
Visualizador de PDF ASP (Tutorial para desenvolvedores)
Introdução à localização de texto em PDFs com C
Encontrar texto em um PDF pode ser uma tarefa desafiadora, especialmente ao trabalhar com arquivos estáticos que não são facilmente editáveis ou pesquisáveis . Seja para automatizar fluxos de trabalho de documentos, criar funcionalidades de busca, destacar textos que correspondam aos seus critérios de pesquisa ou extrair dados, a extração de texto é um recurso essencial para desenvolvedores.
IronPDF , uma poderosa biblioteca .NET , simplifica esse processo, permitindo que os desenvolvedores pesquisem e extraiam texto de PDFs com eficiência. Neste artigo, exploraremos como usar o IronPDF para encontrar texto em um PDF usando C#, com exemplos de código e aplicações práticas.
O que é "Localizar Texto" em C#?
"Localizar texto" refere-se ao processo de busca por texto ou padrões específicos dentro de um documento, arquivo ou outras estruturas de dados. No contexto de arquivos PDF, isso envolve identificar e localizar ocorrências de palavras, frases ou padrões específicos dentro do conteúdo textual de um documento PDF. Essa funcionalidade é essencial para inúmeras aplicações em diversos setores, especialmente ao lidar com dados não estruturados ou semiestruturados armazenados em formato PDF.
Entendendo o texto em arquivos PDF
Os arquivos PDF são projetados para apresentar conteúdo em um formato consistente e independente do dispositivo. No entanto, a forma como o texto é armazenado em PDFs pode variar bastante. O texto pode ser armazenado como:
- Texto pesquisável: Texto que pode ser extraído diretamente porque está incorporado como texto (por exemplo, de um documento do Word convertido para PDF).
- Texto digitalizado: Texto que aparece como uma imagem e que requer OCR (Reconhecimento Óptico de Caracteres) para ser convertido em texto pesquisável.
- Layouts complexos: Texto armazenado em fragmentos ou com codificação incomum, dificultando a extração e a busca precisa.
Essa variabilidade significa que a busca de texto eficaz em PDFs geralmente requer bibliotecas especializadas, como o IronPDF, que podem lidar perfeitamente com diversos tipos de conteúdo.
Por que encontrar textos é importante?
A capacidade de encontrar texto em PDFs tem uma ampla gama de aplicações, incluindo:
-
Automatização de fluxos de trabalho: Automatizar tarefas como processamento de faturas, contratos ou relatórios, identificando termos ou valores-chave em documentos PDF.
-
Extração de dados: Extrair informações para uso em outros sistemas ou para análise.
-
Verificação de conteúdo: Garantir que os termos ou frases necessários estejam presentes nos documentos, como declarações de conformidade ou cláusulas legais.
- Melhorar a experiência do usuário: Habilitar a funcionalidade de busca em sistemas de gerenciamento de documentos, ajudando os usuários a localizar rapidamente informações relevantes.
Desafios na Busca de Texto
Encontrar texto em PDFs nem sempre é fácil devido aos seguintes desafios:
- Variações de codificação: Alguns PDFs usam codificação personalizada para o texto, o que complica a extração.
- Texto fragmentado: O texto pode estar dividido em várias partes, tornando as buscas mais complexas.
- Gráficos e imagens: O texto incorporado em imagens requer OCR para ser extraído.
- Suporte multilíngue: A busca em documentos com diferentes idiomas, alfabetos ou texto da direita para a esquerda exige um tratamento robusto.
Por que escolher o IronPDF para extração de texto?
O IronPDF foi projetado para tornar a manipulação de PDFs o mais simples possível para desenvolvedores que trabalham no ecossistema .NET . Oferece um conjunto de funcionalidades concebidas para simplificar os processos de extração e manipulação de texto.
