
Error iTextSharp "sin páginas" en facturas VeriFactu: AGPL vs IronPDF para ISVs en España
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
El error "el documento no tiene páginas" de iTextSharp ocurre cuando XMLWorker no puede analizar el contenido HTML, pero el renderizador basado en Chrome de IronPDF elimina este problema al procesar el HTML exactamente como lo hacen los navegadores, lo que proporciona una generación de PDF confiable sin excepciones de análisis.
La conversión de HTML a PDF es un requisito común en las aplicaciones .NET , pero los desarrolladores que utilizan iTextSharp con frecuencia encuentran el error "el documento no tiene páginas". Este error aparece cuando falla el proceso de generación de documentos PDF, lo que obliga a los desarrolladores a buscar soluciones. Este análisis explora por qué sucede esto y cómo resolverlo de manera efectiva con las capacidades de HTML a PDF de IronPDF .
Para ISVs españoles de software de facturación: más allá del problema técnico del "documento sin páginas", el uso de iTextSharp bajo licencia AGPL en aplicaciones de facturación en España introduce una triple capa de riesgo: (1) obligación copyleft AGPL — el código fuente del ISV debe publicarse si se distribuye junto con iTextSharp AGPL, comprometiendo la propiedad intelectual del software de facturación propietario; (2) sanciones VeriFactu (AEAT) de hasta 150.000 €/año si el software de facturación distribuido no cumple los requisitos técnicos del Real Decreto-ley 15/2025, incluida la marca VERI*FACTU en las representaciones PDF — con la URL de verificación AEAT y el hash SHA-256 del registro de alta en cada factura; (3) certificaciones TicketBAI fragmentadas — Bizkaia, Gipuzkoa y Araba exigen certificaciones independientes por diputación foral, multiplicando el coste de cumplimiento. IronPDF, con licencia comercial perpetua, elimina el vector AGPL de esta triple exposición y cumple con el procesamiento local que exigen la LOPDGDD y la AEPD para documentos con datos personales de contribuyentes.
¿Qué causa el error "El documento no tiene páginas"?
La excepción "el documento no tiene páginas" se produce cuando el analizador sintáctico de iTextSharp no puede procesar el contenido HTML en un documento PDF válido. Este error generalmente aparece durante la operación de cierre del documento, como se detalla en muchos hilos de Stack Overflow sobre este problema . Comprender la causa raíz ayuda a los desarrolladores a elegir la biblioteca PDF adecuada para sus necesidades .
El error surge porque XMLWorker (el componente de análisis HTML de iTextSharp) falla silenciosamente cuando encuentra estructuras HTML que no puede procesar. En lugar de generar una excepción durante el análisis, produce un documento vacío. Cuando se cierra el documento, iTextSharp detecta que no se escribió ningún contenido y genera la excepción "el documento no tiene páginas". Este modo de falla silenciosa hace que la depuración sea particularmente frustrante, ya que el seguimiento de la pila apunta a la operación de cierre en lugar de a la falla de análisis real.
static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}static void Main(string[] args)
{
Document pdfDoc = new Document(PageSize.A4);
FileStream stream = new FileStream("output.pdf", FileMode.Create);
PdfWriter writer = PdfWriter.GetInstance(pdfDoc, stream);
pdfDoc.Open();
// HTML parsing fails silently -- no exception here
var sr = new StringReader("<div>Complex HTML</div>");
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr);
pdfDoc.Close(); // Exception: The document has no pages
Console.WriteLine("Error: Document has no pages");
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Module Program
Sub Main(args As String())
Dim pdfDoc As New Document(PageSize.A4)
Dim stream As New FileStream("output.pdf", FileMode.Create)
Dim writer As PdfWriter = PdfWriter.GetInstance(pdfDoc, stream)
pdfDoc.Open()
' HTML parsing fails silently -- no exception here
Dim sr As New StringReader("<div>Complex HTML</div>")
XMLWorkerHelper.GetInstance().ParseXHtml(writer, pdfDoc, sr)
pdfDoc.Close() ' Exception: The document has no pages
Console.WriteLine("Error: Document has no pages")
End Sub
End Module¿Qué muestra la salida de la consola cuando ocurre este error?

Este código intenta crear un archivo PDF a partir de HTML, pero encuentra la excepción porque XMLWorker no pudo analizar el contenido HTML correctamente. La operación de escritura se completa, pero no se añade contenido al documento, lo que resulta en un archivo vacío. Este error de análisis es uno de los problemas más comunes que enfrentan los desarrolladores al trabajar con la conversión de HTML a PDF en aplicaciones ASP.NET . La cuestión se vuelve más compleja cuando se trata de estilos CSS personalizados o contenido renderizado en JavaScript.
