
Jak analizować plik PDF w VB.NET
W tym samouczku przedstawiono, jak programowo wyodrębniać teksty i obrazy z plików PDF przy pomocy doskonałej obsługi oferowanej przez IronPDF.
Jak analizować plik PDF w VB.NET
- Pobierz bibliotekę IronPDF C# do analizowania plików PDF
- Wykorzystaj metodę
FromFiledo analizy pliku PDF w VB.NET - Wyodrębnij tekst z otwartego pliku PDF za pomocą metody
ExtractAllText - Użyj metody
ExtractTextFromPages,aby wyodrębnić tekst z określonych stron - Wyodrębnij obrazy z otwartego pliku PDF za pomocą metody
ExtractRawImagesFromPage
IronPDF
Funkcje
Wydajna konwersja plików PDF. Prawie wszystko, co potrafi maszyna, potrafi również IronPDF. Dzięki tej bibliotece PDF programiści mogą szybko tworzyć, odczytywać treści tekstowe, zapisywać, wczytywać i przetwarzać pliki PDF.
IronPDF konwertuje HTML na plik PDF przy pomocy silnika Chrome. Oprócz Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms i WPF. IronPDF obsługuje również aplikacje Xamarin, Blazor, Unity i HoloLens. IronPDF obsługuje zarówno aplikacje Microsoft .NET, jak i .NET Core (zarówno pakiety internetowe ASP.NET, jak i tradycyjne pakiety Windows). IronPDF może służyć do tworzenia estetycznych plików PDF.
IronPDF umożliwia tworzenie plików PDF przy użyciu HTML5, JavaScript, CSS i obrazów. IronPDF posiada również potężny konwerter HTML na PDF, który integruje się z PDF. W IronPDF dostępny jest wydajny mechanizm konwersji plików PDF wykorzystujący silnik renderujący Chromium. Nie jest on również powiązany z żadnymi zewnętrznymi źródłami.
- Obraz PDF można utworzyć z różnych źródeł, w tym HTML, HTML5, ASPX oraz Razor/MVC View. Zarówno pliki HTML, jak i grafiki można konwertować do formatu PDF.
- Narzędzia, które można wykorzystać do pracy z interaktywnymi plikami PDF, obejmują wypełnianie i przesyłanie interaktywnych formularzy.
- Łączenie i dzielenie plików PDF, wyodrębnianie tekstu i obrazów z plików PDF, wyszukiwanie tekstu w plikach PDF, rasteryzacja plików PDF do obrazów, zmiana rozmiaru czcionki i konwersja plików PDF.
- Umożliwia weryfikację formularzy logowania HTML przy użyciu agentów użytkownika, serwerów proxy, plików cookie, nagłówków HTTP i zmiennych formularza.
- Dostęp do zabezpieczonych dokumentów jest możliwy dzięki IronPDF po podaniu nazwy użytkownika i hasła.
- IronPDF to program, który odczytuje tekst w plikach PDF i uzupełnia luki.
- Umożliwia dodawanie tekstu, obrazów, zakładek, znaków wodnych i nie tylko.
- Możesz utworzyć plik PDF na podstawie pliku CSS.
Aby uzyskać więcej informacji, odwiedź stronę z informacjami o licencjach IronPDF, gdzie znajdziesz bezpłatny klucz z ograniczonym dostępem oraz wersję profesjonalną.
 IronPDF – formatowanie czcionek
IronPDF – formatowanie czcionek
Wyodrębnij tekst z pliku PDF
IronPDF może również odczytywać i wyodrębniać tekst z plików PDF przy pomocy bibliotek IronPDF. Poniżej znajduje się fragment kodu IronPDF, który może służyć do analizy istniejących plików PDF.
