
Convertir JPEG a PDF .NET | IronPDF C# Tutorial
IronPDF ofrece a los desarrolladores de C# una forma sencilla de comparar documentos PDF mediante programación: extrayendo el contenido del texto y analizando las diferencias página por página con solo unas pocas líneas de código. Este tutorial muestra ejemplos prácticos de código para comparaciones básicas, análisis de múltiples documentos, gestión de archivos protegidos con contraseña y generación de informes de comparación formateados en .NET 10.
¿Por qué necesita comparar documentos PDF mediante programación?
Comparar documentos PDF manualmente es lento, propenso a errores y no es escalable. En industrias con gran cantidad de documentos, como las legales, financieras y de salud, los archivos cambian constantemente: los contratos se revisan, las facturas se vuelven a emitir y las presentaciones regulatorias necesitan validación de versiones. La comparación automatizada elimina el cuello de botella humano y ofrece resultados consistentes y auditables en todo momento.
IronPDF le ofrece un enfoque listo para producción para comparar dos archivos PDF en C#. La biblioteca utiliza un motor de renderizado Chrome para la extracción precisa de texto de diseños complejos, y su API completa expone métodos intuitivos para cargar, leer y analizar contenido PDF. Ya sea que esté rastreando cambios de contrato, validando resultados generados o construyendo un sistema de auditoría de documentos, IronPDF se encarga del trabajo pesado.
La biblioteca también es una opción sólida para los equipos que ya utilizan .NET en múltiples plataformas. Es compatible con Windows, Linux, macOS, Docker, Azure y AWS sin requerir rutas de código diferentes para cada destino. Esto lo hace práctico para crear herramientas de comparación que se ejecutan en pipelines CI/CD, así como en aplicaciones de escritorio.
¿Cuándo debería utilizar la comparación automatizada de PDF?
La comparación automatizada se vuelve esencial cuando se trabaja con el control de versiones en flujos de trabajo con gran cantidad de documentos. La revisión manual no es práctica cuando se manejan cientos de archivos diariamente o cuando la precisión es fundamental. Los escenarios comunes incluyen la comparación de facturas en distintos ciclos de facturación, la validación de presentaciones reglamentarias contra plantillas aprobadas, el seguimiento de cambios en las especificaciones técnicas en las distintas versiones de lanzamiento y la auditoría de modificaciones de contratos en flujos de trabajo legales.
Las ganancias de precisión son significativas. Un revisor humano que escanee dos documentos de 50 páginas podría pasar por alto un solo número modificado en una tabla financiera. Una comparación automatizada lo detecta instantáneamente, marca la página y produce un informe de diferencias sin fatiga ni inconsistencia.
¿Cuáles son los principales casos de uso?
La comparación de PDF encuentra aplicaciones en muchas industrias y flujos de trabajo:
- Legal : Realizar un seguimiento de las modificaciones del contrato, verificar el cumplimiento entre el borrador y la versión final y confirmar que solo se realizaron los cambios aprobados antes de la firma.
- Finanzas : validar extractos bancarios, detectar cambios no autorizados en las facturas y confirmar que los informes generados coincidan con los resultados esperados.
- Atención médica : verificar que las presentaciones reglamentarias coincidan con la documentación aprobada y confirmar que los registros de los pacientes no se hayan alterado.
- Garantía de calidad : compare los PDF generados por software con los archivos maestros para detectar regresiones de representación en conjuntos de pruebas automatizadas.
- Documentación : Confirmar la coherencia entre las versiones localizadas de los manuales de usuario y garantizar que la traducción no altere el contenido técnico.
El soporte multiplataforma de IronPDF hace que estas soluciones se puedan implementar en entornos Windows, Linux y en la nube sin modificaciones.
¿Cómo instalar IronPDF en un proyecto .NET ?
