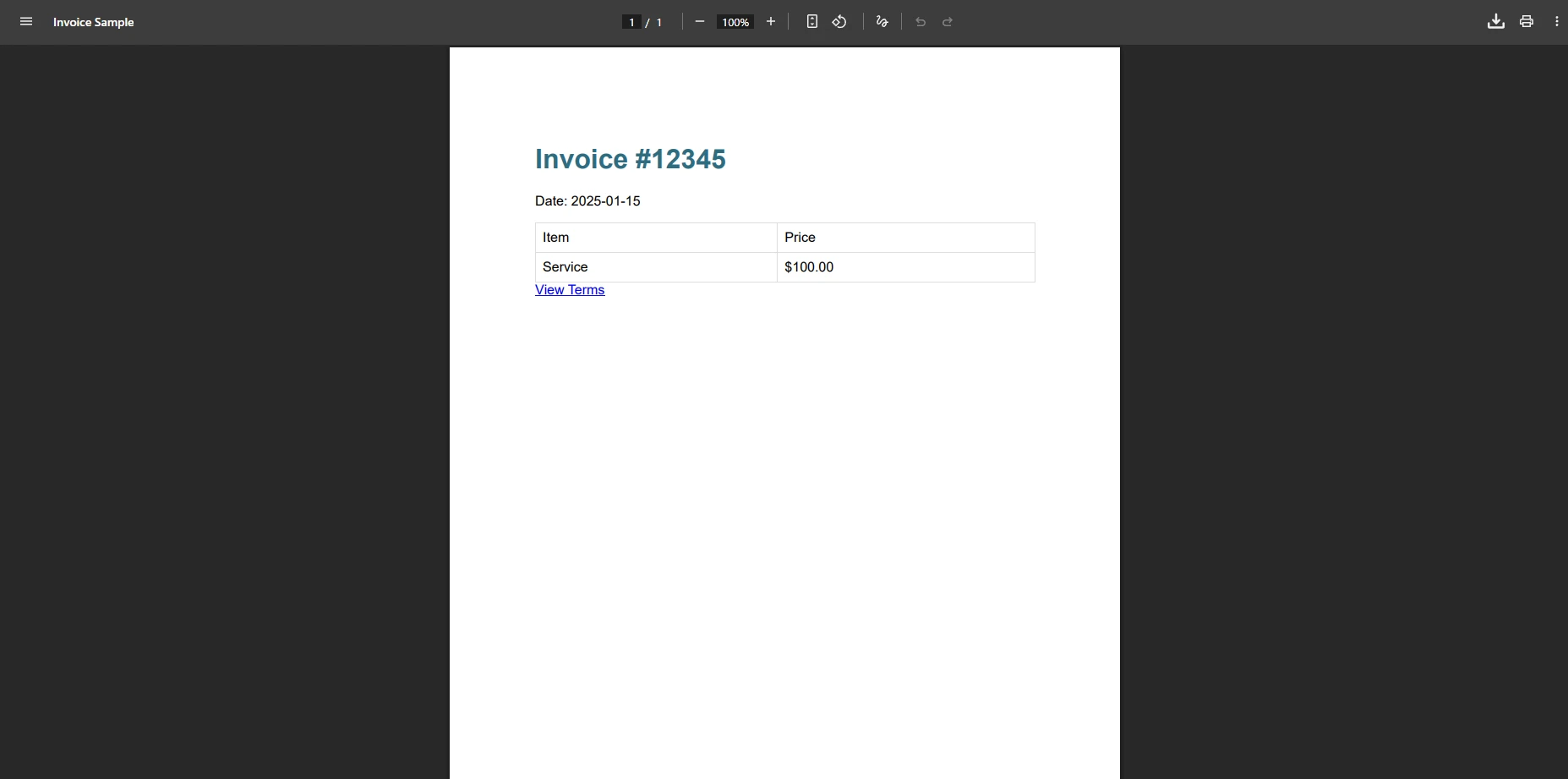
Warum verursachen diese HTML-Elemente Probleme in iTextSharp?