¿Por qué la biblioteca de reemplazo enfrenta el mismo problema?
Aunque XMLWorker sustituyó al obsoleto HTMLWorker, sigue encontrando el mismo problema con ciertas estructuras HTML. El problema persiste porque XMLWorker tiene requisitos de análisis estrictos, como se documenta en los foros oficiales de iText . Esta limitación afecta a los desarrolladores que intentan implementar la conversión de HTML a PDF con píxeles perfectos o que trabajan con diseños CSS responsivos en aplicaciones web modernas.
La solución alternativa habitual es rellenar previamente el documento con un párrafo vacío antes de analizar el HTML. Esto evita la excepción de "no hay páginas" al garantizar que exista al menos un elemento de contenido cuando se cierra el documento:
public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}public static void CreatePDF(string html, string path)
{
using (var fs = new FileStream(path, FileMode.Create))
{
var document = new Document();
var writer = PdfWriter.GetInstance(document, fs);
document.Open();
document.Add(new Paragraph("")); // Workaround to avoid error
var phrase = new Phrase("Draft version", FontFactory.GetFont("Arial", 8));
document.Add(phrase);
using (var sr = new StringReader(html))
{
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
document.Close();
}
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Shared Sub CreatePDF(html As String, path As String)
Using fs As New FileStream(path, FileMode.Create)
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, fs)
document.Open()
document.Add(New Paragraph("")) ' Workaround to avoid error
Dim phrase As New Phrase("Draft version", FontFactory.GetFont("Arial", 8))
document.Add(phrase)
Using sr As New StringReader(html)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
document.Close()
End Using
End Sub¿Cómo se ve la salida PDF con esta solución alternativa?
¿Por qué los elementos HTML complejos aún no se pueden representar?
Agregar un párrafo vacío evita el error inmediato, pero el HTML complejo con elementos de tabla, imágenes o fuentes personalizadas a menudo no se procesa correctamente. Es posible que el contenido falte o esté mal formado en el documento PDF resultante. Los desarrolladores encuentran el mismo problema al procesar HTML con estilos incrustados, elementos de hipervínculo o propiedades de ancho específicas. Las referencias nulas y la representación de elementos faltantes crean problemas adicionales que requieren una mayor resolución.
XMLWorker fue diseñado para manejar un subconjunto de HTML 4 y CSS 2 básico. Las páginas web modernas usan rutinariamente características mucho más allá de este alcance: CSS Grid, Flexbox, variables CSS, calc() expresiones, gráficos SVG y renderización impulsada por JavaScript. Cualquiera de estos puede provocar el error "no hay páginas" o producir una salida defectuosa de manera silenciosa y sin ningún mensaje de error descriptivo que guíe la solución.
// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Fuentes personalizadas -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}// Common XMLWorker limitations that require manual handling
public void ProcessComplexHTML(string htmlContent)
{
// CSS flexbox -- not supported by XMLWorker
if (htmlContent.Contains("display: flex"))
throw new NotSupportedException("Flexbox layout not supported");
// JavaScript content -- silently ignored
if (htmlContent.Contains("<script>"))
Console.WriteLine("Warning: JavaScript will be ignored");
// Fuentes personalizadas -- require manual embedding
if (htmlContent.Contains("@font-face"))
Console.WriteLine("Warning: Web fonts need manual setup");
}' Common XMLWorker limitations that require manual handling
Public Sub ProcessComplexHTML(htmlContent As String)
' CSS flexbox -- not supported by XMLWorker
If htmlContent.Contains("display: flex") Then
Throw New NotSupportedException("Flexbox layout not supported")
End If
' JavaScript content -- silently ignored
If htmlContent.Contains("<script>") Then
Console.WriteLine("Warning: JavaScript will be ignored")
End If
' Fuentes personalizadas -- require manual embedding
If htmlContent.Contains("@font-face") Then
Console.WriteLine("Warning: Web fonts need manual setup")
End If
End Sub¿Cómo puedes convertir HTML moderno sin el mismo error?
