
Jak znaleźć tekst w PDF w C#
Wprowadzenie do wyszukiwania tekstu w plikach PDF za pomocą C
Wyszukiwanie tekstu w pliku PDF może być trudnym zadaniem, zwłaszcza w przypadku plików statycznych, których nie da się łatwo edytować ani przeszukiwać. Niezależnie od tego, czy automatyzujesz przepływ dokumentów, tworzysz funkcję wyszukiwania, chcesz wyróżnić tekst odpowiadający kryteriom wyszukiwania, czy też wyodrębniasz dane, ekstrakcja tekstu jest kluczową funkcją dla programistów.
IronPDF, potężna biblioteka .NET, upraszcza ten proces, umożliwiając programistom wydajne wyszukiwanie i wyodrębnianie tekstu z plików PDF. W tym artykule omówimy, jak używać IronPDF do wyszukiwania tekstu w pliku PDF za pomocą języka C#, wraz z przykładami kodu i praktycznymi zastosowaniami.
Czym jest "Find Text" w języku C#?
"Wyszukiwanie tekstu" odnosi się do procesu wyszukiwania określonego tekstu lub wzorców w dokumencie, pliku lub innych strukturach danych. W kontekście plików PDF polega to na identyfikacji i lokalizacji wystąpień określonych słów, fraz lub wzorców w treści tekstowej dokumentu PDF. Ta funkcjonalność jest niezbędna w wielu aplikacjach w różnych branżach, zwłaszcza w przypadku danych nieustrukturyzowanych lub częściowo ustrukturyzowanych przechowywanych w formacie PDF.
Rozumienie tekstu w plikach PDF
Pliki PDF są zaprojektowane tak, aby prezentować treść w spójnym formacie, niezależnym od urządzenia. Jednak sposób przechowywania tekstu w plikach PDF może się znacznie różnić. Tekst może być zapisany jako:
- Tekst przeszukiwalny: Tekst, który można bezpośrednio wyodrębnić, ponieważ jest osadzony jako tekst (np. z dokumentu WORD przekonwertowanego do formatu PDF).
- Tekst zeskanowany: Tekst wyświetlany jako obraz, który wymaga zastosowania OCR (optycznego rozpoznawania znaków) w celu przekształcenia go w tekst, który można przeszukiwać.
- Złożone układy: Tekst przechowywany w fragmentach lub z nietypowym kodowaniem, co utrudnia jego dokładne wyodrębnianie i wyszukiwanie.
Ta zmienność oznacza, że skuteczne wyszukiwanie tekstu w plikach PDF często wymaga specjalistycznych bibliotek, takich jak IronPDF, które mogą płynnie obsługiwać różnorodne typy treści.
Dlaczego wyszukiwanie tekstu jest ważne?
Możliwość wyszukiwania tekstu w plikach PDF ma szeroki zakres zastosowań, w tym:
-
Automatyzacja przepływów pracy: Automatyzacja zadań, takich jak przetwarzanie faktur, umów lub raportów poprzez identyfikację kluczowych terminów lub wartości w dokumentach PDF.
-
Pobieranie danych: Pobieranie informacji do wykorzystania w innych systemach lub do analizy.
-
Weryfikacja treści: Upewnienie się, że w dokumentach znajdują się wymagane terminy lub frazy, takie jak oświadczenia o zgodności lub klauzule prawne.
- Poprawa komfortu użytkowania: Włączenie funkcji wyszukiwania w systemach zarządzania dokumentami, pomagającej użytkownikom w szybkim odnajdywaniu istotnych informacji.
Wyzwania związane z wyszukiwaniem tekstowym
Wyszukiwanie tekstu w plikach PDF nie zawsze jest proste ze względu na następujące wyzwania:
- Różnice w kodowaniu: Niektóre pliki PDF wykorzystują niestandardowe kodowanie tekstu, co utrudnia jego wyodrębnianie.
- Tekst podzielony na fragmenty: Tekst może być podzielony na wiele części, co utrudnia wyszukiwanie.
- Grafika i obrazy: Tekst osadzony w obrazach wymaga zastosowania OCR w celu wyodrębnienia.
- Obsługa wielu języków: Wyszukiwanie w dokumentach w różnych językach, alfabetach lub z tekstem pisanym od prawej do lewej wymaga solidnego rozwiązania.