Bei Verwendung des XMLWorkers von iTextSharp kann diese Rechnung aufgrund von Tabellenformatierungen, Breiteneigenschaften oder Schriftartspezifikationen fehlschlagen. Der Fehler "Das Dokument hat keine Seiten" tritt häufig auf, wenn diese Elemente nicht unterstützt werden. Hyperlinks und Media-Query-Referenzen werden möglicherweise ebenfalls nicht korrekt dargestellt. Diese Einschränkungen werden kritisch, wenn fortgeschrittene PDF-Funktionen wie digitale Signaturen oder Seitenzahlen in Geschäftsanwendungen implementiert werden.
Laut der Dokumentation des Mozilla Developer Network zu CSS umfasst modernes CSS Hunderte von Eigenschaften und Werten, die von Browsern nativ unterstützt werden. XMLWorker deckt nur einen kleinen Teil davon ab, weshalb reale Webinhalte immer wieder zu Parsing-Fehlern führen.
Wie kann man HTML-zu-PDF-Konvertierungen ohne Parsing-Fehler durchführen?
IronPDF verwendet eine auf Chrome basierende Rendering-Engine, die HTML genau so verarbeitet, wie es in einem Webbrowser angezeigt wird. Dieser Ansatz beseitigt Parsing-Fehler und unterstützt alle modernen HTML- und CSS-Funktionen. Die vollständige Liste der Konfigurationsoptionen finden Sie in der ChromePdfRenderer-API-Referenz . Die Chrome-Engine bietet Unterstützung für die Ausführung von JavaScript , Webfonts und responsive Layouts, die XMLWorker nicht verarbeiten kann.
Wie installiert man IronPDF über NuGet?
Bevor Sie mit dem Schreiben von Code beginnen, installieren Sie das IronPDF NuGet Paket. Dies können Sie über die .NET Befehlszeilenschnittstelle (CLI) tun:
dotnet add package IronPdfdotnet add package IronPdfOder über die NuGet Paket-Manager-Konsole in Visual Studio:
Install-Package IronPdfInstall-Package IronPdfNach der Installation haben Sie Zugriff auf ChromePdfRenderer, wodurch die gesamte iTextSharp + XMLWorker-Pipeline durch einen einzigen, zuverlässigen Aufruf ersetzt wird.
Wie rendert man HTML in PDF mit IronPDF?
Das folgende Beispiel rendert denselben HTML-Rechnungscode, der in iTextSharp zu Fehlern geführt hat. Beachten Sie, dass es keine Workarounds, keine einzufügenden leeren Absätze und keine stillen Fehler gibt, die behandelt werden müssen:
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")Wie sieht die IronPDF Ausgabe aus?