Este escenario del mundo real demuestra cómo convertir una factura con estilo de HTML a PDF. La muestra incluye elementos comunes que a menudo causan problemas: CSS en línea, consultas de medios, diseños de tablas e hipervínculos. Estos son los tipos de estructuras que activan el error "no hay páginas" en XMLWorker:
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Invoice Sample</title>
<style>
.invoice-header {
background-color: #f0f0f0;
padding: 20px;
}
.invoice-table {
margin-top: 20px;
}
@media print {
.no-print { display: none; }
}
</style>
</head>
<body>
<div style="font-family: Arial; width: 100%;">
<div class="invoice-header">
<h1 style="color: #2e6c80;">Invoice #12345</h1>
<p>Date: <span id="date">2025-01-15</span></p>
</div>
<table class="invoice-table" style="width: 100%; border-collapse: collapse;">
<thead>
<tr>
<th style="border: 1px solid #ddd; padding: 8px;">Item</th>
<th style="border: 1px solid #ddd; padding: 8px;">Price</th>
</tr>
</thead>
<tbody>
<tr>
<td style="border: 1px solid #ddd; padding: 8px;">Service</td>
<td style="border: 1px solid #ddd; padding: 8px;">$100.00</td>
</tr>
</tbody>
</table>
<a href="https://example.com/terms" class="no-print">View Terms</a>
</div>
</body>
</html>¿Qué sucede cuando iTextSharp procesa esta factura?
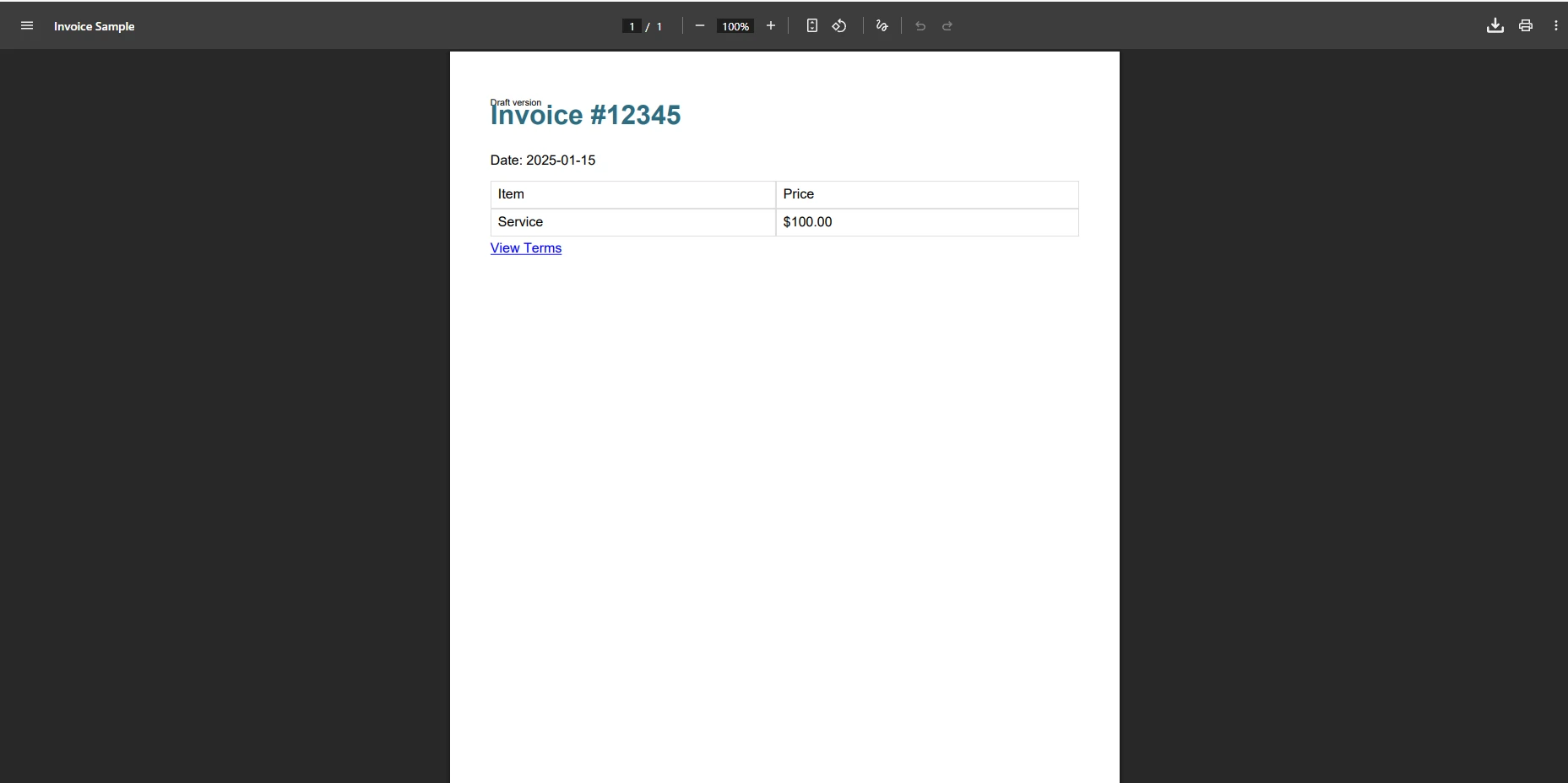
Cuando iTextSharp procesa esta plantilla de factura, la salida a menudo carece de estilo CSS, faltan colores de fondo y se pierden los bordes de las tablas. La consulta @media print se ignora, y cualquier referencia a fuentes web causa fallos silenciosos de análisis. Si el HTML contiene una propiedad CSS que XMLWorker no reconoce, es posible que no se pueda representar todo el bloque, lo que provocará que falte contenido sin que se produzca ningún error en el momento del análisis.
