
Como gerar PDFs em ASP.NET MVC: IronPDF ou iTextSharp?
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
O erro "documento não tem páginas" do iText ocorre quando o XMLWorker falha em analisar conteúdo HTML, mas o renderizador baseado no Chrome do IronPDF elimina esse problema ao processar HTML exatamente como os navegadores fazem, fornecendo geração confiável de PDF sem exceções de análise.
Converter HTML em PDF é um requisito comum em aplicativos .NET, mas os desenvolvedores que usam iText frequentemente encontram o erro "documento não tem páginas". Esse erro ocorre quando o processo de geração do documento PDF falha, deixando os desenvolvedores em busca de soluções. Esta análise explora por que isso acontece e como resolver o problema de forma eficaz com os recursos de conversão de HTML para PDF do IronPDF .
O que causa o erro "O documento não tem páginas"?
A exceção "documento não tem páginas" ocorre quando o analisador do iText falha em processar o conteúdo HTML em um documento PDF válido. Esse erro normalmente ocorre durante a operação de fechamento do documento, conforme detalhado em várias discussões no Stack Overflow sobre esse problema . Compreender a causa raiz ajuda os desenvolvedores a escolher a biblioteca de PDF adequada às suas necessidades .
O erro surge porque o XMLWorker -- componente de análise de HTML do iText -- falha silenciosamente quando encontra estruturas HTML que não pode processar. Em vez de gerar uma exceção durante a análise sintática, produz um documento vazio. Quando o documento é fechado, o iText detecta que nenhum conteúdo foi escrito e lança a exceção "documento não tem páginas". Esse modo de falha silenciosa torna a depuração particularmente frustrante, já que o rastreamento da pilha aponta para a operação de fechamento em vez da falha de análise sintática propriamente dita.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End ModuleO que é exibido no console quando esse erro ocorre?

Este código tenta criar um arquivo PDF a partir de HTML, mas encontra uma exceção porque o XMLWorker não conseguiu analisar o conteúdo HTML corretamente. A operação de gravação é concluída, mas nenhum conteúdo é adicionado ao documento, resultando em um arquivo vazio. Essa falha de análise é um dos problemas mais comuns que os desenvolvedores enfrentam ao trabalhar com a conversão de HTML para PDF em aplicativos ASP.NET . O problema se torna mais complexo ao lidar com estilos CSS personalizados ou conteúdo renderizado por JavaScript.
Por que a biblioteca substituta enfrenta o mesmo problema?
Embora o XMLWorker tenha substituído o HTMLWorker, que foi descontinuado, ele ainda enfrenta o mesmo problema com certas estruturas HTML. O problema persiste porque o XMLWorker tem requisitos de análise rigorosos, conforme documentado nos fóruns oficiais do iText . Essa limitação afeta desenvolvedores que tentam implementar a conversão de HTML para PDF com precisão de pixels ou que trabalham com layouts CSS responsivos em aplicações web modernas.
A solução alternativa mais comum é preencher previamente o documento com um parágrafo vazio antes de analisar o HTML. Isso evita a exceção "nenhuma página" garantindo que exista pelo menos um elemento de conteúdo quando o documento for fechado:
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End SubComo fica o arquivo PDF gerado com essa solução alternativa?
