
Convert JPEG to PDF .NET | IronPDF C# Tutorial
IronPDF offre aux développeurs C# une méthode simple pour comparer des documents PDF par programmation : extraire le contenu textuel et analyser les différences page par page en quelques lignes de code seulement. Ce tutoriel présente des exemples de code pratiques pour les comparaisons de base, l'analyse de plusieurs documents, la gestion des fichiers protégés par mot de passe et la génération de rapports de comparaison formatés sous .NET 10.
Pourquoi avez-vous besoin de comparer des documents PDF par programmation ?
Comparer manuellement des documents PDF est lent, sujet aux erreurs et n'est pas adaptable à grande échelle. Dans les secteurs où les documents sont omniprésents, comme le droit, la finance et la santé, les fichiers changent constamment : les contrats sont révisés, les factures sont réémises et les documents réglementaires nécessitent une validation de version. La comparaison automatisée élimine le goulot d'étranglement humain et fournit des résultats cohérents et vérifiables à chaque fois.
IronPDF vous offre une approche prête à l'emploi pour comparer deux fichiers PDF en C#. La bibliothèque utilise un moteur de rendu Chrome pour une extraction précise du texte à partir de mises en page complexes, et son API complète expose des méthodes intuitives pour charger, lire et analyser le contenu PDF. Que vous suiviez les modifications contractuelles, validiez les résultats générés ou construisiez un système d'audit documentaire, IronPDF prend en charge les tâches les plus ardues.
Cette bibliothèque constitue également un excellent choix pour les équipes utilisant déjà .NET sur plusieurs plateformes. Il prend en charge Windows, Linux, macOS, Docker, Azure et AWS sans nécessiter de chemins de code différents pour chaque cible. Cela le rend pratique pour la création d'outils de comparaison fonctionnant dans des pipelines CI/CD ainsi que dans des applications de bureau.
Quand faut-il utiliser la comparaison automatisée de PDF ?
La comparaison automatisée devient essentielle lorsqu'il s'agit de gérer le contrôle de version dans des flux de travail comportant de nombreux documents. La vérification manuelle est impraticable lorsqu'il s'agit de traiter des centaines de fichiers par jour ou lorsque la précision est essentielle. Les scénarios courants incluent la comparaison des factures entre les cycles de facturation, la validation des documents réglementaires par rapport aux modèles approuvés, le suivi des modifications des spécifications techniques entre les différentes versions et l'audit des modifications contractuelles dans les flux de travail juridiques.
Les gains de précision sont significatifs. Un examinateur humain qui parcourt deux documents de 50 pages pourrait ne pas remarquer un seul chiffre modifié dans un tableau financier. Une comparaison automatisée la détecte instantanément, signale la page et génère un rapport de différences sans effort ni incohérence.
Quels sont les principaux cas d'utilisation ?
La comparaison de fichiers PDF trouve des applications dans de nombreux secteurs et flux de travail :
- Juridique : Suivre les modifications du contrat, vérifier la conformité entre les versions provisoire et finale, et confirmer que seules les modifications approuvées ont été apportées avant la signature.
- Finance : Valider les relevés bancaires, détecter les modifications non autorisées sur les factures et confirmer que les rapports générés correspondent aux résultats attendus.
- Secteur de la santé : Vérifier que les documents réglementaires correspondent à la documentation approuvée et confirmer que les dossiers des patients n'ont pas été modifiés.
- Assurance qualité : Comparer les PDF générés par logiciel aux fichiers maîtres de référence afin de détecter les régressions de rendu dans les suites de tests automatisées.
- Documentation : Vérifier la cohérence entre les versions localisées des manuels d'utilisation et s'assurer que la traduction n'a pas altéré le contenu technique.
La prise en charge multiplateforme d' IronPDF permet de déployer ces solutions sur les environnements Windows, Linux et cloud sans modification.
Comment installer IronPDF dans un projet .NET ?
Installez IronPDF via NuGet en utilisant soit la console du gestionnaire de packages, soit l'interface de ligne de commande .NET :
Install-Package IronPdf
Pour les déploiements Linux ou les environnements basés sur Docker , veuillez vous référer à la documentation spécifique à la plateforme. Une fois l'installation terminée, configurez votre clé de licence si vous en possédez une :
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Le développement et les tests fonctionnent sans clé de licence, bien que des filigranes apparaissent sur les PDF générés. Les déploiements en production nécessitent une licence valide disponible sur la page des licences . L' essai gratuit offre toutes les fonctionnalités pendant 30 jours pour une évaluation sans nécessiter de carte de crédit.