¿Cómo genera IronPDF la misma factura?
¿Por qué estos elementos HTML causan problemas en iTextSharp?
Con XMLWorker de iTextSharp, esta factura podría fallar debido al estilo de la tabla, las propiedades de ancho o las especificaciones de fuente. El error "el documento no tiene páginas" a menudo aparece cuando estos elementos no son compatibles. Es posible que los hipervínculos y las referencias de consultas de medios tampoco se representen correctamente. Estas limitaciones se vuelven críticas al implementar funciones PDF avanzadas como firmas digitales o números de página en aplicaciones comerciales.
Según la documentación de Mozilla Developer Network sobre CSS , el CSS moderno incluye cientos de propiedades y valores que los navegadores admiten de forma nativa. XMLWorker cubre solo una pequeña fracción de estos, por lo que el contenido web del mundo real constantemente genera errores de análisis.
¿Cómo gestionar la conversión de HTML a PDF sin errores de análisis?
IronPDF utiliza un motor de renderizado basado en Chrome que procesa HTML exactamente como aparece en un navegador web. Este enfoque elimina errores de análisis y admite todas las funciones HTML y CSS modernas. Puede explorar la referencia de la API de ChromePdfRenderer para obtener la lista completa de opciones de configuración. El motor Chrome proporciona soporte para la ejecución de JavaScript , fuentes web y diseños responsivos que XMLWorker no puede manejar.
¿Cómo instalar IronPDF a través de NuGet?
Antes de escribir cualquier código, instale el paquete NuGet IronPDF . Puedes hacer esto desde la CLI de .NET :
dotnet add package IronPdfdotnet add package IronPdfO desde la consola del Administrador de paquetes NuGet en Visual Studio:
Install-Package IronPdfInstall-Package IronPdfUna vez instalado, tienes acceso a ChromePdfRenderer, que reemplaza toda la canalización de iTextSharp + Trabajador XML con una sola llamada confiable.
¿Cómo renderizar HTML a PDF con IronPDF?
El siguiente ejemplo muestra el mismo HTML de factura que causó errores en iTextSharp. Observe que no hay soluciones alternativas, ni párrafos vacíos que anteponer, ni errores silenciosos que gestionar:
using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");using IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40;
renderer.RenderingOptions.MarginBottom = 40;
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print;
renderer.RenderingOptions.PrintHtmlBackgrounds = true;
string html = @"<div style='font-family: Arial; width: 100%;'>
<h1 style='color: #2e6c80;'>Invoice #12345</h1>
<table style='width: 100%; border-collapse: collapse;'>
<tr>
<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>
<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>
</tr>
<tr>
<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>
<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>
</tr>
</table>
</div>";
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("invoice.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Configure rendering options for production use
renderer.RenderingOptions.MarginTop = 40
renderer.RenderingOptions.MarginBottom = 40
renderer.RenderingOptions.CssMediaType = PdfCssMediaType.Print
renderer.RenderingOptions.PrintHtmlBackgrounds = True
Dim html As String = "<div style='font-family: Arial; width: 100%;'>" & _
"<h1 style='color: #2e6c80;'>Invoice #12345</h1>" & _
"<table style='width: 100%; border-collapse: collapse;'>" & _
"<tr>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Item</th>" & _
"<th style='border: 1px solid #ddd; padding: 8px;'>Price</th>" & _
"</tr>" & _
"<tr>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>Service</td>" & _
"<td style='border: 1px solid #ddd; padding: 8px;'>$100.00</td>" & _
"</tr>" & _
"</table>" & _
"</div>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("invoice.pdf")¿Cómo se ve la salida de IronPDF ?