Instale IronPDF a través de NuGet usando la Consola del Administrador de paquetes o la CLI de .NET :
Install-Package IronPdf
Para implementaciones de Linux o entornos basados en Docker , consulte la documentación específica de la plataforma. Una vez instalado, configure su clave de licencia si tiene una:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"El desarrollo y las pruebas funcionan sin una clave de licencia, aunque aparecen marcas de agua en los PDF generados. Las implementaciones de producción requieren una licencia válida de la página de licencias . La prueba gratuita proporciona funcionalidad completa para una evaluación de 30 días sin necesidad de tarjeta de crédito.
IronPDF es compatible con .NET Framework 4.6.2+, .NET Core 3.1+ y .NET 5 a .NET 10. Para macOS, son compatibles los procesadores Intel y Apple Silicon. La biblioteca maneja la instalación del motor de renderizado Chrome automáticamente, por lo que no se requiere configuración manual del navegador.
¿Cómo se realiza una comparación básica de PDF?
La base de la comparación de PDF es extraer y comparar el contenido del texto. Las capacidades de extracción de texto de IronPDF proporcionan una recuperación precisa de contenido de prácticamente cualquier diseño de PDF, incluidos documentos de varias columnas, tablas, formularios y PDF escaneados con capas de texto incrustadas. El siguiente ejemplo carga dos archivos, extrae su texto y calcula una puntuación de similitud:
using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}Imports IronPdf
Imports System
' Load two PDF documents
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
' Extract text from both PDFs
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
' Compare the two documents
If text1 = text2 Then
Console.WriteLine("PDF files are identical")
Else
Console.WriteLine("PDFs have differences")
' Calculate character-level similarity