IronPDF prend en charge .NET Framework 4.6.2+, .NET Core 3.1+ et .NET 5 à .NET 10. Sous macOS, les processeurs Intel et Apple Silicon sont pris en charge. La bibliothèque gère automatiquement l'installation du moteur de rendu Chrome, aucune configuration manuelle du navigateur n'est donc requise.
Comment effectuer une comparaison de PDF de base ?
Le principe de la comparaison de fichiers PDF repose sur l'extraction et la comparaison du contenu textuel. Les capacités d'extraction de texte d'IronPDF permettent une récupération précise du contenu de pratiquement n'importe quelle mise en page PDF, y compris les documents à plusieurs colonnes, les tableaux, les formulaires et les PDF numérisés avec des couches de texte intégrées. L'exemple suivant charge deux fichiers, extrait leur texte et calcule un score de similarité :
using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}using IronPdf;
using System;
// Load two PDF documents
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
// Extract text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
if (text1 == text2)
{
Console.WriteLine("PDF files are identical");
}
else
{
Console.WriteLine("PDFs have differences");
// Calculate character-level similarity
int maxLength = Math.Max(text1.Length, text2.Length);
if (maxLength > 0)
{
int differences = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] != text2[i]) differences++;
}
differences += Math.Abs(text1.Length - text2.Length);
double similarity = 1.0 - (double)differences / maxLength;
Console.WriteLine($"Similarity: {similarity:P}");
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}");
}
}Imports IronPdf
Imports System
' Load two PDF documents
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
' Extract text from both PDFs
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
' Compare the two documents
If text1 = text2 Then
Console.WriteLine("PDF files are identical")
Else
Console.WriteLine("PDFs have differences")
' Calculate character-level similarity
Dim maxLength As Integer = Math.Max(text1.Length, text2.Length)
If maxLength > 0 Then
Dim differences As Integer = 0
Dim minLength As Integer = Math.Min(text1.Length, text2.Length)
For i As Integer = 0 To minLength - 1
If text1(i) <> text2(i) Then differences += 1
Next
differences += Math.Abs(text1.Length - text2.Length)
Dim similarity As Double = 1.0 - CDbl(differences) / maxLength
Console.WriteLine($"Similarity: {similarity:P}")
Console.WriteLine($"Character differences: {Math.Abs(text1.Length - text2.Length)}")
End If
End IfCe code utilise des déclarations de niveau supérieur et la méthode ExtractAllText() d'IronPDF pour extraire le texte complet des deux fichiers, puis effectue une comparaison au niveau des caractères pour calculer un pourcentage de similitude. Le score vous donne une mesure rapide et quantitative du degré de différence entre les documents.
L'approche au niveau des caractères est volontairement simple et rapide. Elle est particulièrement efficace lorsqu'il est nécessaire de détecter rapidement une divergence entre deux documents, par exemple pour repérer des écrasements accidentels ou confirmer qu'un processus de conversion a produit le résultat attendu. Pour les scénarios nécessitant une analyse plus nuancée — comme l'identification des phrases modifiées ou le suivi des différences sémantiques —, vous pouvez superposer des algorithmes de distance de Levenshtein ou de diff aux chaînes de texte extraites.
À quoi ressemblent les fichiers PDF d'entrée ?