Dlaczego warto wybrać IronPDF do ekstrakcji tekstu?
IronPDF został zaprojektowany tak, aby obsługa plików PDF była jak najbardziej płynna dla programistów pracujących w ekosystemie .NET. Oferuje Suite funkcji dostosowanych do usprawnienia procesów pozyskiwania i przetwarzania tekstu.
Kluczowe korzyści
-
Łatwość użytkowania:
IronPDF oferuje intuicyjny interfejs API, który pozwala programistom szybko rozpocząć pracę bez konieczności przechodzenia przez stromy proces nauki. Niezależnie od tego, czy wykonujesz podstawowe wyodrębnianie tekstu, konwersję HTML do PDF, czy zaawansowane operacje, metody tej biblioteki są proste w użyciu.
-
Wysoka dokładność:
W przeciwieństwie do niektórych bibliotek PDF, które mają trudności z plikami PDF zawierającymi złożone układy lub osadzone czcionki, IronPDF niezawodnie i precyzyjnie wyodrębnia tekst.
-
Obsługa wielu platform:
IronPDF jest kompatybilny zarówno z .NET Framework, jak i .NET Core, co gwarantuje programistom możliwość korzystania z niego w nowoczesnych aplikacjach internetowych, aplikacjach desktopowych, a nawet w starszych systemach.
-
Obsługa zaawansowanych zapytań:
Biblioteka obsługuje zaawansowane techniki wyszukiwania, takie jak wyrażenia regularne i ukierunkowane wyodrębnianie, dzięki czemu nadaje się do złożonych zastosowań, takich jak eksploracja danych lub indeksowanie dokumentów.
Konfiguracja IronPDF w projekcie
IronPDF jest dostępny za pośrednictwem NuGet, co ułatwia dodanie go do projektów .NET. Oto jak zacząć.
Instalacja
Aby zainstalować IronPDF, użyj menedżera pakietów NuGet w Visual Studio lub uruchom następujące polecenie w konsoli menedżera pakietów:
Install-Package IronPdfInstall-Package IronPdfSpowoduje to pobranie i zainstalowanie biblioteki wraz z jej zależnościami.
Podstawowa konfiguracja
Po zainstalowaniu biblioteki należy dołączyć ją do projektu poprzez odwołanie się do przestrzeni nazw IronPDF. Dodaj następujący wiersz na początku pliku kodu:
using IronPdf;using IronPdf;Imports IronPdfPrzykład kodu: Wyszukiwanie tekstu w pliku PDF
IronPDF upraszcza proces wyszukiwania tekstu w dokumencie PDF. Poniżej znajduje się szczegółowa instrukcja, jak to osiągnąć.
Ładowanie pliku PDF
Pierwszym krokiem jest załadowanie pliku PDF, nad którym chcesz pracować. Odbywa się to przy użyciu klasy PdfDocument, jak widać w poniższym kodzie:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")Klasa PdfDocument reprezentuje plik PDF w pamięci, umożliwiając wykonywanie różnych operacji, takich jak wyodrębnianie tekstu lub modyfikowanie treści. Po załadowaniu pliku PDF możemy przeszukiwać tekst z całego dokumentu PDF lub konkretnej strony w pliku.