Wyodrębnij tekst ze wszystkich stron
Poniższy przykład kodu pokazuje pierwszą metodę pozyskiwania całej zawartości pliku PDF jako ciągu znaków za pomocą zaledwie kilku wierszy.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModulePowyższy przykładowy kod pokazuje, jak użyć metody FromFile do odczytania pliku PDF z istniejącego pliku i przekształcenia go w obiekt dokumentu PDF. Obiekt udostępnia metodę o nazwie ExtractAllText, która wyodrębnia zwykły tekst z pliku PDF i przekształca go w ciąg znaków.
Wyodrębnij tekst według numeru strony
Poniższy przykładowy kod pokazuje, jak wyodrębnić dane z pliku PDF na podstawie numeru strony.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModulePowyższy kod pokazuje, jak odczytać plik PDF z istniejącego pliku i przekształcić go w obiekt dokumentu PDF za pomocą funkcji FromFile. Dostęp do tekstów i obrazów w pliku PDF można uzyskać za pomocą tego obiektu. Obiekt oferuje metodę o nazwie ExtractTextFromPage, która pozwala wysłać numer strony jako parametr, aby uzyskać ciąg znaków zawierający każde słowo, które znajdowało się na tej stronie pliku PDF.
Wyodrębnij tekst między stronami
Poniższy kod pokazuje, jak wyodrębnić dane z wielu stron.