Principais benefícios
- Facilidade de uso:
O IronPDF apresenta uma API intuitiva, permitindo que os desenvolvedores comecem rapidamente sem uma curva de aprendizado íngreme. Quer você esteja realizando extração de texto básica, conversão de HTML para PDF ou operações avançadas, seus métodos são fáceis de usar.
- Alta Precisão:
Ao contrário de algumas bibliotecas PDF que lutam com PDFs contendo layouts complexos ou fontes incorporadas, o IronPDF extrai texto de maneira confiável e precisa.
- Suporte a Várias Plataformas:
O IronPDF é compatível com .NET Framework e .NET Core, garantindo que os desenvolvedores possam usá-lo em aplicativos web modernos, aplicativos desktop e até mesmo sistemas legados.
- Suporte para Consultas Avançadas:
A biblioteca suporta técnicas de pesquisa avançadas, como expressões regulares e extração direcionada, tornando-a adequada para casos de uso complexos como mineração de dados ou indexação de documentos.
Configurando o IronPDF em seu projeto
O IronPDF está disponível via NuGet, facilitando sua adição aos seus projetos .NET . Veja como começar.
Instalação
Para instalar o IronPDF , utilize o Gerenciador de Pacotes NuGet no Visual Studio ou execute o seguinte comando no Console do Gerenciador de Pacotes:
Install-Package IronPdf
Isso fará o download e a instalação da biblioteca juntamente com suas dependências.
Configuração básica