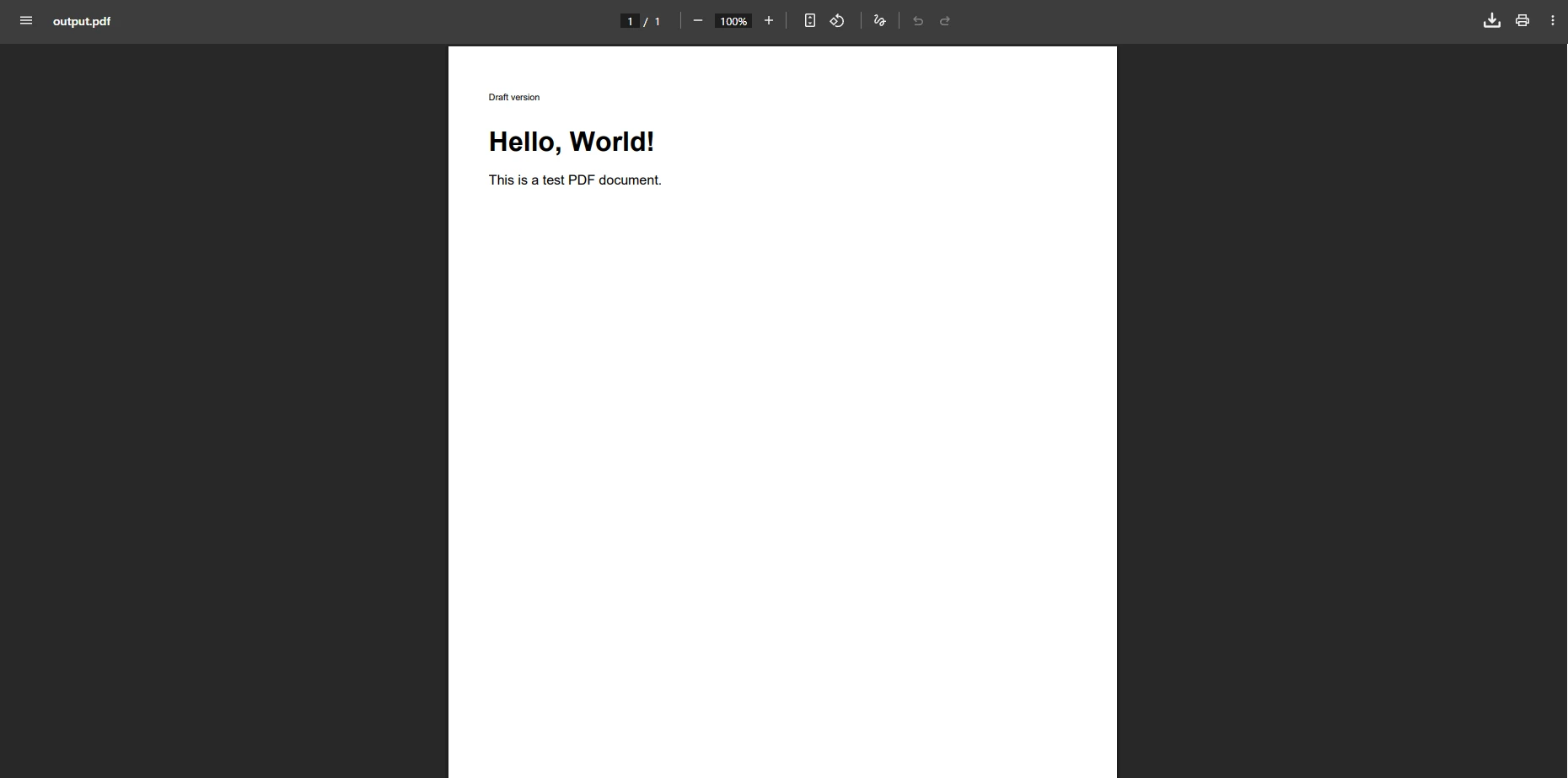
Por que elementos HTML complexos ainda não são renderizados corretamente?
Adicionar um parágrafo vazio evita o erro imediato, mas HTML complexo com elementos de tabela, imagens ou fontes personalizadas geralmente não é renderizado corretamente. O conteúdo pode estar ausente ou malformado no documento PDF resultante. Os desenvolvedores encontram o mesmo problema ao processar HTML com estilos incorporados, elementos de hiperlink ou propriedades de largura específicas. Referências nulas e a falta de renderização de elementos criam problemas adicionais que exigem soluções mais aprofundadas.
O XMLWorker foi projetado para lidar com um subconjunto de HTML 4 e CSS básico 2. Páginas da web modernas rotineiramente usam recursos bem além desse escopo: CSS Grid, Flexbox, variáveis CSS, expressões calc(), gráficos SVG e renderização movida por JavaScript. Qualquer um desses fatores pode desencadear o erro "nenhuma página" ou produzir resultados corrompidos silenciosamente, sem nenhuma mensagem de erro descritiva para orientar a correção.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Fontes personalizadas -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Fontes personalizadas -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}' Common XMLWorker limitations that require manual handling
Public Sub ProcessComplexHTML(ByVal htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Fontes personalizadas -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End SubComo converter HTML moderno sem cometer o mesmo erro?
Este cenário real demonstra a conversão de uma fatura formatada de HTML para PDF. O exemplo inclui elementos comuns que frequentemente causam problemas: CSS embutido, consultas de mídia, layouts de tabela e hiperlinks. Esses são os tipos de estruturas que acionam o erro "nenhuma página" no XMLWorker:
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>O que acontece quando o iText processa esta fatura?
