
ASP PDF 뷰어 (개발자 튜토리얼)
C#을 사용한 PDF에서 텍스트 찾기 소개
PDF 내에서 텍스트를 찾는 것은 특히 쉽게 편집거나 검색할 수 없는 정적 파일을 다룰 때 까다로운 작업일 수 있습니다. 문서 워크플로우를 자동화하거나, 검색 기능을 구축하거나, 검색 기준에 맞는 텍스트를 강조 표시하거나, 데이터를 추출하는 등, 텍스트 추출은 개발자에게 중요한 기능입니다.
IronPDF는 강력한 .NET 라이브러리로, 이 과정을 간단하게 하여 개발자들이 PDF에서 텍스트를 효율적으로 검색 및 추출할 수 있게 해줍니다. 이 기사에서는 IronPDF를 사용하여 C#에서 PDF의 텍스트를 찾는 방법을 코드 예제 및 실용적인 응용 사례와 함께 탐구할 것입니다.
C#에서 "텍스트 찾기"란 무엇입니까?
'텍스트 찾기'란 문서, 파일 또는 기타 데이터 구조 내에서 특정 텍스트나 패턴을 검색하는 과정을 말합니다. PDF 파일의 문맥에서는 특정 단어, 구문, 또는 텍스트 내용 내에서의 패턴의 예를 식별하고 위치를 찾는 것을 포함합니다. 이 기능은 특히 PDF 형식에 저장된 비정형 데이터나 반정형 데이터와 다룰 때 여러 산업 분야에 걸쳐 필수적입니다.
PDF 파일 내의 텍스트 이해하기
PDF 파일은 일관된, 장치 독립적인 형식으로 콘텐츠를 제공하도록 설계되었습니다. 그러나 PDF에서 텍스트가 저장되는 방식은 크게 다양할 수 있습니다. 텍스트는 다음과 같이 저장될 수 있습니다:
- 검색 가능한 텍스트: 텍스트로 삽입되어 직접 추출 가능한 텍스트 (예: Word 문서에서 PDF로 변환된 경우).
- 스캔된 텍스트: 이미지로 표시되어 OCR (광학 문자 인식)으로 검색 가능한 텍스트로 변환해야 하는 텍스트.
- 복잡한 레이아웃: 조각으로 저장되거나 비정상적인 인코딩을 가진 텍스트로, 정확하게 추출하고 검색하기 어려운 경우.
이러한 가변성은 PDF에서의 효과적인 텍스트 검색이 다양한 콘텐츠 유형을 매끄럽게 처리할 수 있는 전문 라이브러리, 예를 들어 IronPDF를 종종 필요로 한다는 것을 의미합니다.
텍스트 찾기가 왜 중요한가?
PDF에서 텍스트를 찾는 능력은 다음과 같은 다양한 응용 분야에 걸쳐 있습니다:
-
워크플로 자동화: PDF 문서에서 키 용어나 값을 식별하여 송장, 계약서 또는 보고서를 처리하는 작업 자동화.
-
데이터 추출: 다른 시스템 사용 또는 분석을 위한 정보 추출.
-
콘텐츠 확인: 문서에 필요한 용어 또는 구문이 있는지 확인하여, 준수 성명서 또는 법적 조항 등을 포함시킴.
- 사용자 경험 향상: 문서 관리 시스템에서 검색 기능을 활성화하여 사용자가 관련 정보를 신속하게 찾을 수 있도록 지원.
텍스트 검색의 도전과제
PDF에서 텍스트 찾기는 다음과 같은 이유로 항상 간단하지 않습니다:
- 인코딩 변형: 일부 PDF는 텍스트에 대해 사용자 정의 인코딩을 사용하여 추출을 복잡하게 만듭니다.
- 조각화된 텍스트: 텍스트가 여러 조각으로 나뉠 수 있어 검색을 더 복잡하게 만듭니다.
- 그래픽 및 이미지: 이미지에 삽입된 텍스트는 추출을 위해 OCR이 필요합니다.
- 다국어 지원: 다른 언어, 스크립트 또는 오른쪽에서 왼쪽으로 쓰는 텍스트가 있는 문서를 검색하려면 강력한 처리가 필요합니다.
텍스트 추출을 위해 IronPDF를 선택해야 하는 이유?
