
ASP PDF Görüntüleyici (Geliştirici Eğitimi)
C# ile PDF'lerde Metin Bulmaya Giriş
PDF içinde metin bulmak, özellikle kolay düzenlenebilir veya aranabilir olmayan statik dosyayla çalışırken zorlu bir görev olabilir. Belge iş akışlarını otomatikleştiriyor, arama işlevselliği oluşturuyor, sorgulama ölçütünüze uygun metinleri öne çıkıyor veya verileri çıkartıyor olun, metin çıkarımı geliştiriciler için kritik bir özelliktir.
IronPDF, güçlü bir .NET kütüphanesi olarak, bu süreci basitleştirir ve geliştiricilere PDF'lerden verimli bir şekilde metin çıkartma ve arama gerçekleştirmelerine olanak tanır. Bu makalede, IronPDF kullanarak C# ile PDF'de metin bulmanın yollarını, kod örnekleri ve pratik uygulamaları ile keşfedeceğiz.
C#'de "Metin Bulma" Nedir?
"Metin bul" [Find Text], bir belge, dosya veya diğer veri yapılarına belirli metni veya desenleri arama sürecine atıfta bulunur. PDF dosyaları bağlamında, bir PDF belgesinin metin içeriği içinde belirli kelime, ifadeler veya desenlerin örneklerini tanımlama ve konumlandırma işlemini içerir. Bu işlevsellik, PDF formatında depolanan yapılandırılmamış veya yarı yapılandırılmış verilerle ilgilenildiğinde, endüstriler arasında sayısız uygulama için elzemdir.
PDF Dosyalarında Metni Anlamak
PDF dosyaları, içeriği tutarlı, cihazdan bağımsız bir formatta sunmak için tasarlanmıştır. Ancak, metnin PDF'lerde nasıl saklandığı büyük ölçüde değişebilir. Metin şu şekilde saklanabilir:
Aranabilir Metin: Metin olarak yerleştirildiği için doğrudan çıkartılabilir (örneğin, PDF'ye dönüştürülmüş bir Word belgesinden). Tarama Metni: Görüntü olarak görünülen metin olup, aranabilir metne dönüştürmek için OCR (Optik Karakter Tanıma) gerektirir. Karmaşık Düzenler: Parçalar halinde veya alışılmadık bir kodlamayla saklanan metin, doğru çıkartmayı ve aramayı zorlaştırır.
Bu değişkenlik, PDF'lerde etkili bir metin araması yapmanın genellikle çeşitli içerik türlerini sorunsuz bir şekilde işleyebilen IronPDF gibi özel kütüphaneler gerektirdiği anlamına gelir.
Metin Bulmak Neden Önemlidir?
PDF'lerde metin bulma yeteneği, birçok uygulama için geniş bir uygulama yelpazesi sunar, bunlar arasında:
İş Akışlarını Otomatikleştirme: Anahtar terim veya değerleri PDF belgelerinde belirleyerek fatura, sözleşme veya raporlar gibi görevleri otomatikleştirme.
Veri Çıkartma: Bilgiyi diğer sistemlerde kullanım veya analiz amaçlı çıkartma.
İçerik Doğrulama: Uyumluluk beyanları veya yasal maddeler gibi gereken terim veya ifadelerin belgelerde mevcut olmasını sağlama.
Kullanıcı Deneyimini Artırma: Kullanıcıların hızlı bir şekilde ilgili bilgiyi bulmasına yardımcı olarak belge yönetim sistemlerinde arama işlevselliğini devreye sokma.
Metin Aramada Zorluklar
PDF'lerde metin bulmak, aşağıdaki zorluklar nedeniyle her zaman kolay olmayabilir:
Kodlama Varyasyonları: Bazı PDF'ler metin için özel bir kodlama kullanır ve çıkarımı karmaşıklaştırır. Parçalanmış Metin: Metin birden çok parçaya bölünmüş olabilir, bu da aramaları daha karmaşık hale getirir. Grafikler ve Görüntüler: Görüntülerde gömülü metinlerin çıkartılması için OCR gerektirir. Çok Dilli Destek: Farklı diller, yazı sistemleri veya sağdan sola metinlerle belgeler arasında arama yapmak için güçlü bir işleme gerektirir.