Dim maxLength As Integer = Math.Max(text1.Length, text2.Length)
If maxLength > 0 Then
Dim differences As Integer = 0
Dim minLength As Integer = Math.Min(text1.Length, text2.Length)
For i As Integer = 0 To minLength - 1
If text1(i) <> text2(i) Then differences += 1
Next
differences += Math.Abs(text1.Length - text2.Length)
Dim similarity As Double = 1.0 - CDbl(differences) / maxLength
Console.WriteLine($"Similarity: {similarity:P}")
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}")
End If
End IfEste código utiliza declaraciones de nivel superior y el método ExtractAllText() de IronPDF para extraer el texto completo de ambos archivos y luego realiza una comparación a nivel de caracteres para calcular un porcentaje de similitud. La puntuación le proporciona una medida rápida y cuantitativa de cuán diferentes son los documentos.
El enfoque a nivel de carácter es intencionadamente simple y rápido. Funciona bien cuando se necesita una señal rápida sobre si dos documentos divergieron, como detectar sobrescrituras accidentales o confirmar que una canalización de conversión produjo el resultado esperado. Para escenarios que requieren un análisis más matizado (como identificar qué oraciones cambiaron o rastrear diferencias semánticas), puede aplicar algoritmos de distancia de Levenshtein o de diferenciación sobre las cadenas de texto extraídas.
¿Qué aspecto tienen los archivos PDF de entrada?
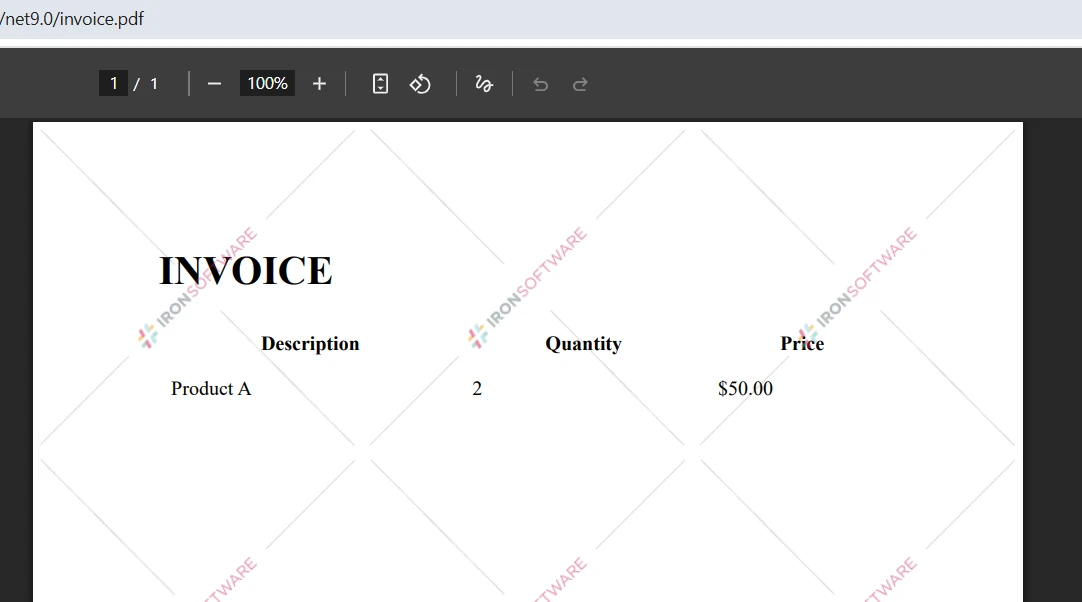
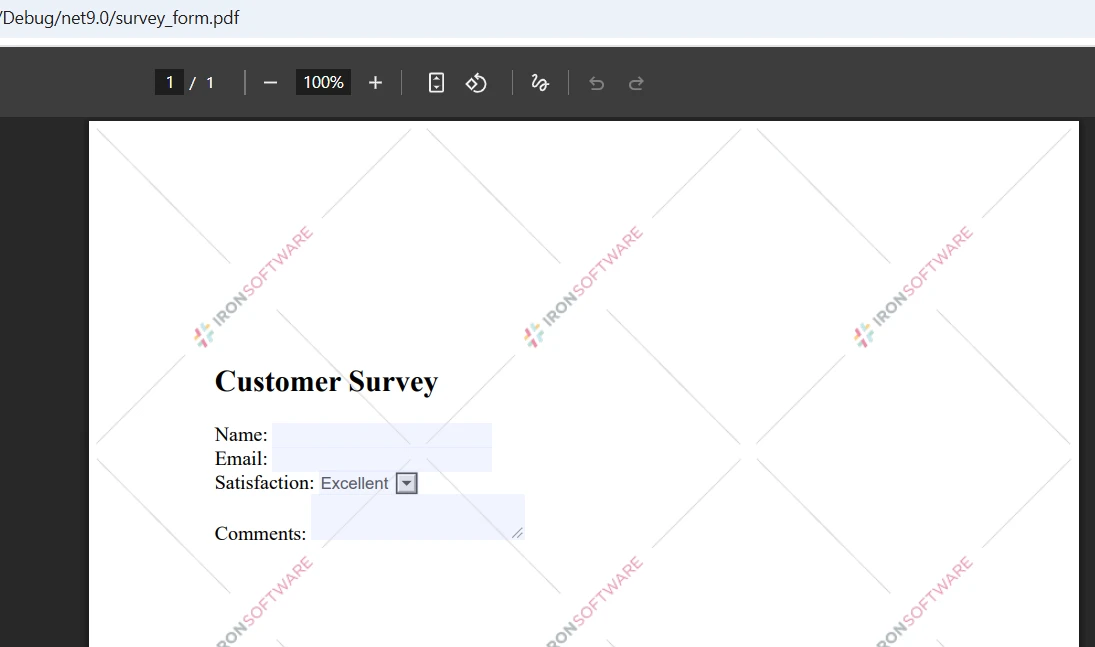
¿Qué muestra el resultado de la comparación?
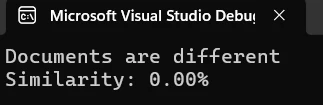
La salida de la consola muestra el porcentaje de similitud entre documentos. Un puntaje de similitud del 2,60%, como se muestra arriba, indica que los dos documentos tienen un contenido casi completamente diferente. Esta métrica le ayuda a evaluar rápidamente el grado de diferencia y decidir los próximos pasos.
¿Cuáles son los límites de la comparación basada sólo en texto?
