
C#でPDF内のテキストを見つける方法
PDFでテキストを見つけるためのC#入門
PDF内でテキストを見つけることは、特に編集や検索が容易でない静的ファイルで作業する際には困難なタスクです。 ドキュメントワークフローの自動化や検索機能の構築、検索基準に合致するテキストのハイライト、データの抽出が必要な場合、テキスト抽出は開発者にとって重要な機能です。
IronPDFは強力な.NETライブラリで、このプロセスを容易にし、開発者がPDFから効率的にテキストを検索し、抽出できるようにします。 この記事では、IronPDFを使用してPDF内のテキストをC#で見つける方法を、コード例や実用的な応用例と共に探ります。
C#での"テキスト検索"とは?
"テキスト検索"とは、ドキュメント、ファイル、または他のデータ構造内で特定のテキストやパターンを検索するプロセスを指します。 PDFファイルのコンテキストでは、特定の単語、フレーズ、またはパターンをPDFドキュメントのテキストコンテンツ内で特定し、見つけ出すことを含みます。 この機能は、特にPDF形式で保存された非構造化または半構造化データを扱う場合に、業界全般で多くのアプリケーションにとって重要です。
PDFファイル内のテキストの理解
PDFファイルは、コンテンツを一貫したデバイス非依存のフォーマットで提示するように設計されています。 ただし、PDF内でのテキストの保存方法は大きく異なることがあります。 テキストは以下のように保存されている場合があります:
- 検索可能なテキスト: Word文書からPDFに変換された例などで、テキストとして埋め込まれているため直接抽出可能なテキスト。
- スキャンされたテキスト: OCR(光学文字認識)で検索可能なテキストに変換する必要がある画像として表示されるテキスト。
- 複雑なレイアウト: 断片的に保存されたり特殊なエンコードがされているため、正確に抽出および検索するのが難しいテキスト。
この多様性のため、PDFで効果的なテキスト検索には、IronPDFのような多様なコンテンツ種類をシームレスに処理できる特殊なライブラリが必要となる場合があります。
なぜテキスト検索が重要なのか?
PDF内のテキストを見つける能力は、次のような幅広いアプリケーションにおいて重要です:
-
ワークフローの自動化: PDFドキュメント内の重要な用語や値を特定することで、請求書、契約書、報告書などの処理を自動化します。
-
データ抽出: 他のシステムでの使用や分析のために情報を抽出します。
-
コンテンツの検証: コンプライアンスの声明や法的条項など、必要な用語やフレーズが文書内に存在することを確認します。
- ユーザーエクスペリエンスの向上: 文書管理システムに検索機能を組み込み、ユーザーが関連情報を迅速に見つけられるようにします。
テキスト検索の課題
PDFでのテキスト検索は以下の課題のため常に簡単ではありません:
- エンコーディングのバリエーション: 一部のPDFはテキストにカスタムエンコーディングを使用しており、抽出が複雑になります。
- 断片化されたテキスト: テキストが複数の部分に分割されている可能性があり、検索を複雑にします。
- グラフィックスと画像: 画像に埋め込まれたテキストはOCRを用いた抽出が必要です。
- 多言語サポート: 異なる言語やスクリプト、右から左へのテキストを含む文書全体で検索するには強力な処理が必要です。
なぜIronPDFをテキスト抽出に選ぶのか?
IronPDFは、.NETエコシステムで作業する開発者向けにPDF操作を可能な限りシームレスに行えるように設計されています。 テキスト抽出および操作プロセスを簡素化するための機能セットを提供します。
主要な利点
- 使いやすさ:
IronPDFは直感的なAPIを備えており、開発者が急な学習曲線なしにすぐ開始できるようにします。 基本的なテキスト抽出やHTMLからPDFへの変換、または高度な操作を行う場合でも、その方法は直感的に利用できます。
-
高精度:
一部のPDFライブラリが複雑なレイアウトや埋め込まれたフォントを含むPDFに苦労する中、IronPDFは正確にテキストを抽出します。
-
クロスプラットフォームサポート:
IronPDFは.NET Frameworkと.NET Coreの両方と互換性があり、現代のWebアプリケーション、デスクトップアプリケーション、さらにはレガシーシステムでも使用できます。
-
高度なクエリーのサポート:
このライブラリは正規表現やターゲット抽出などの高度な検索技術をサポートしており、データマイニングやドキュメントインデックスの作成など、複雑なユースケースに適しています。
IronPDFをプロジェクトに設定する方法
IronPDFはNuGetを通じて入手可能で、.NETプロジェクトへの追加が容易です。 始める方法は次のとおりです。
インストール
IronPDFをインストールするには、Visual StudioのNuGetパッケージマネージャーを使用するか、パッケージマネージャーコンソールで次のコマンドを実行します:
Install-Package IronPdfInstall-Package IronPdfこれにより、ライブラリとその依存関係がダウンロードおよびインストールされます。
基本的なセットアップ
ライブラリがインストールされたら、IronPDFの名前空間を参照してプロジェクトに含める必要があります。 コードファイルの先頭に次の行を追加します:
using IronPdf;using IronPdf;Imports IronPdfコード例:PDF内のテキストを見つける
IronPDFは、PDFドキュメント内のテキストを見つけるプロセスを簡素化します。 以下はこの方法を達成するためのステップバイステップのデモンストレーションです。
PDFファイルの読み込み
最初のステップは作業したいPDFファイルを読み込むことです。 これは、次のコードに示すように、PdfDocument クラスを使用して行われます。
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")PdfDocument クラスはメモリ内の PDF ファイルを表し、テキストの抽出やコンテンツの変更などのさまざまな操作を実行できます。 PDFが読み込まれたら、PDFドキュメント全体またはファイル内の特定のPDFページからテキストを検索できます。
特定のテキストを検索する
PDF を読み込んだ後、ExtractAllText() メソッドを使用してドキュメント全体のテキスト コンテンツを抽出します。 標準的な文字列操作技術を使用して特定の用語を検索できます:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End Class入力 PDF
コンソール出力
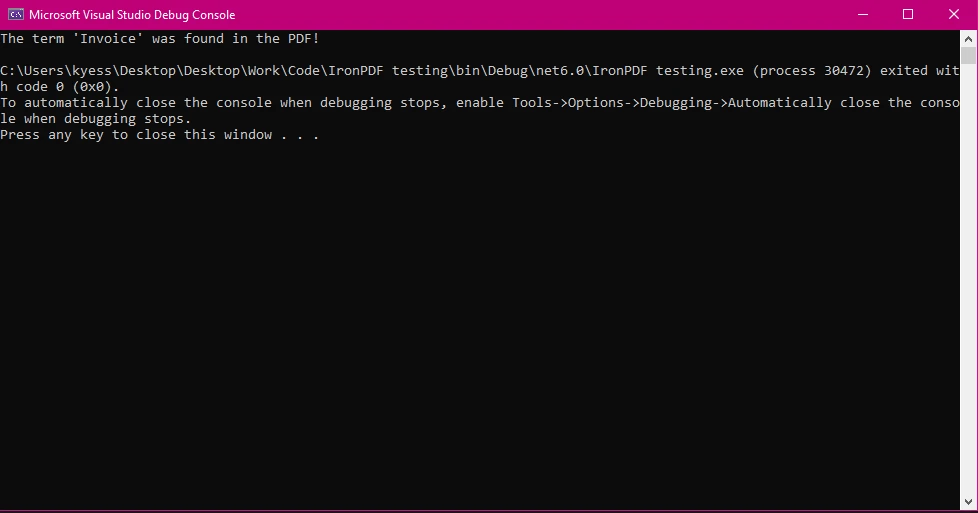
この例では、用語がPDFに存在するかどうかを確認する簡単なケースを示しています。 StringComparison.OrdinalIgnoreCaseは、検索されたテキストが大文字と小文字を区別しないことを保証します。
テキスト検索のための高度な機能
IronPDFは、そのテキスト検索機能を拡張するいくつかの高度な機能を提供しています。
正規表現の使用
正規表現はテキスト内のパターンを検索するための強力なツールです。 たとえば、PDF内のすべてのメールアドレスを特定したい場合があります:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next match入力 PDF
コンソール出力
この例では、正規表現パターンを使用してドキュメント内のすべてのメールアドレスを特定し印刷します。
特定のページからテキストを抽出する
時々、PDFの特定のページ内でのみ検索する必要があります。 IronPDF、PdfDocument.Pagesプロパティを使用して個々のページをターゲットにすることができます。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End Class入力 PDF
コンソール出力
このアプローチは、大きなPDFを扱う際にパフォーマンスを最適化するのに役立ちます。
実際の利用例
契約分析
法律専門家はIronPDFを使用して、長い契約書の中で重要な用語や条項を自動的に検索することができます。 たとえば、"Termination Clause"や"Confidentiality"をドキュメント内で迅速に特定します。
請求書処理
ファイナンスや会計業務のワークフローでは、IronPDFは大量のPDFファイルでの請求書番号、日付、合計金額の特定を容易にし、業務を合理化し、手動作業を削減します。
データマイニング
IronPDFは、PDF形式で保存されたレポートやログから情報を抽出・分析するためにデータパイプラインに統合できます。 これは、大量の非構造化データを扱う業界にとって特に便利です。
結論
IronPDFは単なるPDFを扱うためのライブラリ以上のものです。 それは.NET開発者が複雑なPDF操作を容易に行うための完全なツールキットです。 テキストを抽出し特定の用語を見つけることから、正規表現を使った高度なパターンマッチングまで、IronPDFは通常かなりの手動労力や複数のライブラリを必要とするタスクを効率化します。
PDFのテキスト抽出と検索の能力は、業界全般で強力なユースケースを切り開きます。 法律専門家は契約書内の重要な条項を自動的に検索でき、会計士は請求書処理を効率化し、あらゆる分野の開発者は効率的なドキュメントワークフローを作成できます。 .NET CoreおよびFrameworkと互換性があり、正確なテキスト抽出と高度な機能を提供することで、IronPDFはPDFニーズを煩わしさなく満たします。
今すぐ始めましょう!