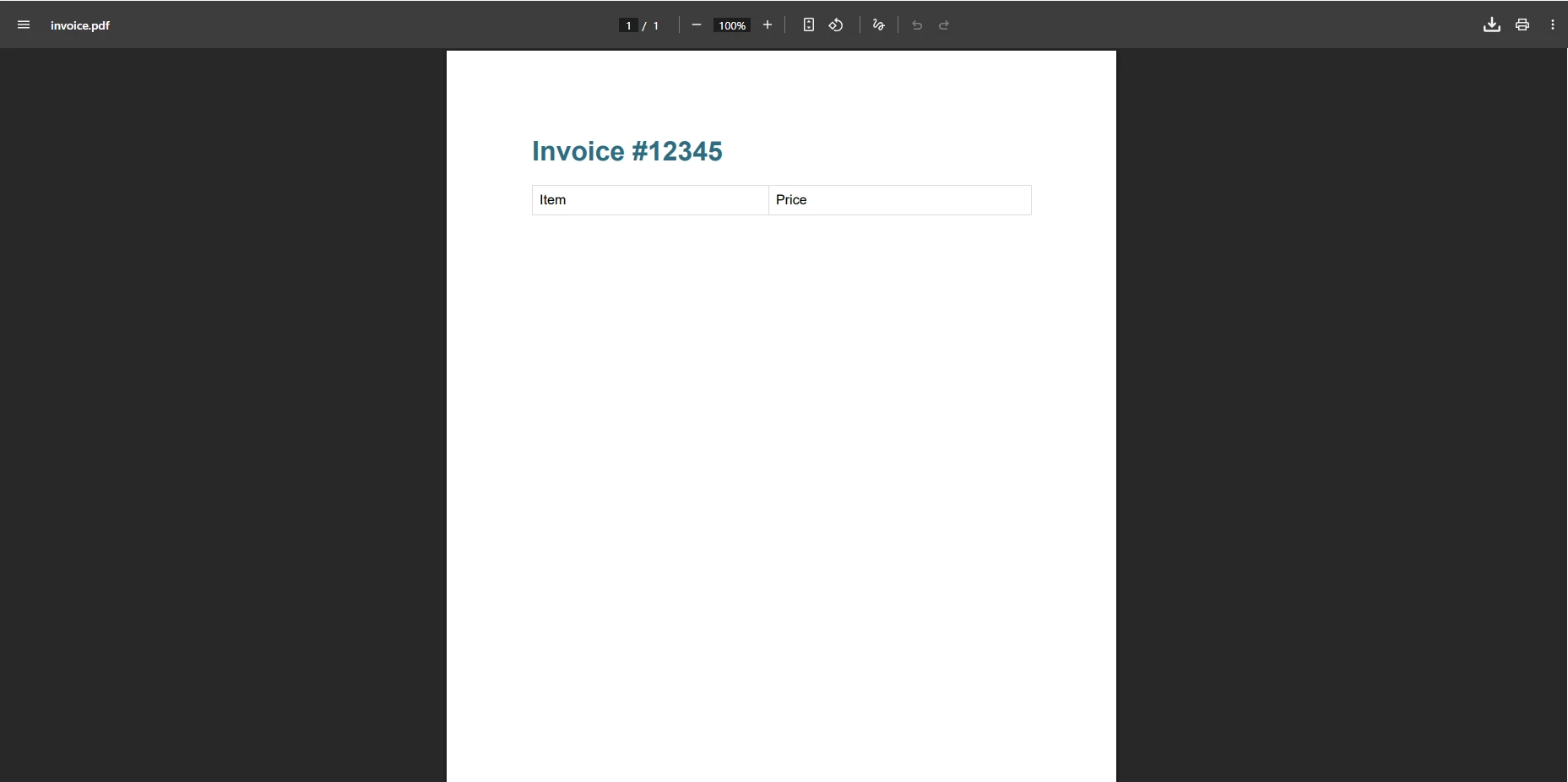
¿Por qué este enfoque elimina los errores de análisis?
Este código crea correctamente el archivo PDF sin ninguna excepción. El método maneja HTML y CSS complejos de forma automática, eliminando la necesidad de recurrir a métodos alternativos. El contenido debe reproducirse perfectamente, como en la vista previa del navegador. IronPDF también admite renderizado asincrónico , márgenes personalizados y compresión de PDF para tamaños de archivos optimizados.