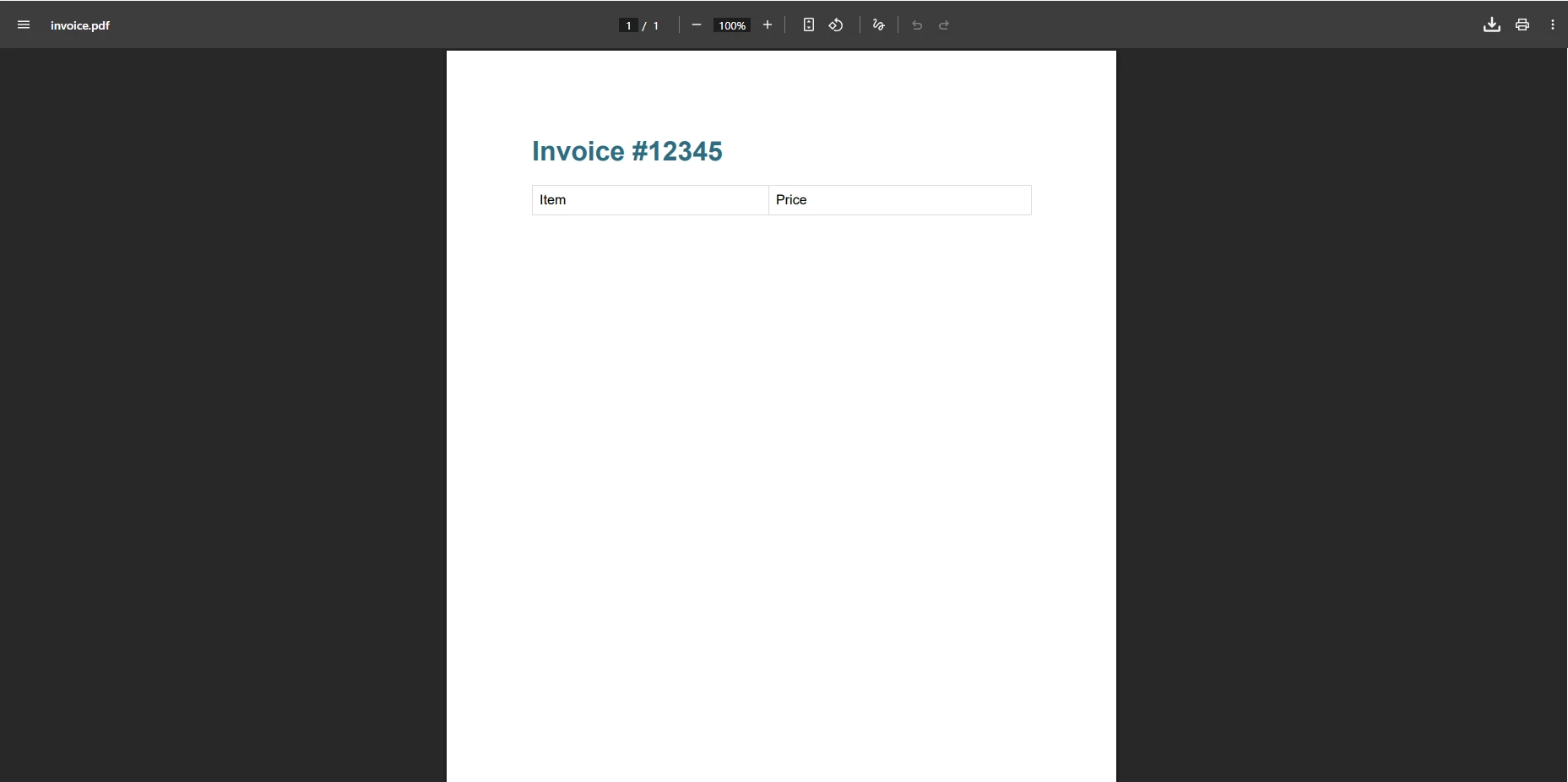
Warum beseitigt dieser Ansatz Parsing-Fehler?
Mit diesem Code wird die PDF-Datei ausnahmslos erfolgreich erstellt. Die Methode verarbeitet komplexe HTML- und CSS-Inhalte automatisch, so dass keine Umgehungslösungen erforderlich sind. Der Inhalt wird pixelgenau wiedergegeben und entspricht der Browser-Vorschau. IronPDF unterstützt außerdem asynchrones Rendering , benutzerdefinierte Ränder und PDF-Komprimierung für optimierte Dateigrößen.
Für Szenarien mit vielen JavaScript-Inhalten oder Single-Page-Anwendungen ermöglicht die Option RenderDelay von IronPDF die Ausführung des JavaScript vor der PDF-Erfassung – etwas, was XMLWorker überhaupt nicht kann. Das folgende Beispiel fügt Kopf- und Fußzeilen sowie Sicherheitseinstellungen in einem produktionsreifen, asynchronen Muster hinzu:
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End ClassWas ist die beste Lösung für eine zuverlässige PDF-Erstellung?
