
Comment analyser un fichier PDF en VB.NET
Ce tutoriel présente comment extraire par programmation des textes et des images à partir de fichiers PDF avec le support de premier ordre d'IronPDF.
Comment analyser un fichier PDF en VB.NET
- Téléchargez la bibliothèque IronPDF C# pour analyser les fichiers PDF
- Utiliser la méthode `FromFile` pour analyser un fichier PDF en VB.NET
- Extraire le texte d'un PDF ouvert avec la méthode `ExtractAllText`
- Utilisez la méthode `ExtractTextFromPages` pour extraire le texte de certaines pages
- Extraire des images d'un PDF ouvert avec la méthode `ExtractRawImagesFromPage`
IronPDF
Fonctionnalités
Conversion efficace de PDF. Presque tout ce qu'une machine peut faire, IronPDF peut le faire aussi. Grâce à cette bibliothèque PDF, les développeurs peuvent rapidement créer, lire le contenu textuel, écrire, charger et manipuler des PDF.
IronPDF convertit le HTML en un enregistrement PDF à l'aide du moteur Chrome. Avec, entre autres, Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms et WPF. IronPDF prend également en charge les applications Xamarin, Blazor, Unity et HoloLens. IronPDF supporte à la fois les applications Microsoft .NET et .NET Core (les packages Web ASP.NET et les packages Windows conventionnels). IronPDF peut être utilisé pour créer des PDF esthétiquement plaisants.
IronPDF peut créer un PDF en utilisant HTML5, JavaScript, CSS et des images. IronPDF dispose également d'un puissant convertisseur HTML en PDF qui s'intègre aux PDF. Un fort mécanisme de conversion PDF est présent dans IronPDF utilisant le moteur de rendu Chromium. Il est également indépendant de toute source extérieure.
- Une image PDF peut être créée à partir de diverses sources, y compris HTML, HTML5, ASPX et Razor/MVC View. Les actifs HTML et image peuvent tous deux être convertis en PDF.
- Les outils qui peuvent être utilisés pour travailler avec des PDFs interactifs incluent remplir et soumettre des formulaires interactifs.
- Fusionner et diviser des PDFs, extraire du texte et des images des fichiers PDF, rechercher du texte dans des fichiers PDF, rasteriser des PDFs en images, changer la taille de la police et convertir des fichiers PDF.
- Il permet la vérification des formulaires de connexion HTML en utilisant des user-agents, des proxies, des cookies, des en-têtes HTTP et des variables de formulaire.
- L'accès à des documents sécurisés est rendu possible par IronPDF en fournissant des noms d'utilisateur et des mots de passe.
- IronPDF est un programme qui lit le texte dans le PDF et comble les lacunes.
- Permet d'ajouter des textes, des images, des signets, des filigranes, et plus encore.
- Vous pouvez créer un fichier PDF à partir d'un fichier CSS.
Pour plus de détails, visitez cette page d'information sur les licences IronPDF pour une clé limitée gratuite et une version professionnelle.
 IronPDF - Formatage de la police
IronPDF - Formatage de la police
Extraire le texte d'un fichier PDF
IronPDF peut également lire et extraire du texte à partir de fichiers PDF avec l'aide des bibliothèques IronPDF. Voici un modèle de code IronPDF qui peut être utilisé pour examiner les fichiers PDF présents.
Extraire le texte de toutes les pages
L'exemple de code ci-dessous démontre la première méthode pour acquérir tout le contenu PDF sous forme de chaîne en quelques lignes.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleL'exemple de code ci-dessus démontre comment utiliser la méthode FromFile pour lire un PDF à partir d'un fichier existant et le convertir en un objet document PDF. L'objet fournit une méthode appelée ExtractAllText qui extraira le texte brut du PDF et le transformera en chaîne de caractères.
Extraire le texte par numéro de page
L'exemple de code ci-dessous montre comment extraire des données d'un fichier PDF en utilisant le numéro de page.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleLe code ci-dessus montre comment lire un PDF à partir d'un fichier existant et le transformer en un objet document PDF en utilisant la fonction FromFile . Les textes et les images peuvent être accessibles sur le PDF en utilisant cet objet. L'objet propose une méthode appelée ExtractTextFromPage qui vous permet d'envoyer un numéro de page comme paramètre pour obtenir une chaîne contenant tous les mots présents sur cette page du PDF.
Extraire le texte entre les pages
Le code ci-dessous montre comment extraire les données entre plusieurs pages.
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleLe code ci-dessus démontre comment utiliser la méthode FromFile pour lire un PDF à partir d'un fichier existant et le convertir en un objet document PDF. Cet objet permet d'examiner le texte et les images dans le PDF. L'objet possède une méthode appelée ExtractTextFromPages qui peut être utilisée pour obtenir une chaîne qui inclut tout le contenu textuel des pages données du document en passant une liste de numéros de page comme paramètre. En dessous, la gauche est le PDF source et la droite est les données extraites.