Metin Çıkarma İşlemi için IronPDF Neden Seçilmeli?
IronPDF, .NET ekosisteminde çalışan geliştiriciler için PDF işlemini mümkün olduğunca sorunsuz hale getirmek üzere tasarlanmıştır. Metin çıkarma ve manipülasyon işlemlerini kolaylaştırmak için özelleştirilmiş bir özellik seti sunar.
Anahtar Faydalar
- Kullanım Kolaylığı:
IronPDF, geliştiricilerin zorlu bir öğrenim eğrisi olmadan hızlı başlamasını sağlamak için sezgisel bir API içerir. İster temel metin çıkarımı ister HTML'den PDF'e dönüştürme veya gelişmiş işlemler yapıyor olun, yöntemleri kullanımı kolaydır.
- Yüksek Doğruluk:
Bazı PDF kütüphaneleri, karmaşık düzenler veya yerleşik yazı tipleri içeren PDF'lerle başa çıkmakta zorlanırken, IronPDF metni güvenilir şekilde yüksek bir hassasiyetle çıkarır.
- Çapraz Platform Desteği:
IronPDF, hem .NET Framework hem de .NET Core ile uyumludur, böylece modern web uygulamalarında, masaüstü uygulamalarında ve hatta eski sistemlerde kullanılmasını sağlar.
- Gelişmiş Sorgular için Destek:
Kütüphane, veri madenciliği veya belge indeksleme gibi karmaşık kullanım durumları için uygun hale getiren gelişmiş arama teknikleri, örneğin düzenli ifadeler ve hedeflenmiş çıkarım gibi destekler.
Projenizde IronPDF'i Kurma
IronPDF, NuGet aracılığıyla sunulur, bu da onu .NET projelerinize eklemeyi kolaylaştırır. İşte nasıl başlayacağınız.
Kurulum
IronPDF'i yüklemek için Visual Studio'da NuGet Paket Yöneticisi'ni kullanabilir veya Paket Yöneticisi Konsolu'nda aşağıdaki komutu çalıştırabilirsiniz:
Install-Package IronPdf
Bu, kütüphane ve bağımlılıklarını indirip yükleyecektir.
Temel Kurulum
Kütüphane yüklendikten sonra, IronPDF ad alanına başvurarak projenize dahil etmeniz gerekir. Kod dosyanızın başına aşağıdaki satırı ekleyin:
using IronPdf;using IronPdf;Imports IronPdfKod Örneği: PDF'de Metin Bulma
IronPDF, bir PDF belgesi içinde metin bulma sürecini basitleştirir. Aşağıda, bu hedefe nasıl ulaşılacağını adım adım gösteren bir demo bulunmaktadır.
Bir PDF Dosyasını Yükleme
İlk adım, üzerinde çalışmak istediğiniz PDF dosyasını yüklemektir. Bu, aşağıdaki kodda görüldüğü gibi PdfDocument sınıfı kullanılarak yapılır:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("example.pdf");Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("example.pdf")PdfDocument sınıfı bellekte PDF dosyasını temsil eder, bu sayede metin çıkarma veya içeriği değiştirme gibi çeşitli işlemler yapabilirsiniz. PDF yüklendikten sonra, metni tüm PDF belgesinden veya dosya içindeki belirli bir sayfadan arayabiliriz.
