
Jak porównać dwa pliki PDF w języku C# przy użyciu IronPDF
IronPDF zapewnia programistom C# prosty sposób na programowe porównywanie dokumentów PDF — wyodrębnianie treści tekstowej i analizowanie różnic strona po stronie za pomocą zaledwie kilku wierszy kodu. Ten samouczek przedstawia praktyczne przykłady kodu dotyczące podstawowych porównań, analizy wielu dokumentów, obsługi plików chronionych hasłem oraz generowania sformatowanych raportów porównawczych w .NET 10.
Dlaczego warto porównywać dokumenty PDF programowo?
Ręczne porównywanie dokumentów PDF jest powolne, podatne na błędy i nie nadaje się do skalowania. W branżach opartych na dokumentacji, takich jak branża prawnicza, finansowa i opieki zdrowotnej, pliki ulegają ciągłym zmianom — umowy są aktualizowane, faktury ponownie wystawiane, a dokumenty regulacyjne wymagają weryfikacji wersji. Zautomatyzowane porównanie eliminuje wąskie gardło związane z pracą ludzką i za każdym razem zapewnia spójne, weryfikowalne wyniki.
IronPDF zapewnia gotowe do użycia rozwiązanie do porównywania dwóch plików PDF w języku C#. Biblioteka wykorzystuje silnik renderujący Chrome do dokładnego wyodrębniania tekstu ze złożonych układów, a jej pełny interfejs API udostępnia intuicyjne metody ładowania, odczytu i analizy treści plików PDF. Niezależnie od tego, czy śledzisz zmiany w umowach, weryfikujesz wygenerowane wyniki, czy budujesz system audytu dokumentów, IronPDF zajmie się tym za Ciebie.
Biblioteka ta jest również doskonałym wyborem dla zespołów, które już korzystają z platformy .NET na wielu platformach. Obsługuje systemy Windows, Linux, macOS, Docker, Azure i AWS bez konieczności stosowania różnych ścieżek kodu dla każdego z tych środowisk. Dzięki temu nadaje się do tworzenia narzędzi porównawczych działających w potokach CI/CD, a także w aplikacjach desktopowych.
Kiedy warto skorzystać z automatycznego porównywania plików PDF?
Automatyczne porównywanie staje się niezbędne przy zarządzaniu wersjami w procesach pracy opartych na dużej ilości dokumentów. Ręczna weryfikacja jest niepraktyczna w przypadku przetwarzania setek plików dziennie lub gdy precyzja ma kluczowe znaczenie. Typowe scenariusze obejmują porównywanie faktur w różnych cyklach rozliczeniowych, weryfikację dokumentów regulacyjnych pod kątem zgodności z zatwierdzonymi szablonami, śledzenie zmian w specyfikacjach technicznych w różnych wersjach wydania oraz kontrolę zmian w umowach w ramach procesów prawnych.
Zysk w zakresie dokładności jest znaczący. Człowiek sprawdzający dwa 50-stronicowe dokumenty może przeoczyć jedną zmienioną liczbę w tabeli finansowej. Automatyczne porównanie natychmiast to wykrywa, oznacza stronę i generuje raport różnic bez zmęczenia i niespójności.
Jakie są główne zastosowania?
Porównanie plików PDF znajduje zastosowanie w wielu branżach i procesach roboczych:
- Kancelaria: Śledź zmiany w umowach, sprawdzaj zgodność wersji roboczej z ostateczną oraz upewnij się, że przed podpisaniem wprowadzono wyłącznie zatwierdzone zmiany.
- Finanse: Sprawdzanie wyciągi bankowych, wykrywanie nieautoryzowanych zmian w fakturach oraz potwierdzanie, że wygenerowane raporty są zgodne z oczekiwanymi wynikami.
- Opieka zdrowotna: Sprawdź, czy zgłoszenia regulacyjne są zgodne z zatwierdzoną dokumentacją, oraz upewnij się, że dokumentacja pacjentów nie została zmieniona.
- Zapewnienie jakości: Porównaj pliki PDF wygenerowane przez oprogramowanie z plikami wzorcowymi, aby wykryć regresje renderowania w automatycznych Suite testów.