IronPDF는 .NET 생태계에서 작업하는 개발자를 위해 PDF 조작을 최대한 원활하게 만드는 것을 목표로 설계되었습니다. 텍스트 추출 및 조작 프로세스를 간소화하기 위한 기능 모음을 제공합니다.
주요 이점
-
사용 용이성:
IronPDF는 직관적인 API를 제공하여 개발자가 큰 학습 곡선 없이도 빠르게 시작할 수 있습니다. 기본적인 텍스트 추출이나 HTML을 PDF로 변환하는 것 등의 고급 작업을 수행할 때도 그 방법이 간단합니다.
-
높은 정확도:
IronPDF는 복잡한 레이아웃이나 내장 글꼴이 포함된 PDF에서도 신뢰할 수 있게 텍스트를 정확하게 추출합니다.
-
크로스플랫폼 지원:
IronPDF는 .NET Framework 및 .NET Core와 호환되어 개발자가 현대적인 웹 앱, 데스크톱 애플리케이션 및 레거시 시스템에서도 사용할 수 있습니다.
-
고급 쿼리 지원:
라이브러리는 정규 표현식 및 대상 추출과 같은 고급 검색 기술을 지원하여 데이터 마이닝이나 문서 색인과 같은 복잡한 사용 사례에 적합합니다.
프로젝트에서 IronPDF 설정하기
IronPDF는 NuGet을 통해 제공되어 .NET 프로젝트에 추가하기 쉽습니다. 여기서는 시작하는 방법입니다.
설치
IronPDF를 설치하려면 Visual Studio에서 NuGet 패키지 관리자를 사용하거나 패키지 관리자 콘솔에서 다음 명령을 실행하십시오:
Install-Package IronPdf
이 명령은 라이브러리와 그 종속성을 다운로드하고 설치합니다.
기본 설정
라이브러리가 설치되면 IronPDF 네임스페이스를 참조하여 프로젝트에 포함해야 합니다. 코드 파일의 상단에 다음 줄을 추가하십시오:
using IronPdf;using IronPdf;Imports IronPdf코드 예제: PDF에서 텍스트 찾기
IronPDF는 PDF 문서 내에서 텍스트를 찾는 과정을 간소화합니다. 아래에 단계별 데모가 나와 있습니다.
PDF 파일 로드하기
첫 번째 단계는 작업할 PDF 파일을 로드하는 것입니다. 이는 다음 코드에서 볼 수 있듯이 PdfDocument 클래스를 사용하여 수행됩니다.
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")PdfDocument 클래스는 메모리 내에서 PDF 파일을 나타내며, 텍스트 추출이나 내용 수정과 같은 다양한 작업을 수행할 수 있습니다. PDF가 로드되면 파일 내의 전체 PDF 문서 또는 특정 PDF 페이지에서 텍스트를 검색할 수 있습니다.
특정 텍스트 검색
PDF를 로드한 후 ExtractAllText() 메서드를 사용하여 전체 문서의 텍스트 내용을 추출합니다. 그런 다음 표준 문자열 조작 기술을 사용하여 특정 용어를 검색할 수 있습니다:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End Class입력 PDF
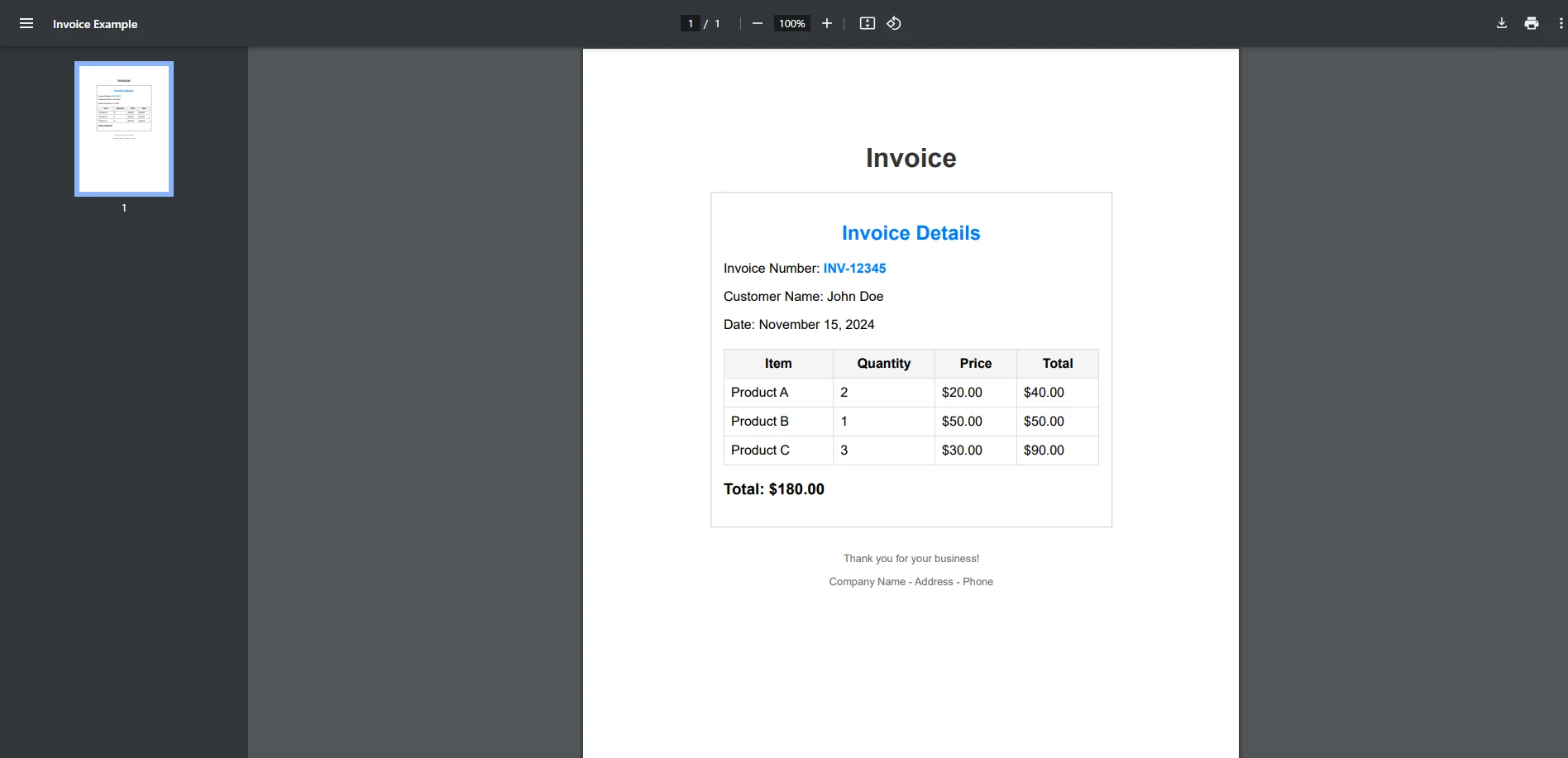
콘솔 출력
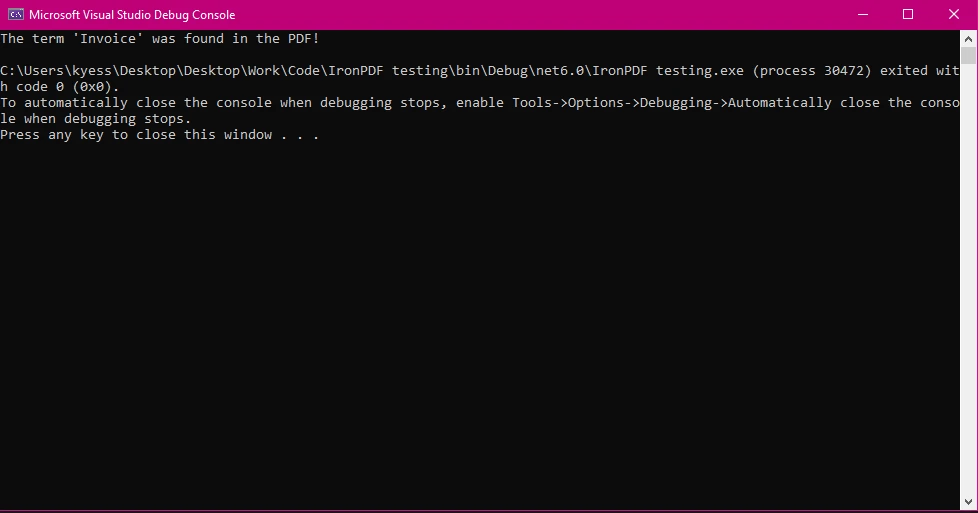
이 예제는 PDF에서 용어가 존재하는지 확인하는 간단한 경우를 보여줍니다. StringComparison.OrdinalIgnoreCase는 검색된 텍스트가 대소문자를 구분하지 않도록 보장합니다.
