
Como adicionar números de página em um PDF usando C#
Este tutorial apresenta como extrair textos e imagens de arquivos PDF programaticamente, com suporte de primeira classe do IronPDF.
Como analisar um arquivo PDF em VB.NET
- Baixe a biblioteca IronPDF C# para analisar arquivos PDF.
- Utilize o método
FromFilepara analisar um arquivo PDF em VB .NET. - Extrair texto de um PDF aberto com o método
ExtractAllText - Utilize o método
ExtractTextFromPagespara extrair texto de determinadas páginas. - Extrair imagens de um PDF aberto com o método
ExtractRawImagesFromPage
IronPDF
Características
Conversão eficiente de PDFs. O IronPDF também consegue fazer praticamente tudo que uma máquina pode fazer. Graças a esta biblioteca de PDF, os desenvolvedores podem criar, ler conteúdo de texto, escrever, carregar e manipular PDFs rapidamente.
O IronPDF converte HTML em um documento PDF utilizando o mecanismo do Chrome. Ele é compatível com Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms e WPF. O IronPDF também oferece suporte a aplicativos Xamarin, Blazor, Unity e HoloLens. O IronPDF é compatível com aplicações Microsoft .NET e .NET Core (tanto pacotes Web ASP.NET quanto pacotes convencionais do Windows). O IronPDF pode ser usado para criar PDFs visualmente atraentes.
O IronPDF pode criar um PDF usando HTML5, JavaScript, CSS e imagens. O IronPDF também possui um poderoso conversor de HTML para PDF que se integra ao PDF. O IronPDF possui um mecanismo robusto de conversão de PDF que utiliza o motor de renderização Chromium. Além disso, é independente de quaisquer fontes externas.
- Uma imagem em PDF pode ser criada a partir de diversas fontes, incluindo HTML, HTML5, ASPX e Razor/MVC View. Tanto arquivos HTML quanto imagens podem ser convertidos para PDF.
- As ferramentas que podem ser usadas para trabalhar com PDFs interativos incluem o preenchimento e o envio de formulários interativos .
- Mesclar e dividir PDFs , extrair texto e imagens de arquivos PDF, pesquisar texto em arquivos PDF, rasterizar PDFs em imagens , alterar o tamanho da fonte e converter arquivos PDF.
- Permite a verificação de formulários de login HTML usando agentes de usuário, proxies, cookies, cabeçalhos HTTP e variáveis de formulário.
- O IronPDF permite o acesso a documentos protegidos mediante o fornecimento de nomes de usuário e senhas.
- O IronPDF é um programa que lê texto em PDF e preenche as lacunas.
- Permite adicionar texto, imagens, marcadores , marcas d'água e muito mais.
- Você pode criar um arquivo PDF a partir de um arquivo CSS.
Para obter mais detalhes, visite esta página de informações sobre licenciamento do IronPDF para obter uma chave limitada gratuita e a versão profissional.
 IronPDF- Formatação de fontes
IronPDF- Formatação de fontes
Extrair texto de um arquivo PDF
O IronPDF também pode ler e extrair texto de arquivos PDF com a ajuda das bibliotecas do IronPDF . A seguir, apresentamos um padrão de código IronPDF que pode ser usado para examinar arquivos PDF existentes.
Extrair texto de todas as páginas
O exemplo de código abaixo demonstra o primeiro método para obter todo o conteúdo do PDF como uma string com apenas algumas linhas.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleO código de exemplo acima demonstra como usar o método FromFile para ler um PDF de um arquivo existente e convertê-lo em um objeto de documento PDF. O objeto fornece um método chamado ExtractAllText que extrai texto simples do PDF e o transforma em uma string.
Extrair texto por número de página
O código de exemplo abaixo mostra como extrair dados de um arquivo PDF usando o número da página.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleO código acima mostra como ler um PDF de um arquivo existente e transformá-lo em um objeto de documento PDF usando a função FromFile. É possível acessar textos e imagens no PDF usando este objeto. O objeto oferece um método chamado ExtractTextFromPage que permite enviar um número de página como parâmetro para obter uma string que contém cada palavra que estava naquela página do PDF.
Extrair texto entre páginas
O código abaixo mostra como extrair dados entre várias páginas.
