
JPEG in PDF konvertieren .NET | IronPDF C# Tutorial
IronPDF bietet C#-Entwicklern eine einfache Möglichkeit, PDF-Dokumente programmatisch zu vergleichen – Textinhalte zu extrahieren und Unterschiede seitenweise mit nur wenigen Codezeilen zu analysieren. Dieses Tutorial führt Sie durch praktische Codebeispiele für grundlegende Vergleiche, die Analyse mehrerer Dokumente, die Verarbeitung passwortgeschützter Dateien und die Generierung formatierter Vergleichsberichte in .NET 10.
Warum muss man PDF-Dokumente programmatisch vergleichen?
Das manuelle Vergleichen von PDF-Dokumenten ist langsam, fehleranfällig und nicht skalierbar. In dokumentenintensiven Branchen wie dem Rechts-, Finanz- und Gesundheitswesen ändern sich Dateien ständig – Verträge werden überarbeitet, Rechnungen neu ausgestellt und behördliche Dokumente müssen versioniert werden. Der automatisierte Vergleich beseitigt den menschlichen Engpass und liefert jedes Mal konsistente, nachvollziehbare Ergebnisse.
IronPDF bietet Ihnen einen produktionsreifen Ansatz zum Vergleichen zweier PDF-Dateien in C#. Die Bibliothek verwendet eine Chrome-Rendering-Engine für die präzise Textextraktion aus komplexen Layouts, und ihre vollständige API bietet intuitive Methoden zum Laden, Lesen und Analysieren von PDF-Inhalten. Ob Sie Vertragsänderungen verfolgen, generierte Ergebnisse validieren oder ein Dokumentenprüfungssystem aufbauen möchten – IronPDF übernimmt die Hauptarbeit.
Die Bibliothek ist auch eine gute Wahl für Teams, die .NET bereits auf mehreren Plattformen einsetzen. Es unterstützt Windows, Linux, macOS, Docker, Azure und AWS, ohne dass für jedes Zielsystem unterschiedliche Codepfade erforderlich sind. Dadurch eignet es sich sowohl für die Entwicklung von Vergleichstools, die in CI/CD-Pipelines laufen, als auch für Desktop-Anwendungen.
Wann sollte man den automatisierten PDF-Vergleich verwenden?
Der automatisierte Vergleich wird unerlässlich bei der Versionskontrolle in dokumentenintensiven Arbeitsabläufen. Eine manuelle Überprüfung ist unpraktisch, wenn täglich Hunderte von Dateien bearbeitet werden müssen oder wenn Genauigkeit von entscheidender Bedeutung ist. Zu den typischen Anwendungsfällen gehören der Vergleich von Rechnungen über verschiedene Abrechnungszyklen hinweg, die Überprüfung von behördlichen Meldungen anhand genehmigter Vorlagen, die Nachverfolgung von Änderungen in technischen Spezifikationen über verschiedene Release-Versionen hinweg und die Prüfung von Vertragsänderungen in juristischen Arbeitsabläufen.
Die Genauigkeitsgewinne sind signifikant. Ein menschlicher Prüfer, der zwei 50-seitige Dokumente durchsieht, könnte eine einzige geänderte Zahl in einer Finanztabelle übersehen. Ein automatisierter Vergleich erkennt dies sofort, markiert die Seite und erstellt einen Differenzbericht ohne Ermüdung oder Inkonsistenz.
Was sind die wichtigsten Anwendungsfälle?
Der PDF-Vergleich findet in vielen Branchen und Arbeitsabläufen Anwendung:
- Rechtliches : Vertragsänderungen verfolgen, Übereinstimmung zwischen Entwurf und Endfassung prüfen und sicherstellen, dass vor der Unterzeichnung nur genehmigte Änderungen vorgenommen wurden.
- Finanzen : Bankauszüge prüfen, unautorisierte Änderungen an Rechnungen erkennen und sicherstellen, dass die generierten Berichte den erwarteten Ergebnissen entsprechen.