Wyszukiwanie konkretnego tekstu
Po załadowaniu pliku PDF użyj metody ExtractAllText(), aby wyodrębnić treść tekstową całego dokumentu. Następnie można wyszukiwać konkretne terminy przy użyciu standardowych technik manipulacji ciągami znaków:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
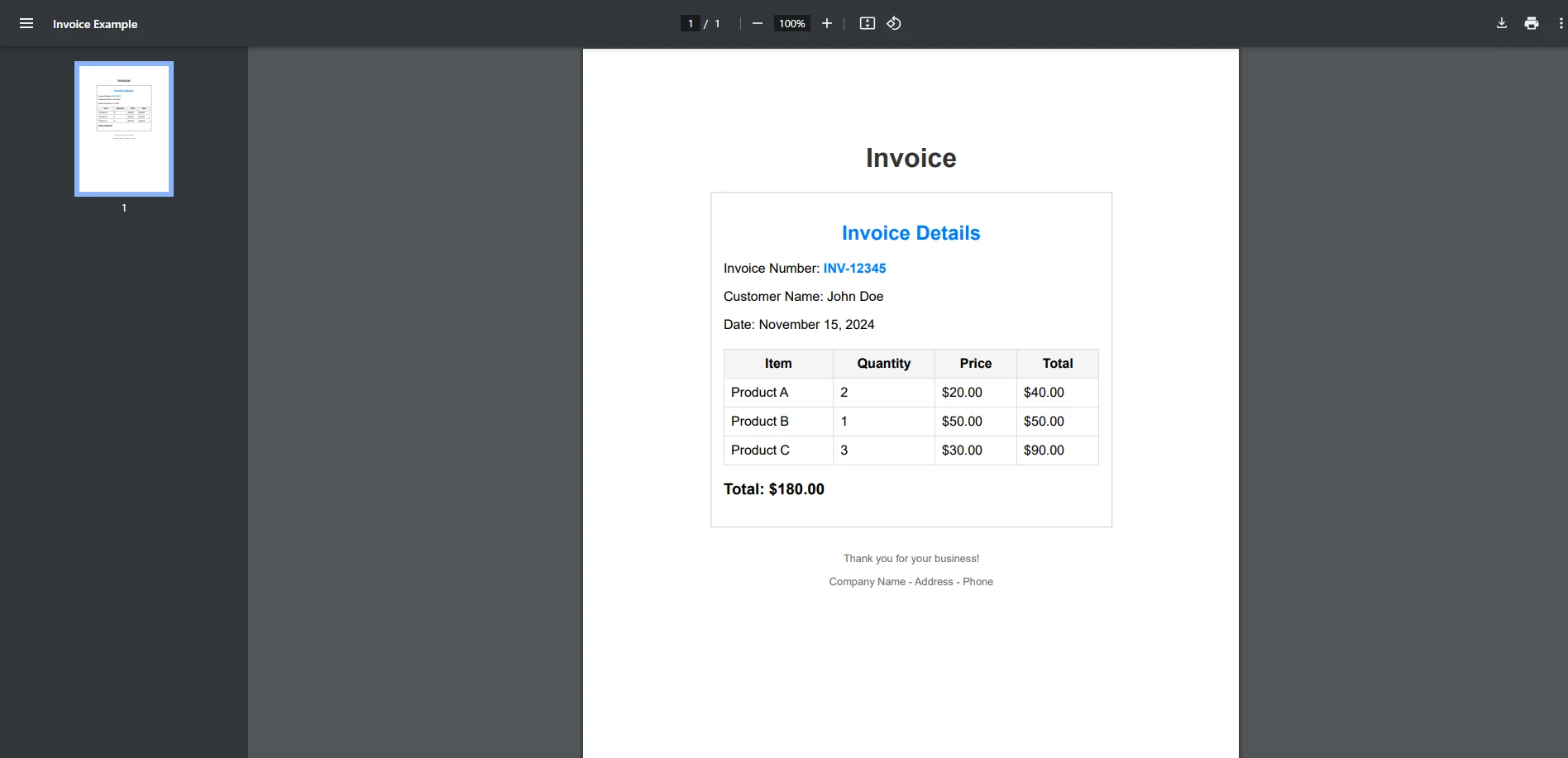
End ClassPlik wejściowy PDF
Wynik konsoli
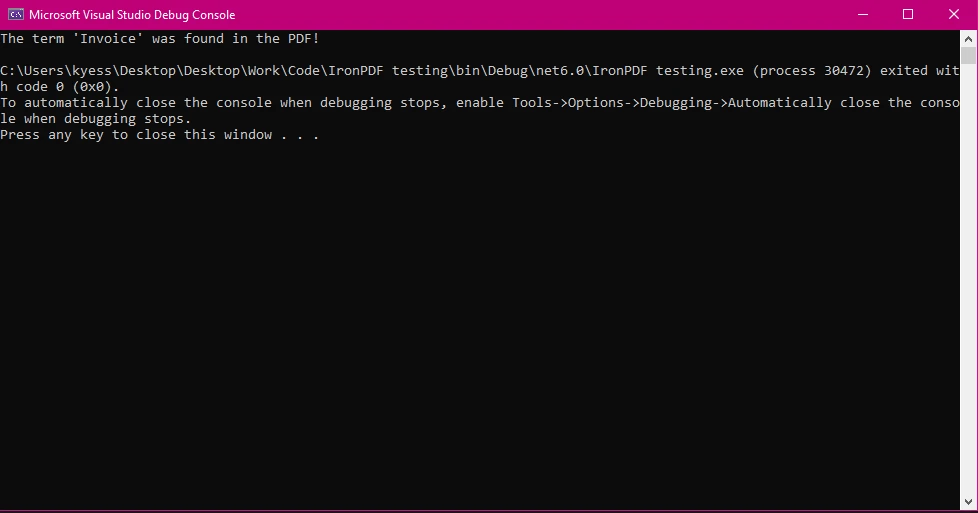
Ten przykład pokazuje prosty przypadek, w którym sprawdzasz, czy termin występuje w pliku PDF. StringComparison.OrdinalIgnoreCase gwarantuje, że wyszukiwany tekst nie rozróżnia wielkości liter.