- Dokumentacja: Sprawdź spójność między zlokalizowanymi wersjami instrukcji obsługi i upewnij się, że tłumaczenie nie zmieniło treści technicznych.
Obsługa wielu platform w IronPDF sprawia, że rozwiązania te można wdrażać w środowiskach Windows, Linux i chmury bez konieczności modyfikacji.
Jak zainstalować IronPDF w projekcie .NET?
Zainstaluj IronPDF za pośrednictwem NuGet, korzystając z konsoli menedżera pakietów lub interfejsu CLI .NET:
Install-Package IronPdf
dotnet add package IronPdfInstall-Package IronPdf
dotnet add package IronPdf
W przypadku wdrożeń w systemie Linux lub środowisków opartych na Dockerze należy zapoznać się z dokumentacją dotyczącą danej platformy. Po zainstalowaniu skonfiguruj klucz licencyjny, jeśli go posiadasz:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Prace związane z tworzeniem i testowaniem działają bez klucza licencyjnego, choć na wygenerowanych plikach PDF pojawiają się znaki wodne. Wdrożenia produkcyjne wymagają ważnej licencji z strony licencyjnej. Bezpłatna wersja próbna zapewnia pełną funkcjonalność na 30 dni bez konieczności podawania danych karty kredytowej.
IronPDF obsługuje .NET Framework 4.6.2+, .NET Core 3.1+ oraz .NET 5 do .NET 10. W przypadku systemu macOS obsługiwane są zarówno procesory Intel, jak i Apple Silicon. Biblioteka automatycznie obsługuje instalację silnika renderującego Chrome, więc nie jest wymagana ręczna konfiguracja przeglądarki.
!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101000101111101010011010101000100000101010010010101000100010101000100010111110101011101001001010100010010000101111101010000010100100100111101000100010101010100001101010100010111110101010001010010010010010100000101001100010111110100001001001100010011110100001101001011--}
Jak przeprowadzić podstawowe porównanie plików PDF?
Podstawą porównywania plików PDF jest wyodrębnianie i porównywanie treści tekstowej. Funkcje ekstrakcji tekstu IronPDF zapewniają dokładne pobieranie treści z praktycznie każdego układu pliku PDF, w tym dokumentów wielokolumnowych, tabel, formularzy i zeskanowanych plików PDF z osadzonymi warstwami tekstowymi. Poniższy przykład ładuje dwa pliki, wyodrębnia z nich tekst i oblicza wynik podobieństwa:
using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}Imports IronPdf
Imports System
' Load two PDF documents
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
' Extract text from both PDFs
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
' Compare the two documents
If text1 = text2 Then
Console.WriteLine("PDF files are identical")
Else
Console.WriteLine("PDFs have differences")
' Calculate character-level similarity
Dim maxLength As Integer = Math.Max(text1.Length, text2.Length)
If maxLength > 0 Then
Dim differences As Integer = 0
Dim minLength As Integer = Math.Min(text1.Length, text2.Length)
For i As Integer = 0 To minLength - 1
If text1(i) <> text2(i) Then differences += 1
Next
differences += Math.Abs(text1.Length - text2.Length)
Dim similarity As Double = 1.0 - CDbl(differences) / maxLength
Console.WriteLine($"Similarity: {similarity:P}")
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}")
End If
End IfTen kod wykorzystuje instrukcje najwyższego poziomu oraz metodę ExtractAllText() biblioteki IronPDF do pobrania pełnego tekstu z obu plików, a następnie przeprowadza porównanie na poziomie znaków w celu obliczenia procentowego podobieństwa. Wynik stanowi szybką, ilościową miarę tego, jak bardzo dokumenty się od siebie różnią.
Podejście oparte na znakach jest celowo proste i szybkie. Sprawdza się dobrze, gdy potrzebujesz szybkiej informacji o tym, czy dwa dokumenty się różnią, np. w celu wykrycia przypadkowego nadpisania lub potwierdzenia, że proces konwersji dał oczekiwany wynik. W scenariuszach wymagających bardziej szczegółowej analizy — takich jak identyfikacja zmienionych zdań lub śledzenie różnic semantycznych — można zastosować algorytmy odległości Levenshteina lub algorytmy porównawcze na wyodrębnionych ciągach tekstowych.