- Gesundheitswesen : Überprüfen Sie, ob die behördlichen Einreichungen mit den genehmigten Unterlagen übereinstimmen, und bestätigen Sie, dass die Patientendaten nicht verändert wurden.
- Qualitätssicherung : Vergleich der softwaregenerierten PDFs mit den Referenzdateien, um Darstellungsfehler in automatisierten Testreihen aufzudecken.
- Dokumentation : Sicherstellen, dass die lokalisierten Versionen der Benutzerhandbücher konsistent sind und dass die Übersetzung den technischen Inhalt nicht verändert hat.
Dank der plattformübergreifenden Unterstützung von IronPDF lassen sich diese Lösungen ohne Änderungen in Windows-, Linux- und Cloud-Umgebungen einsetzen.
Wie installiert man IronPDF in einem .NET -Projekt?
Installieren Sie IronPDF über NuGet entweder mithilfe der Paket-Manager-Konsole oder der .NET -Befehlszeilenschnittstelle:
Install-Package IronPdf
Informationen zu Linux-Bereitstellungen oder Docker-basierten Umgebungen finden Sie in der plattformspezifischen Dokumentation. Nach der Installation konfigurieren Sie Ihren Lizenzschlüssel, falls Sie einen besitzen:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Die Entwicklung und das Testen funktionieren auch ohne Lizenzschlüssel, allerdings werden auf den generierten PDFs Wasserzeichen angezeigt. Für den Einsatz in der Produktion ist eine gültige Lizenz von der Lizenzierungsseite erforderlich. Die kostenlose Testversion bietet vollen Funktionsumfang für eine 30-tägige Evaluierung ohne Angabe einer Kreditkarte.
IronPDF unterstützt .NET Framework 4.6.2+, .NET Core 3.1+ und .NET 5 bis .NET 10. Für macOS werden sowohl Intel- als auch Apple Silicon-Prozessoren unterstützt. Die Bibliothek übernimmt die Installation der Chrome-Rendering-Engine automatisch, sodass keine manuelle Browserkonfiguration erforderlich ist.
Wie führt man einen einfachen PDF-Vergleich durch?
Die Grundlage des PDF-Vergleichs besteht in der Extraktion und dem Vergleich von Textinhalten. Die Textextraktionsfunktionen von IronPDF ermöglichen die präzise Inhaltswiedergabe aus praktisch jedem PDF-Layout, einschließlich mehrspaltiger Dokumente, Tabellen, Formulare und gescannter PDFs mit eingebetteten Textebenen. Das folgende Beispiel lädt zwei Dateien, extrahiert deren Text und berechnet einen Ähnlichkeitswert:
using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}Imports IronPdf
Imports System
' Load two PDF documents
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
' Extract text from both PDFs
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
' Compare the two documents
If text1 = text2 Then
Console.WriteLine("PDF files are identical")
Else
Console.WriteLine("PDFs have differences")
' Calculate character-level similarity
Dim maxLength As Integer = Math.Max(text1.Length, text2.Length)
If maxLength > 0 Then
Dim differences As Integer = 0
Dim minLength As Integer = Math.Min(text1.Length, text2.Length)
For i As Integer = 0 To minLength - 1
If text1(i) <> text2(i) Then differences += 1
Next
differences += Math.Abs(text1.Length - text2.Length)
Dim similarity As Double = 1.0 - CDbl(differences) / maxLength
Console.WriteLine($"Similarity: {similarity:P}")
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}")
End If
End IfDieser Code verwendet Top-Level-Anweisungen und die ExtractAllText()-Methode von IronPDF, um den vollständigen Text aus beiden Dateien zu ziehen, und führt dann einen Zeichenvergleich durch, um einen Ähnlichkeitsprozentsatz zu berechnen. Die Punktzahl liefert Ihnen ein schnelles, quantitatives Maß dafür, wie unterschiedlich die Dokumente sind.