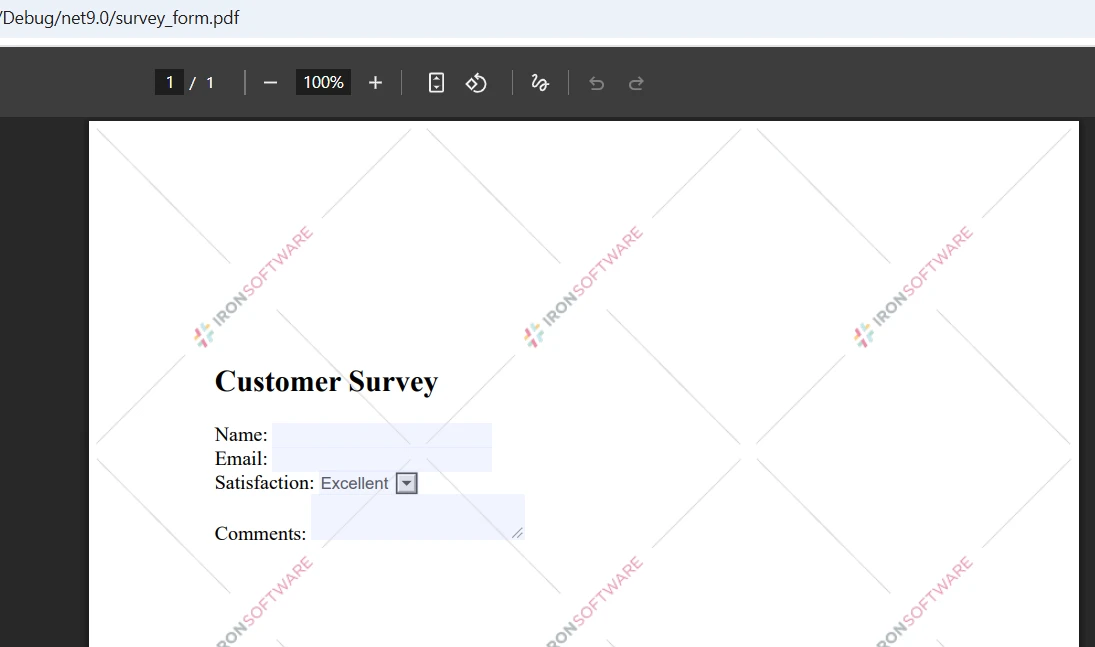
Que montrent les résultats de la comparaison ?
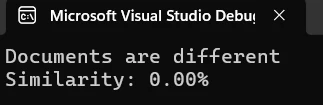
La sortie de la console affiche le pourcentage de similarité entre les documents. Un score de similarité de 2,60 %, comme indiqué ci-dessus, indique que les deux documents ont un contenu presque entièrement différent. Cet indicateur vous permet d'évaluer rapidement l'ampleur de la différence et de décider des prochaines étapes.
Quelles sont les limites de la comparaison textuelle uniquement ?
La comparaison de texte seul ne tient pas compte des différences de mise en forme, d'images ou de disposition. Deux fichiers PDF peuvent avoir un texte identique mais avoir une apparence complètement différente si l'un d'eux utilise une police, un format de page ou un placement d'image différents. Pour une comparaison visuelle complète, envisagez de combiner les capacités d'extraction d'images d'IronPDF avec une bibliothèque de comparaison d'images. Les fonctionnalités de rastérisation d'IronPDF convertissent les pages en images pour une comparaison pixel par pixel lorsque la précision visuelle prime sur le contenu textuel.
Comment comparer des fichiers PDF page par page ?
La comparaison de documents complets vous indique si deux PDF diffèrent, mais la comparaison page par page vous indique précisément où ils diffèrent. Ceci est particulièrement précieux pour les documents structurés tels que les rapports, les factures et les formulaires, où le contenu suit une mise en page prévisible d'une page à l'autre :
using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");using IronPdf;
using System;
using System.Collections.Generic;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
var pageResults = new List<(int Page, double Similarity)>();
for (int i = 0; i < maxPages; i++)
{
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
int maxLen = Math.Max(page1Text.Length, page2Text.Length);
double sim = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(page1Text.Length - page2Text.Length) / maxLen;
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}");
pageResults.Add((i + 1, sim));
}
}
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim maxPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
Dim pageResults = New List(Of (Page As Integer, Similarity As Double))()
For i As Integer = 0 To maxPages - 1
Dim page1Text As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2Text As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If page1Text <> page2Text Then
Dim maxLen As Integer = Math.Max(page1Text.Length, page2Text.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(page1Text.Length - page2Text.Length)) / maxLen)
Console.WriteLine($"Page {i + 1} differs -- similarity: {sim:P}")
pageResults.Add((i + 1, sim))
End If
Next
Console.WriteLine($"\nTotal pages with differences: {pageResults.Count}")Cette méthode parcourt chaque page en utilisant ExtractTextFromPage(), comparant le contenu individuellement. Cette approche permet de gérer les fichiers PDF avec un nombre de pages différent sans erreur : les pages présentes dans un document mais pas dans l'autre sont traitées comme des chaînes vides, ce qui les enregistre correctement comme différentes.