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModulePowyższy kod pokazuje, jak użyć metody FromFile do odczytania pliku PDF z istniejącego pliku i przekształcenia go w obiekt dokumentu PDF. Ten obiekt umożliwia przeglądanie tekstu i obrazów w pliku PDF. Obiekt posiada metodę o nazwie ExtractTextFromPages, której można użyć do uzyskania ciągu znaków zawierającego całą treść tekstową na określonych stronach dokumentu poprzez przekazanie listy numerów stron jako parametru. Poniżej po lewej stronie znajduje się plik PDF źródłowy, a po prawej stronie wyodrębnione dane.
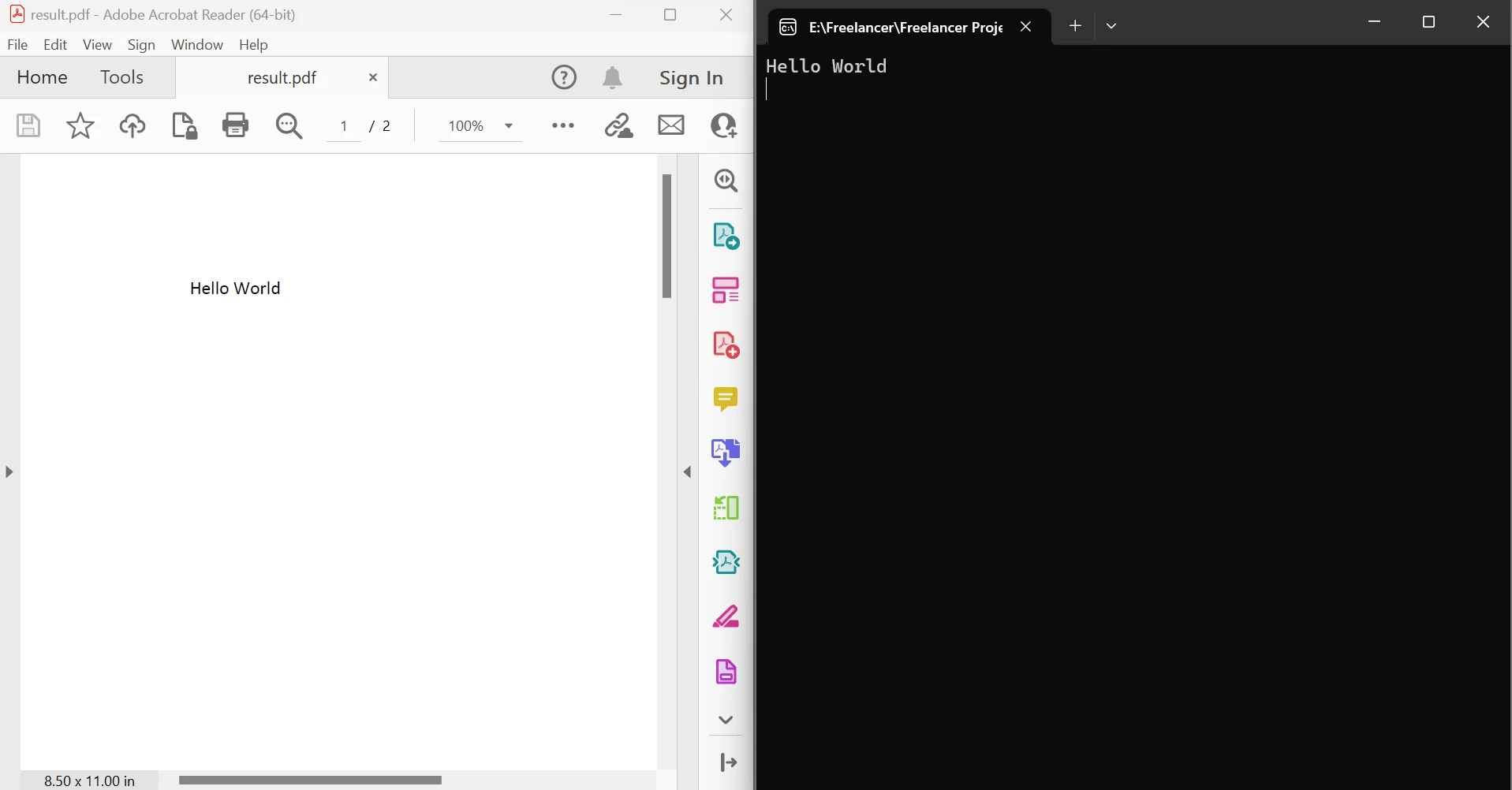 Wyodrębnij tekst pomiędzy stronami
Wyodrębnij tekst pomiędzy stronami
Wyodrębnij obraz z pliku PDF
IronPDF udostępnia listę metod służących do wyodrębniania obrazów, takich jak:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
Każda metoda umożliwia wyodrębnianie obrazów z jednej lub wielu stron dokumentu.
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModulePowyższy kod pokazuje, jak odczytać dokument z istniejącego pliku i przekształcić go w obiekt dokumentu PDF za pomocą funkcji FromFile. Przekazując numer strony do metody ExtractRawImagesFromPage obiektu, można uzyskać listę bajtów zawierającą wszystkie obrazy, które znajdowały się na tej stronie dokumentu. Za pomocą pętli For Each każdy strumień bajtów jest przetwarzany i zamieniany na strumień pamięci, a następnie na Bitmap, co ułatwia zapisywanie obrazów. Poniższy obrazek przedstawia wynik działania powyższego kodu.