텍스트 검색을 위한 고급 기능
IronPDF는 텍스트 검색 기능을 강화하는 여러 가지 고급 기능을 제공합니다.
정규 표현식 사용
정규 표현식은 텍스트 내에서 패턴을 찾는 강력한 도구입니다. 예를 들어, PDF에서 모든 이메일 주소를 찾고 싶을 수 있습니다:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next match입력 PDF
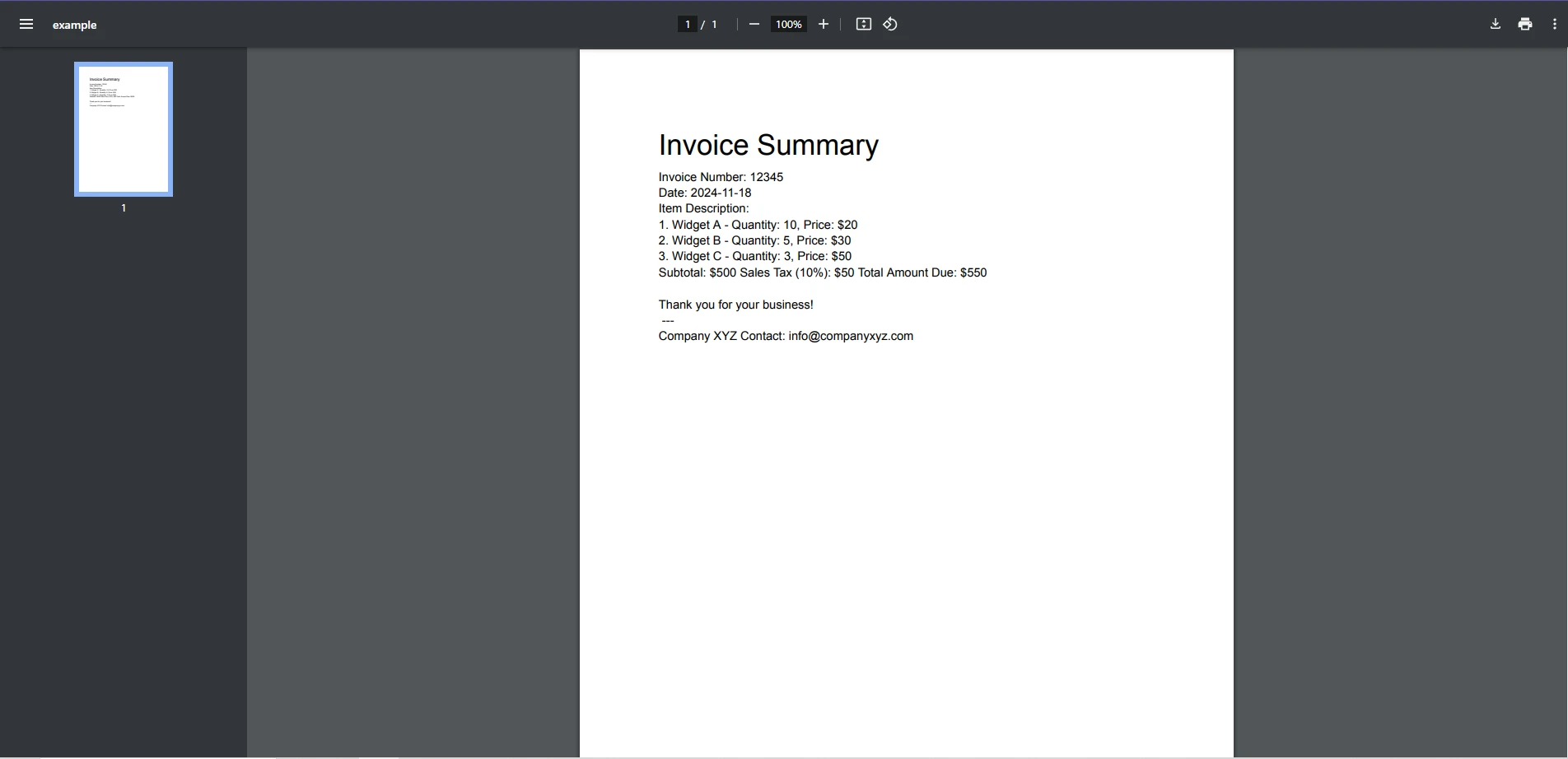
콘솔 출력
이 예제는 문서에서 발견된 모든 이메일 주소를 식별하고 출력하기 위한 정규식 패턴을 사용합니다.