La comparaison page par page est particulièrement utile lorsque vous devez localiser précisément les modifications dans des documents volumineux. Au lieu de devoir examiner un contrat juridique complet de 200 pages, vous recevez une liste des cinq pages qui ont réellement été modifiées. Cela réduit considérablement le temps d'analyse et rend les résultats de la comparaison exploitables.
Pour optimiser les performances avec les fichiers PDF volumineux, IronPDF prend en charge le traitement asynchrone et les opérations parallèles afin de gérer efficacement les comparaisons par lots. Le guide d'optimisation des performances aborde des techniques supplémentaires pour les opérations à grande échelle, notamment des stratégies de gestion de la mémoire pour le traitement séquentiel de nombreux fichiers volumineux.
Comment comparer plusieurs documents PDF simultanément ?
La comparaison par lots de fichiers PDF avec un seul document de référence est simple avec IronPDF. L'exemple suivant compare un nombre quelconque de fichiers au premier fichier fourni, et collecte les résultats pour la création d'un rapport :
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
string[] pdfPaths = { "reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf" };
if (pdfPaths.Length < 2)
{
Console.WriteLine("At least 2 PDFs required for comparison");
return;
}
var referencePdf = PdfDocument.FromFile(pdfPaths[0]);
string referenceText = referencePdf.ExtractAllText();
var results = new List<(string File, double Similarity, bool Identical)>();
for (int i = 1; i < pdfPaths.Length; i++)
{
try
{
var currentPdf = PdfDocument.FromFile(pdfPaths[i]);
string currentText = currentPdf.ExtractAllText();
bool identical = referenceText == currentText;
int maxLen = Math.Max(referenceText.Length, currentText.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(referenceText.Length - currentText.Length) / maxLen;
results.Add((Path.GetFileName(pdfPaths[i]), similarity, identical));
string status = identical ? "identical to reference" : $"differs -- similarity: {similarity:P}";
Console.WriteLine($"{Path.GetFileName(pdfPaths[i])}: {status}");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfPaths[i]}: {ex.Message}");
}
}
Console.WriteLine($"\nBatch complete: {results.Count} files compared");
Console.WriteLine($"Identical: {results.FindAll(r => r.Identical).Count}");
Console.WriteLine($"Different: {results.FindAll(r => !r.Identical).Count}");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Module Module1
Sub Main()
Dim pdfPaths As String() = {"reference.pdf", "version1.pdf", "version2.pdf", "version3.pdf"}
If pdfPaths.Length < 2 Then
Console.WriteLine("At least 2 PDFs required for comparison")
Return
End If
Dim referencePdf = PdfDocument.FromFile(pdfPaths(0))
Dim referenceText As String = referencePdf.ExtractAllText()
Dim results As New List(Of (File As String, Similarity As Double, Identical As Boolean))()
For i As Integer = 1 To pdfPaths.Length - 1
Try
Dim currentPdf = PdfDocument.FromFile(pdfPaths(i))
Dim currentText As String = currentPdf.ExtractAllText()
Dim identical As Boolean = (referenceText = currentText)
Dim maxLen As Integer = Math.Max(referenceText.Length, currentText.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(referenceText.Length - currentText.Length)) / maxLen)
results.Add((Path.GetFileName(pdfPaths(i)), similarity, identical))
Dim status As String = If(identical, "identical to reference", $"differs -- similarity: {similarity:P}")
Console.WriteLine($"{Path.GetFileName(pdfPaths(i))}: {status}")
Catch ex As Exception
Console.WriteLine($"Error processing {pdfPaths(i)}: {ex.Message}")
End Try
Next
Console.WriteLine($"\nBatch complete: {results.Count} files compared")
Console.WriteLine($"Identical: {results.FindAll(Function(r) r.Identical).Count}")
Console.WriteLine($"Different: {results.FindAll(Function(r) Not r.Identical).Count}")
End Sub
End ModuleCette approche charge le document de référence une seule fois, puis parcourt tous les autres fichiers en les comparant à celui-ci. Le bloc try/catch garantit qu'un fichier corrompu ou inaccessible n'interrompt pas le traitement par lots entier : l'erreur est consignée et le traitement se poursuit avec le fichier suivant.
