如何在.NET MAUI中查看PDF(逐步)教程
本教程介绍如何通过 IronPDF 的一流支持以编程方式从 PDF 文件中提取文本和图像。
如何在VB.NET中解析PDF文件
- 下载 IronPDF C# 库以解析 PDF 文件。
- 在 VB.NET 中利用
FromFile方法解析 PDF 文件 - 使用
ExtractAllText方法从打开的 PDF 中提取文本 - 使用
ExtractTextFromPages方法从特定页面中提取文本 - 使用
ExtractRawImagesFromPage方法从打开的 PDF 中提取图像
IronPDF
特点
高效的 PDF 转换。 几乎任何机器可以做的事情,IronPDF 都可以做到。 多亏了这个 PDF 库,开发人员可以快速创建、读取文本内容、写入、加载和操作 PDF。
IronPDF 在 Chrome 引擎的帮助下,将 HTML 转换为 PDF 记录。它支持 Windows Forms、HTML、ASPX、Razor HTML、.NET Core、ASP.NET、Windows Forms 和 WPF。 IronPDF 还支持 Xamarin、Blazor、Unity 和 HoloLens 应用程序。 IronPDF 支持 Microsoft .NET 和 .NET Core 应用程序(包括 ASP.NET Web 套件和传统 Windows 套件)。 IronPDF 可用于制作美观的 PDF。
IronPDF 可以使用 HTML5、JavaScript、CSS 和图像创建 PDF。 IronPDF 还拥有强大的 HTML 转 PDF 转换器,它与 PDF 集成。 IronPDF 利用 Chromium 渲染引擎提供了强大的 PDF 转换机制。它不依赖于任何外部来源。
- PDF 图像可以从多种来源创建,包括 HTML、HTML5、ASPX 和 Razor/MVC 视图。 HTML 和图像资源都可以转换为 PDF。
- 可用于处理交互式PDF的工具包括填写和提交交互式表单。
- 合并和拆分PDF,提取文字和图像从PDF文件,搜索PDF文件中的文本,光栅化PDF为图像,改变字体大小和转换PDF文件。
- 它允许使用用户代理、代理、cookie、HTTP 头和表单变量验证 HTML 登录表单。
- 通过提供用户名和密码,IronPDF 可以访问受保护的文档。
- IronPDF 是一个读取 PDF 文本并填补空白的程序。
- 允许添加文本、图像、书签、水印等。
- 您可以从 CSS 文件创建 PDF。
欲了解更多详情,请访问此IronPDF 许可信息页面以获取免费限定密钥和专业版本。
 IronPDF 字体格式化
IronPDF 字体格式化
从 PDF 文件中提取文本
IronPDF 还可以借助 IronPDF 库读取和提取 PDF 文件中的文本。 下面是可用于检查当前 PDF 文件的 IronPDF 代码模式。
从所有页面中提取文本
下面的代码示例演示了第一种方法,以仅用几行代码获取所有 PDF 内容为字符串。