Para escenarios que involucran contenido pesado en JavaScript o aplicaciones de una sola página, la opción RenderDelay de IronPDF permite que el JavaScript se ejecute antes de que se capture el PDF, algo que XMLWorker no puede hacer en absoluto. El siguiente ejemplo agrega encabezados, pies de página y configuraciones de seguridad en un patrón asincrónico listo para producción:
using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}using IronPdf;
using Microsoft.Extensions.Logging;
// Production-ready PDF generation with IronPDF
public class PdfGenerator
{
private readonly ChromePdfRenderer _renderer;
private readonly ILogger<PdfGenerator> _logger;
public PdfGenerator(ILogger<PdfGenerator> logger)
{
_logger = logger;
_renderer = new ChromePdfRenderer();
_renderer.RenderingOptions.Timeout = 60;
_renderer.RenderingOptions.EnableJavaScript = true;
_renderer.RenderingOptions.RenderDelay = 2000;
_renderer.RenderingOptions.HtmlHeader = new HtmlHeaderFooter
{
Height = 25,
HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
};
}
public async Task<PdfDocument> GenerateWithRetry(string html, int maxRetries = 3)
{
for (int i = 0; i < maxRetries; i++)
{
try
{
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1);
return await _renderer.RenderHtmlAsPdfAsync(html);
}
catch (Exception ex)
{
_logger.LogWarning("PDF generation failed: {Message}", ex.Message);
if (i == maxRetries - 1) throw;
await Task.Delay(1000 * (i + 1));
}
}
throw new InvalidOperationException("PDF generation failed after retries");
}
}Imports IronPdf
Imports Microsoft.Extensions.Logging
' Production-ready PDF generation with IronPDF
Public Class PdfGenerator
Private ReadOnly _renderer As ChromePdfRenderer
Private ReadOnly _logger As ILogger(Of PdfGenerator)
Public Sub New(logger As ILogger(Of PdfGenerator))
_logger = logger
_renderer = New ChromePdfRenderer()
_renderer.RenderingOptions.Timeout = 60
_renderer.RenderingOptions.EnableJavaScript = True
_renderer.RenderingOptions.RenderDelay = 2000
_renderer.RenderingOptions.HtmlHeader = New HtmlHeaderFooter With {
.Height = 25,
.HtmlFragment = "<div style='text-align: center;'>{page} of {total-pages}</div>"
}
End Sub
Public Async Function GenerateWithRetry(html As String, Optional maxRetries As Integer = 3) As Task(Of PdfDocument)
For i As Integer = 0 To maxRetries - 1
Try
_logger.LogInformation("Generating PDF, attempt {Attempt}", i + 1)
Return Await _renderer.RenderHtmlAsPdfAsync(html)
Catch ex As Exception
_logger.LogWarning("PDF generation failed: {Message}", ex.Message)
If i = maxRetries - 1 Then Throw
Await Task.Delay(1000 * (i + 1))
End Try
Next
Throw New InvalidOperationException("PDF generation failed after retries")
End Function
End Class¿Cuál es la mejor solución para una generación de PDF confiable?
Al comparar las dos bibliotecas para la conversión de HTML a PDF, las diferencias en capacidad afectan directamente la calidad del PDF y la confiabilidad de la implementación:
| Función | iTextSharp + Trabajador XML | IronPDF |
|---|---|---|
| Compatibilidad con HTML/CSS moderno | Limitado (HTML 4, CSS 2) | Completo (motor de renderizado Chrome) |
| Ejecución de JavaScript | No | Sí |
| Manejo de errores | Excepciones de análisis comunes | Representación confiable |
| Tablas complejas | A menudo falla | Soporte completo |
| Fuentes personalizadas | Se requiere incrustación manual | Manejo automático |
| Compatibilidad con SVG | No | Sí |
| Renderizado asincrónico | No | Sí |
| Compatibilidad con Docker/Linux | Limitado | Soporte nativo completo |
| Tipos de medio CSS | Básico | Pantalla e impresión |
| Herramientas de depuración | Limitado | Integración de Chrome DevTools |
¿Cómo migrar de iTextSharp a IronPDF?