La comparación de solo texto no captura diferencias de formato, imágenes o diseño. Dos archivos PDF pueden tener texto idéntico pero verse completamente diferentes si uno tiene una fuente, un tamaño de página o una ubicación de imagen diferentes. Para una comparación visual completa, considere combinar las capacidades de extracción de imágenes de IronPDF con una biblioteca de comparación de imágenes. Las funciones de rasterización de IronPDF convierten páginas en imágenes para compararlas píxel por píxel cuando la precisión visual importa más que el contenido del texto.
¿Cómo comparar archivos PDF página por página?
La comparación de documentos completos le indica si dos PDF difieren, pero la comparación página por página le indica exactamente dónde difieren. Esto es especialmente valioso para documentos estructurados como informes, facturas y formularios donde el contenido sigue un diseño predecible en todas las páginas:
using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim maxPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
Dim pageResults = New List(Of (Page As Integer, Similarity As Double))()
For i As Integer = 0 To maxPages - 1
Dim page1Text As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2Text As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If page1Text <> page2Text Then
Dim maxLen As Integer = Math.Max(page1Text.Length, page2Text.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(page1Text.Length - page2Text.Length)) / maxLen)
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}")
pageResults.Add((i + 1, sim))
End If
Next
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}")Este método itera a través de cada página utilizando ExtractTextFromPage(), comparando el contenido individualmente. Este enfoque maneja archivos PDF con diferentes cantidades de páginas sin errores: las páginas que existen en un documento pero no en el otro se tratan como cadenas vacías, lo que las registra correctamente como diferentes.
La comparación página por página es especialmente útil cuando se necesita localizar con precisión las ubicaciones de las modificaciones en documentos grandes. En lugar de revisar un acuerdo legal completo de 200 páginas, obtienes una lista de las cinco páginas que realmente cambiaron. Esto reduce drásticamente el tiempo de revisión y hace que el resultado de la comparación sea procesable.
Para un mejor rendimiento con archivos PDF de gran tamaño, IronPDF admite el procesamiento asincrónico y operaciones paralelas para gestionar comparaciones por lotes de manera eficiente. La guía de optimización del rendimiento cubre técnicas adicionales para operaciones a gran escala, incluidas estrategias de gestión de memoria para procesar muchos archivos grandes en secuencia.
¿Cómo comparar varios documentos PDF a la vez?
La comparación de PDF por lotes con un único documento de referencia es sencilla con IronPDF. El siguiente ejemplo compara cualquier cantidad de archivos con el primer archivo proporcionado y recopila resultados para generar informes:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Module Module1
Sub Main()
Dim pdfPaths As String() = {"reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf"}
If pdfPaths.Length < 2 Then
Console.WriteLine("At least 2 PDFs required for comparison")
Return
End If
Dim referencePdf = PdfDocument.FromFile(pdfPaths(0))
Dim referenceText As String = referencePdf.ExtractAllText()
Dim results As New List(Of (File As String, Similarity As Double, Identical As Boolean))()
For i As Integer = 1 To pdfPaths.Length - 1
Try
Dim currentPdf = PdfDocument.FromFile(pdfPaths(i))
Dim currentText As String = currentPdf.ExtractAllText()
Dim identical As Boolean = (referenceText = currentText)
Dim maxLen As Integer = Math.Max(referenceText.Length, currentText.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(referenceText.Length - currentText.Length)) / maxLen)
results.Add((Path.GetFileName(pdfPaths(i)), similarity, identical))
Dim status As String = If(identical, "identical to reference", $"differs -- similarity: {similarity:P}")
Console.WriteLine($"{Path.GetFileName(pdfPaths(i))}: {status}")
Catch ex As Exception
Console.WriteLine($"Error processing {pdfPaths(i)}: {ex.Message}")
End Try
Next
Console.WriteLine($"\nBatch complete: {results.Count} files compared")
Console.WriteLine($"Identical: {results.FindAll(Function(r) r.Identical).Count}")
Console.WriteLine($"Different: {results.FindAll(Function(r) Not r.Identical).Count}")
End Sub
End ModuleEste enfoque carga el documento de referencia una vez y luego recorre todos los demás archivos comparándolos con él. El bloque try/catch garantiza que un archivo dañado o inaccesible no cancele todo el lote: el error se registra y el procesamiento continúa con el siguiente archivo.