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End Module上面的示例代码演示如何使用FromFile方法从现有文件中读取PDF并将其转换为PDF文档对象。 该对象提供了一个名为ExtractAllText的方法,能够从PDF中提取纯文本并将其转换为字符串。
按页码提取文本
下面的示例代码说明了如何使用页码从 PDF 文件中提取数据。
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End Module上面的代码展示如何使用FromFile函数从现有文件中读取PDF并将其转换为PDF文档对象。 使用此对象可访问 PDF 中的文本和图像。 该对象提供了一个名为ExtractTextFromPage的方法,可以通过发送页面编号作为参数来获取包含该PDF页面上每个单词的字符串。
在页面之间提取文本
下面的代码显示了如何提取多个页面之间的数据。
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End Module上面的代码演示如何使用FromFile方法从现有文件中读取PDF并将其转换为PDF文档对象。 此对象允许检查 PDF 中的文本和图像。 该对象具有一个名为ExtractTextFromPages的方法,可以通过传递页面编号列表作为参数来获得包含文档给定页面上所有文本内容的字符串。 左侧是源 PDF,右侧是提取的数据。
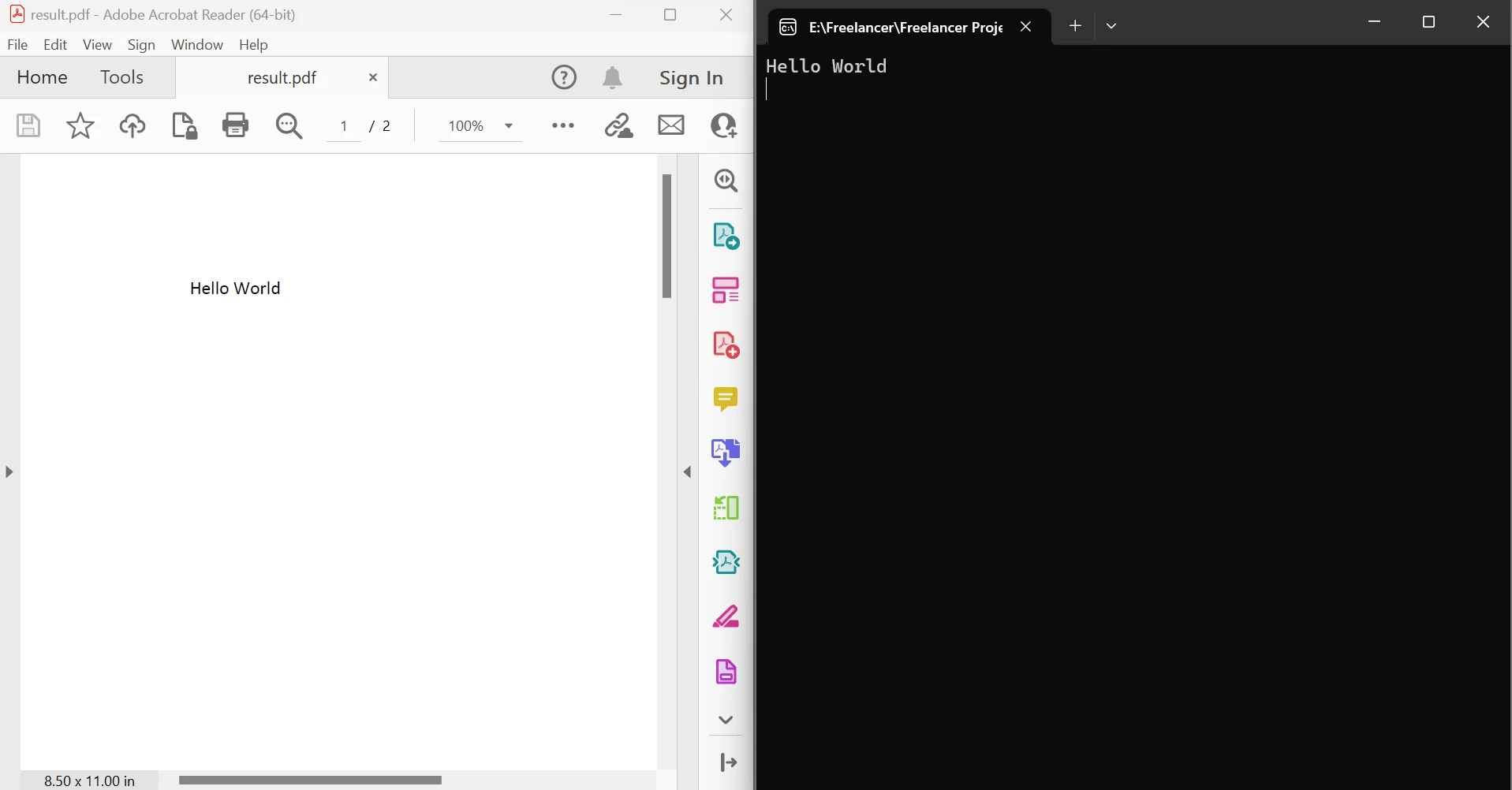 在页面之间提取文本输出
在页面之间提取文本输出
从 PDF 文件中提取图像
IronPDF 提供了一系列方法以提取图像,例如:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
每种方法都允许从文档的一个或多个页面中提取图像。
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleImports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End Module上面的代码展示如何使用FromFile函数从现有文件中读取文档并将其转换为PDF文档对象。 通过将页面编号传递给对象的ExtractRawImagesFromPage方法,可以获得包含文档该页上每幅图片的字节列表。 使用Bitmap,以帮助保存图片。 下面的图像显示了上述代码的输出。
 从 PDF 提取图像输出
从 PDF 提取图像输出
欲了解更多有关 IronPDF API 代码教程的信息,请参阅 IronPDF 文档。 您还可以访问其他教程,学习如何使用 C# 解析 PDF 文本。
结论