Após a instalação da biblioteca, você precisa incluí-la em seu projeto, referenciando o namespace IronPDF . Adicione a seguinte linha no início do seu arquivo de código:
using IronPdf;using IronPdf;Imports IronPdfExemplo de código: Encontrando texto em um PDF
O IronPDF simplifica o processo de localização de texto em um documento PDF. A seguir, apresentamos uma demonstração passo a passo de como realizar esse objetivo.
Carregando um arquivo PDF
O primeiro passo é carregar o arquivo PDF com o qual você deseja trabalhar. Isso é feito usando a classe PdfDocument, conforme visto no código a seguir:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")A classe PdfDocument representa o arquivo PDF na memória, permitindo realizar várias operações como extrair texto ou modificar o conteúdo. Após o carregamento do PDF, podemos pesquisar texto em todo o documento PDF ou em uma página específica dentro do arquivo.
Pesquisa por texto específico
Após carregar o PDF, use o método ExtractAllText() para extrair o conteúdo de texto de todo o documento. Em seguida, você pode pesquisar termos específicos usando técnicas padrão de manipulação de strings:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
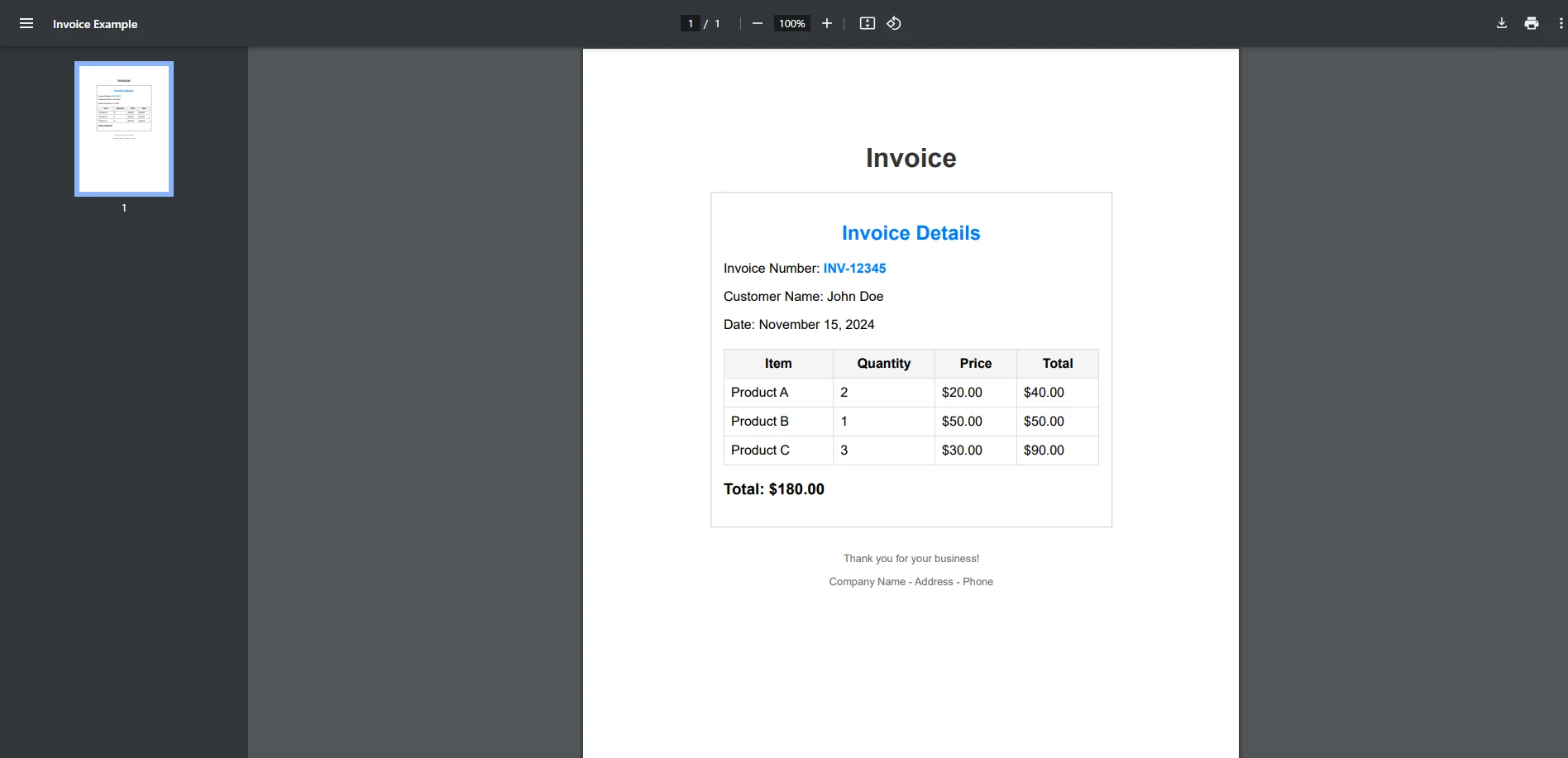
End ClassEntrada PDF
Saída do console
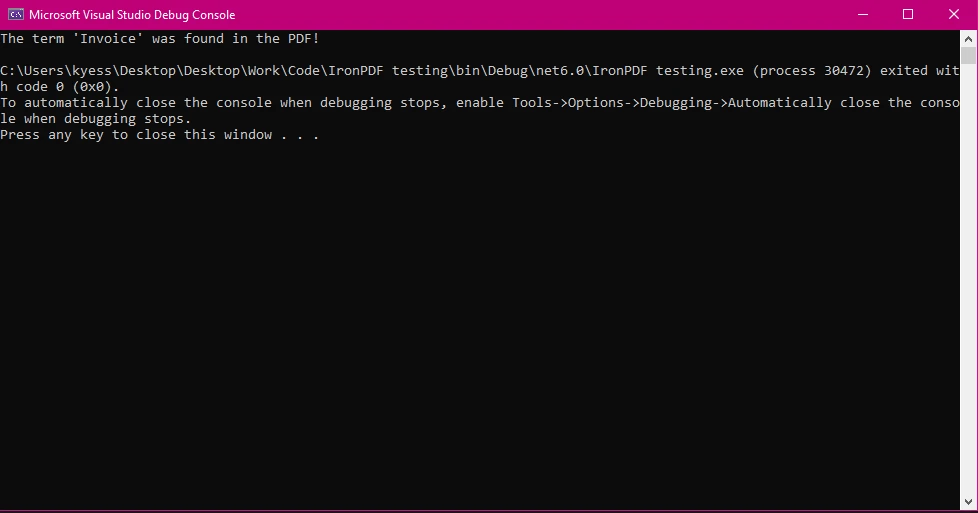
Este exemplo demonstra um caso simples em que você verifica se um termo existe no PDF. O StringComparison.OrdinalIgnoreCase assegura que o texto pesquisado não distingue maiúsculas de minúsculas.