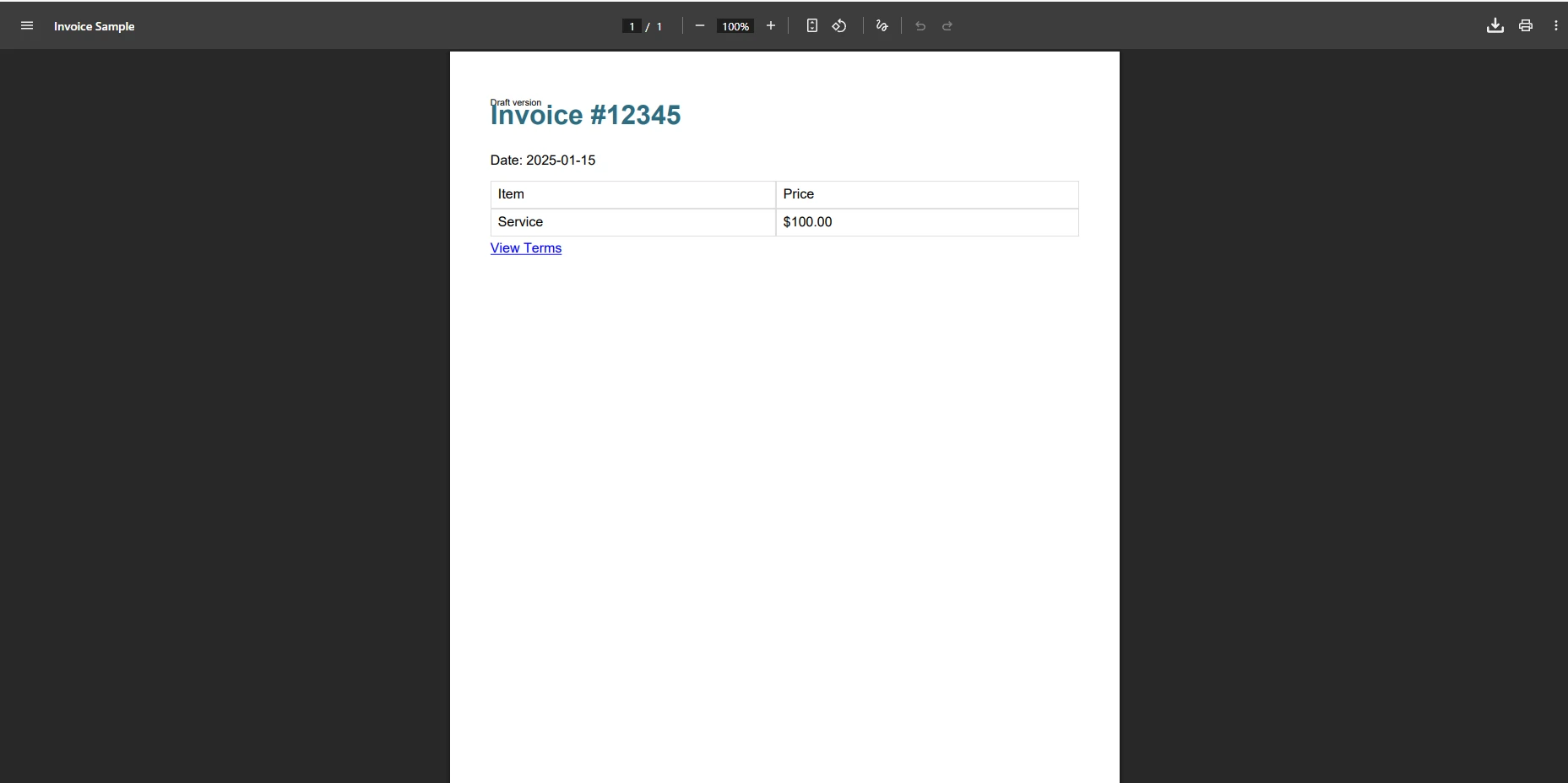
Quando o iText processa este modelo de fatura, a saída é frequentemente despojada de estilização CSS, faltando cores de fundo e perdendo bordas de tabela. A consulta @media print é ignorada, e qualquer referência a fontes da web causa falhas de análise silenciosas. Se o HTML contiver uma propriedade CSS que o XMLWorker não reconheça, todo o bloco poderá não ser renderizado, resultando em conteúdo ausente sem que nenhum erro seja exibido durante a análise.