Belirli Metni Arama
PDF yüklendikten sonra, tüm belgenin metin içeriğini çıkarmak için ExtractAllText() yöntemini kullanın. Ardından, standart dize manipülasyon teknikleri kullanarak belirli terimleri arayabilirsiniz:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
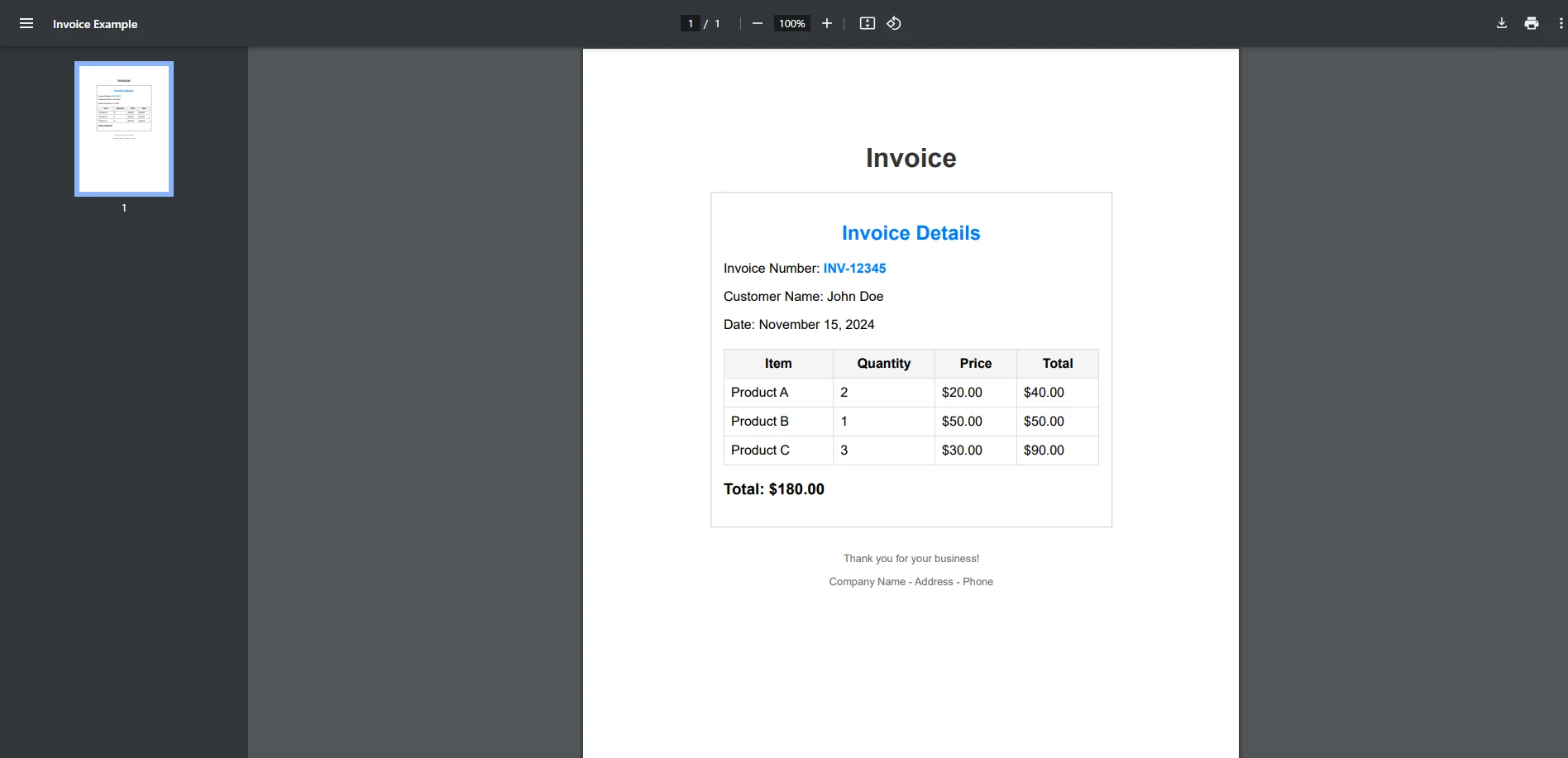
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
string path = "example.pdf";
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile(path);
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for a specific term
string searchTerm = "Invoice";
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
Console.WriteLine(isFound
? $"The term '{searchTerm}' was found in the PDF!"