Der Ansatz auf Zeichenebene ist bewusst einfach und schnell. Er eignet sich gut, wenn man schnell erkennen muss, ob zwei Dokumente voneinander abweichen, beispielsweise um versehentliches Überschreiben zu erkennen oder zu bestätigen, dass eine Konvertierungspipeline das erwartete Ergebnis erzeugt hat. Für Szenarien, die eine differenziertere Analyse erfordern – wie die Identifizierung geänderter Sätze oder die Verfolgung semantischer Unterschiede – können Sie Levenshtein-Distanz- oder Diff-Algorithmen auf die extrahierten Textzeichenfolgen anwenden.
Wie sehen die Eingabe-PDFs aus?
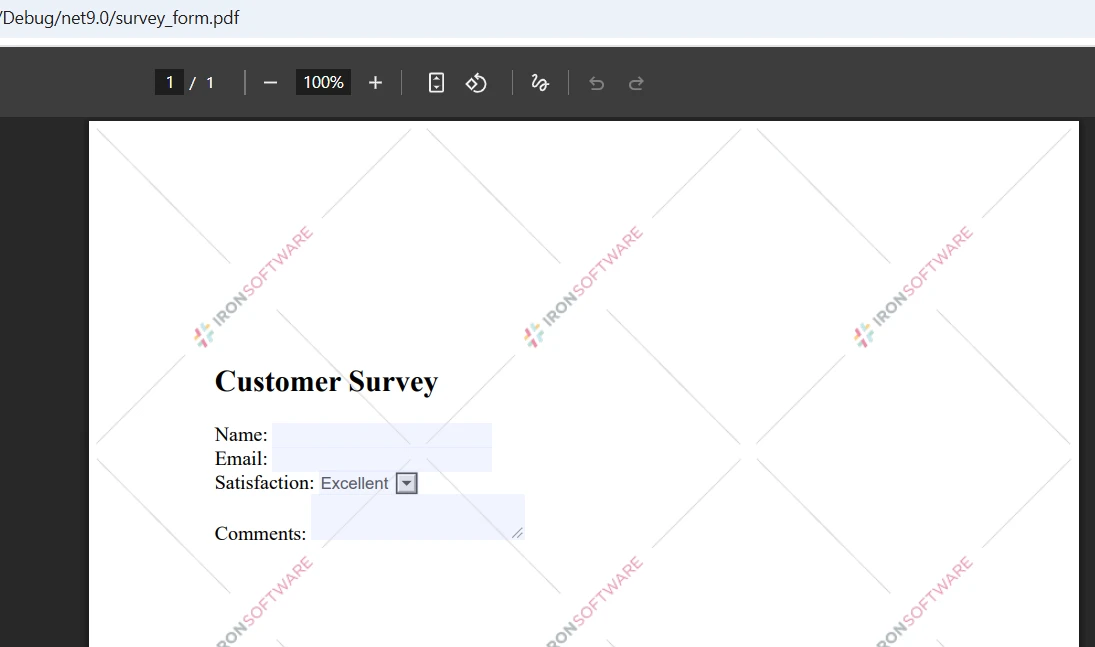
Was zeigt die Vergleichsausgabe an?
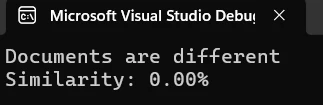
Die Konsolenausgabe zeigt die prozentuale Ähnlichkeit zwischen den Dokumenten an. Ein Ähnlichkeitswert von 2,60 %, wie oben dargestellt, zeigt an, dass die beiden Dokumente fast vollständig unterschiedliche Inhalte haben. Diese Kennzahl hilft Ihnen, das Ausmaß der Unterschiede schnell einzuschätzen und über die nächsten Schritte zu entscheiden.
Was sind die Grenzen des reinen Textvergleichs?