Zaawansowane funkcje wyszukiwania tekstu
IronPDF oferuje kilka zaawansowanych funkcji, które rozszerzają jego możliwości wyszukiwania tekstu.
Korzystanie z wyrażeń regularnych
Wyrażenia regularne to potężne narzędzie do wyszukiwania wzorców w tekście. Na przykład, możesz chcieć znaleźć wszystkie adresy e-mail w pliku PDF:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
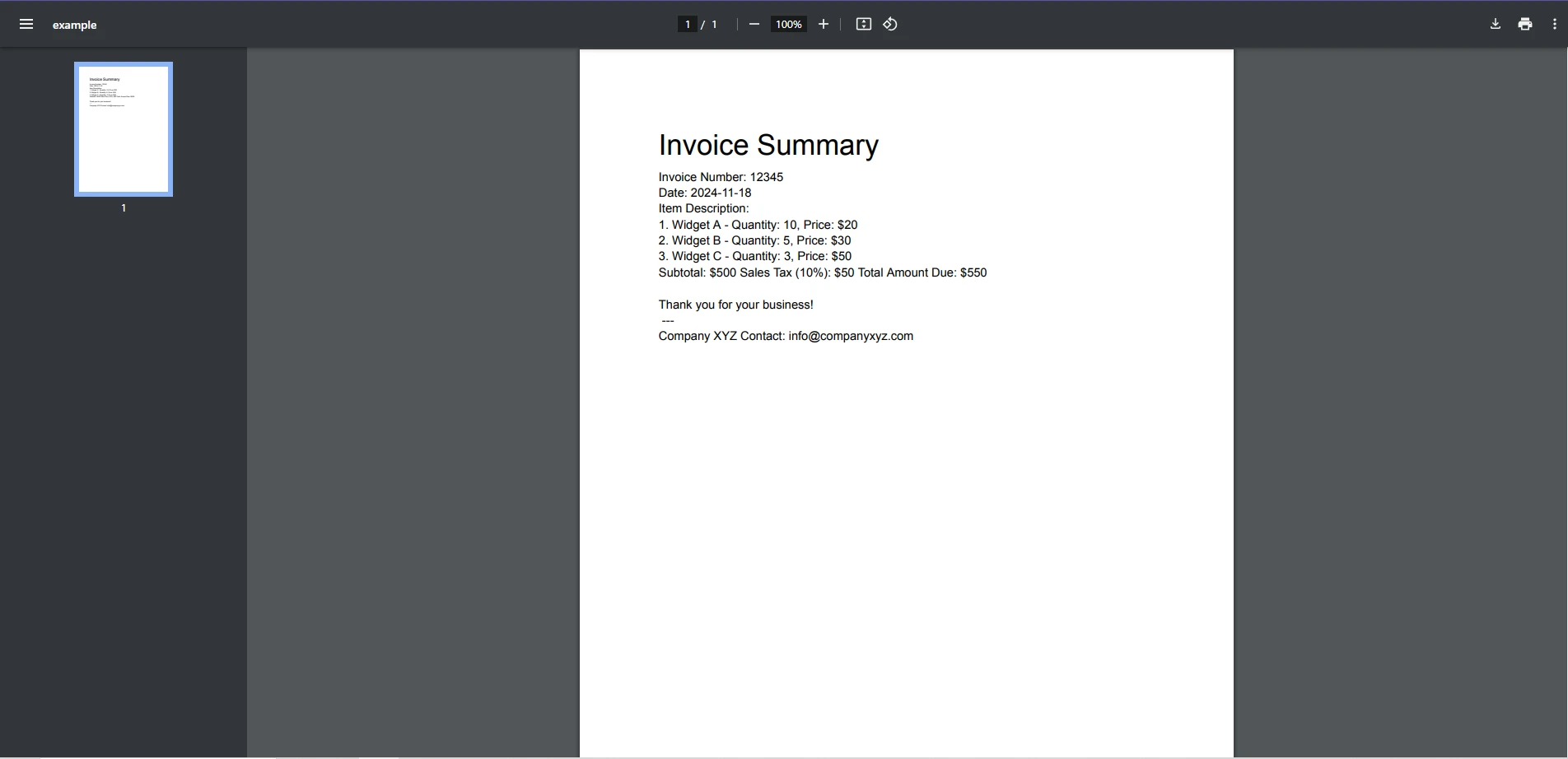
Next matchPlik wejściowy PDF
Wynik konsoli
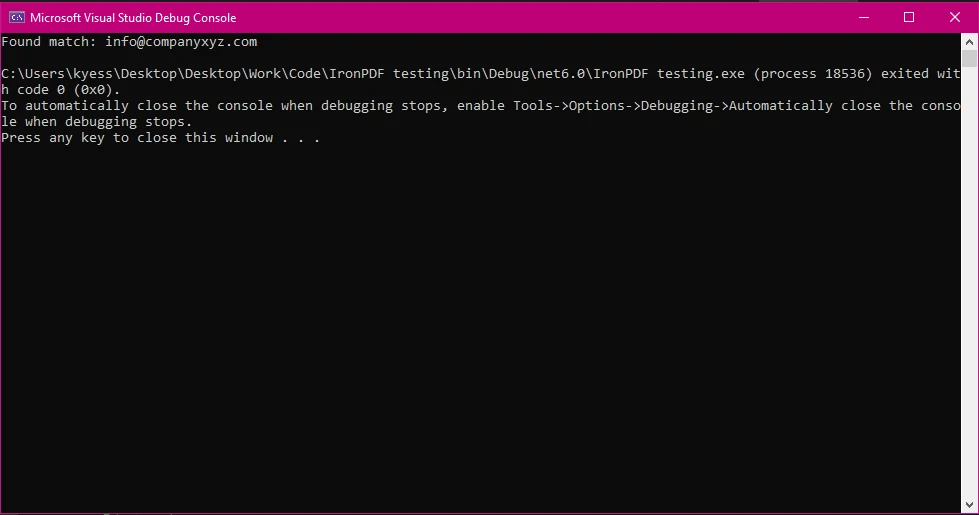