Pour les très grands lots, envisagez d'utiliser des modèles de tâches asynchrones pour charger et extraire le texte de plusieurs fichiers PDF en parallèle plutôt que séquentiellement. Lors du choix d'un document de référence, utilisez la dernière version approuvée pour les scénarios de contrôle de version, ou le modèle de sortie attendu pour les flux de travail d'assurance qualité. Vous pouvez également automatiser la sélection des références en lisant les métadonnées PDF telles que les dates de création et les numéros de version intégrés aux documents eux-mêmes.
Comment comparer les PDF protégés par mot de passe ?
IronPDF gère les PDFs cryptés en acceptant le mot de passe directement dans l'appel FromFile. Il n'est pas nécessaire de déchiffrer les fichiers en externe avant de les charger : la bibliothèque gère l'authentification en interne. La bibliothèque prend en charge les normes de chiffrement RC4 40 bits, RC4 128 bits et AES 128 bits :
using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}using IronPdf;
using System;
try
{
// Load password-protected PDFs
var pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1");
var pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2");
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages");
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages");
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool identical = text1.Equals(text2);
int maxLen = Math.Max(text1.Length, text2.Length);
double similarity = maxLen == 0 ? 1.0
: 1.0 - (double)Math.Abs(text1.Length - text2.Length) / maxLen;
Console.WriteLine($"Documents are {(identical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:P}");
// Optionally save a secured comparison report
if (!identical)
{
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(
$"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>");
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password";
reportPdf.SecuritySettings.UserPassword = "report-user-password";
reportPdf.SecuritySettings.AllowUserPrinting = true;
reportPdf.SecuritySettings.AllowUserCopyPasteContent = false;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Secured report saved.");
}
}
catch (Exception ex)
{
Console.WriteLine($"Error handling secured PDFs: {ex.Message}");
}Imports IronPdf
Imports System
Try
' Load password-protected PDFs
Dim pdf1 = PdfDocument.FromFile("secure-document1.pdf", "password1")
Dim pdf2 = PdfDocument.FromFile("secure-document2.pdf", "password2")
Console.WriteLine($"PDF 1 loaded: {pdf1.PageCount} pages")
Console.WriteLine($"PDF 2 loaded: {pdf2.PageCount} pages")
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
Dim identical As Boolean = text1.Equals(text2)
Dim maxLen As Integer = Math.Max(text1.Length, text2.Length)
Dim similarity As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(text1.Length - text2.Length)) / maxLen)
Console.WriteLine($"Documents are {(If(identical, "identical", "different"))}")
Console.WriteLine($"Similarity: {similarity:P}")
' Optionally save a secured comparison report
If Not identical Then
Dim renderer = New ChromePdfRenderer()
Dim reportPdf = renderer.RenderHtmlAsPdf($"<h1>Comparison Result</h1><p>Similarity: {similarity:P}</p>")
reportPdf.SecuritySettings.OwnerPassword = "report-owner-password"
reportPdf.SecuritySettings.UserPassword = "report-user-password"
reportPdf.SecuritySettings.AllowUserPrinting = True
reportPdf.SecuritySettings.AllowUserCopyPasteContent = False
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Secured report saved.")
End If
Catch ex As Exception
Console.WriteLine($"Error handling secured PDFs: {ex.Message}")
End TryEn transmettant des mots de passe à FromFile, vous pouvez comparer des PDFs cryptés sans aucune étape de pré-déchiffrement. Les fonctionnalités de sécurité d'IronPDF assurent une gestion appropriée du contenu protégé, et les signatures numériques ajoutent une couche supplémentaire de vérification de l'authenticité du document.
Lors de la manipulation de fichiers PDF protégés par mot de passe, stockez les identifiants dans des variables d'environnement ou un gestionnaire de secrets plutôt que de les intégrer directement dans le code source. Mettez en œuvre des pratiques de journalisation excluant les informations sensibles et ajoutez une logique de nouvelle tentative avec des limites de tentatives pour empêcher les attaques par force brute. Pour les besoins de chiffrement avancés, le guide de conformité PDF/UA couvre les configurations de sécurité conformes aux normes d'accessibilité.
Comment générer un rapport comparatif PDF ?