Como o IronPDF renderiza a mesma fatura?
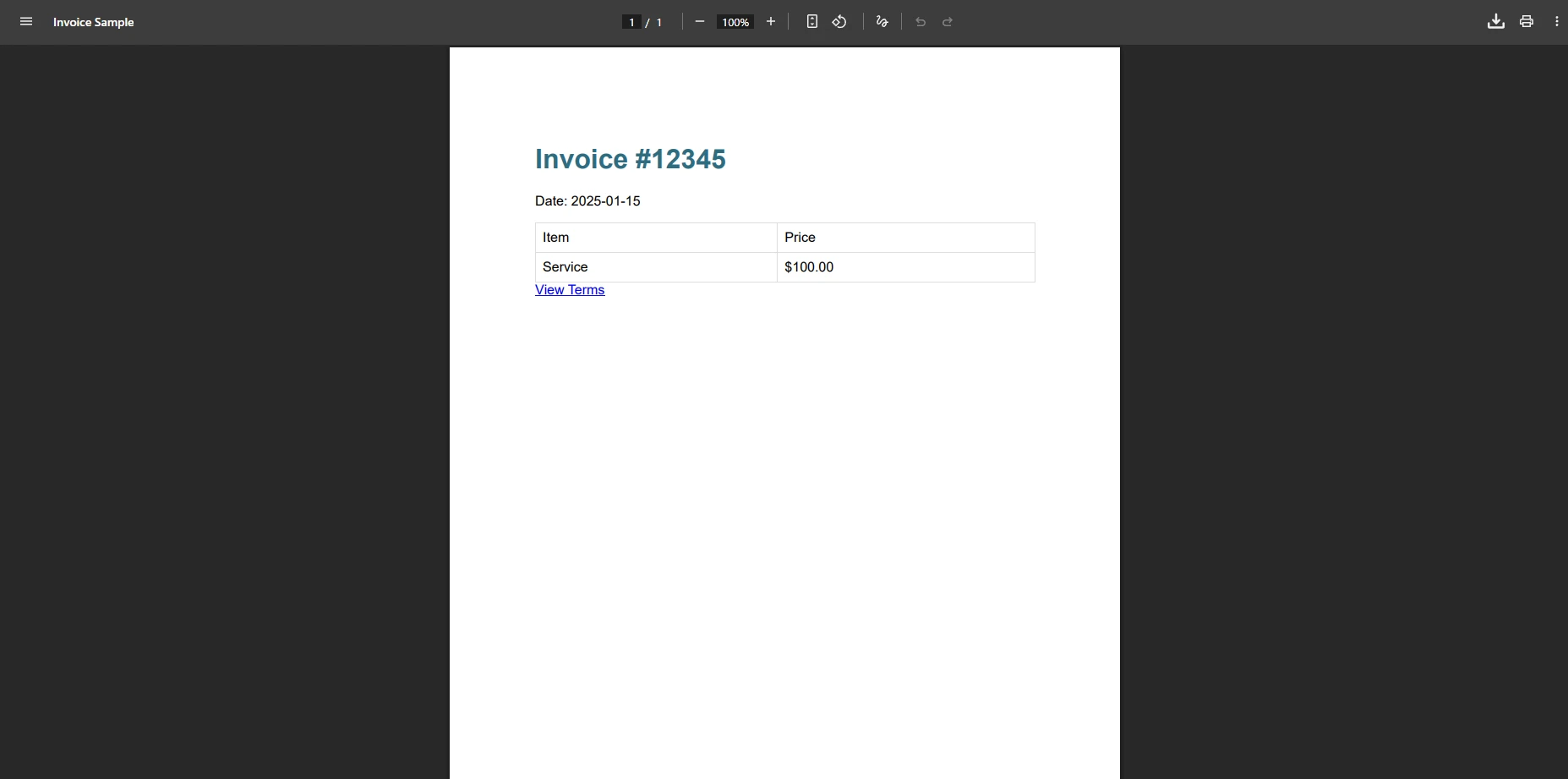
Por que esses elementos HTML causam problemas no iText?