Para los desarrolladores que experimentan el error "el documento no tiene páginas", la migración a IronPDF ofrece una solución inmediata. El proceso de conversión es directo, y IronPDF ofrece completa documentación y ejemplos de código. La siguiente comparación antes y después muestra la reducción de la complejidad:
// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}// Before (iTextSharp) -- error-prone approach requiring workarounds
public byte[] CreatePdfWithIText(string htmlContent)
{
using var ms = new MemoryStream();
var document = new Document();
var writer = PdfWriter.GetInstance(document, ms);
document.Open();
// Must add empty paragraph to avoid "no pages" error
document.Add(new Paragraph(""));
try
{
using var sr = new StringReader(htmlContent);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
catch (Exception ex)
{
document.Add(new Paragraph("Error: " + ex.Message));
}
document.Close();
return ms.ToArray();
}
// After (IronPDF) -- reliable, no workarounds needed
public byte[] CreatePdfWithIron(string htmlContent)
{
ChromePdfRenderer renderer = new ChromePdfRenderer();
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500;
PdfDocument pdf = renderer.RenderHtmlAsPdf(htmlContent);
return pdf.BinaryData;
}Imports System.IO
Imports iTextSharp.text
Imports iTextSharp.text.pdf
Imports iTextSharp.tool.xml
Public Class PdfCreator
' Before (iTextSharp) -- error-prone approach requiring workarounds
Public Function CreatePdfWithIText(htmlContent As String) As Byte()
Using ms As New MemoryStream()
Dim document As New Document()
Dim writer As PdfWriter = PdfWriter.GetInstance(document, ms)
document.Open()
' Must add empty paragraph to avoid "no pages" error
document.Add(New Paragraph(""))
Try
Using sr As New StringReader(htmlContent)
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr)
End Using
Catch ex As Exception
document.Add(New Paragraph("Error: " & ex.Message))
End Try
document.Close()
Return ms.ToArray()
End Using
End Function
' After (IronPDF) -- reliable, no workarounds needed
Public Function CreatePdfWithIron(htmlContent As String) As Byte()
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(htmlContent)
Return pdf.BinaryData
End Function
End Class¿Qué hace que la API de IronPDF sea más amigable para los desarrolladores?
La API simplificada significa menos código que mantener y ningún error de análisis que depurar. IronPDF también ofrece funciones para agregar encabezados y pies de página , fusionar archivos PDF y aplicar firmas digitales sin soluciones alternativas complejas. Para los equipos que trabajan en entornos Docker o que implementan en servidores Linux, IronPDF ofrece un comportamiento consistente en todas las plataformas.
Comience su prueba gratuita para experimentar la conversión de HTML a PDF sin errores.
¿Cuales son tus próximos pasos?
El error "el documento no tiene páginas" se debe a limitaciones de análisis fundamentales integradas en XMLWorker de iTextSharp. Si bien existen soluciones alternativas (como rellenar previamente el documento con un párrafo vacío), no resuelven el problema subyacente con el procesamiento complejo de HTML. La renderización basada en Chrome de IronPDF proporciona una solución confiable que maneja contenido web moderno sin analizar excepciones.
Para las aplicaciones de producción que requieren una generación de PDF coherente a partir de HTML, IronPDF elimina la frustración de depurar los errores del analizador y ofrece resultados profesionales. El motor gestiona todos los elementos HTML, estilos CSS y JavaScript, garantizando que los documentos se visualicen correctamente en todo momento. Ya sea que cree facturas , informes o cualquier documento con texto, tablas e imágenes, IronPDF le ofrece la solución que necesita.
Consideraciones específicas para ISVs en España: si su aplicación genera facturas, recibos o documentos fiscales, el error "documento sin páginas" de XMLWorker puede impedir la emisión conforme de facturas Facturae o documentos con marca VERI*FACTU requerida por la AEAT. La inestabilidad de análisis de iTextSharp es especialmente crítica en contextos donde la generación de PDF de facturas debe ser 100 % fiable para cumplir los plazos de VeriFactu y TicketBAI. IronPDF, con su motor Chrome integrado, elimina los fallos silenciosos de análisis y soporta la generación de PDF/A necesaria para el archivado conforme de facturas electrónicas.
Para seguir adelante, estos son los próximos pasos recomendados:
- Instala IronPDF a través de NuGet (
dotnet add package IronPdf) y ejecuta la guía rápida de inicio - Revise el tutorial de HTML a PDF para obtener una guía completa de las opciones de representación
- Explore la referencia de la API de ChromePdfRenderer para configurar márgenes, encabezados, tiempos de espera de JavaScript y configuraciones de seguridad.
- Consulte la comparación entre iTextSharp y IronPDF para obtener un desglose detallado de las diferencias entre bibliotecas.