Beim Vergleich der beiden Bibliotheken zur HTML-zu-PDF-Konvertierung wirken sich die Unterschiede im Funktionsumfang direkt auf die PDF-Qualität und die Zuverlässigkeit der Bereitstellung aus:
| Merkmal | iTextSharp + XMLWorker | IronPDF |
|---|---|---|
| Unterstützung für modernes HTML/CSS | Eingeschränkt (HTML 4, CSS 2) | Vollständig (Chrome-Rendering-Engine) |
| JavaScript-Ausführung | Nein | Ja |
| Fehlerbehandlung | Häufige Parse-Ausnahmen | Zuverlässige Darstellung |
| Komplexe Tabellen | Oftmals scheitert | Volle Unterstützung |
| Benutzerdefinierte Schriftarten | Manuelle Einbettung erforderlich | Automatische Handhabung |
| SVG-Unterstützung | Nein | Ja |
| Asynchrones Rendering | Nein | Ja |
| Docker/Linux-Unterstützung | Begrenzt | Vollständige native Unterstützung |
| CSS Medientypen | Basic | Bildschirm und Druck |
| Debugging-Tools | Begrenzt | Chrome DevTools-Integration |
Wie migriert man von iTextSharp zu IronPDF?
Für Entwickler, die mit dem Fehler "Dokument hat keine Seiten" konfrontiert sind, bietet die Migration zu IronPDF eine sofortige Lösung. Der Konvertierungsprozess ist unkompliziert, und IronPDF bietet eine vollständige Dokumentation sowie Codebeispiele . Der folgende Vorher-Nachher-Vergleich verdeutlicht die Reduzierung der Komplexität:
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassWas macht die IronPDF-API entwicklerfreundlicher?
Die vereinfachte API bedeutet, dass weniger Code gewartet werden muss und keine Parsing-Fehler zu beheben sind. IronPDF bietet außerdem Funktionen zum Hinzufügen von Kopf- und Fußzeilen , zum Zusammenführen von PDFs und zum Anwenden digitaler Signaturen ohne aufwendige Umwege. Für Teams, die in Docker-Umgebungen arbeiten oder auf Linux-Servern bereitstellen, bietet IronPDF ein einheitliches Verhalten über alle Plattformen hinweg.
Starten Sie Ihre kostenlose Testphase und erleben Sie eine fehlerfreie HTML-zu-PDF-Konvertierung .
Was sind Ihre nächsten Schritte?
Der Fehler "Das Dokument hat keine Seiten" rührt von grundlegenden Parsing-Beschränkungen her, die in iTextSharps XMLWorker eingebaut sind. Es gibt zwar Umgehungsmöglichkeiten – wie zum Beispiel das Vorbefüllen des Dokuments mit einem leeren Absatz –, diese lösen aber nicht das zugrundeliegende Problem der komplexen HTML-Verarbeitung. IronPDFs Chrome-basiertes Rendering bietet eine zuverlässige Lösung, die moderne Webinhalte ohne Parsing-Ausnahmen verarbeitet.
Für Produktionsanwendungen, die eine konsistente PDF-Erzeugung aus HTML erfordern, beseitigt IronPDF die Frustration bei der Fehlersuche im Parser und liefert professionelle Ergebnisse. Die Engine verarbeitet alle HTML-Elemente, CSS-Stile und JavaScript und gewährleistet so die korrekte Darstellung Ihrer Dokumente. Ob Rechnungen , Berichte oder beliebige Dokumente mit Text, Tabellen und Bildern – IronPDF bietet die passende Lösung.
Um voranzukommen, werden folgende nächste Schritte empfohlen:
- Installieren Sie IronPDF über NuGet (
dotnet add package IronPdf) und führen Sie die Schnellstartanleitung aus - Im HTML-zu-PDF-Tutorial finden Sie eine vollständige Übersicht der Rendering-Optionen.