Com o XMLWorker do iText, esta fatura pode falhar devido à estilização de tabelas, propriedades de largura ou especificações de fontes. O erro "o documento não possui páginas" geralmente ocorre quando esses elementos não são suportados. Hiperlinks e referências de media queries também podem não ser renderizados corretamente. Essas limitações tornam-se críticas ao implementar recursos avançados de PDF, como assinaturas digitais ou números de página, em aplicações comerciais.
De acordo com a documentação da Mozilla Developer Network sobre CSS , o CSS moderno inclui centenas de propriedades e valores que os navegadores suportam nativamente. O XMLWorker abrange apenas uma pequena fração desses casos, e é por isso que o conteúdo da web do mundo real causa falhas de análise de forma consistente.
Como lidar com a conversão de HTML para PDF sem erros de análise sintática?
O IronPDF utiliza um mecanismo de renderização baseado no Chrome que processa o HTML exatamente como ele aparece em um navegador da web. Essa abordagem elimina erros de análise sintática e oferece suporte a todos os recursos modernos de HTML e CSS. Você pode consultar a referência da API ChromePdfRenderer para obter a lista completa de opções de configuração. O mecanismo do Chrome oferece suporte à execução de JavaScript , fontes da web e layouts responsivos que o XMLWorker não consegue lidar.
Como instalar o IronPDF via NuGet?
Antes de escrever qualquer código, instale o pacote NuGet IronPDF . Você pode fazer isso a partir da CLI do .NET :
dotnet add package IronPdf
Ou a partir do Console do Gerenciador de Pacotes NuGet no Visual Studio:
Install-Package IronPdf
Uma vez instalado, você tem acesso a ChromePdfRenderer, que substitui todo o pipeline iText + XMLWorker por uma chamada única e confiável.
Como converter HTML para PDF com o IronPDF?
O exemplo a seguir renderiza o mesmo HTML de fatura que causou falhas no iText. Observe que não há soluções alternativas, nem parágrafos vazios para prencher, nem falhas silenciosas a gerenciar:
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")Qual é a aparência da saída do IronPDF ?
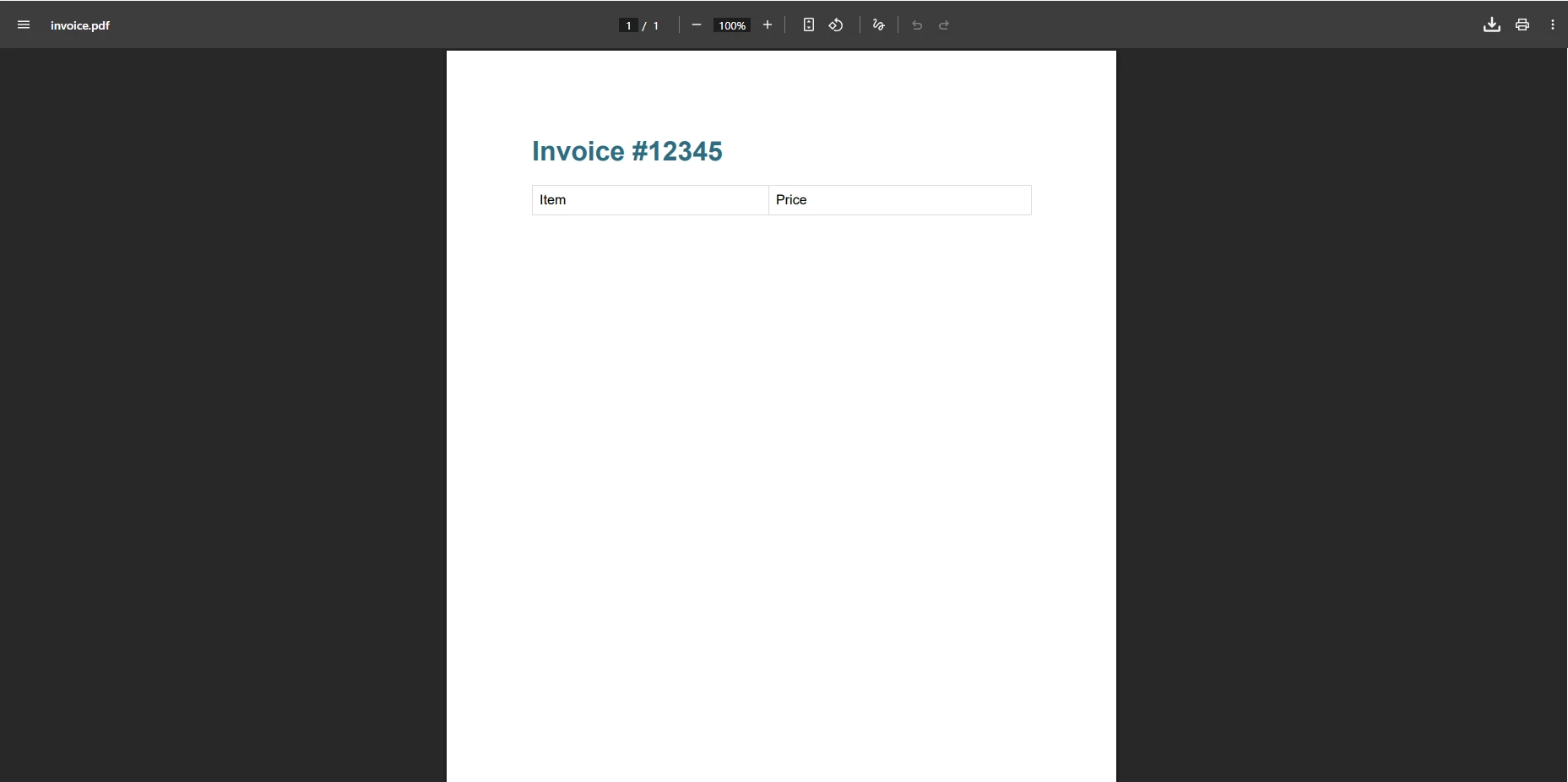
Por que essa abordagem elimina erros de análise sintática?