Un rapport formaté offre aux parties prenantes une vision claire des changements intervenus entre deux documents. L'exemple suivant utilise la conversion HTML vers PDF d'IronPDF pour produire un rapport stylisé avec des indicateurs de différence par page :
using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
var pdf1 = PdfDocument.FromFile("document1.pdf");
var pdf2 = PdfDocument.FromFile("document2.pdf");
var differences = new List<(int Page, double Similarity, int Len1, int Len2, int CharDiff)>();
int totalPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
for (int i = 0; i < totalPages; i++)
{
string p1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) ?? "" : "";
string p2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) ?? "" : "";
if (p1 == p2) continue;
int maxLen = Math.Max(p1.Length, p2.Length);
double sim = maxLen == 0 ? 1.0 : 1.0 - (double)Math.Abs(p1.Length - p2.Length) / maxLen;
int charDiff = Math.Abs(p1.Length - p2.Length);
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff));
}
// Build HTML report
var sb = new StringBuilder();
sb.Append(@"<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>");
sb.Append("<h1>PDF Comparison Report</h1>");
sb.Append("<div class='summary'>");
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>");
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>");
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>");
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>");
sb.Append("</div>");
if (differences.Count > 0)
{
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>");
foreach (var d in differences)
{
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>");
}
sb.Append("</tbody></table>");
}
else
{
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>");
}
sb.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.MarginTop = 25;
renderer.RenderingOptions.MarginBottom = 25;
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print;
var reportPdf = renderer.RenderHtmlAsPdf(sb.ToString());
reportPdf.MetaData.Author = "PDF Comparison Tool";
reportPdf.MetaData.Title = "PDF Comparison Report";
reportPdf.MetaData.CreationDate = DateTime.Now;
reportPdf.SaveAs("comparison-report.pdf");
Console.WriteLine("Report saved to comparison-report.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Text
Dim pdf1 = PdfDocument.FromFile("document1.pdf")
Dim pdf2 = PdfDocument.FromFile("document2.pdf")
Dim differences = New List(Of (Page As Integer, Similarity As Double, Len1 As Integer, Len2 As Integer, CharDiff As Integer))()
Dim totalPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
For i As Integer = 0 To totalPages - 1
Dim p1 As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim p2 As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If p1 = p2 Then Continue For
Dim maxLen As Integer = Math.Max(p1.Length, p2.Length)
Dim sim As Double = If(maxLen = 0, 1.0, 1.0 - CDbl(Math.Abs(p1.Length - p2.Length)) / maxLen)
Dim charDiff As Integer = Math.Abs(p1.Length - p2.Length)
differences.Add((i + 1, sim, p1.Length, p2.Length, charDiff))
Next
' Build HTML report
Dim sb = New StringBuilder()
sb.Append("<html><head><style>
body { font-family: Arial, sans-serif; margin: 20px; }
h1 { color: #333; border-bottom: 2px solid #4CAF50; }
.summary { background: #f0f0f0; padding: 15px; border-radius: 5px; margin-bottom: 20px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background: #4CAF50; color: white; }
.ok { background: #c8e6c9; padding: 15px; border-radius: 5px; }
</style></head><body>")
sb.Append("<h1>PDF Comparison Report</h1>")
sb.Append("<div class='summary'>")
sb.Append($"<p><strong>File 1:</strong> {Path.GetFileName("document1.pdf")}</p>")
sb.Append($"<p><strong>File 2:</strong> {Path.GetFileName("document2.pdf")}</p>")
sb.Append($"<p><strong>Pages with differences:</strong> {differences.Count} of {totalPages}</p>")
sb.Append($"<p><strong>Generated:</strong> {DateTime.Now:yyyy-MM-dd HH:mm:ss}</p>")
sb.Append("</div>")
If differences.Count > 0 Then
sb.Append("<table><thead><tr><th>Page</th><th>Similarity</th><th>File 1 Length</th><th>File 2 Length</th><th>Char Diff</th></tr></thead><tbody>")
For Each d In differences
sb.Append($"<tr><td>{d.Page}</td><td>{d.Similarity:P}</td><td>{d.Len1}</td><td>{d.Len2}</td><td>{d.CharDiff}</td></tr>")
Next
sb.Append("</tbody></table>")
Else
sb.Append("<p class='ok'>No differences detected -- files are identical.</p>")
End If
sb.Append("</body></html>")
Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 25
renderer.RenderingOptions.MarginBottom = 25
renderer.RenderingOptions.CssMediaType = IronPdf.Rendering.PdfCssMediaType.Print
Dim reportPdf = renderer.RenderHtmlAsPdf(sb.ToString())
reportPdf.MetaData.Author = "PDF Comparison Tool"
reportPdf.MetaData.Title = "PDF Comparison Report"
reportPdf.MetaData.CreationDate = DateTime.Now
reportPdf.SaveAs("comparison-report.pdf")
Console.WriteLine("Report saved to comparison-report.pdf")Cette solution utilise le rendu HTML pour créer des rapports Professional avec un style personnalisé. La prise en charge CSS d'IronPDF permet une personnalisation complète : ajustez les polices, les couleurs et les mises en page pour qu'elles correspondent à l'image de marque de votre entreprise. Ajoutez des en-têtes et des pieds de page avec numéros de page et horodatages pour les flux de travail documentaires formels.