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleO código acima demonstra como usar o método FromFile para ler um PDF de um arquivo existente e convertê-lo em um objeto de documento PDF. Este objeto permite examinar o texto e as imagens no PDF. O objeto tem um método chamado ExtractTextFromPages que pode ser usado para obter uma string que inclui todo o conteúdo de texto nas páginas dadas do documento, passando uma lista de números de página como parâmetro. Abaixo, à esquerda, encontra-se o PDF original e, à direita, os dados extraídos.
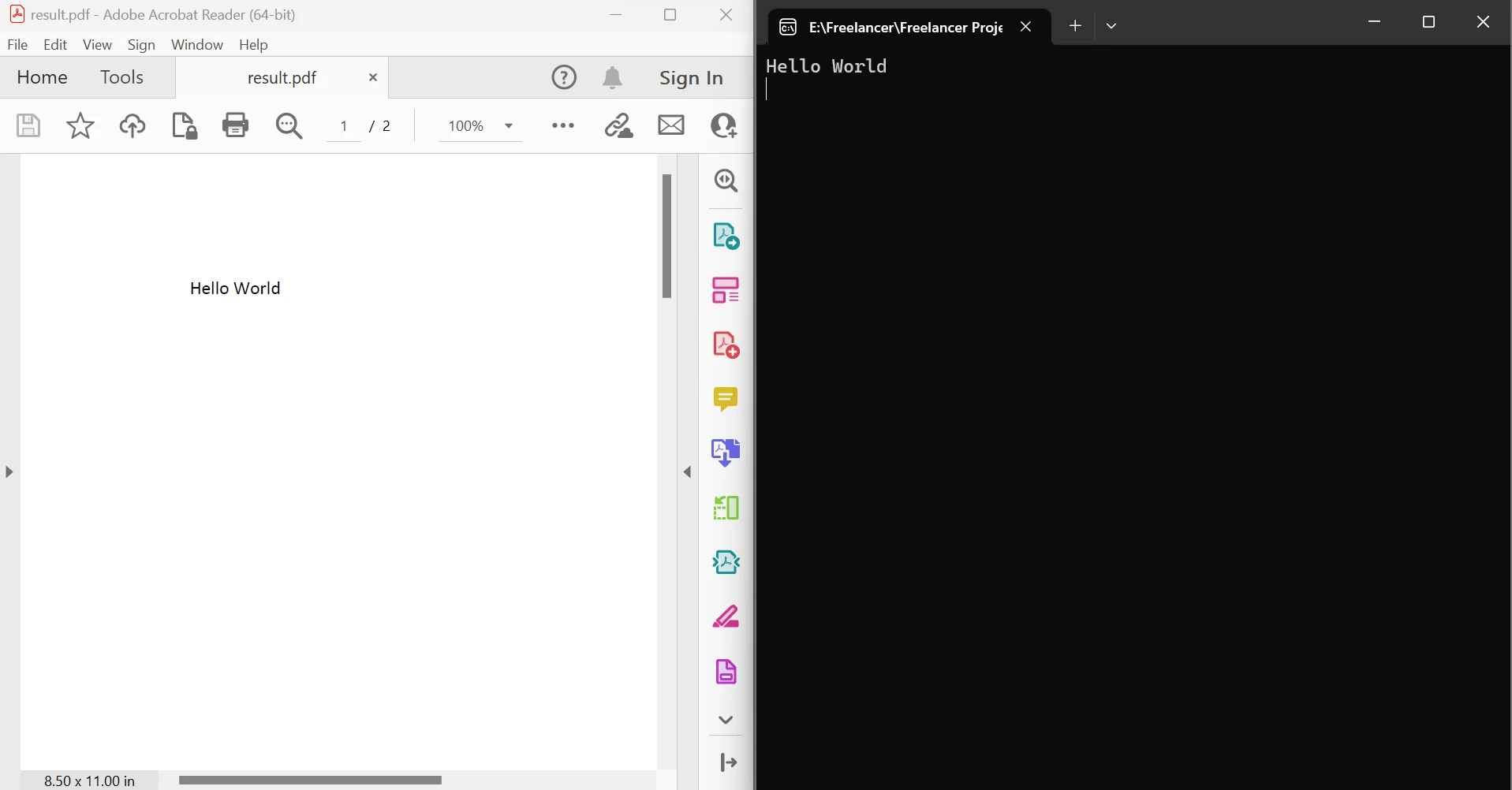 Extrair texto entre páginas (saída)
Extrair texto entre páginas (saída)
Extrair imagem de um arquivo PDF
O IronPDF fornece uma lista de métodos para extrair imagens, tais como:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
Cada método permite extrair imagens de uma página ou de várias páginas do documento.