W tym przykładzie użyto wzorca wyrażenia regularnego do identyfikacji i wydrukowania wszystkich adresów e-mail znalezionych w dokumencie.
Pobieranie tekstu z określonych stron
Czasami może być konieczne przeszukiwanie tylko określonej strony pliku PDF. IronPDF umożliwia kierowanie reklam na poszczególne strony przy użyciu właściwości PdfDocument.Pages:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassPlik wejściowy PDF
Wynik konsoli
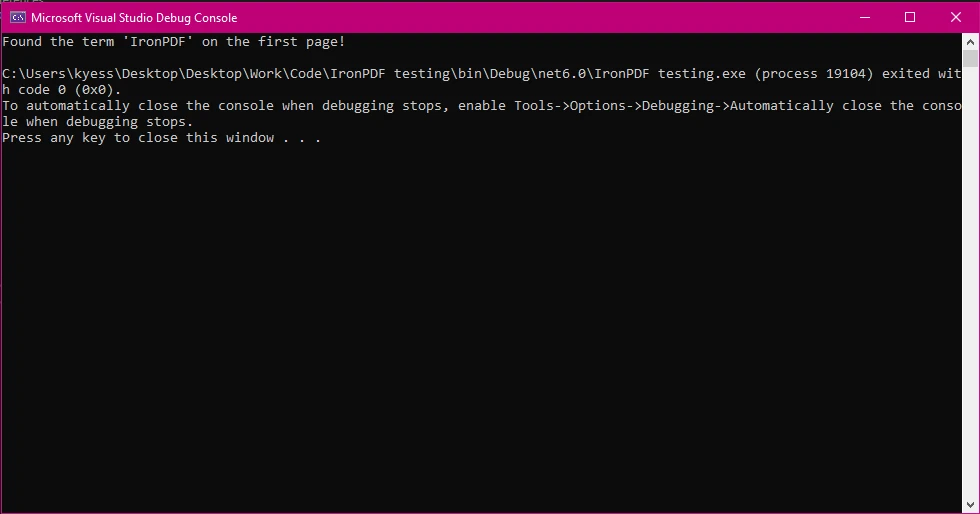
Takie podejście jest przydatne do optymalizacji wydajności podczas pracy z dużymi plikami PDF.