: $"The term '{searchTerm}' was not found.");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim path As String = "example.pdf"
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile(path)
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for a specific term
Dim searchTerm As String = "Invoice"
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
Console.WriteLine(If(isFound, $"The term '{searchTerm}' was found in the PDF!", $"The term '{searchTerm}' was not found."))
End Sub
End ClassGiriş PDF
Konsol Çıkışı
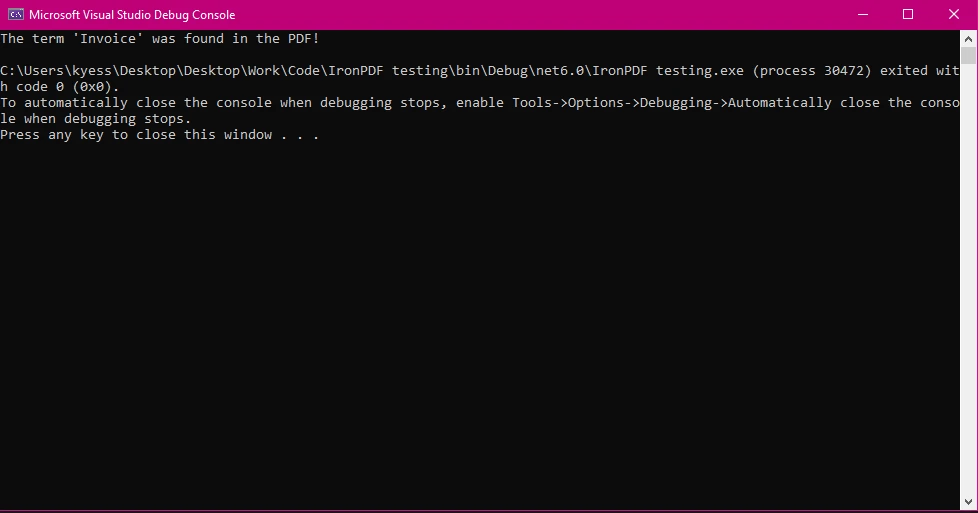
Bu örnek, PDF içinde bir terimin var olup olmadığını kontrol ettiğiniz basit bir durumu gösteriyor. StringComparison.OrdinalIgnoreCase aranan metnin büyük-küçük harf duyarlılığı olmadan bulunmasını sağlar.
Gelişmiş Metin Arama Özellikleri
IronPDF, metin arama yeteneklerini genişleten birkaç gelişmiş özellik sunar.
Düzenli İfadeler Kullanma
Düzenli ifadeler, metin içinde kalıpları bulmak için güçlü bir araçtır. Örneğin, bir PDF'teki tüm e-posta adreslerini bulmak isteyebilirsiniz:
using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
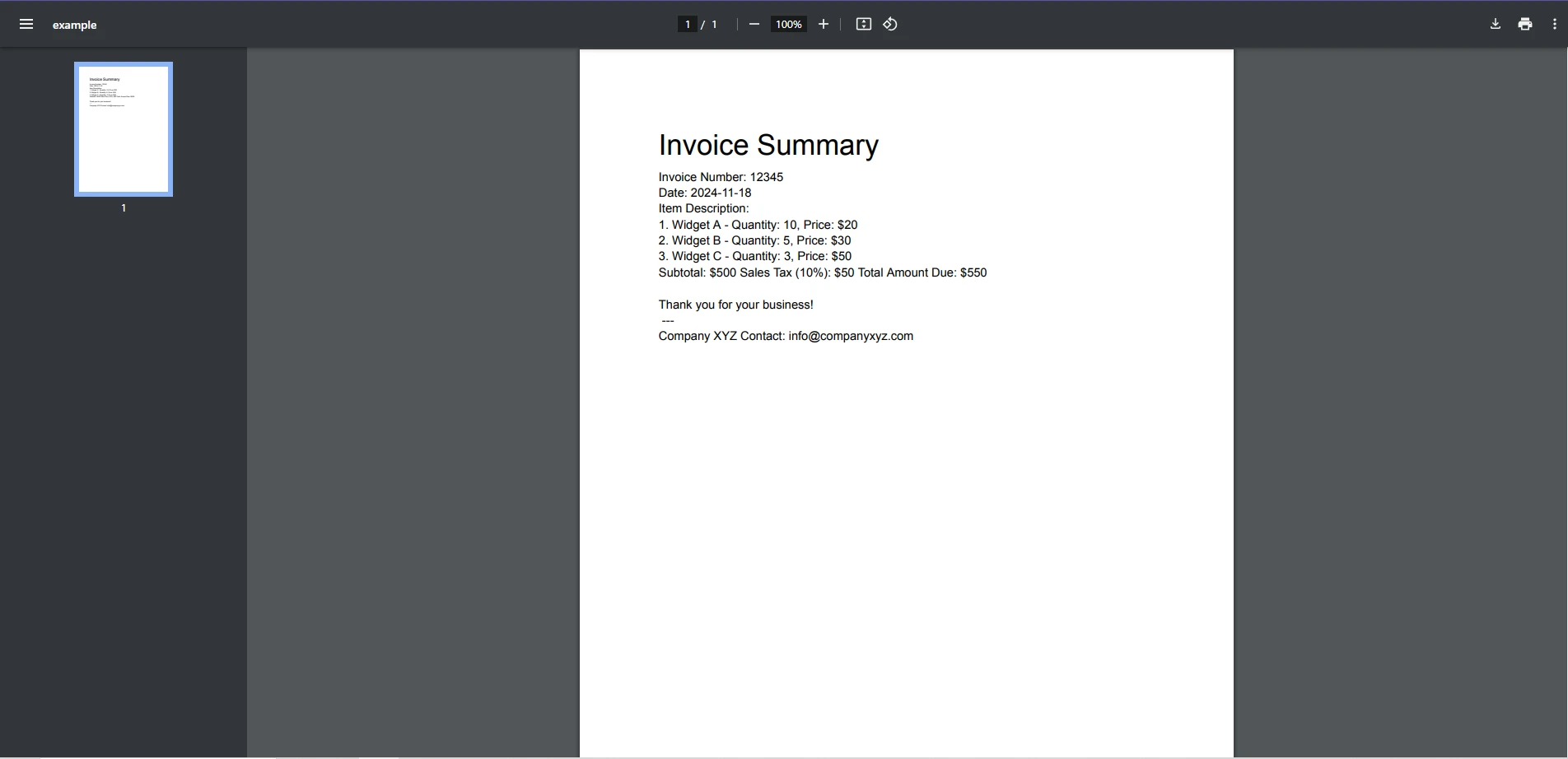
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}using System.Text.RegularExpressions; // Required namespace for using regex
// Extract all text
string pdfText = pdf.ExtractAllText();
// Use a regex to find patterns (e.g., email addresses)
Regex regex = new Regex(@"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}");