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleImports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleO código acima mostra como ler um documento de um arquivo existente e transformá-lo em um objeto de documento PDF usando a função FromFile. Ao passar um número de página para o método ExtractRawImagesFromPage do objeto, pode-se obter uma lista de bytes que contém cada imagem que estava presente naquela página do documento. Usando um loop For Each, cada fluxo de bytes é processado e transformado em um fluxo de memória, depois em um Bitmap, o que ajuda na salvaguarda de imagens. A imagem abaixo mostra o resultado do código acima.
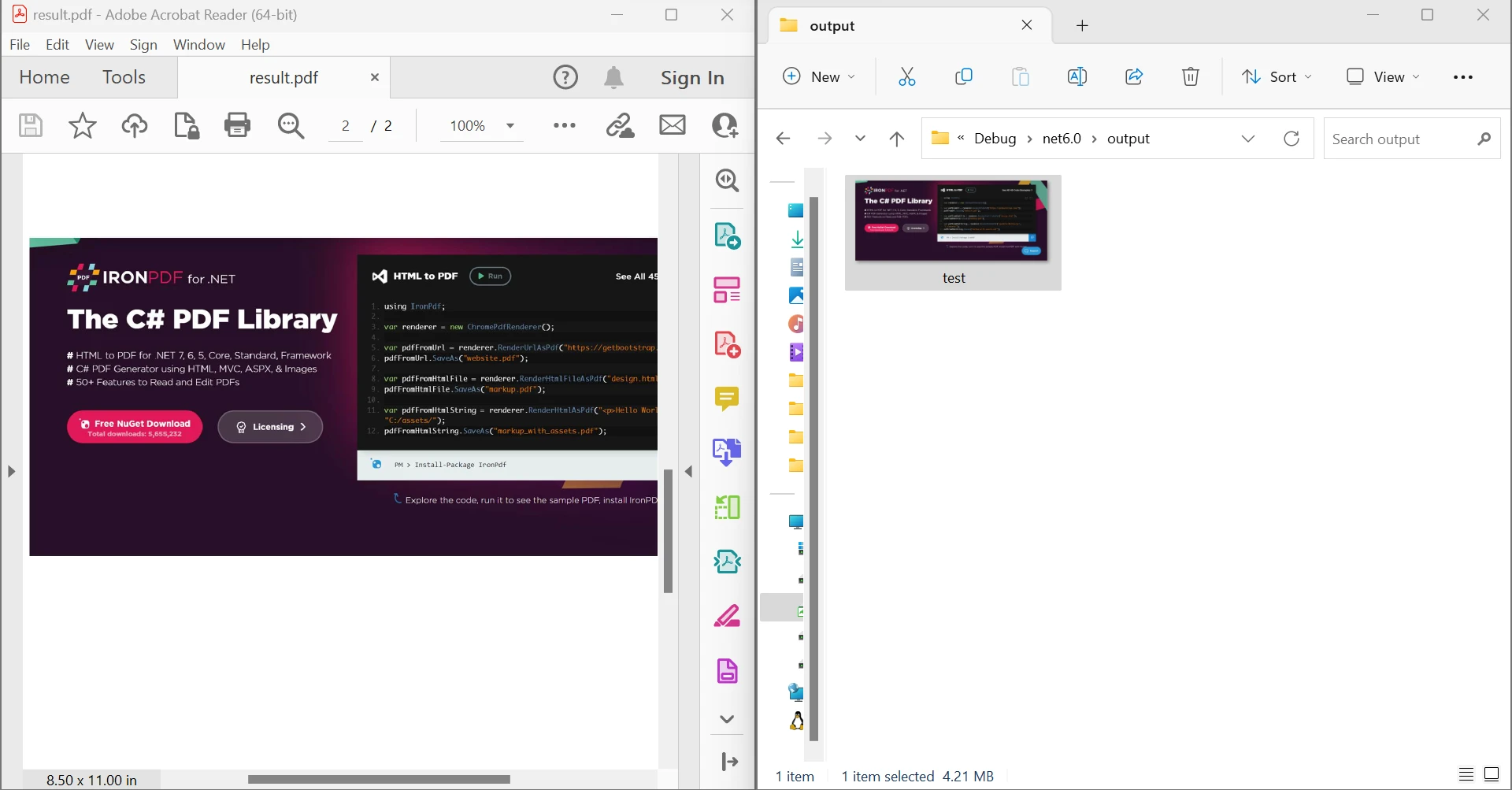 Extrair imagens de um arquivo PDF
Extrair imagens de um arquivo PDF
Para saber mais sobre o tutorial de código da API do IronPDF , consulte a documentação do IronPDF . Você também pode visitar outros tutoriais para aprender como analisar texto em PDF usando C# .