Jak wyglądają pliki PDF, z których korzystamy?
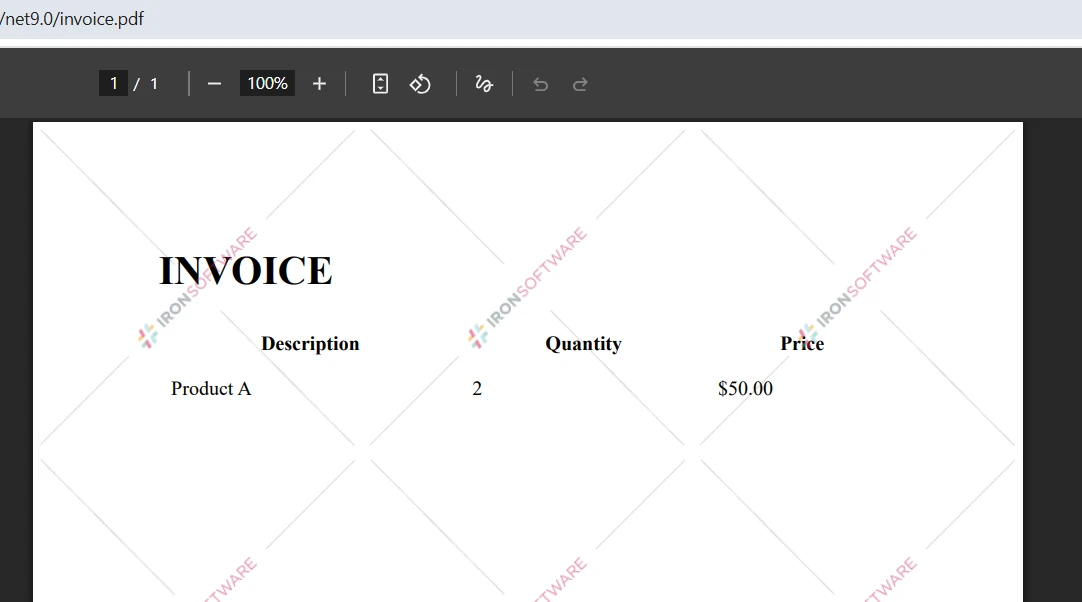
Co pokazuje wynik porównania?
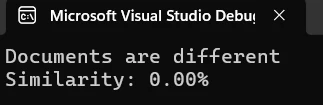
Wynik wyświetlany w konsoli pokazuje procentowe podobieństwo między dokumentami. Wynik podobieństwa wynoszący 2,60%, jak pokazano powyżej, wskazuje, że oba dokumenty mają niemal całkowicie odmienną treść. Ten wskaźnik pomaga szybko ocenić stopień różnicy i podjąć decyzję co do dalszych kroków.
Jakie są ograniczenia porównania wyłącznie tekstowego?
Text-only comparison does not capture formatting, images, or layout differences. Dwa pliki PDF mogą zawierać identyczny tekst, ale wyglądać zupełnie inaczej, jeśli jeden z nich ma inną czcionkę, rozmiar strony lub rozmieszczenie obrazów. Aby uzyskać pełne porównanie wizualne, warto rozważyć połączenie funkcji wyodrębniania obrazów IronPDF z biblioteką do porównywania obrazów. Funkcje rasteryzacji IronPDF konwertują strony na obrazy w celu porównania piksel po pikselu, gdy dokładność wizualna ma większe znaczenie niż treść tekstowa.
Jak porównać pliki PDF strona po stronie?