MatchCollection matches = regex.Matches(pdfText);
foreach (Match match in matches)
{
Console.WriteLine($"Found match: {match.Value}");
}Imports System.Text.RegularExpressions ' Required namespace for using regex
' Extract all text
Private pdfText As String = pdf.ExtractAllText()
' Use a regex to find patterns (e.g., email addresses)
Private regex As New Regex("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
Private matches As MatchCollection = regex.Matches(pdfText)
For Each match As Match In matches
Console.WriteLine($"Found match: {match.Value}")
Next matchGiriş PDF
Konsol Çıkışı
Bu örnek, belgede bulunan tüm e-posta adreslerini tanımlamak ve yazdırmak için bir regex deseni kullanır.
Belirli Sayfalardan Metin Çıkarma
Bazen sadece bir PDF'in belirli bir sayfası içinde arama yapmanız gerekebilir. IronPDF, PdfDocument.Pages özelliği ile tek tek sayfaları hedeflemenize olanak tanır:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("urlPdf.pdf");
// Extract text from the first page
var pageText = pdf.Pages[0].Text.ToString();
if (pageText.Contains("IronPDF"))
{
Console.WriteLine("Found the term 'IronPDF' on the first page!");
}
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("urlPdf.pdf")
' Extract text from the first page
Dim pageText = pdf.Pages(0).Text.ToString()
If pageText.Contains("IronPDF") Then
Console.WriteLine("Found the term 'IronPDF' on the first page!")