Conclusão
A licença de desenvolvimento da biblioteca IronPDF é gratuita. Caso o IronPDF seja utilizado em um ambiente de produção, diferentes licenças podem ser adquiridas dependendo das necessidades do desenvolvedor. O plano Lite começa em $999 e não tem custos contínuos. Também são oferecidas alternativas de redistribuição SaaS e OEM. Todas as licenças incluem atualizações, um ano de suporte ao produto e uma licença permanente. Eles também são úteis para fabricação, preparação e desenvolvimento. É uma compra única. Existem licenças adicionais gratuitas, com prazo de validade limitado, disponíveis para consulta. Visite a página com informações completas sobre licenciamento do IronPDF para ler os detalhes de preços e licenciamento do IronPDF. O IronPDF também oferece licenças gratuitas para proteção contra cópia.
Perguntas frequentes
Como posso extrair texto de um PDF em VB.NET?
Utilizando a biblioteca IronPDF, você pode extrair texto de um PDF usando o método ExtractAllText . Isso permite recuperar o texto de todas as páginas de um documento PDF em seu projeto VB.NET.
É possível extrair imagens de páginas específicas de um PDF usando VB.NET?
Sim, o IronPDF permite extrair imagens de páginas específicas usando o método ExtractRawImagesFromPage . Esse método retorna os dados da imagem como arrays de bytes, que podem ser convertidos em arquivos de imagem.
Como posso converter conteúdo HTML em um documento PDF em VB.NET?
O IronPDF oferece uma poderosa conversão de HTML para PDF usando o mecanismo de renderização Chromium. Você pode usar métodos como RenderHtmlAsPdf para converter strings ou arquivos HTML em documentos PDF de forma eficiente.
Quais são os benefícios de usar o IronPDF para analisar PDFs em aplicações VB.NET?
O IronPDF oferece APIs versáteis para extração de texto e imagens, suporta conversão de HTML para PDF e é compatível com diversas plataformas .NET, incluindo ASP.NET, Windows Forms e Blazor. Também oferece diferentes opções de licenciamento para atender às necessidades de desenvolvimento e produção.
Como faço para integrar o IronPDF ao meu projeto VB.NET?
Para integrar o IronPDF, baixe a biblioteca do NuGet e adicione-a ao seu projeto VB.NET. Isso permitirá que você acesse seus métodos para analisar e manipular arquivos PDF programaticamente.
O IronPDF consegue lidar com tarefas de análise e conversão de PDFs?
Sim, o IronPDF foi projetado para lidar com eficiência tanto com a análise sintática (extração de texto e imagem) quanto com a conversão (como HTML para PDF), tornando-se uma solução completa para manipulação de PDFs em VB.NET.
Quais são as opções de licenciamento disponíveis para o IronPDF?
A IronPDF oferece uma licença de desenvolvimento gratuita e várias licenças de produção, incluindo Lite, SaaS e redistribuição OEM. Essas licenças incluem atualizações e suporte por um ano, atendendo a diferentes necessidades de projeto.
O IronPDF depende de algum recurso externo para funcionar?
Não, o IronPDF é autossuficiente e utiliza o mecanismo de renderização Chromium internamente, garantindo uma funcionalidade robusta sem depender de recursos externos para conversão e análise de PDFs.
O IronPDF é compatível com o .NET 10 e como isso beneficia os desenvolvedores de VB.NET?
Sim, o IronPDF oferece suporte completo ao .NET 10, além de versões anteriores como .NET 9, 8, 7, 6, Core, Standard e Framework. Isso significa que projetos VB.NET direcionados ao .NET 10 podem usar o IronPDF sem configuração adicional. Os desenvolvedores se beneficiam das novas melhorias de desempenho em tempo de execução do .NET 10 — como alocações de memória reduzidas, otimizações aprimoradas de tempo de execução e JIT — que melhoram a geração de PDFs, a extração de texto/imagem e a renderização de HTML para PDF.