Porównanie całego dokumentu pozwala stwierdzić, czy dwa pliki PDF różnią się od siebie, ale porównanie strona po stronie pokazuje dokładnie, gdzie występują różnice. Jest to szczególnie cenne w przypadku dokumentów o strukturze, takich jak raporty, faktury i formularze, w których treść ma przewidywalny układ na wszystkich stronach:
using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim maxPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
Dim pageResults = New List(Of (Page As Integer, Similarity As Double))()
For i As Integer = 0 To maxPages - 1
Dim page1Text As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2Text As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If page1Text <> page2Text Then
Dim maxLen As Integer = Math.Max(page1Text.Length, page2Text.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(page1Text.Length - page2Text.Length)) / maxLen)
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}")
pageResults.Add((i + 1, sim))
End If
Next
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}")Ta metoda iteruje przez każdą stronę przy użyciu ExtractTextFromPage(), porównując zawartość indywidualnie. To podejście pozwala bezbłędnie obsługiwać pliki PDF o różnej liczbie stron — strony, które istnieją w jednym dokumencie, ale nie w drugim, są traktowane jako puste ciągi znaków, co pozwala poprawnie zarejestrować je jako różne.
Porównanie strona po stronie jest szczególnie przydatne, gdy trzeba wskazać miejsca modyfikacji w dużych dokumentach. Zamiast przeglądać całą 200-stronicową umowę prawną, otrzymujesz listę pięciu stron, które faktycznie uległy zmianie. To znacznie skraca czas przeglądu i sprawia, że wyniki porównania są przydatne w praktyce.
Aby zapewnić wydajność przy pracy z dużymi plikami PDF, IronPDF obsługuje przetwarzanie asynchroniczne i operacje równoległe, co pozwala na efektywne porównywanie partii danych. Przewodnik po optymalizacji wydajności obejmuje dodatkowe techniki dotyczące operacji na dużą skalę, w tym strategie zarządzania pamięcią służące do sekwencyjnego przetwarzania wielu dużych plików.
Jak porównać wiele dokumentów PDF jednocześnie?
Porównanie wielu plików PDF z jednym dokumentem referencyjnym jest proste dzięki IronPDF. Poniższy przykład porównuje dowolną liczbę plików z pierwszym dostarczonym plikiem, gromadząc wyniki do celów raportowania:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Module Module1
Sub Main()
Dim pdfPaths As String() = {"reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf"}
If pdfPaths.Length < 2 Then
Console.WriteLine("At least 2 PDFs required for comparison")
Return
End If
Dim referencePdf = PdfDocument.FromFile(pdfPaths(0))
Dim referenceText As String = referencePdf.ExtractAllText()
Dim results As New List(Of (File As String, Similarity As Double, Identical As Boolean))()
For i As Integer = 1 To pdfPaths.Length - 1
Try
Dim currentPdf = PdfDocument.FromFile(pdfPaths(i))
Dim currentText As String = currentPdf.ExtractAllText()
Dim identical As Boolean = (referenceText = currentText)
Dim maxLen As Integer = Math.Max(referenceText.Length, currentText.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(referenceText.Length - currentText.Length)) / maxLen)
results.Add((Path.GetFileName(pdfPaths(i)), similarity, identical))
Dim status As String = If(identical, "identical to reference", $"differs -- similarity: {similarity:P}")
Console.WriteLine($"{Path.GetFileName(pdfPaths(i))}: {status}")
Catch ex As Exception
Console.WriteLine($"Error processing {pdfPaths(i)}: {ex.Message}")
End Try
Next
Console.WriteLine($"\nBatch complete: {results.Count} files compared")
Console.WriteLine($"Identical: {results.FindAll(Function(r) r.Identical).Count}")
Console.WriteLine($"Different: {results.FindAll(Function(r) Not r.Identical).Count}")
End Sub
End ModuleTo podejście polega na jednokrotnym załadowaniu dokumentu referencyjnego, a następnie przechodzeniu w pętli przez każdy kolejny plik i porównywaniu go z tym dokumentem. Blok try/catch gwarantuje, że jeden uszkodzony lub niedostępny plik nie spowoduje przerwania całej partii — błąd jest rejestrowany, a przetwarzanie jest kontynuowane z następnym plikiem.