Para lotes muy grandes, considere usar patrones de tareas asincrónicas para cargar y extraer texto de múltiples PDF en paralelo en lugar de secuencialmente. Al seleccionar un documento de referencia, utilice la última versión aprobada para escenarios de control de versiones o la plantilla de salida esperada para flujos de trabajo de control de calidad. También puede automatizar la selección de referencias leyendo metadatos PDF , como fechas de creación y números de versión, incrustados en los propios documentos.
¿Cómo se comparan los PDF protegidos con contraseña?
IronPDF maneja archivos PDF encriptados aceptando la contraseña directamente en la llamada FromFile. No es necesario descifrar archivos externamente antes de cargarlos: la biblioteca se encarga de la autenticación internamente. La biblioteca admite los estándares de cifrado RC4 de 40 bits, RC4 de 128 bits y AES de 128 bits:
using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
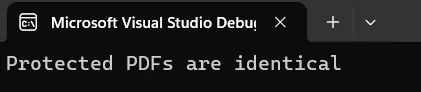
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}Imports IronPdf
Imports System
Try
' Load password-protected PDFs
Dim pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1")
Dim pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2")
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages")
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages")
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
Dim identical As Boolean = text1.Equals(text2)
Dim maxLen As Integer = Math.Max(text1.Length, text2.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(text1.Length - text2.Length)) / maxLen)
Console.WriteLine($"Documents are {(If(identical, "identical", "different"))}")
Console.WriteLine($"Similarity: {similarity:P}")
' Optionally save a secured comparison report
If Not identical Then
Dim renderer = New ChromePdfRenderer()
Dim reportPdf = renderer.RenderHtmlAsPdf($"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>")
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password"
reportPdf.SecuritySettings.UserPassword = "report-user-password"
reportPdf.SecuritySettings.AllowUserPrinting = True
reportPdf.SecuritySettings.AllowUserCopyPasteContent = False
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Secured report saved.")
End If
Catch ex As Exception
Console.WriteLine($"Error handling secured PDFs: {ex.Message}")
End TryAl pasar las contraseñas a FromFile, puede comparar archivos PDF cifrados sin necesidad de descifrarlos previamente. Las funciones de seguridad de IronPDF garantizan el correcto manejo del contenido protegido, y las firmas digitales añaden una capa adicional de verificación de la autenticidad de los documentos.
Al manipular archivos PDF protegidos con contraseña, almacene las credenciales en variables de entorno o en un administrador de secretos en lugar de codificarlas en el código fuente. Implemente prácticas de registro que excluyan información confidencial y agregue lógica de reintento con límites de intentos para evitar escenarios de fuerza bruta. Para necesidades de cifrado avanzadas, la guía de cumplimiento de PDF/UA cubre configuraciones de seguridad que cumplen con la accesibilidad.
¿Cómo se genera un informe de comparación en PDF?
Un informe formateado proporciona a las partes interesadas una visión clara de lo que cambió entre dos documentos. El siguiente ejemplo utiliza la conversión de HTML a PDF de IronPDF para producir un informe con estilo y métricas de diferencia por página:
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Text
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim differences = New List(Of (Page As Integer, Similarity As Double, Len1 As Integer, Len2 As Integer, CharDiff As Integer))()
Dim totalPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
For i As Integer = 0 To totalPages - 1
Dim p1 As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim p2 As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If p1 = p2 Then Continue For
Dim maxLen As Integer = Math.Max(p1.Length, p2.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(p1.Length - p2.Length)) / maxLen)
Dim charDiff As Integer = Math.Abs(p1.Length - p2.Length)
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff))
Next
' Build HTML report
Dim sb = New StringBuilder()
sb.Append("<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>")
sb.Append("<h1>PDF Comparison Report</h1>")
sb.Append("<div class='summary'>")
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>")
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>")
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>")
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>")
sb.Append("</div>")
If differences.Count > 0 Then
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>")
For Each d In differences
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>")
Next
sb.Append("</tbody></table>")
Else
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>")
End If
sb.Append("</body></html>")
Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 25
renderer.RenderingOptions.MarginBottom = 25
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print
Dim reportPdf = renderer.RenderHtmlAsPdf(sb.ToString())
reportPdf.MetaData.Author = "PDF Comparison Tool"
reportPdf.MetaData.Title = "PDF Comparison Report"
reportPdf.MetaData.CreationDate = DateTime.Now
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Report saved to comparison-report.pdf")Esta solución utiliza renderizado HTML para crear informes profesionales con estilo personalizado. La compatibilidad con CSS de IronPDF permite una personalización completa: ajuste fuentes, colores y diseños para que coincidan con la marca corporativa. Agregue encabezados y pies de página con números de página y marcas de tiempo para flujos de trabajo de documentos formales.