Le rapport généré fournit un résumé clair des différences, avec des indicateurs détaillés par page. Vous pouvez étendre le rapport pour y inclure des graphiques visuels pour les scores de similarité, des vignettes de pages montrant les zones modifiées et des signets pour faciliter la navigation dans les rapports volumineux. Pour les rapports destinés à l'archivage, IronPDF prend en charge le format PDF/A afin de garantir une lisibilité à long terme et la conformité aux réglementations en matière de conservation des documents.
Quelles sont les meilleures pratiques pour la comparaison de fichiers PDF en .NET?
Avant de déployer une fonctionnalité de comparaison de PDF en production, quelques principes permettent de faire la différence entre un prototype fragile et un outil fiable :
Gérer le texte nul et vide avec élégance. ExtractAllText() peut renvoyer une chaîne vide pour les PDFs uniquement image ou les documents scannés sans couche de texte. Vérifiez toujours l'absence de résultats vides avant d'exécuter la logique de comparaison, et déterminez si deux résultats vides sont considérés comme " identiques " ou " indéterminés ".
Normalisez le texte avant toute comparaison. Différents générateurs de PDF peuvent produire des différences mineures au niveau des espaces, des fins de ligne ou de la normalisation Unicode pour un même contenu visuel. Exécuter text.Trim().Replace("\r\n", "\n") avant la comparaison évite les faux positifs dus à des différences purement cosmétiques.
Pour les processus métier, privilégiez les seuils de similarité aux correspondances exactes. Un score de similarité de 98 % indique probablement que deux documents sont fonctionnellement identiques, même si l'un d'eux présente une légère différence d'horodatage ou d'identifiant généré automatiquement. Définissez un seuil adapté à votre domaine plutôt que d'exiger une égalité exacte des caractères.
Consignez les résultats de la comparaison avec les métadonnées des fichiers. Stockez les noms de fichiers, leurs tailles, leurs dates de modification et leurs scores de similarité dans un journal structuré. Cela crée une piste d'audit que les équipes de conformité peuvent consulter sans avoir à relancer la comparaison.
Tenez compte des problèmes d'encodage et de police. Certains fichiers PDF utilisent des tables d'encodage personnalisées pour leurs couches de texte. Le moteur d'IronPDF basé sur Chrome gère correctement la plupart des cas, mais si vous constatez un rendu de texte illisible, vérifiez si le PDF source utilise un encodage de police non standard. Le guide de dépannage couvre les problèmes d'extraction courants et leurs solutions.
Pour les équipes qui développent des pipelines de comparaison de documents de production, la documentation Microsoft sur les modèles asynchrones dans .NET fournit des conseils utiles sur la structuration du traitement parallèle des fichiers. Il est également utile de consulter la spécification PDF (ISO 32000) si vous avez besoin de comprendre quels types de contenu peuvent ou non apparaître dans la couche texte d'un document donné.
Comment débuter dès aujourd'hui avec la comparaison de PDF ?