Ein reiner Textvergleich erfasst weder Formatierungs-, Bild- noch Layoutunterschiede. Zwei PDFs können identischen Text haben, aber völlig unterschiedlich aussehen, wenn eine eine andere Schriftart, Seitengröße oder Bildplatzierung aufweist. Für einen umfassenden visuellen Vergleich empfiehlt es sich, die Bildextraktionsfunktionen von IronPDF mit einer Bildvergleichsbibliothek zu kombinieren. Die Rasterisierungsfunktionen von IronPDF wandeln Seiten in Bilder um, um einen pixelgenauen Vergleich zu ermöglichen, wenn die visuelle Genauigkeit wichtiger ist als der Textinhalt.
Wie vergleicht man PDFs Seite für Seite?
Ein Vergleich des gesamten Dokuments zeigt Ihnen, ob sich zwei PDFs unterscheiden, ein seitenweiser Vergleich zeigt Ihnen hingegen genau, wo die Unterschiede liegen. Dies ist besonders wertvoll für strukturierte Dokumente wie Berichte, Rechnungen und Formulare, bei denen der Inhalt einem vorhersehbaren Layout über die Seiten hinweg folgt:
using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim maxPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
Dim pageResults = New List(Of (Page As Integer, Similarity As Double))()
For i As Integer = 0 To maxPages - 1
Dim page1Text As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2Text As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If page1Text <> page2Text Then
Dim maxLen As Integer = Math.Max(page1Text.Length, page2Text.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(page1Text.Length - page2Text.Length)) / maxLen)
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}")
pageResults.Add((i + 1, sim))
End If
Next
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}")Diese Methode iteriert durch jede Seite mithilfe von ExtractTextFromPage() und vergleicht die Inhalte individuell. Der Ansatz verarbeitet PDFs mit unterschiedlicher Seitenzahl fehlerfrei – Seiten, die in dem einen Dokument vorhanden sind, im anderen jedoch nicht, werden als leere Zeichenketten behandelt, wodurch sie korrekt als unterschiedlich registriert werden.
Der seitenweise Vergleich ist besonders nützlich, wenn Sie die Änderungsstellen in großen Dokumenten genau lokalisieren müssen. Statt eines 200-seitigen Rechtsvertrags durchzusehen, erhalten Sie eine Liste der fünf Seiten, die sich tatsächlich geändert haben. Dadurch wird die Überprüfungszeit drastisch reduziert und die Vergleichsergebnisse werden direkt umsetzbar.
Für eine optimale Performance bei großen PDFs unterstützt IronPDF die asynchrone Verarbeitung und parallele Operationen, um Stapelvergleiche effizient durchzuführen. Der Leitfaden zur Leistungsoptimierung umfasst zusätzliche Techniken für groß angelegte Operationen, einschließlich Speichermanagementstrategien für die sequentielle Verarbeitung vieler großer Dateien.
Wie vergleicht man mehrere PDF-Dokumente gleichzeitig?