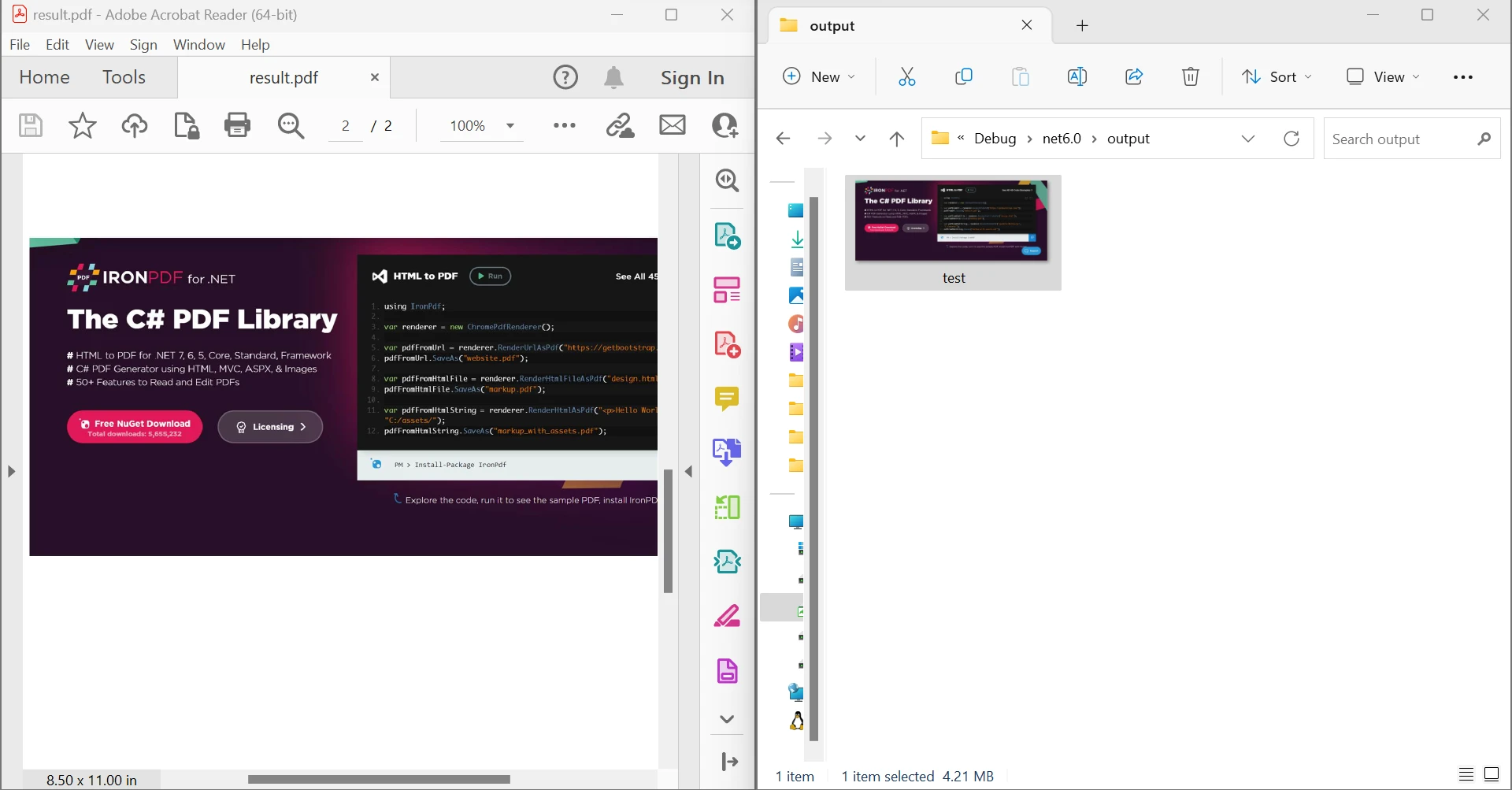 Wyodrębnij obrazy z pliku PDF
Wyodrębnij obrazy z pliku PDF
Aby dowiedzieć się więcej o samouczku dotyczącym kodu API IronPDF, zapoznaj się z dokumentacją IronPDF. Możesz również zapoznać się z innymi samouczkami, aby dowiedzieć się, jak analizować tekst w plikach PDF przy użyciu języka C#.
Wnioski
Licencja deweloperska biblioteki IronPDF jest bezpłatna. W przypadku korzystania z IronPDF w środowisku produkcyjnym można nabyć różne licencje w zależności od potrzeb programisty. Plan Lite zaczyna się od $799 i nie wiąże się z żadnymi stałymi kosztami. Dostępne są również opcje dystrybucji w modelu SaaS i OEM. Wszystkie licencje obejmują aktualizacje, roczną pomoc techniczną oraz licencję bezterminową. Są one również przydatne w produkcji, wdrażaniu i rozwoju. Jest to zakup jednorazowy. Dostępne są dodatkowe bezpłatne licencje ograniczone czasowo. Zapoznaj się z wyczerpującymi informacjami na temat licencji IronPDF, aby przeczytać pełne szczegóły dotyczące cen i licencji IronPDF. IronPDF zapewnia również bezpłatne licencje na ochronę przed kopiowaniem.