Recursos avançados para pesquisa de texto
O IronPDF oferece diversos recursos avançados que ampliam suas capacidades de busca de texto.
Utilizando expressões regulares
Expressões regulares são uma ferramenta poderosa para encontrar padrões em textos. Por exemplo, você pode querer localizar todos os endereços de e-mail em um PDF:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
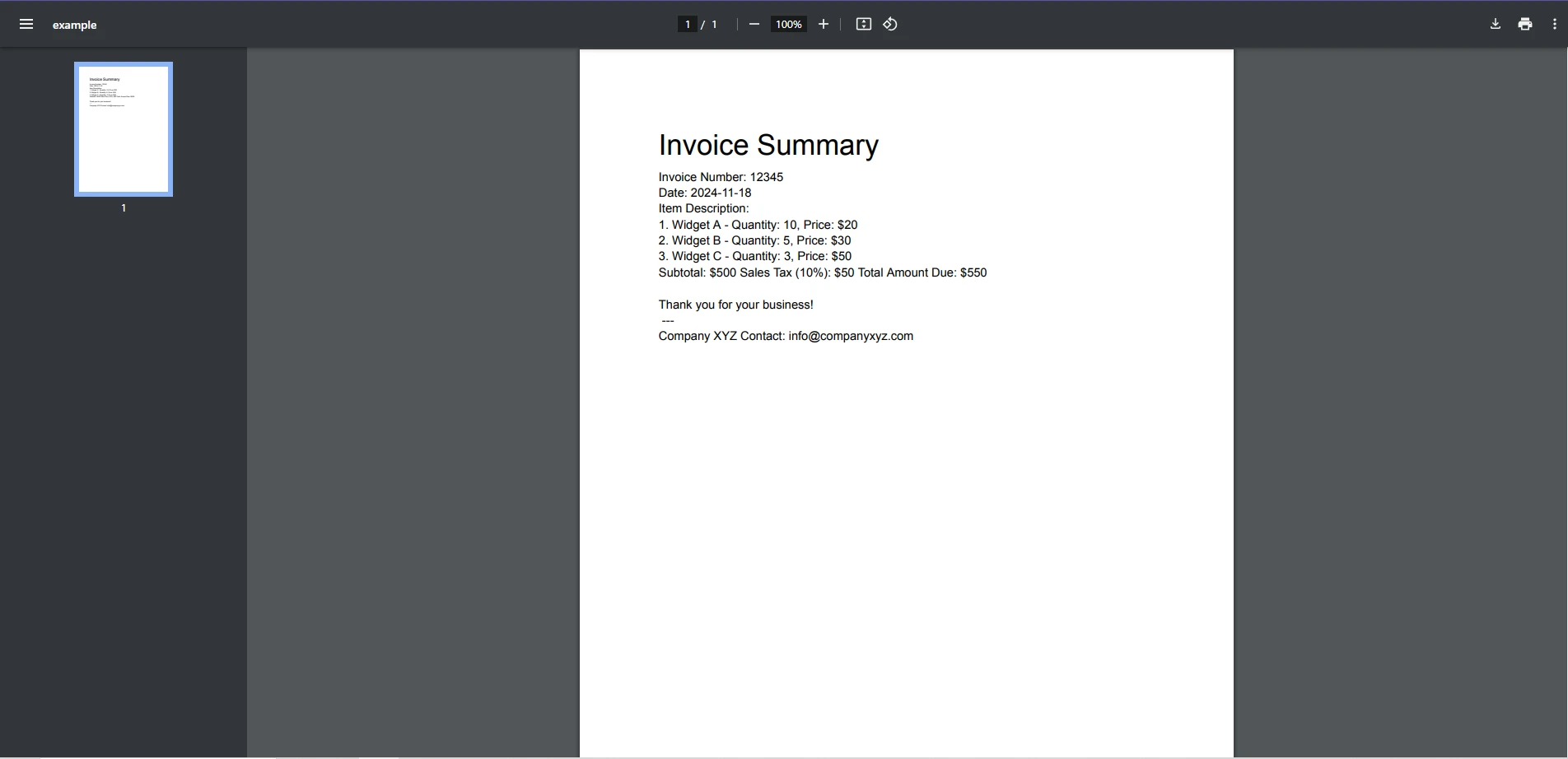
Next matchEntrada PDF
Saída do console
Este exemplo utiliza uma expressão regular para identificar e imprimir todos os endereços de e-mail encontrados no documento.