W przypadku bardzo dużych partii warto rozważyć użycie wzorców zadań asynchronicznych, aby ładować i wyodrębniać tekst z wielu plików PDF równolegle, a nie sekwencyjnie. Wybierając dokument referencyjny, należy użyć najnowszej zatwierdzonej wersji w przypadku scenariuszy kontroli wersji lub oczekiwanego szablonu wyjściowego w przypadku procesów zapewnienia jakości. Można również zautomatyzować wybór odniesień poprzez odczyt metadanych plików PDF, takich jak daty utworzenia i numery wersji osadzone w samych dokumentach.
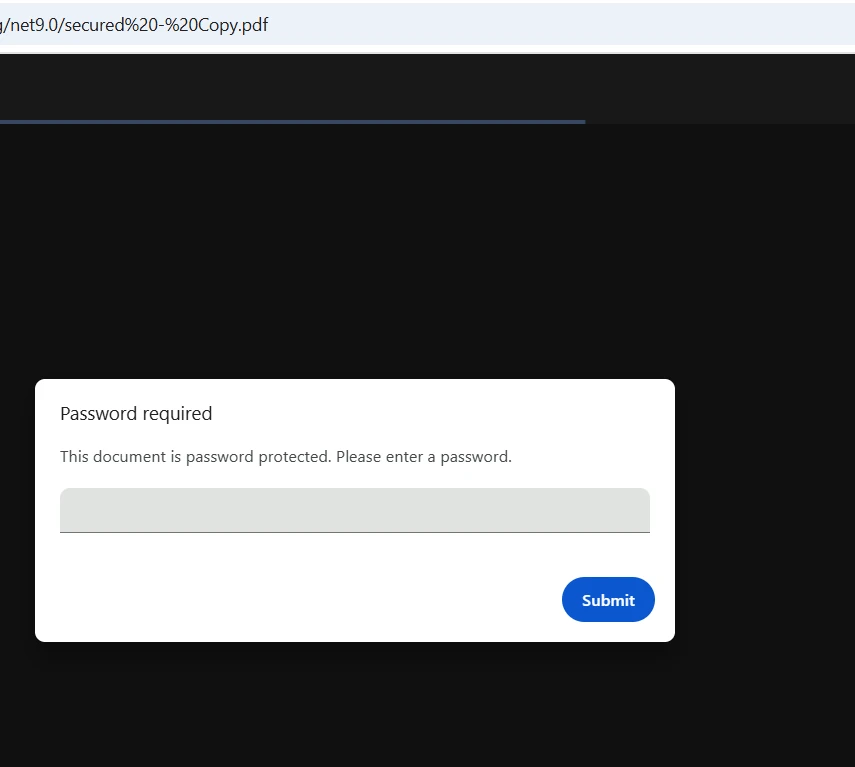
Jak porównać pliki PDF chronione hasłem?
IronPDF obsługuje zaszyfrowane pliki PDF, przyjmując hasło bezpośrednio w wywołaniu FromFile. Nie ma potrzeby odszyfrowywania plików na zewnątrz przed ich załadowaniem — biblioteka zajmuje się uwierzytelnianiem wewnętrznie. Biblioteka obsługuje standardy szyfrowania 40-bitowego RC4, 128-bitowego RC4 oraz 128-bitowego AES:
using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
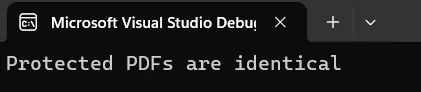
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}Imports IronPdf
Imports System
Try
' Load password-protected PDFs
Dim pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1")
Dim pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2")
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages")
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages")
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
Dim identical As Boolean = text1.Equals(text2)
Dim maxLen As Integer = Math.Max(text1.Length, text2.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(text1.Length - text2.Length)) / maxLen)
Console.WriteLine($"Documents are {(If(identical, "identical", "different"))}")
Console.WriteLine($"Similarity: {similarity:P}")
' Optionally save a secured comparison report
If Not identical Then
Dim renderer = New ChromePdfRenderer()
Dim reportPdf = renderer.RenderHtmlAsPdf($"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>")
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password"
reportPdf.SecuritySettings.UserPassword = "report-user-password"
reportPdf.SecuritySettings.AllowUserPrinting = True
reportPdf.SecuritySettings.AllowUserCopyPasteContent = False
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Secured report saved.")