Mit IronPDF ist der Stapelvergleich von PDFs anhand eines einzelnen Referenzdokuments unkompliziert. Das folgende Beispiel vergleicht eine beliebige Anzahl von Dateien mit der ersten angegebenen Datei und sammelt die Ergebnisse für die Berichterstellung:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Module Module1
Sub Main()
Dim pdfPaths As String() = {"reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf"}
If pdfPaths.Length < 2 Then
Console.WriteLine("At least 2 PDFs required for comparison")
Return
End If
Dim referencePdf = PdfDocument.FromFile(pdfPaths(0))
Dim referenceText As String = referencePdf.ExtractAllText()
Dim results As New List(Of (File As String, Similarity As Double, Identical As Boolean))()
For i As Integer = 1 To pdfPaths.Length - 1
Try
Dim currentPdf = PdfDocument.FromFile(pdfPaths(i))
Dim currentText As String = currentPdf.ExtractAllText()
Dim identical As Boolean = (referenceText = currentText)
Dim maxLen As Integer = Math.Max(referenceText.Length, currentText.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(referenceText.Length - currentText.Length)) / maxLen)
results.Add((Path.GetFileName(pdfPaths(i)), similarity, identical))
Dim status As String = If(identical, "identical to reference", $"differs -- similarity: {similarity:P}")
Console.WriteLine($"{Path.GetFileName(pdfPaths(i))}: {status}")
Catch ex As Exception
Console.WriteLine($"Error processing {pdfPaths(i)}: {ex.Message}")
End Try
Next
Console.WriteLine($"\nBatch complete: {results.Count} files compared")
Console.WriteLine($"Identical: {results.FindAll(Function(r) r.Identical).Count}")
Console.WriteLine($"Different: {results.FindAll(Function(r) Not r.Identical).Count}")
End Sub
End ModuleBei diesem Ansatz wird das Referenzdokument einmal geladen und anschließend jede andere Datei mit diesem verglichen. Der try/catch-Block stellt sicher, dass eine beschädigte oder nicht zugängliche Datei nicht zum Abbruch des gesamten Batches führt – der Fehler wird protokolliert und die Verarbeitung wird mit der nächsten Datei fortgesetzt.
Bei sehr großen Datenmengen empfiehlt es sich, asynchrone Aufgabenmuster zu verwenden, um Text aus mehreren PDFs parallel statt sequenziell zu laden und zu extrahieren. Bei der Auswahl eines Referenzdokuments sollte für Versionskontrollszenarien die neueste genehmigte Version oder für Qualitätssicherungs-Workflows die erwartete Ausgabevorlage verwendet werden. Sie können die Referenzauswahl auch automatisieren, indem Sie PDF-Metadaten wie Erstellungsdatum und Versionsnummer auslesen, die in den Dokumenten selbst eingebettet sind.
Wie vergleicht man passwortgeschützte PDFs?
IronPDF verarbeitet verschlüsselte PDFs, indem es das Passwort direkt im FromFile-Aufruf akzeptiert. Dateien müssen vor dem Laden nicht extern entschlüsselt werden – die Bibliothek kümmert sich intern um die Authentifizierung. Die Bibliothek unterstützt die Verschlüsselungsstandards 40-Bit RC4, 128-Bit RC4 und 128-Bit AES:
using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}Imports IronPdf
Imports System
Try
' Load password-protected PDFs
Dim pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1")
Dim pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2")
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages")
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages")
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
Dim identical As Boolean = text1.Equals(text2)
Dim maxLen As Integer = Math.Max(text1.Length, text2.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(text1.Length - text2.Length)) / maxLen)
Console.WriteLine($"Documents are {(If(identical, "identical", "different"))}")
Console.WriteLine($"Similarity: {similarity:P}")
' Optionally save a secured comparison report
If Not identical Then
Dim renderer = New ChromePdfRenderer()
Dim reportPdf = renderer.RenderHtmlAsPdf($"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>")
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password"
reportPdf.SecuritySettings.UserPassword = "report-user-password"
reportPdf.SecuritySettings.AllowUserPrinting = True
reportPdf.SecuritySettings.AllowUserCopyPasteContent = False
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Secured report saved.")
End If
Catch ex As Exception
Console.WriteLine($"Error handling secured PDFs: {ex.Message}")
End TryDurch die Übergabe von Passwörtern an FromFile können Sie verschlüsselte PDFs ohne jeden Pre-Decryptionsschritt vergleichen. Die Sicherheitsfunktionen von IronPDF gewährleisten eine ordnungsgemäße Handhabung von geschütztem Inhalt, und digitale Signaturen bieten eine zusätzliche Schicht der Dokumentauthentifizierungsüberprüfung.
Beim Umgang mit passwortgeschützten PDFs sollten Zugangsdaten in Umgebungsvariablen oder einem Geheimnismanager gespeichert werden, anstatt sie im Quellcode fest zu kodieren. Implementieren Sie Protokollierungspraktiken, die sensible Informationen ausschließen, und fügen Sie eine Wiederholungslogik mit Versuchslimits hinzu, um Brute-Force-Angriffe zu verhindern. Für fortgeschrittene Verschlüsselungsanforderungen bietet der PDF/UA-Konformitätsleitfaden Informationen zu barrierefreien Sicherheitskonfigurationen.