La comparaison de PDF en C# est une compétence pratique qui ouvre la voie à l'automatisation des documents dans de nombreux secteurs d'activité, et IronPDF la rend accessible à tout développeur .NET . Commencez par l'exemple d'extraction de texte de base, étendez-le à une analyse page par page si nécessaire, et utilisez le générateur de rapports HTML pour fournir un résultat Professional aux parties prenantes.
| Scénario | Approche | Méthode clé |
|---|---|---|
| Comparaison de textes de base | Extraire le texte intégral des deux documents et comparer les chaînes de caractères. | ExtractAllText() |
| Analyse page par page | Comparez chaque page individuellement pour repérer les emplacements des modifications. | ExtractTextFromPage() |
| Comparaison par lots | Comparer plusieurs fichiers à un seul document de référence | PdfDocument.FromFile() |
| Fichiers protégés par mot de passe | Transmettez le mot de passe directement au chargeur de fichiers ; aucun déchiffrement préalable n'est nécessaire. | PdfDocument.FromFile(chemin, mot de passe) |
| Génération de rapports | Convertir un résumé comparatif HTML en un rapport PDF stylisé | ChromePdfRenderer.RenderHtmlAsPdf() |
Téléchargez la version d'essai gratuite pour commencer à créer des documents avec IronPDF immédiatement – aucune carte de crédit n'est requise pour l'évaluation de 30 jours. Le guide de démarrage rapide explique la configuration initiale en moins de cinq minutes. Lorsque vous serez prêt pour la production, consultez la page des licences pour connaître les options qui correspondent à la taille de votre équipe et à vos exigences de déploiement.
Pour approfondir vos connaissances, explorez la série complète de tutoriels couvrant la création, l'édition et la manipulation de fichiers PDF. La documentation de référence de l'API fournit une documentation détaillée des méthodes, et la section des exemples présente des implémentations concrètes, notamment la gestion des formulaires et le tatouage numérique .
Questions Fréquemment Posées
Comment comparer deux fichiers PDF à l'aide de C# ?
Vous pouvez comparer deux fichiers PDF à l'aide de C# en utilisant la puissante fonction de comparaison de PDF d'IronPDF, qui vous permet d'identifier les différences de texte, d'images et de mise en page entre deux documents PDF.
Quels sont les avantages de l'utilisation d'IronPDF pour la comparaison de PDF ?
IronPDF offre un moyen simple et efficace de comparer des fichiers PDF, en garantissant la précision de la détection des différences. Il prend en charge différents modes de comparaison et s'intègre parfaitement aux projets C#.
IronPDF peut-il gérer de gros fichiers PDF pour la comparaison ?
Oui, IronPDF est conçu pour traiter efficacement les fichiers PDF volumineux, ce qui le rend adapté à la comparaison de documents étendus sans compromettre les performances.
IronPDF prend-il en charge la comparaison visuelle des PDF ?
IronPDF permet de comparer visuellement les PDF en mettant en évidence les différences de mise en page et d'images, offrant ainsi une vue d'ensemble des changements entre les documents.
Est-il possible d'automatiser la comparaison de PDF avec IronPDF ?
Oui, vous pouvez automatiser les processus de comparaison de PDF à l'aide d'IronPDF dans vos applications C#, ce qui est idéal pour les scénarios nécessitant des comparaisons fréquentes ou par lots.
Quels types de différences IronPDF peut-il détecter dans les fichiers PDF ?
IronPDF peut détecter les différences textuelles, graphiques et de mise en page, garantissant ainsi une comparaison approfondie de l'ensemble du contenu des fichiers PDF.
Comment IronPDF assure-t-il la précision de la comparaison des PDF ?
IronPDF garantit la précision en utilisant des algorithmes avancés pour comparer méticuleusement le contenu des PDF, minimisant ainsi le risque de négliger des différences subtiles.
Puis-je intégrer IronPDF à d'autres applications .NET pour la comparaison de PDF ?
Oui, IronPDF est conçu pour s'intégrer de manière transparente aux applications .NET, ce qui permet aux développeurs d'incorporer la fonctionnalité de comparaison de PDF dans leurs solutions logicielles existantes.
Dois-je avoir une expérience préalable de la comparaison de PDF pour utiliser IronPDF ?
Aucune expérience préalable n'est nécessaire. IronPDF fournit des outils conviviaux et une documentation complète pour vous guider dans le processus de comparaison des PDF, même si vous êtes novice en matière de manipulation des PDF.
Existe-t-il une démo ou une version d'essai de la fonction de comparaison de PDF d'IronPDF ?
Oui, IronPDF propose un essai gratuit qui vous permet d'explorer et de tester ses fonctionnalités de comparaison de PDF avant de vous engager dans un achat.