End If
Catch ex As Exception
Console.WriteLine($"Error handling secured PDFs: {ex.Message}")
End TryPrzekazując hasła do FromFile, można porównywać zaszyfrowane pliki PDF bez konieczności ich wcześniejszego odszyfrowywania. Funkcje bezpieczeństwa IronPDF zapewniają prawidłowe obchodzenie się z treściami chronionymi, a podpisy cyfrowe stanowią dodatkową warstwę weryfikacji autentyczności dokumentów.
W przypadku plików PDF chronionych hasłem należy przechowywać dane uwierzytelniające w zmiennych środowiskowych lub menedżerze sekretów, zamiast zakodowywać je na stałe w kodzie źródłowym. Wprowadź praktyki rejestrowania, które wykluczają informacje wrażliwe, oraz dodaj logikę ponownych prób z limitami prób, aby zapobiec scenariuszom ataków brute-force. W przypadku zaawansowanych potrzeb w zakresie szyfrowania przewodnik zgodności z PDF/UA obejmuje konfiguracje zabezpieczeń zgodne z zasadami dostępności.
Jak wygenerować raport porównawczy w formacie PDF?
Sformatowany raport daje interesariuszom jasny obraz tego, co się zmieniło między dwoma dokumentami. W poniższym przykładzie wykorzystano konwersję HTML na PDF w IronPDF w celu utworzenia stylizowanego raportu z wskaźnikami różnic dla poszczególnych stron:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Text
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim differences = New List(Of (Page As Integer, Similarity As Double, Len1 As Integer, Len2 As Integer, CharDiff As Integer))()
Dim totalPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
For i As Integer = 0 To totalPages - 1
Dim p1 As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim p2 As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If p1 = p2 Then Continue For
Dim maxLen As Integer = Math.Max(p1.Length, p2.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(p1.Length - p2.Length)) / maxLen)
Dim charDiff As Integer = Math.Abs(p1.Length - p2.Length)
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff))
Next
' Build HTML report
Dim sb = New StringBuilder()
sb.Append("<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>")
sb.Append("<h1>PDF Comparison Report</h1>")
sb.Append("<div class='summary'>")
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>")
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>")
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>")
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>")
sb.Append("</div>")
If differences.Count > 0 Then
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>")
For Each d In differences
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>")
Next
sb.Append("</tbody></table>")
Else
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>")
End If
sb.Append("</body></html>")
Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 25
renderer.RenderingOptions.MarginBottom = 25
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print
Dim reportPdf = renderer.RenderHtmlAsPdf(sb.ToString())
reportPdf.MetaData.Author = "PDF Comparison Tool"
reportPdf.MetaData.Title = "PDF Comparison Report"
reportPdf.MetaData.CreationDate = DateTime.Now
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Report saved to comparison-report.pdf")To rozwiązanie wykorzystuje renderowanie HTML do tworzenia profesjonalnych raportów o niestandardowym wyglądzie. Obsługa CSS przez IronPDF pozwala na pełną personalizację — dostosowanie czcionek, kolorów i układów do wizerunku firmy. Dodaj nagłówki i stopki z numerami stron oraz znacznikami czasu, aby zapewnić formalną strukturę dokumentu.

Wygenerowany raport zawiera przejrzyste podsumowanie różnic wraz ze szczegółowymi wskaźnikami dla poszczególnych stron. Możesz rozszerzyć raport o wykresy przedstawiające wyniki podobieństwa, miniatury stron pokazujące zmienione obszary oraz zakładki ułatwiające nawigację w długich raportach. W przypadku raportów archiwalnych IronPDF obsługuje format PDF/A, aby zapewnić długoterminową czytelność i zgodność z przepisami dotyczącymi przechowywania dokumentów.
Jakie są najlepsze praktyki dotyczące porównywania plików PDF w .NET?