- Revise las guías de solución de problemas para optimizar la producción para cargas de trabajo de gran volumen
- Para implementaciones en la nube, consulte las guías de configuración de Azure y Docker
Preguntas Frecuentes
¿Qué causa el error de iTextSharp HTML a PDF 'el documento no tiene páginas'?
El error "el documento no tiene páginas" en iTextSharp se produce cuando falla el proceso de análisis sintáctico durante la conversión de HTML a PDF, a menudo debido a problemas con el contenido HTML o a funciones no compatibles.
¿Existe alguna alternativa a iTextSharp para la conversión de HTML a PDF?
Sí, IronPDF ofrece una solución fiable para la conversión de HTML a PDF en aplicaciones .NET, superando muchas limitaciones encontradas en iTextSharp.
¿En qué se diferencia IronPDF de iTextSharp en la conversión de HTML a PDF?
IronPDF proporciona capacidades de análisis más completas y soporta una gama más amplia de características de HTML y CSS, reduciendo la probabilidad de errores de conversión como el error 'sin páginas'.
¿Puede IronPDF convertir documentos HTML complejos a PDF?
IronPDF está diseñado para manejar documentos HTML complejos, incluidos aquellos con CSS avanzado, JavaScript y elementos multimedia, garantizando un resultado PDF preciso.
¿Por qué los desarrolladores deberían considerar el uso de IronPDF en lugar de iTextSharp?
Los desarrolladores podrían preferir IronPDF sobre iTextSharp debido a su facilidad de uso, soporte completo para HTML y CSS, y su capacidad para producir PDFs de alta calidad sin errores comunes.
¿Es IronPDF compatible con JavaScript y CSS durante el proceso de conversión de PDF?
Sí, IronPDF es totalmente compatible con JavaScript, CSS y HTML5 moderno, lo que garantiza que la integridad visual del HTML original se mantenga en el resultado PDF.
¿Cómo puedo empezar a utilizar IronPDF para la conversión de HTML a PDF?
Para empezar a utilizar IronPDF, puede explorar sus tutoriales detallados y la documentación disponible en su sitio web, que proporciona guías paso a paso para la implementación.
¿Cuáles son los beneficios de usar IronPDF para desarrolladores .NET?
IronPDF ofrece a los desarrolladores .NET una herramienta flexible para la generación de PDF, con ventajas como soporte para contenido HTML complejo, facilidad de integración y rendimiento confiable.
¿Ofrece IronPDF algún tipo de soporte para solucionar errores de conversión de PDF?
Sí, IronPDF proporciona amplios recursos de asistencia, incluida documentación y un equipo de asistencia, para ayudar a solucionar cualquier problema que surja durante la conversión de PDF.
¿Hay alguna forma de probar las capacidades de IronPDF antes de comprarlo?
IronPDF ofrece una versión de prueba gratuita que permite a los desarrolladores probar sus funciones y evaluar su rendimiento antes de tomar una decisión de compra.
¿Por qué el error 'documento sin páginas' de iTextSharp es especialmente crítico para ISVs españoles que generan facturas VeriFactu?
En España, el Real Decreto-ley 15/2025 (VeriFactu) exige que el software de facturación genere PDFs con la marca VERI*FACTU y metadatos de encadenamiento criptográfico. Si XMLWorker de iTextSharp falla silenciosamente al procesar el HTML de la factura, el PDF no se genera correctamente y el software no cumple los requisitos técnicos de la AEAT, lo que puede derivar en sanciones de hasta 150.000 €/año para el ISV distribuidor. Además, iTextSharp bajo AGPL obliga a publicar el código fuente propietario. IronPDF, con motor Chrome y licencia comercial, elimina ambos riesgos.
¿Qué es TicketBAI y cómo afecta a los ISVs que usan iTextSharp en el País Vasco?
TicketBAI es el sistema obligatorio de facturación electrónica del País Vasco, gestionado independientemente por Bizkaia, Gipuzkoa y Araba — cada diputación foral exige su propia certificación. Los ISVs que distribuyen software de facturación en estas provincias deben certificarse tres veces por separado. Si el software usa iTextSharp bajo AGPL y genera PDFs de facturas con errores de análisis, el ISV enfrenta tanto la inestabilidad técnica de XMLWorker como la exposición AGPL. IronPDF, con procesamiento HTML fiable y licencia perpetua comercial, simplifica la certificación TicketBAI al garantizar la generación correcta de PDFs de facturas.