El informe generado proporciona un resumen claro de las diferencias con métricas detalladas por página. Puede ampliar el informe para incluir gráficos visuales con puntuaciones de similitud, miniaturas de páginas que muestren áreas modificadas y marcadores para facilitar la navegación en informes extensos. Para informes de calidad de archivo, IronPDF admite el formato PDF/A para garantizar la legibilidad a largo plazo y el cumplimiento de las normas de retención de documentos.
¿Cuáles son las mejores prácticas para la comparación de PDF en .NET?
Antes de enviar una función de comparación de PDF a producción, algunos patrones marcan la diferencia entre un prototipo frágil y una herramienta confiable:
Maneje texto nulo y vacío con elegancia. ExtractAllText() puede devolver una cadena vacía para archivos PDF que solo contienen imágenes o documentos escaneados sin una capa de texto. Verifique siempre si hay resultados vacíos antes de ejecutar la lógica de comparación y decida si vacío versus vacío cuenta como "idéntico" o "indeterminado".
Normalice el texto antes de compararlo. Distintos generadores de PDF pueden producir patrones de espacios en blanco, finales de línea o normalización Unicode ligeramente diferentes para el mismo contenido visual. Ejecutar text.Trim().Replace("\r\n", "\n") antes de la comparación evita falsos positivos debido a diferencias puramente cosméticas.
Utilice umbrales de similitud en lugar de coincidencias exactas para los flujos de trabajo empresariales. Un índice de similitud del 98 % probablemente significa que dos documentos son funcionalmente idénticos, incluso si uno tiene una marca de tiempo o un ID generado automáticamente ligeramente diferente. Defina un umbral apropiado para su dominio en lugar de exigir una igualdad exacta de caracteres.
Resultados de la comparación de registros con metadatos de archivos. Almacene los nombres de archivo, tamaños, fechas de modificación y puntuaciones de similitud en un registro estructurado. Esto crea un registro de auditoría que los equipos de cumplimiento pueden revisar sin tener que volver a ejecutar la comparación.
Considere la codificación y las fuentes. Algunos archivos PDF utilizan tablas de codificación personalizadas para sus capas de texto. El motor basado en Chrome de IronPDF maneja la mayoría de los casos correctamente, pero si ve un texto ilegible, verifique si el PDF de origen usa una codificación de fuente no estándar. La guía de solución de problemas cubre problemas de extracción comunes y sus resoluciones.
Para los equipos que crean canales de comparación de documentos de producción, la documentación de Microsoft sobre patrones asincrónicos en .NET proporciona una guía útil sobre cómo estructurar el procesamiento de archivos en paralelo. También vale la pena revisar la especificación PDF (ISO 32000) si necesita comprender qué tipos de contenido pueden o no aparecer en la capa de texto de un documento determinado.
¿Cómo empezar a realizar comparaciones de PDF hoy mismo?