- In der ChromePdfRenderer-API-Referenz finden Sie Informationen zur Konfiguration von Rändern, Kopfzeilen, JavaScript Wartezeiten und Sicherheitseinstellungen.
- Im Vergleich von iTextSharp und IronPDF finden Sie eine detaillierte Aufschlüsselung der Bibliotheksunterschiede.
- Lesen Sie die Leitfäden zur Fehlerbehebung , um die Ausgabe bei hohem Arbeitsaufkommen zu optimieren.
- Informationen zu Cloud-Bereitstellungen finden Sie in den Einrichtungsanleitungen für Azure und Docker.
Häufig gestellte Fragen
Was verursacht den iTextSharp HTML zu PDF 'das Dokument hat keine Seiten' Fehler?
Der Fehler "Das Dokument hat keine Seiten" in iTextSharp tritt auf, wenn der Parsing-Prozess während der Konvertierung von HTML in PDF fehlschlägt, oft aufgrund von Problemen mit dem HTML-Inhalt oder nicht unterstützten Funktionen.
Gibt es eine Alternative zu iTextSharp für die Konvertierung von HTML in PDF?
Ja, IronPDF bietet eine zuverlässige Lösung für die Konvertierung von HTML in PDF in .NET-Anwendungen und überwindet viele Einschränkungen von iTextSharp.
Wie geht IronPDF mit der Konvertierung von HTML in PDF anders um als iTextSharp?
IronPDF bietet umfassendere Parsing-Fähigkeiten und unterstützt eine breitere Palette von HTML- und CSS-Funktionen, wodurch die Wahrscheinlichkeit von Konvertierungsfehlern wie dem 'keine Seiten'-Fehler verringert wird.
Kann IronPDF komplexe HTML-Dokumente in PDF konvertieren?
IronPDF wurde entwickelt, um komplexe HTML-Dokumente zu verarbeiten, einschließlich solcher mit fortgeschrittenen CSS-, JavaScript- und Multimedia-Elementen, und um eine genaue PDF-Ausgabe zu gewährleisten.
Warum sollten Entwickler IronPDF gegenüber iTextSharp bevorzugen?
Entwickler könnten IronPDF gegenüber iTextSharp bevorzugen aufgrund seiner Benutzerfreundlichkeit, vollständigen Unterstützung von HTML und CSS und seiner Fähigkeit, hochwertige PDFs ohne häufige Fehler zu erzeugen.
Unterstützt IronPDF JavaScript und CSS während des PDF-Konvertierungsprozesses?
IronPDF unterstützt JavaScript, CSS und modernes HTML5 und stellt damit sicher, dass die visuelle Integrität des Original-HTML in der PDF-Ausgabe erhalten bleibt.
Wie kann ich mit IronPDF für die Konvertierung von HTML in PDF beginnen?
Um mit IronPDF zu beginnen, können Sie die detaillierten Tutorien und die Dokumentation auf der IronPDF-Website nutzen, die Schritt-für-Schritt-Anleitungen für die Implementierung bereitstellen.
Was sind die Vorteile der Verwendung von IronPDF for .NET-Entwickler?
IronPDF bietet .NET-Entwicklern ein flexibles Tool zur PDF-Generierung, mit Vorteilen wie Unterstützung für komplexen HTML-Inhalt, einfacher Integration und zuverlässiger Leistung.
Bietet IronPDF Unterstützung bei der Behebung von Fehlern bei der PDF-Konvertierung?
Ja, IronPDF bietet umfangreiche Support-Ressourcen, einschließlich Dokumentation und ein Support-Team, das bei der Fehlersuche und -behebung bei Problemen mit der PDF-Konvertierung hilft.
Gibt es eine Möglichkeit, die Fähigkeiten von IronPDF vor dem Kauf zu testen?
IronPDF bietet eine kostenlose Testversion an, die es Entwicklern ermöglicht, die Funktionen zu testen und die Leistung zu bewerten, bevor sie eine Kaufentscheidung treffen.