Este código cria o arquivo PDF com sucesso, sem nenhuma exceção. O método lida automaticamente com HTML e CSS complexos, eliminando a necessidade de soluções alternativas. O conteúdo é renderizado com perfeição de pixels, correspondendo à pré-visualização do navegador. O IronPDF também oferece suporte à renderização assíncrona , margens personalizadas e compressão de PDF para otimizar o tamanho dos arquivos.
Para cenários que envolvem conteúdo pesado em JavaScript ou aplicativos de página única, a opção RenderDelay do IronPDF permite que o JavaScript seja executado antes que o PDF seja gerado -- algo que o XMLWorker não pode fazer de forma alguma. O exemplo a seguir adiciona cabeçalhos, rodapés e configurações de segurança em um padrão assíncrono pronto para produção:
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End ClassQual é a melhor solução para geração confiável de PDFs?
Ao comparar as duas bibliotecas para conversão de HTML para PDF, as diferenças de capacidade afetam diretamente a qualidade do PDF e a confiabilidade da implementação:
| Recurso | iText + XMLWorker | IronPDF |
|---|---|---|
| Suporte moderno a HTML/CSS | Limitado (HTML 4, CSS 2) | Completo (mecanismo de renderização do Chrome) |
| Execução de JavaScript | Não | Sim |
| Tratamento de erros | Exceções de análise sintática comuns | Renderização confiável |
| Tabelas complexas | Frequentemente falha | Apoio total |
| Fontes personalizadas | Incorporação manual necessária | manuseio automático |
| Suporte a SVG | Não | Sim |
| Renderização assíncrona | Não | Sim |
| Suporte a Docker/Linux | Limitado | Suporte nativo completo |
| tipos de mídia CSS | Básico | Serigrafia e Impressão |
| Ferramentas de depuração | Limitado | Integração do Chrome DevTools |
Como migrar do iText para o IronPDF?
Para desenvolvedores que enfrentam o erro "documento não possui páginas", a migração para o IronPDF oferece uma solução imediata. O processo de conversão é direto, e o IronPDF oferece documentação completa e exemplos de código. A comparação a seguir, de antes e depois, mostra a redução na complexidade:
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End ClassO que torna a API do IronPDF mais amigável para desenvolvedores?
A API simplificada significa menos código para manter e nenhum erro de análise para depurar. O IronPDF também oferece recursos para adicionar cabeçalhos e rodapés , mesclar PDFs e aplicar assinaturas digitais sem soluções alternativas complexas. Para equipes que trabalham em ambientes Docker ou que fazem implantações em servidores Linux, o IronPDF oferece comportamento consistente em todas as plataformas.