Wie erstellt man einen PDF-Vergleichsbericht?
Ein formatierter Bericht vermittelt den Beteiligten einen klaren Überblick darüber, was sich zwischen zwei Dokumenten geändert hat. Das folgende Beispiel nutzt die HTML-zu-PDF-Konvertierung von IronPDF, um einen formatierten Bericht mit Metriken zu den Unterschieden pro Seite zu erstellen:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Text
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim differences = New List(Of (Page As Integer, Similarity As Double, Len1 As Integer, Len2 As Integer, CharDiff As Integer))()
Dim totalPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
For i As Integer = 0 To totalPages - 1
Dim p1 As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim p2 As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If p1 = p2 Then Continue For
Dim maxLen As Integer = Math.Max(p1.Length, p2.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(p1.Length - p2.Length)) / maxLen)
Dim charDiff As Integer = Math.Abs(p1.Length - p2.Length)
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff))
Next
' Build HTML report
Dim sb = New StringBuilder()
sb.Append("<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>")
sb.Append("<h1>PDF Comparison Report</h1>")
sb.Append("<div class='summary'>")
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>")
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>")
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>")
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>")
sb.Append("</div>")
If differences.Count > 0 Then
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>")
For Each d In differences
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>")
Next
sb.Append("</tbody></table>")
Else
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>")
End If
sb.Append("</body></html>")
Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 25
renderer.RenderingOptions.MarginBottom = 25
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print
Dim reportPdf = renderer.RenderHtmlAsPdf(sb.ToString())
reportPdf.MetaData.Author = "PDF Comparison Tool"
reportPdf.MetaData.Title = "PDF Comparison Report"
reportPdf.MetaData.CreationDate = DateTime.Now
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Report saved to comparison-report.pdf")Diese Lösung nutzt HTML-Rendering , um Professional Berichte mit individuellem Styling zu erstellen. Die CSS-Unterstützung von IronPDF ermöglicht eine vollständige Anpassung – Schriftarten, Farben und Layouts können an das Corporate Branding angepasst werden. Fügen Sie Kopf- und Fußzeilen mit Seitenzahlen und Zeitstempeln für formale Dokumentworkflows hinzu.

Der generierte Bericht bietet eine übersichtliche Zusammenfassung der Unterschiede mit detaillierten Kennzahlen pro Seite. Sie können den Bericht um visuelle Diagramme für Ähnlichkeitswerte, Seitenminiaturen, die geänderte Bereiche anzeigen, und Lesezeichen zur einfachen Navigation in umfangreichen Berichten erweitern. Für archivierungsfähige Berichte unterstützt IronPDF das PDF/A-Format , um die langfristige Lesbarkeit und die Einhaltung der Aufbewahrungsvorschriften für Dokumente zu gewährleisten.
Was sind die Best Practices für den PDF-Vergleich in .NET?
Bevor eine PDF-Vergleichsfunktion in die Produktion geht, entscheiden einige wenige Muster darüber, ob aus einem fragilen Prototyp ein zuverlässiges Werkzeug wird:
Gehen Sie mit null und leerem Text vorsichtig um. ExtractAllText() kann für reine Bild-PDFs oder gescannte Dokumente ohne Textebene einen leeren String zurückgeben. Prüfen Sie vor dem Ausführen der Vergleichslogik immer auf leere Ergebnisse und entscheiden Sie, ob ein leerer Vergleich als "identisch" oder "unbestimmt" zu werten ist.