Często Zadawane Pytania
Jak moge wydobyc tekst z PDF w VB.NET?
Korzystajac z biblioteki IronPDF, mozesz wydobyc tekst z PDF, uzywajac metody ExtractAllText. Pozwala to na pobranie tekstu ze wszystkich stron dokumentu PDF w projekcie VB.NET.
Czy mozna wydobyc obrazy z okreslonych stron PDF za pomoca VB.NET?
Tak, IronPDF pozwala na wydobycie obrazow z okreslonych stron przy uzyciu metody ExtractRawImagesFromPage. Ta metoda zwraca dane obrazu jako tablice bajtow, ktore mozna przeksztalcic w pliki obrazow.
Jak moge konwertowac tresc HTML do dokumentu PDF w VB.NET?
IronPDF oferuje zaawansowana konwersje HTML do PDF z uzyciem silnika renderujacego Chromium. Mozesz uzywac metod takich jak RenderHtmlAsPdf, aby efektywnie konwertowac lancuchy lub pliki HTML do dokumentow PDF.
Jakie sa korzysci z korzystania z IronPDF do analizowania PDF w aplikacjach VB.NET?
IronPDF dostarcza wszechstronne API do wydobywania tekstu i obrazow, wspiera konwersje HTML do PDF i jest kompatybilny z rozmaitymi platformami .NET, wlaczajac ASP.NET, Windows Forms i Blazor. Oferuje rowniez rozne opcje licencyjne, aby dopasowac sie do potrzeb rozwoju i produkcji.
Jak zintegrowac IronPDF z moim projektem VB.NET?
Aby zintegrowac IronPDF, pobierz biblioteke z NuGet i dodaj do swojego projektu VB.NET. Umozliwi to dostep do metod sluzacych do analizowania i manipulacji plikami PDF programowo.
Czy IronPDF radzi sobie z zadaniami zarowno analizy, jak i konwersji PDF?
Tak, IronPDF jest zaprojektowany do radzenia sobie z zadaniami analizy (ekstrakcja tekstu i obrazu) oraz konwersji (takimi jak HTML do PDF) efektywnie, co czyni go kompleksowym rozwiazaniem do manipulacji PDF w VB.NET.
Jakie opcje licencyjne są dostępne dla IronPDF?
IronPDF oferuje darmowa licencje rozwojowa i rozne licencje produkcyjne, w tym Lite, SaaS i OEM do redystrybucji. Te licencje obejmuja aktualizacje i wsparcie przez rok, dostosowujac sie do zroznicowanych potrzeb projektowych.
Czy IronPDF jest zalezne od jakichkolwiek zewnetrznych zasobow dla swojej funkcjonalnosci?
Nie, IronPDF jest samodzielne i uzywa wewnetrznie silnika renderujacego Chromium, zapewniajac niezawodna funkcjonalnosc bez polegania na zewnetrznych zasobach dla konwersji i analizy PDF.
Czy IronPDF obsluguje .NET 10 i jakie korzysci przynosi deweloperom VB.NET?
Tak, IronPDF w pelni obsluguje .NET 10, wraz z wczesniejszymi wersjami jak .NET 9, 8, 7, 6, Core, Standard i Framework. Oznacza to, ze projekty VB.NET kierujace sie na .NET 10 moga uzywac IronPDF bez dodatkowej konfiguracji. Deweloperzy korzystaja z nowych ulepszen wydajnosciowych w czasie wykonywania w .NET 10 — takich jak zmniejszone alokacje stosu, lepsze optymalizacje czasu wykonywania & JIT — co ulepsza generacje PDF, ekstrakcje tekstu/obrazu i renderowanie HTML do PDF.