Inicie seu teste gratuito para experimentar a conversão de HTML para PDF sem erros.
Quais são os seus próximos passos?
O erro "documento não tem páginas" decorre de limitações fundamentais de análise embutidas no XMLWorker do iText. Embora existam soluções alternativas — como preencher previamente o documento com um parágrafo vazio — elas não resolvem o problema subjacente do processamento complexo de HTML. A renderização do IronPDF baseada no Chrome oferece uma solução confiável que lida com conteúdo da web moderno sem exceções de análise sintática.
Para aplicações de produção que exigem a geração consistente de PDFs a partir de HTML, o IronPDF elimina a frustração de depurar erros de análise sintática e oferece resultados profissionais. O mecanismo processa todos os elementos HTML, estilos CSS e JavaScript, garantindo que os documentos sejam renderizados corretamente sempre. Seja para criar faturas , relatórios ou qualquer documento com texto, tabelas e imagens, o IronPDF oferece a solução ideal.
Para prosseguir, seguem os próximos passos recomendados:
- Instale o IronPDF via NuGet (
dotnet add package IronPdf) e execute o guia de início rápido Consulte o tutorial de HTML para PDF para obter um passo a passo completo das opções de renderização. - Consulte a referência da API ChromePdfRenderer para configurar margens, cabeçalhos, tempos de espera do JavaScript e configurações de segurança.
- Verifique a comparação entre iText e IronPDF para uma análise detalhada das diferenças entre bibliotecas
- Consulte os guias de solução de problemas para otimizar a saída em cargas de trabalho de alto volume.
- Para implantações em nuvem, consulte os guias de configuração do Azure e do Docker.
Perguntas frequentes
O que causa o erro "o documento não tem páginas" ao converter iTextSharp de HTML para PDF?
O erro "o documento não possui páginas" no iTextSharp ocorre quando o processo de análise falha durante a conversão de HTML para PDF, geralmente devido a problemas com o conteúdo HTML ou recursos não suportados.
Existe alguma alternativa ao iTextSharp para conversão de HTML em PDF?
Sim, o IronPDF oferece uma solução confiável para conversão de HTML para PDF em aplicações .NET, superando muitas limitações encontradas no iTextSharp.
Como o IronPDF lida com a conversão de HTML para PDF de forma diferente do iTextSharp?
IronPDF fornece capacidades de análise mais completas e suporta uma gama mais ampla de recursos HTML e CSS, reduzindo a probabilidade de erros de conversão, como o erro 'sem páginas'.
O IronPDF consegue converter documentos HTML complexos em PDF?
O IronPDF foi projetado para lidar com documentos HTML complexos, incluindo aqueles com CSS avançado, JavaScript e elementos multimídia, garantindo uma saída de PDF precisa.
Por que os desenvolvedores deveriam considerar o uso do IronPDF em vez do iTextSharp?
Desenvolvedores podem preferir IronPDF ao invés de iTextSharp devido à sua facilidade de uso, suporte total a HTML e CSS e à sua capacidade de produzir PDFs de alta qualidade sem erros comuns.
O IronPDF oferece suporte a JavaScript e CSS durante o processo de conversão de PDF?
Sim, o IronPDF oferece suporte completo a JavaScript, CSS e HTML5 moderno, garantindo que a integridade visual do HTML original seja mantida na saída em PDF.
Como posso começar a usar o IronPDF para conversão de HTML para PDF?
Para começar a usar o IronPDF, você pode explorar os tutoriais detalhados e a documentação disponíveis no site deles, que fornecem guias passo a passo para a implementação.
Quais são os benefícios de usar o IronPDF para desenvolvedores .NET?
IronPDF oferece aos desenvolvedores .NET uma ferramenta flexível para geração de PDF, com vantagens como suporte para conteúdo HTML complexo, facilidade de integração e desempenho confiável.
O IronPDF oferece algum suporte para solucionar erros de conversão de PDF?
Sim, a IronPDF oferece amplos recursos de suporte, incluindo documentação e uma equipe de suporte, para ajudar a solucionar quaisquer problemas encontrados durante a conversão de PDF.
Existe alguma forma de testar as funcionalidades do IronPDF antes de comprá-lo?
O IronPDF oferece uma versão de avaliação gratuita que permite aos desenvolvedores testar seus recursos e avaliar seu desempenho antes de tomar uma decisão de compra.