Przed wprowadzeniem funkcji porównywania plików PDF do produkcji kilka wzorców decyduje o tym, czy będzie to kruchy prototyp, czy niezawodne narzędzie:
Prawidłowo obsługuj wartości null i pusty tekst. ExtractAllText() może zwracać pusty ciąg znaków w przypadku plików PDF zawierających wyłącznie obrazy lub zeskanowanych dokumentów bez warstwy tekstowej. Zawsze sprawdzaj, czy wyniki są puste przed uruchomieniem logiki porównawczej, i zdecyduj, czy wynik "pusty kontra pusty" liczy się jako "identyczny" czy "nieokreślony".
Przed porównaniem należy znormalizować tekst. Różne generatory plików PDF mogą tworzyć nieco inne wzorce spacji, zakończenia linii lub normalizację Unicode dla tej samej treści wizualnej. Uruchomienie text.Trim().Replace("\r\n", "\n") przed porównaniem zapobiega fałszywym wynikom pozytywnym wynikającym z czysto kosmetycznych różnic.
W przypadku procesów biznesowych należy stosować progi podobieństwa zamiast dokładnych dopasowań. Wynik podobieństwa na poziomie 98% prawdopodobnie oznacza, że dwa dokumenty są funkcjonalnie identyczne, nawet jeśli jeden z nich ma nieco inny znacznik czasu lub automatycznie wygenerowany identyfikator. Zdefiniuj próg odpowiedni dla swojej dziedziny, zamiast wymagać dokładnej zgodności znaków.
Porównaj wyniki z metadanymi plików. Zapisz nazwy plików, rozmiary, daty modyfikacji i wyniki podobieństwa w uporządkowanym dzienniku. Tworzy to ścieżkę audytu, którą zespoły ds. zgodności mogą przejrzeć bez konieczności ponownego uruchamiania porównania.
Należy wziąć pod uwagę kwestie związane z kodowaniem i czcionkami. Niektóre pliki PDF wykorzystują niestandardowe tabele kodowania dla warstw tekstowych. Silnik IronPDF oparty na przeglądarce Chrome radzi sobie poprawnie w większości przypadków, ale jeśli zauważysz zniekształcony tekst, sprawdź, czy źródłowy plik PDF używa niestandardowego kodowania czcionek. Przewodnik dotyczący rozwiązywania problemów obejmuje typowe problemy związane z ekstrakcją oraz sposoby ich rozwiązywania.
Dla zespołów tworzących produkcyjne potoki porównywania dokumentów dokumentacja Microsoftu dotycząca wzorców asynchronicznych w .NET stanowi przydatny przewodnik po strukturyzowaniu równoległego przetwarzania plików. Warto również zapoznać się ze specyfikacją PDF (ISO 32000), jeśli chcesz zrozumieć, jakie rodzaje treści mogą, a jakie nie mogą pojawiać się w warstwie tekstowej danego dokumentu.
Jak już dziś rozpocząć korzystanie z PDF Comparison?
Porównanie plików PDF w języku C# to praktyczna umiejętność, która otwiera możliwości automatyzacji dokumentów w wielu branżach — a IronPDF sprawia, że jest ona dostępna dla każdego programisty .NET. Zacznij od podstawowego przykładu wyodrębniania tekstu, rozszerz go w razie potrzeby do analizy strona po stronie i skorzystaj z generatora raportów HTML, aby dostarczyć profesjonalne wyniki interesariuszom.
| Scenariusz | Podejście | Kluczowa metoda |
|---|---|---|
| Podstawowe porównanie tekstów | Wyodrębnij pełny tekst z obu dokumentów i porównaj ciągi znaków | ExtractAllText() |
| Analiza strona po stronie | Porównaj każdą stronę osobno, aby wskazać miejsca zmian | ExtractTextFromPage() |
| Porównanie partii | Porównaj wiele plików z jednym dokumentem referencyjnym | PdfDocument.FromFile() |
| Pliki chronione hasłem | Przekaż hasło bezpośrednio do modułu ładującego pliki — nie jest wymagane wcześniejsze odszyfrowanie | PdfDocument.FromFile(path, password) |
| Generowanie raportów | Konwersja zestawienia porównawczego w formacie HTML na raport PDF z formatowaniem | ChromePdfRenderer.RenderHtmlAsPdf() |
Pobierz bezpłatną wersję próbną, aby od razu rozpocząć tworzenie z IronPDF — do 30-dniowego okresu próbnego nie jest wymagana karta kredytowa. Przewodnik szybkiego startu przeprowadza użytkownika przez proces wstępnej konfiguracji w mniej niż pięć minut. Kiedy będziesz gotowy do wdrożenia, zapoznaj się ze stroną dotyczącą licencji, aby znaleźć opcje dostosowane do wielkości Twojego zespołu i wymagań wdrożeniowych.