Praktyczne przykłady zastosowań
Analiza umowy
Prawnicy mogą używać IronPDF do automatyzacji wyszukiwania kluczowych terminów lub klauzul w długich umowach. Na przykład, szybko znajdź w dokumentach "klauzulę Rozwiązania umowy" lub "poufność".
Przetwarzanie faktur
W procesach finansowych lub księgowych IronPDF może pomóc w lokalizowaniu numerów faktur, dat lub kwot całkowitych w plikach PDF o dużej objętości, usprawniając operacje i zmniejszając nakład pracy ręcznej.
Eksploracja danych
IronPDF można zintegrować z potokami danych w celu wyodrębniania i analizowania informacji z raportów lub logów przechowywanych w formacie PDF. Jest to szczególnie przydatne w branżach zajmujących się dużymi ilościami danych nieustrukturyzowanych.
Wnioski
IronPDF to coś więcej niż tylko biblioteka do pracy z plikami PDF; To kompletny zestaw narzędzi, który umożliwia programistom .NET łatwą obsługę złożonych operacji na plikach PDF. Od wyodrębniania tekstu i wyszukiwania określonych terminów po zaawansowane dopasowywanie wzorców za pomocą wyrażeń regularnych — IronPDF usprawnia zadania, które w innym przypadku wymagałyby znacznego nakładu pracy ręcznej lub użycia wielu bibliotek.
Możliwość wyodrębniania i wyszukiwania tekstu w plikach PDF otwiera szerokie możliwości zastosowań w różnych branżach. Prawnicy mogą zautomatyzować wyszukiwanie kluczowych klauzul w umowach, księgowi mogą usprawnić przetwarzanie faktur, a programiści z dowolnej dziedziny mogą tworzyć wydajne przepływy pracy z dokumentami. Dzięki precyzyjnemu wyodrębnianiu tekstu, kompatybilności z .NET Core i Framework oraz zaawansowanym funkcjom, IronPDF zapewnia, że Twoje potrzeby związane z plikami PDF zostaną zaspokojone bez żadnych kłopotów.
Zacznij już dziś!
Nie pozwól, aby przetwarzanie plików PDF spowalniało proces tworzenia oprogramowania. Zacznij korzystać z IronPDF już dziś, aby uprościć proces wyodrębniania tekstu i zwiększyć wydajność. Oto jak możesz zacząć:
- Pobierz bezpłatną wersję próbną: Odwiedź stronę IronPDF.
- Zapoznaj się z dokumentacją: Przejrzyj szczegółowe przewodniki i przykłady w dokumentacji IronPDF.
- Zacznij tworzyć: Wprowadź zaawansowane funkcje obsługi plików PDF do swoich aplikacji .NET przy minimalnym wysiłku.
Zrób pierwszy krok w kierunku optymalizacji przepływu pracy z dokumentami dzięki IronPDF. Wykorzystaj w pełni jego potencjał, usprawnij proces tworzenia oprogramowania i dostarczaj solidne rozwiązania oparte na formacie PDF szybciej niż kiedykolwiek.
Często Zadawane Pytania
Jak mogę znaleźć tekst w pliku PDF za pomocą języka C#?
Aby znaleźć tekst w pliku PDF przy użyciu języka C#, można skorzystać z funkcji wyodrębniania tekstu biblioteki IronPDF. Po załadowaniu dokumentu PDF można wyszukiwać określony tekst przy użyciu wyrażeń regularnych lub poprzez określenie wzorców tekstowych. IronPDF udostępnia metody podświetlania i wyodrębniania pasującego tekstu.
Jakie metody wyszukiwania tekstu w plikach PDF oferuje IronPDF?