특정 페이지에서 텍스트 추출
때때로 PDF의 특정 페이지 내에서만 검색해야 할 수도 있습니다. IronPDF는 PdfDocument.Pages 속성을 사용하여 개별 페이지를 대상으로 지정할 수 있습니다.
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End Class입력 PDF
콘솔 출력
이 방법은 대형 PDF 파일을 다룰 때 성능을 최적화하는 데 유용합니다.
실제 활용 사례
계약 분석
법무 전문가들은 IronPDF를 사용하여 긴 계약서 내의 주요 용어 또는 조항을 자동으로 검색할 수 있습니다. 예를 들어, 문서에서 '해지 조항' 또는 '기밀 유지'를 빠르게 찾습니다.
송장 처리
재무나 회계 워크플로우에서 IronPDF는 대량의 PDF 파일에서 송장 번호, 날짜, 총 금액을 찾아 작업을 간소화하고 수작업을 줄이는 데 도움이 될 수 있습니다.
데이터 마이닝
IronPDF는 보고서 또는 PDF 형식으로 저장된 로그에서 정보를 추출하고 분석하도록 데이터 파이프라인에 통합될 수 있습니다. 이는 대량의 비정형 데이터를 다루는 산업에서 특히 유용합니다.
결론
IronPDF는 단순히 PDF 작업을 위한 라이브러리가 아닙니다; .NET 개발자에게 복잡한 PDF 작업을 쉽게 처리할 수 있는 완전한 도구 세트를 제공합니다. 텍스트 추출과 특정 용어 찾기에서 정규 표현식을 사용한 고급 패턴 일치 수행까지, IronPDF는 상당한 수작업이나 여러 라이브러리가 필요할 수 있는 작업을 간소화합니다.
PDF에서 텍스트를 추출하고 검색할 수 있는 기능은 산업 전반에 걸쳐 강력한 사용 사례를 열어줍니다. 법무 전문가들은 계약서의 중요한 조항을 검색을 자동화할 수 있고, 회계사는 송장 처리를 단순화할 수 있으며, 모든 분야의 개발자는 효율적인 문서 워크플로우를 생성할 수 있습니다. .NET Core 및 Framework와의 호환성과 고급 기능을 갖춘 정확한 텍스트 추출 기능을 제공함으로써 IronPDF는 PDF 요구 사항이 번거로움 없이 충족되도록 보장합니다.
지금 시작하세요!
PDF 처리가 개발 속도를 늦추지 않도록 하세요. 오늘부터 IronPDF를 사용하여 텍스트 추출을 간소화하고 생산성을 높이세요. 시작하는 방법은 다음과 같습니다:
- 체험판 다운로드: IronPDF를 방문하세요.
- 문서 살펴보기: IronPDF 문서에서 자세한 가이드와 예제를 확인하세요.
- 구현 시작: 최소한의 노력으로 .NET 애플리케이션에 강력한 PDF 기능을 구현하세요.
IronPDF로 문서 워크플로우 최적화를 위한 첫걸음을 내딛으세요. 그 잠재력을 최대한 활용하여 개발 과정을 개선하고 강력한 PDF 중심의 솔루션을 더 빠르게 제공합니다.
자주 묻는 질문
C#을 사용하여 PDF에서 텍스트를 어떻게 찾을 수 있나요?
C#을 사용하여 PDF에서 텍스트를 찾으려면, IronPDF의 텍스트 추출 기능을 활용할 수 있습니다. PDF 문서를 불러와 정규 표현식이나 텍스트 패턴을 지정하여 특정 텍스트를 검색할 수 있습니다. IronPDF는 일치하는 텍스트를 강조 표시하고 추출하는 방법을 제공합니다.