库 IronPDF 的开发许可证是免费的。 若在生产环境中使用 IronPDF,可根据开发者的需求购买不同的许可证。 Lite计划从$999开始,无持续费用。 还提供 SaaS 和 OEM 重新分发选项。 所有许可证包括更新、一年的产品支持和永久许可证。 它们同样适用于制造、临时与开发环境。 这是一项一次性购买。 还有其他免费、时间有限的许可证可用。 请访问 全面的 IronPDF 许可信息,阅读 IronPDF 的完整定价和许可详情。 IronPDF 还提供免费的用于复制保护的许可证。
常见问题解答
如何在 VB.NET 中从 PDF 中提取文本?
using IronPDF 库,您可以通过使用 ExtractAllText 方法从 PDF 中提取文本。这允许您在 VB.NET 项目中从 PDF 文档的所有页面检索文本。
能否使用 VB.NET 从 PDF 的特定页面中提取图像?
是的,IronPDF 允许您使用其 ExtractRawImagesFromPage方法从特定页面提取图像。该方法将图像数据以字节数组形式返回,您可以将其转换为图像文件。
如何在 VB.NET 中将 HTML 内容转换为 PDF 文档?
IronPDF 使用 Chromium 渲染引擎提供强大的 HTML 到 PDF 转换。您可以使用RenderHtmlAsPdf 等方法高效地将 HTML 字符串或文件转换为 PDF 文档。
在 VB.NET 应用程序中使用 IronPDF 进行 PDF 解析有哪些优点?
IronPDF 提供用于提取文本和图像的多功能 API,支持 HTML 到 PDF 的转换,并兼容各种 .NET 平台,包括 ASP.NET、Windows Forms 和 Blazor。它还提供多种许可选项,以满足开发和生产需求。
如何将 IronPDF 集成到我的 VB.NET 项目中?
要集成 IronPDF,请从 NuGet 下载库并添加到您的 VB.NET 项目中。这样您就可以以编程方式访问其解析和操作 PDF 文件的方法。
IronPDF 能否同时处理 PDF 解析和转换任务?
是的,IronPDF 的设计能够高效地同时处理解析(文本和图像提取)和转换任务(如 HTML 到 PDF),使其成为 VB.NET 中 PDF 操作的综合解决方案。
IronPDF有哪些许可选项?
IronPDF 提供免费的开发许可证和各种生产许可证,包括 Lite、SaaS 和 OEM 重新分发。这些许可证包括一年的更新和支持,满足不同的项目需求。
IronPDF 的功能依赖于任何外部资源吗?
不,IronPDF 是自包含的,并在内部使用 Chromium 渲染引擎,确保在 PDF 转换和解析中具有稳健的功能,不依赖外部资源。
IronPDF 是否支持 .NET 10?它能为 VB.NET 开发人员带来哪些好处?
是的,IronPDF 完全支持 .NET 10,以及之前的版本,例如 .NET 9、8、7、6、Core、Standard 和 Framework。这意味着面向 .NET 10 的 VB.NET 项目无需额外配置即可使用 IronPDF。开发人员可以受益于 .NET 10 中新增的运行时性能改进,例如减少堆分配、改进运行时和 JIT 优化,这些改进增强了 PDF 生成、文本/图像提取以及 HTML 到 PDF 的渲染性能。