Aby pogłębić swoją wiedzę, zapoznaj się z kompletną serią samouczków dotyczących tworzenia, edycji i obróbki plików PDF. Dokumentacja API zawiera szczegółowe informacje o metodach, a sekcja przykładów pokazuje rzeczywiste implementacje, w tym obsługę formularzy i znakowanie wodne.
Często Zadawane Pytania
Jak mogę porównać dwa pliki PDF za pomocą języka C#?
Możesz porównać dwa pliki PDF za pomocą języka C#, korzystając z potężnej funkcji porównywania plików PDF biblioteki IronPDF, która pozwala zidentyfikować różnice w tekście, obrazach i układzie między dwoma dokumentami PDF.
Jakie są zalety korzystania z IronPDF do porównywania plików PDF?
IronPDF zapewnia prosty i wydajny sposób porównywania plików PDF, gwarantując dokładność w wykrywaniu różnic. Obsługuje różne tryby porównywania i płynnie integruje się z projektami C#.
Czy IronPDF radzi sobie z dużymi plikami PDF w celu porównania?
Tak, IronPDF został zaprojektowany do wydajnej obsługi dużych plików PDF, dzięki czemu nadaje się do porównywania obszernych dokumentów bez utraty wydajności.
Czy IronPDF obsługuje wizualne porównywanie plików PDF?
IronPDF umożliwia wizualne porównanie plików PDF poprzez zaznaczanie różnic w układzie i obrazach, zapewniając kompleksowy przegląd zmian między dokumentami.
Czy możliwe jest zautomatyzowanie porównywania plików PDF za pomocą IronPDF?
Tak, można zautomatyzować procesy porównywania plików PDF za pomocą IronPDF w aplikacjach napisanych w języku C#, co idealnie sprawdza się w sytuacjach wymagających częstych lub zbiorczych porównań.
Jakie rodzaje różnic może wykryć IronPDF w plikach PDF?
IronPDF potrafi wykrywać różnice tekstowe, graficzne i w układzie, zapewniając dokładne porównanie całej zawartości plików PDF.
W jaki sposób IronPDF zapewnia dokładność porównania plików PDF?
IronPDF zapewnia dokładność dzięki zaawansowanym algorytmom, które skrupulatnie porównują zawartość plików PDF, minimalizując ryzyko przeoczenia subtelnych różnic.
Czy mogę zintegrować IronPDF z innymi aplikacjami .NET w celu porównywania plików PDF?
Tak, IronPDF został zaprojektowany tak, aby płynnie integrować się z aplikacjami .NET, umożliwiając programistom włączenie funkcji porównywania plików PDF do istniejących rozwiązań programowych.
Czy potrzebuję wcześniejszego doświadczenia w porównywaniu plików PDF, aby korzystać z IronPDF?
Nie jest wymagane wcześniejsze doświadczenie. IronPDF zapewnia przyjazne dla użytkownika narzędzia i obszerną dokumentację, które poprowadzą Cię przez proces porównywania plików PDF, nawet jeśli dopiero zaczynasz przygodę z obróbką plików PDF.
Czy dostępna jest wersja demonstracyjna lub próbna funkcji porównywania plików PDF w IronPDF?
Tak, IronPDF oferuje bezpłatną wersję próbną, która pozwala zapoznać się z funkcjami porównywania plików PDF i przetestować je przed podjęciem decyzji o zakupie.