IronPDF는 PDF에서 텍스트를 검색하는 데 어떤 방법을 제공합니까?
IronPDF는 기본 텍스트 검색, 정규 표현식을 사용한 고급 검색 및 문서의 특정 페이지 내 검색 기능을 포함한 다양한 방법을 제공합니다. 또한 복잡한 레이아웃에서 텍스트를 추출하고 다국어 콘텐츠를 처리할 수 있는 기능도 지원합니다.
C#을 사용하여 PDF의 특정 페이지에서 텍스트를 추출할 수 있습니까?
네, IronPDF를 사용하여 PDF의 특정 페이지에서 텍스트를 추출할 수 있습니다. 페이지 번호나 범위를 지정하여 원하는 문서 섹션을 대상으로 할 수 있으며, 이렇게 하면 텍스트 추출 과정이 더 효율적입니다.
IronPDF는 스캔된 문서의 텍스트를 어떻게 처리합니까?
IronPDF는 OCR(광학 문자 인식)을 사용하여 스캔된 문서의 텍스트를 처리할 수 있습니다. 이 기능은 이미지에 내장된 텍스트를 검색 가능하고 추출 가능한 텍스트로 변환할 수 있습니다.
PDF 내 텍스트 검색에서 일반적인 문제는 무엇입니까?
PDF 내 텍스트 검색의 일반적인 문제는 텍스트 인코딩 변형 처리, 복잡한 레이아웃으로 인한 텍스트 단편화, 이미지 내에 내장된 텍스트 처리입니다. IronPDF는 강력한 텍스트 추출 및 OCR 기능으로 이러한 문제를 해결합니다.
PDF 워크플로에서 텍스트 추출이 중요한 이유는 무엇입니까?
텍스트 추출은 워크플로 자동화, 콘텐츠 검증, 데이터 마이닝에 중요합니다. 이를 통해 데이터 조작이 더 쉬워지고, 콘텐츠 검증이 가능해지며, 정적인 PDF 콘텐츠를 검색 가능하고 편집 가능하게 만들어 사용자 상호작용을 향상시킵니다.
텍스트 추출을 위해 IronPDF를 사용하는 이점은 무엇입니까?
IronPDF는 텍스트 추출에 대해 높은 정확성, 사용의 용이성, 플랫폼 간 호환성, 고급 검색 기능과 같은 여러 가지 이점을 제공합니다. 복잡한 PDF 레이아웃에서 텍스트 추출을 단순화하며 다국어 텍스트 추출을 지원합니다.
IronPDF는 대용량 PDF 파일의 성능을 어떻게 최적화합니까?
IronPDF는 특정 페이지나 범위에서 텍스트를 추출하도록 하여 대용량 PDF 파일의 성능을 최적화하며, 처리 부하를 최소화합니다. 또한 텍스트 추출 과정에서 메모리 사용을 최적화하여 대용량 문서를 효율적으로 처리합니다.
IronPDF는 .NET Framework와 .NET Core 프로젝트에 모두 적합합니까?
네, IronPDF는 .NET Framework와 .NET Core 모두와 호환되어 현대적인 웹 및 데스크톱 애플리케이션, 또한 기존 시스템을 포함한 다양한 애플리케이션에 적합합니다.
IronPDF를 사용하여 PDF에서 텍스트 검색을 시작하려면 어떻게 해야 합니까?
IronPDF를 사용하여 PDF에서 텍스트 검색을 시작하려면 그들의 웹사이트에서 무료 체험판을 다운로드하고, 제공된 포괄적인 문서 및 튜토리얼을 따라하며, .NET 프로젝트에 라이브러리를 통합하여 PDF 처리 기능을 향상하도록 하세요.
IronPDF는 PDF에서 텍스트를 찾고 추출하는 데 .NET 10과 완전히 호환됩니까?
네, IronPDF는 .NET 10과 완전히 호환되며, 텍스트 추출이나 검색 기능에 특별한 구성이 필요하지 않습니다. 웹, 데스크톱, 콘솔, 클라우드와 같은 일반적인 프로젝트 유형 모두에서 .NET 10을 지원하며, IronPDF의 텍스트 검색 및 추출 API를 튜토리얼에 설명된 대로 사용하면서 최신 런타임 개선 기능을 활용합니다.