End If
End Sub
End ClassGiriş PDF
Konsol Çıkışı
Bu yaklaşım, büyük PDF'lerle çalışırken performansı optimize etmek için yararlıdır.
Gerçek Dünyada Kullanım Durumları
Sözleşme Analizi
Hukuk profesyonelleri, uzun sözleşmelerdeki anahtar terimleri veya maddeleri otomatik olarak aramak için IronPDF kullanabilir. Örneğin, belgelerde "Fesih Maddesi" veya "Gizlilik"i hızlıca bulun.
Fatura İşleme
Finans veya muhasebe iş akışlarında, IronPDF, toplu PDF dosyalarındaki fatura numaraları, tarihler veya toplam tutarları bulmaya yardımcı olarak işlemleri hızlandırır ve el işi çabalarını azaltır.
Veri Madenciliği
IronPDF, PDF formatında depolanan raporlar veya günlüklerden bilgi çıkarmak ve analiz etmek için veri hatlarına entegre edilebilir. Bu, büyük miktarlarda yapılandırılmamış verilerle uğraşan endüstriler için özellikle yararlıdır.
Sonuç
IronPDF, sadece PDF'lerle çalışmak için bir kütüphane değildir; devlerin PDF işlemlerini kolaylıkla gerçekleştirmelerine olanak tanıyan eksiksiz bir araç setidir. Metin çıkarımı yapmaktan ve belirli terimleri bulmaktan, düzenli ifadelerle gelişmiş desen eşleme işlemlerini yapmaya kadar, IronPDF, aksi takdirde önemli el işi çaba veya birçok kütüphane gerektirebilecek görevleri kolaylaştırır.
PDF'lerde metin çıkarma ve arama yeteneği, çeşitli endüstrilerde güçlü kullanım durumlarını akeyarlar. Hukuk profesyonelleri anahtar maddeleri otomatik olarak arayabilir, muhasebeciler fatura işlemlerini hızlandırabilir ve her alandaki geliştiriciler, verimli belge iş akışları oluşturabilir. Metin çıkarımında kesinlik sunarak, .NET Core ve Framework uyumluluğu ile gelişmiş yetenekler sunarak, IronPDF, PDF ihtiyaçlarınızı zahmetsizce karşılar.
Bugün Başlayın!
PDF işlemi geliştirmelerinizi yavaşlatmasın. Metin çıkarımı işlemlerinizi kolaylaştırmak ve üretkenliğinizi artırmak için bugün IronPDF kullanmaya başlayın. İşte nasıl başlayabileceğiniz:
- Ücretsiz Deneme Sürümünü İndirin: IronPDF ziyaret edin.
- Dokümantasyonu İnceleyin: IronPDF dokümantasyonunda ayrıntılı kılavuzlar ve örnekleri keşfedin.
- Başlayın: .NET uygulamalarınıza güçlü PDF işlevselliği uygulayın ve minimum çabayla kodlayın.
IronPDF ile belge iş akışlarınızı optimize etmeye ilk adımı atın. Tam potansiyelini açığa çıkarın, geliştirme sürecinizi geliştirin ve sağlam, PDF destekli çözümleri her zamankinden daha hızlı sunun.
Sıkça Sorulan Sorular
C# ile PDF içinde metni nasıl bulabilirim?
C# ile PDF içinde metin bulmak için, IronPDF'nin metin çıkartma yeteneklerinden yararlanabilirsiniz. Bir PDF belgesi yükleyerek, regular expressions kullanarak veya metin kalıplarını belirterek belirli metni arayabilirsiniz. IronPDF, eşleşen metni vurgulamanız ve çıkarmanız için yöntemler sağlar.
IronPDF, PDF'lerde metin aramak için hangi yöntemleri sunar?