IronPDF oferuje różne metody wyszukiwania tekstu w plikach PDF, w tym podstawowe wyszukiwanie tekstu, wyszukiwanie zaawansowane z wykorzystaniem wyrażeń regularnych oraz możliwość wyszukiwania w określonych stronach dokumentu. Obsługuje również wyodrębnianie tekstu ze złożonych układów graficznych oraz obsługę treści wielojęzycznych.
Czy mogę wyodrębnić tekst z określonych stron w pliku PDF za pomocą języka C#?
Tak, za pomocą IronPDF można wyodrębnić tekst z określonych stron w pliku PDF. Określając numery stron lub zakresy, można wybrać żądane sekcje dokumentu, co sprawia, że proces wyodrębniania tekstu jest bardziej wydajny.
W jaki sposób IronPDF obsługuje tekst w zeskanowanych dokumentach?
IronPDF może przetwarzać tekst w zeskanowanych dokumentach za pomocą OCR (optycznego rozpoznawania znaków). Ta funkcja pozwala mu konwertować obrazy tekstu na tekst, który można przeszukiwać i z którego można wyodrębniać dane, nawet jeśli tekst jest osadzony w obrazach.
Jakie są typowe wyzwania związane z wyszukiwaniem tekstu w plikach PDF?
Typowe wyzwania związane z wyszukiwaniem tekstu w plikach PDF obejmują radzenie sobie z różnicami w kodowaniu tekstu, fragmentarycznym tekstem spowodowanym złożonymi układami oraz tekstem osadzonym w obrazach. IronPDF rozwiązuje te problemy, zapewniając solidne funkcje wyodrębniania tekstu i OCR.
Dlaczego ekstrakcja tekstu jest ważna w procesach związanych z plikami PDF?
Ekstrakcja tekstu ma kluczowe znaczenie dla automatyzacji przepływu pracy, weryfikacji treści i eksploracji danych. Ułatwia ona manipulowanie danymi i weryfikację treści, a także poprawia interakcję z użytkownikiem, umożliwiając przeszukiwanie i edycję statycznych treści w plikach PDF.
Jakie są zalety korzystania z IronPDF do wyodrębniania tekstu?
IronPDF oferuje szereg korzyści związanych z ekstrakcją tekstu, w tym wysoką dokładność, łatwość obsługi, kompatybilność międzyplatformową oraz zaawansowane funkcje wyszukiwania. Upraszcza proces ekstrakcji tekstu ze złożonych układów plików PDF i obsługuje wielojęzyczną ekstrakcję tekstu.
W jaki sposób IronPDF może zoptymalizować wydajność w przypadku dużych plików PDF?
IronPDF optymalizuje wydajność w przypadku dużych plików PDF, umożliwiając użytkownikom wyodrębnianie tekstu z określonych stron lub zakresów, minimalizując obciążenie procesora. Efektywnie obsługuje również duże dokumenty, optymalizując wykorzystanie pamięci podczas wyodrębniania tekstu.
Czy IronPDF nadaje się zarówno do projektów .NET Framework, jak i .NET Core?
Tak, IronPDF jest kompatybilny zarówno z .NET Framework, jak i .NET Core, dzięki czemu nadaje się do szerokiego zakresu zastosowań, w tym nowoczesnych aplikacji internetowych i desktopowych, a także starszych systemów.
Jak mogę zacząć używać IronPDF do wyszukiwania tekstu w plikach PDF?
Aby rozpocząć korzystanie z IronPDF do wyszukiwania tekstu w plikach PDF, można pobrać bezpłatną wersję próbną ze strony internetowej, postępować zgodnie z obszerną dokumentacją i samouczkami oraz zintegrować bibliotekę z projektami .NET w celu rozszerzenia możliwości obsługi plików PDF.
Czy IronPDF jest w pełni kompatybilny z .NET 10 podczas wyszukiwania i wyodrębniania tekstu z plików PDF?
Tak — IronPDF jest w pełni kompatybilny z .NET 10 i nie wymaga specjalnej konfiguracji w celu korzystania z funkcji wyodrębniania tekstu lub wyszukiwania. Obsługuje .NET 10 we wszystkich typowych typach projektów — internetowych, desktopowych, konsolowych i chmurowych — oraz korzysta z najnowszych ulepszeń środowiska uruchomieniowego podczas korzystania z interfejsów API IronPDF do wyszukiwania i wyodrębniania tekstu, zgodnie z opisem w samouczku.