Normalisieren Sie den Text vor dem Vergleich. Unterschiedliche PDF-Generatoren können bei demselben visuellen Inhalt leicht unterschiedliche Leerzeichenmuster, Zeilenumbrüche oder Unicode-Normalisierungen erzeugen. Das Ausführen von text.Trim().Replace("\r\n", "\n") vor dem Vergleich verhindert falsch positive Ergebnisse aufgrund rein kosmetischer Unterschiede.
Verwenden Sie für Geschäftsprozesse Ähnlichkeitsschwellenwerte anstelle von exakten Übereinstimmungen. Ein Ähnlichkeitswert von 98 % bedeutet wahrscheinlich, dass zwei Dokumente funktional identisch sind, selbst wenn eines einen leicht abweichenden Zeitstempel oder eine automatisch generierte ID aufweist. Definieren Sie einen für Ihren Anwendungsbereich geeigneten Schwellenwert, anstatt eine exakte Zeichengleichheit zu fordern.
Ergebnisse des Protokollvergleichs mit Dateimetadaten. Dateinamen, Größen, Änderungsdaten und Ähnlichkeitswerte werden in einem strukturierten Protokoll gespeichert. Dadurch entsteht ein Prüfpfad, den die Compliance-Teams einsehen können, ohne den Vergleich erneut durchführen zu müssen.
Beachten Sie mögliche Probleme mit der Kodierung und den Schriftarten. Einige PDF-Dateien verwenden benutzerdefinierte Kodierungstabellen für ihre Textebenen. Die Chrome-basierte Engine von IronPDF verarbeitet die meisten Fälle korrekt. Sollten Sie jedoch fehlerhaften Text sehen, überprüfen Sie, ob die Quell-PDF eine nicht standardmäßige Schriftkodierung verwendet. Der Leitfaden zur Fehlerbehebung behandelt häufige Extraktionsprobleme und deren Lösungen.
Für Teams, die Produktionsdokumentvergleichspipelines erstellen, bietet die Microsoft-Dokumentation zu asynchronen Mustern in .NET nützliche Hinweise zur Strukturierung der parallelen Dateiverarbeitung. Es lohnt sich auch, die PDF-Spezifikation (ISO 32000) zu konsultieren, wenn Sie wissen möchten, welche Arten von Inhalten in der Textebene eines Dokuments erscheinen dürfen und welche nicht.
Wie fängt man heute mit dem PDF-Vergleich an?
Der PDF-Vergleich in C# ist eine praktische Fähigkeit, die die Dokumentenautomatisierung in zahlreichen Branchen ermöglicht – und IronPDF macht sie für jeden .NET Entwickler zugänglich. Beginnen Sie mit dem einfachen Beispiel zur Textextraktion, erweitern Sie es bei Bedarf auf die seitenweise Analyse und nutzen Sie den HTML-Berichtsgenerator, um Professional Ergebnisse für Ihre Stakeholder zu erstellen.
| Szenario | Ansatz | Schlüsselmethode |
|---|---|---|
| Grundlegender Textvergleich | Extrahieren Sie den Volltext aus beiden Dokumenten und vergleichen Sie die Zeichenketten. | ExtractAllText() |
| Analyse Seite für Seite | Vergleichen Sie jede Seite einzeln, um die Änderungsstellen genau zu lokalisieren. | ExtractTextFromPage() |
| Chargenvergleich | Vergleichen Sie mehrere Dateien mit einem einzelnen Referenzdokument | PdfDocument.FromFile() |
| Passwortgeschützte Dateien | Übergeben Sie das Passwort direkt an den Dateilader – eine vorherige Entschlüsselung ist nicht erforderlich. | PdfDocument.FromFile(path, password) |
| Berichtserstellung | HTML-Vergleichszusammenfassung in einen formatierten PDF-Bericht umwandeln | ChromePdfRenderer.RenderHtmlAsPdf() |
Laden Sie die kostenlose Testversion herunter und legen Sie sofort mit IronPDF los – für die 30-tägige Testphase ist keine Kreditkarte erforderlich. Die Kurzanleitung führt Sie in weniger als fünf Minuten durch die Ersteinrichtung. Wenn Sie bereit für die Produktion sind, prüfen Sie auf der Lizenzierungsseite die Optionen, die zu Ihrer Teamgröße und Ihren Bereitstellungsanforderungen passen.