PDF処理があなたの開発を遅らせないようにしましょう。 IronPDFを活用してテキスト抽出を簡素化し、生産性を高めましょう。 こちらが始め方です:
- 無料トライアルをダウンロード: IronPDFを訪問してください。
- ドキュメントをチェックアウト: IronPDF ドキュメントで詳細なガイドや例を探求してください。
- 作成を開始: .NETアプリケーションに強力なPDF機能を最小限の労力で実装してください。
IronPDFを使用してあなたのドキュメントワークフローを最適化する第一歩を踏み出してください。 その完全なポテンシャルを解き放ち、あなたの開発プロセスを向上させ、かつてないほど迅速に堅牢でPDFを活用したソリューションを提供しましょう。
よくある質問
C#を使ってPDFでのテキストをどのように見つけられますか?
C#を使用してPDF内でテキストを見つけるには、IronPDFのテキスト抽出機能を利用できます。PDFドキュメントを読み込むことで、正規表現やテキストパターンを指定して特定のテキストを検索できます。IronPDFはマッチしたテキストのハイライトおよび抽出の方法を提供しています。
IronPDFはPDF内のテキスト検索にどのような方法を提供していますか?
IronPDFは、基本的なテキスト検索から正規表現を使用した高度な検索、ドキュメント内の特定のページ内での検索機能まで、さまざまな方法を提供しています。また、複雑なレイアウトからのテキスト抽出と多言語コンテンツの処理もサポートしています。
C#を使ってPDFの特定ページからテキストを抽出できますか?
はい、IronPDFを使用すると、PDF内の特定のページからテキストを抽出できます。ページ番号や範囲を指定することで、ドキュメント内の必要なセクションをターゲットにでき、より効率的なテキスト抽出を実現します。
IronPDFはスキャンされたドキュメント内のテキストをどのように処理しますか?
IronPDFはOCR (光学文字認識)を使用してスキャンされたドキュメント内のテキストを処理します。この機能により、画像内のテキストを検索可能で抽出可能なテキストに変換し、画像に埋め込まれたテキストであっても処理できます。
PDF内のテキスト検索における一般的な課題は何ですか?
PDF内のテキスト検索における一般的な課題には、テキストエンコーディングのばらつき、複雑なレイアウトによりフラグメント化されたテキスト、画像内に埋め込まれたテキストの処理などがあります。IronPDFは、強力なテキスト抽出とOCR機能を提供することでこれらの課題に対処しています。
PDFワークフローでテキスト抽出が重要な理由は何ですか?
テキスト抽出は、ワークフローの自動化、コンテンツの検証、データマイニングにとって重要です。それによりデータ操作が容易になり、コンテンツの検証が可能になり、静的なPDFコンテンツを検索および編集可能にすることでユーザーインタラクションが向上します。
IronPDFを使用することのできるテキスト抽出の利点は何ですか?
IronPDFは、高精度、使いやすさ、クロスプラットフォームの互換性、高度な検索機能など、テキスト抽出におけるいくつかの利点を提供します。複雑なPDFレイアウトからのテキスト抽出を簡略化し、多言語テキスト抽出をサポートします。
IronPDFは大規模なPDFファイルのパフォーマンスをどのように最適化しますか?
IronPDFは、特定のページや範囲からテキストを抽出することでプロセスの負荷を最小限にし、大規模なPDFファイルのパフォーマンスを最適化します。テキスト抽出中のメモリ使用を最適化することで、大規模なドキュメントを効率的に処理します。
IronPDFは.NET Frameworkと.NET Coreの両方のプロジェクトに適していますか?
はい、IronPDFは.NET Frameworkおよび.NET Coreの両方と互換性があり、現代のウェブおよびデスクトップアプリケーション、従来のシステムを含むさまざまなアプリケーションに適しています。
PDFでのテキスト検索をIronPDFで始めるにはどうすればいいですか?
IronPDFでPDFのテキスト検索を始めるには、公式ウェブサイトから無料トライアルをダウンロードし、提供される包括的なドキュメントとチュートリアルに従い.NETプロジェクトにライブラリを統合して、PDF処理能力を拡張します。
IronPDF は、PDF 内のテキストを検索および抽出する際に .NET 10 と完全に互換性がありますか?
はい。IronPDFは.NET 10と完全に互換性があり、テキスト抽出や検索機能のために特別な設定は必要ありません。Web、デスクトップ、コンソール、クラウドなど、一般的なプロジェクトタイプすべてで.NET 10をサポートし、チュートリアルで説明されているIronPDFのテキスト検索および抽出APIを使用しながら、最新のランタイム改善の恩恵を受けることができます。