Extraindo texto de páginas específicas
Às vezes, você pode precisar pesquisar apenas em uma página específica de um PDF. IronPDF permite que você direcione páginas individuais usando a propriedade PdfDocument.Pages:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassEntrada PDF
Saída do console
Essa abordagem é útil para otimizar o desempenho ao trabalhar com PDFs grandes.
Casos de uso no mundo real
Análise de Contrato
Profissionais da área jurídica podem usar o IronPDF para automatizar a busca por termos ou cláusulas importantes em contratos extensos. Por exemplo, localize rapidamente as cláusulas "Cláusula de Rescisão" ou "Confidencialidade" em documentos.
Processamento de faturas
Em fluxos de trabalho financeiros ou contábeis, o IronPDF pode ajudar a localizar números de faturas, datas ou valores totais em arquivos PDF em lote, otimizando as operações e reduzindo o esforço manual.
Mineração de dados
O IronPDF pode ser integrado em fluxos de dados para extrair e analisar informações de relatórios ou registros armazenados em formato PDF. Isso é particularmente útil para setores que lidam com grandes volumes de dados não estruturados.
Conclusão
IronPDF é mais do que apenas uma biblioteca para trabalhar com PDFs; É um conjunto de ferramentas completo que permite aos desenvolvedores .NET lidar com operações complexas em PDF com facilidade. Desde a extração de texto e a busca de termos específicos até a realização de correspondência de padrões avançada com expressões regulares, o IronPDF simplifica tarefas que, de outra forma, exigiriam um esforço manual significativo ou o uso de várias bibliotecas.
A capacidade de extrair e pesquisar texto em PDFs abre portas para casos de uso poderosos em diversos setores. Profissionais da área jurídica podem automatizar a busca por cláusulas críticas em contratos, contadores podem agilizar o processamento de faturas e desenvolvedores de qualquer área podem criar fluxos de trabalho de documentos eficientes. Ao oferecer extração de texto precisa, compatibilidade com .NET Core e Framework, além de recursos avançados, o IronPDF garante que suas necessidades de PDF sejam atendidas sem complicações.
Comece hoje mesmo!
Não deixe que o processamento de PDFs atrase seu desenvolvimento. Comece a usar o IronPDF hoje mesmo para simplificar a extração de texto e aumentar a produtividade. Veja como você pode começar:
- Faça o download da versão de avaliação gratuita: Visite o IronPDF .
- Consulte a documentação: Explore guias detalhados e exemplos na documentação do IronPDF .
- Comece a construir: Implemente funcionalidades avançadas de PDF em seus aplicativos .NET com o mínimo esforço.
Dê o primeiro passo para otimizar seus fluxos de trabalho de documentos com o IronPDF. Desbloqueie todo o seu potencial, aprimore seu processo de desenvolvimento e entregue soluções robustas baseadas em PDF mais rapidamente do que nunca.