La comparación de PDF en C# es una habilidad práctica que facilita la automatización de documentos en docenas de industrias, y IronPDF la pone al alcance de cualquier desarrollador .NET . Empiece con el ejemplo básico de extracción de texto, amplíelo al análisis página por página según sea necesario y utilice el generador de informes HTML para ofrecer resultados profesionales a las partes interesadas.
| Scenario | Approach | Key Method |
|---|---|---|
| Comparación de textos básicos | Extraiga el texto completo de ambos documentos y compare cadenas | `ExtractAllText()` |
| Análisis página por página | Compare cada página individualmente para identificar las ubicaciones de los cambios | `ExtractTextFromPage()` |
| Comparación de lotes | Comparar varios archivos con un único documento de referencia | `PdfDocument.FromFile()` |
| Archivos protegidos con contraseña | Pase la contraseña directamente al cargador de archivos (no es necesario descifrarla previamente) | `PdfDocument.FromFile(path, password)` |
| Generación de informes | Convertir un resumen de comparación HTML en un informe PDF con estilo | `ChromePdfRenderer.RenderHtmlAsPdf()` |
Descargue la prueba gratuita para comenzar a construir con IronPDF inmediatamente: no se requiere tarjeta de crédito para la evaluación de 30 días. La guía de inicio rápido explica el proceso de configuración inicial en menos de cinco minutos. Cuando esté listo para la producción, revise la página de licencias para conocer las opciones que se ajusten al tamaño de su equipo y los requisitos de implementación.
Para un aprendizaje más profundo, explore la serie completa de tutoriales que cubre la creación, edición y manipulación de PDF. La referencia de API proporciona documentación detallada de los métodos, y la sección de ejemplos demuestra implementaciones del mundo real, incluido el manejo de formularios y marcas de agua .
Preguntas Frecuentes
¿Cómo puedo comparar dos archivos PDF utilizando C#?
Puede comparar dos archivos PDF utilizando C# mediante la potente función de comparación de PDF de IronPDF, que le permite identificar diferencias en el texto, las imágenes y el diseño entre dos documentos PDF.
¿Cuáles son las ventajas de utilizar IronPDF para la comparación de PDF?
IronPDF ofrece una forma sencilla y eficaz de comparar archivos PDF, garantizando la precisión en la detección de diferencias. Admite varios modos de comparación y se integra a la perfección con proyectos de C#.
¿Puede IronPDF manejar archivos PDF grandes para la comparación?
Sí, IronPDF está diseñado para gestionar eficazmente archivos PDF de gran tamaño, por lo que es adecuado para comparar documentos extensos sin comprometer el rendimiento.
¿Es IronPDF compatible con la comparación visual de PDF?
IronPDF permite la comparación visual de los PDF resaltando las diferencias en el diseño y las imágenes, proporcionando una visión completa de los cambios entre los documentos.
¿Es posible automatizar la comparación de PDF usando IronPDF?
Sí, puede automatizar los procesos de comparación de PDF utilizando IronPDF en sus aplicaciones de C#, lo cual es ideal para escenarios que requieren comparaciones frecuentes o por lotes.
¿Qué tipos de diferencias puede detectar IronPDF en los archivos PDF?
IronPDF puede detectar diferencias textuales, gráficas y de diseño, garantizando una comparación exhaustiva de todo el contenido de los archivos PDF.
¿Cómo garantiza IronPDF la precisión en la comparación de PDF?
IronPDF garantiza la precisión utilizando algoritmos avanzados para comparar meticulosamente el contenido de los PDF, minimizando el riesgo de pasar por alto diferencias sutiles.
¿Puedo integrar IronPDF con otras aplicaciones .NET para la comparación de PDF?
Sí, IronPDF está diseñado para integrarse perfectamente con las aplicaciones .NET, lo que permite a los desarrolladores incorporar la funcionalidad de comparación de PDF en sus soluciones de software existentes.
¿Necesito experiencia previa en comparación de PDF para utilizar IronPDF?
No es necesaria experiencia previa. IronPDF proporciona herramientas fáciles de usar y documentación completa para guiarle a través del proceso de comparación de PDF, incluso si es nuevo en la manipulación de PDF.
¿Hay alguna demostración o prueba disponible para la función de comparación de PDF de IronPDF?
Sí, IronPDF ofrece una versión de prueba gratuita que le permite explorar y probar sus funciones de comparación de PDF antes de comprometerse a una compra.