IronPDF, PDF'lerde metin aramak için çeşitli yöntemler sunar, temel metin arama, regular expressions kullanarak gelişmiş arama ve belgenin belirli sayfalarında arama yapabilme dahil. Ayrıca karmaşık yerleşimlerden metin çıkartmayı ve çok dilli içeriği işlemeyi de destekler.
C# ile bir PDF'den belirli sayfalardan metin çıkartabilir miyim?
Evet, IronPDF kullanarak bir PDF içindeki belirli sayfalardan metin çıkartabilirsiniz. Sayfa numaralarını veya aralıklarını belirleyerek belge içindeki istediğiniz bölümleri hedef alabilir, böylece metin çıkartma sürecini daha verimli hale getirebilirsiniz.
IronPDF, taranmış belgelerdeki metni nasıl işler?
IronPDF, taranmış belgelerdeki metni OCR (Optik Karakter Tanıma) kullanarak işler. Bu özellik, metin görüntülerini, görüntülere gömülü olan metin olsa bile, aranabilir ve çıkartılabilir metne dönüştürmelerine olanak tanır.
PDF'lerde metin aramada yaygın zorluklar nelerdir?
PDF'lerde metin aramada yaygın zorluklar metin kodlama varyasyonları, karmaşık yerleşimler nedeniyle parçalanmış metin ve görüntüler içine gömülü olan metinleri içerir. IronPDF bu zorlukları, sağlam metin çıkartma ve OCR yetenekleri sağlayarak çözer.
Metin çıkartma, PDF iş akışları için neden önemlidir?
Metin çıkartma, iş akışlarını otomatikleştirmek, içerik doğrulama ve veri madenciliği için önemlidir. Statik PDF içeriğini aranabilir ve düzenlenebilir hale getirerek veri manipülasyonunu, içerik doğrulamayı kolaylaştırır ve kullanıcı etkileşimini artırır.
Metin çıkartma için IronPDF kullanmanın faydaları nelerdir?
IronPDF, metin çıkartma için yüksek doğruluk, kullanım kolaylığı, platformlar arası uyumluluk ve gelişmiş arama özellikleri dahil olmak üzere birçok fayda sunar. Karmaşık PDF yerleşimlerinden metin çıkartma sürecini basitleştirir ve çok dilli metin çıkartma destekler.
IronPDF, büyük PDF dosyalarının performansını nasıl optimize eder?
IronPDF, büyük PDF dosyalarının performansını, kullanıcıların belirli sayfalardan veya aralıklardan metin çıkartmalarına izin vererek optimize eder, bu da işlem yükünü minimize eder. Metin çıkartma sırasında bellek kullanımını optimize ederek büyük belgeleri etkin bir şekilde yönetir.
IronPDF, hem .NET Framework hem de .NET Core projeleri için uygun mu?
Evet, IronPDF, hem .NET Framework hem de .NET Core ile uyumludur, böylece modern web ve masaüstü uygulamaları yanı sıra eski sistemler için de uygundur.
PDF'lerde metin aramak için IronPDF kullanmaya nasıl başlayabilirim?
IronPDF'yi PDF'lerde metin aramak için kullanmaya başlamak için, web sitesinden ücretsiz bir deneme versiyonu indirip, sunulan kapsamlı belgeler ve eğitimleri takip edebilir, kütüphaneyi .NET projelerinize entegre ederek PDF işleme yeteneklerini artırabilirsiniz.
IronPDF, PDF'lerde metin bulma ve çıkartmada .NET 10 ile tamamen uyumlu mu?
Evet—IronPDF, metin çıkartma veya arama işlevselliği için özel bir yapılandırma gerektirmeksizin ve tüm olağan proje türlerini destekleyerek .NET 10 ile tamamen uyumludur—web, masaüstü, konsol ve bulut. IronPDF'nin metin arama ve çıkartma API'lerini kullanırken, öğreticide tarif edildiği gibi en son çalışma süresi iyileştirmelerinden faydalanır.