Perguntas frequentes
Como posso encontrar texto em um PDF usando C#?
Para encontrar texto em um PDF usando C#, você pode utilizar os recursos de extração de texto do IronPDF. Ao carregar um documento PDF, você pode pesquisar por um texto específico usando expressões regulares ou especificando padrões de texto. O IronPDF fornece métodos para destacar e extrair o texto correspondente.
Quais métodos o IronPDF oferece para pesquisar texto em PDFs?
O IronPDF oferece vários métodos para pesquisar texto em PDFs, incluindo pesquisa básica de texto, pesquisa avançada usando expressões regulares e a capacidade de pesquisar em páginas específicas de um documento. Ele também suporta a extração de texto de layouts complexos e o processamento de conteúdo multilíngue.
É possível extrair texto de páginas específicas de um PDF usando C#?
Sim, usando o IronPDF, você pode extrair texto de páginas específicas dentro de um PDF. Ao especificar os números ou intervalos de páginas, você pode selecionar as seções desejadas do documento, tornando o processo de extração de texto mais eficiente.
Como o IronPDF lida com texto em documentos digitalizados?
O IronPDF consegue processar texto em documentos digitalizados usando OCR (Reconhecimento Óptico de Caracteres). Esse recurso permite converter imagens de texto em texto pesquisável e extraível, mesmo que o texto esteja incorporado em imagens.
Quais são alguns dos desafios comuns na busca de texto em PDFs?
Os desafios comuns na busca de texto em PDFs incluem lidar com variações na codificação de texto, texto fragmentado devido a layouts complexos e texto incorporado em imagens. O IronPDF resolve esses desafios fornecendo recursos robustos de extração de texto e OCR.
Por que a extração de texto é importante para fluxos de trabalho em PDF?
A extração de texto é crucial para automatizar fluxos de trabalho, verificar conteúdo e realizar mineração de dados. Ela permite uma manipulação de dados mais fácil, verificação de conteúdo e aprimora a interação do usuário, tornando o conteúdo estático de PDFs pesquisável e editável.
Quais são os benefícios de usar o IronPDF para extração de texto?
O IronPDF oferece diversas vantagens para extração de texto, incluindo alta precisão, facilidade de uso, compatibilidade multiplataforma e recursos avançados de busca. Ele simplifica o processo de extração de texto de layouts de PDF complexos e suporta extração de texto multilíngue.
Como o IronPDF pode otimizar o desempenho para arquivos PDF grandes?
O IronPDF otimiza o desempenho para arquivos PDF grandes, permitindo que os usuários extraiam texto de páginas ou intervalos específicos, minimizando a carga de processamento. Ele também lida com documentos grandes de forma eficiente, otimizando o uso de memória durante a extração de texto.
O IronPDF é adequado tanto para projetos .NET Framework quanto para projetos .NET Core?
Sim, o IronPDF é compatível com o .NET Framework e o .NET Core, o que o torna adequado para uma variedade de aplicações, incluindo aplicações web e desktop modernas, bem como sistemas legados.
Como posso começar a usar o IronPDF para pesquisa de texto em PDFs?
Para começar a usar o IronPDF para pesquisa de texto em PDFs, você pode baixar uma versão de avaliação gratuita do site deles, seguir a documentação e os tutoriais abrangentes fornecidos e integrar a biblioteca aos seus projetos .NET para aprimorar os recursos de manipulação de PDFs.
O IronPDF é totalmente compatível com o .NET 10 na busca e extração de texto em PDFs?
Sim, o IronPDF é totalmente compatível com o .NET 10, sem necessidade de configuração especial para extração de texto ou funcionalidade de busca. Ele suporta o .NET 10 em todos os tipos de projeto usuais — web, desktop, console e nuvem — e se beneficia das melhorias mais recentes do runtime ao usar as APIs de busca e extração de texto do IronPDF, conforme descrito no tutorial.