Für ein tieferes Verständnis empfiehlt sich ein Blick auf die vollständige Tutorialreihe zur Erstellung, Bearbeitung und Manipulation von PDFs. Die API-Referenz bietet eine detaillierte Methodendokumentation, und der Abschnitt "Beispiele" demonstriert praktische Implementierungen, einschließlich Formularverarbeitung und Wasserzeichen .
Häufig gestellte Fragen
Wie kann ich zwei PDF-Dateien mit C# vergleichen?
Sie können zwei PDF-Dateien mit C# vergleichen, indem Sie die leistungsstarke PDF-Vergleichsfunktion von IronPDF nutzen, mit der Sie Unterschiede in Text, Bildern und Layout zwischen zwei PDF-Dokumenten erkennen können.
Welche Vorteile hat der PDF-Vergleich mit IronPDF?
IronPDF bietet einen einfachen und effizienten Weg zum Vergleich von PDF-Dateien und gewährleistet die Genauigkeit bei der Erkennung von Unterschieden. Es unterstützt verschiedene Vergleichsmodi und lässt sich nahtlos in C#-Projekte integrieren.
Kann IronPDF große PDF-Dateien für den Vergleich verarbeiten?
Ja, IronPDF ist für die effiziente Verarbeitung großer PDF-Dateien konzipiert und eignet sich daher für den Vergleich umfangreicher Dokumente ohne Leistungseinbußen.
Unterstützt IronPDF den visuellen Vergleich von PDFs?
IronPDF ermöglicht den visuellen Vergleich von PDFs, indem es Unterschiede im Layout und in den Bildern hervorhebt und einen umfassenden Überblick über die Änderungen zwischen den Dokumenten bietet.
Ist es möglich, den PDF-Vergleich mit IronPDF zu automatisieren?
Ja, Sie können PDF-Vergleichsprozesse mit IronPDF in Ihren C#-Anwendungen automatisieren, was ideal für Szenarien ist, die häufige oder Stapelvergleiche erfordern.
Welche Arten von Unterschieden kann IronPDF in PDF-Dateien erkennen?
IronPDF kann textliche, grafische und Layout-Unterschiede erkennen und so einen gründlichen Vergleich des gesamten Inhalts der PDF-Dateien gewährleisten.
Wie gewährleistet IronPDF die Genauigkeit beim PDF-Vergleich?
IronPDF stellt die Genauigkeit sicher, indem es fortschrittliche Algorithmen einsetzt, um PDF-Inhalte sorgfältig zu vergleichen und so das Risiko zu minimieren, dass subtile Unterschiede übersehen werden.
Kann ich IronPDF mit anderen .NET-Anwendungen für den PDF-Vergleich integrieren?
Ja, IronPDF ist so konzipiert, dass es sich nahtlos in .NET-Anwendungen integrieren lässt, so dass Entwickler PDF-Vergleichsfunktionen in ihre bestehenden Softwarelösungen einbauen können.
Benötige ich Vorkenntnisse im PDF-Vergleich, um IronPDF zu nutzen?
Es sind keine Vorkenntnisse erforderlich. IronPDF bietet benutzerfreundliche Werkzeuge und eine umfassende Dokumentation, die Sie durch den Prozess des PDF-Vergleichs führt, selbst wenn Sie noch keine Erfahrung mit der PDF-Bearbeitung haben.
Gibt es eine Demo- oder Testversion für die IronPDF PDF-Vergleichsfunktion?
Ja, IronPDF bietet eine kostenlose Testversion an, mit der Sie die Funktionen des PDF-Vergleichs erkunden und testen können, bevor Sie sich zum Kauf verpflichten.