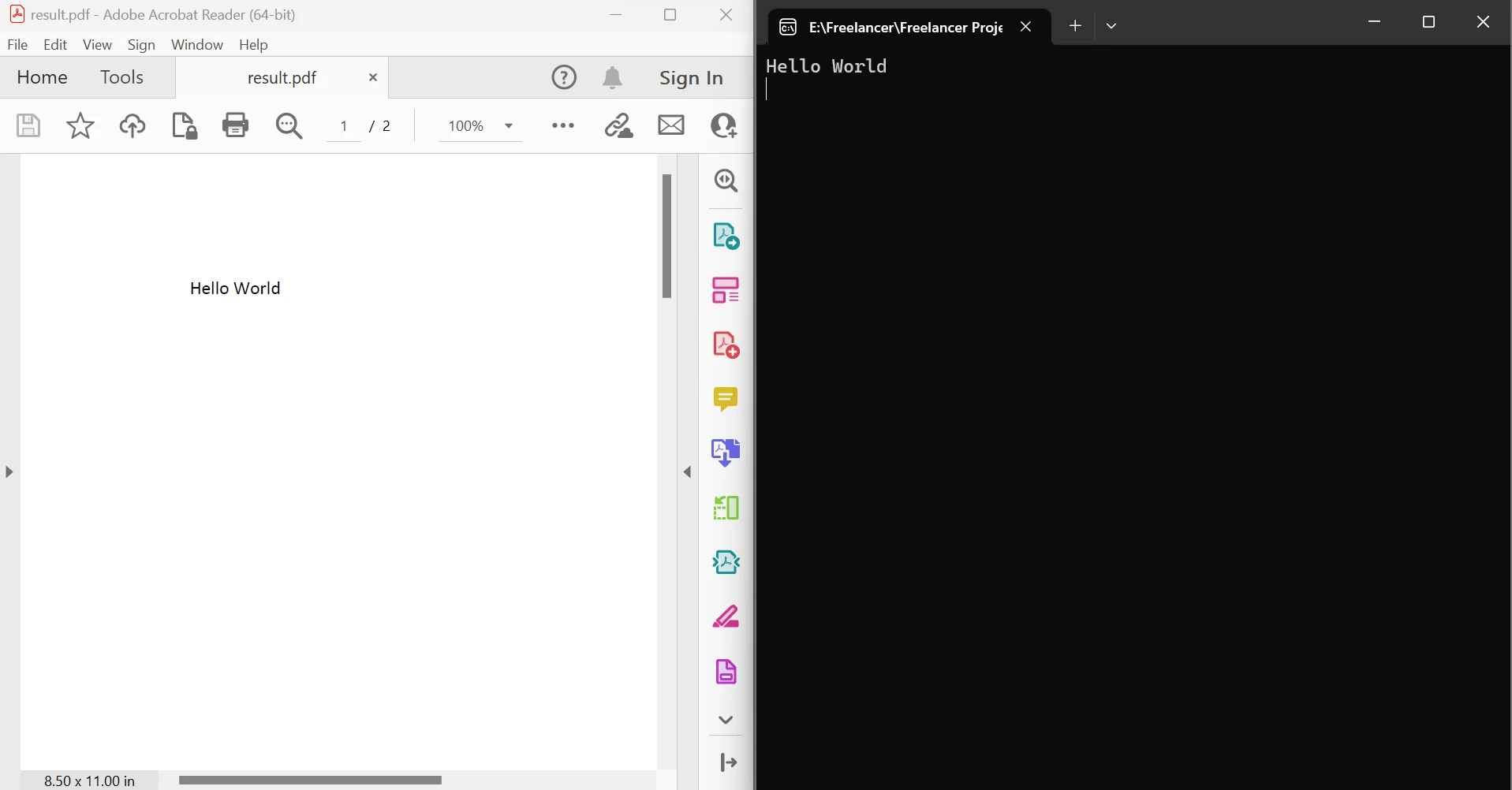 Sortie du texte extrait entre les pages
Sortie du texte extrait entre les pages
Extraire une image d'un fichier PDF
IronPDF fournit une liste de méthodes pour extraire des images telles que :
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
Chaque méthode permet d'extraire des images d'une page ou de plusieurs pages du document.
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleLe code ci-dessus montre comment lire un document à partir d'un fichier existant et le transformer en un objet document PDF à l'aide de la fonction FromFile. En passant un numéro de page à la méthode ExtractRawImagesFromPage de l'objet, une liste d'octets peut être obtenue qui contient toutes les images présentes sur cette page du document. En utilisant une boucle For Each, chaque flux d'octets est traité et transformé en un flux de mémoire, puis en un Bitmap, ce qui facilite la sauvegarde de l'image. L'image ci-dessous montre la sortie du code ci-dessus.
 Sortie des images extraites du PDF
Sortie des images extraites du PDF
Pour en savoir plus sur le tutoriel du code API IronPDF, référez-vous à la documentation IronPDF. Vous pouvez également visiter d'autres tutoriels pour apprendre comment analyser le texte PDF en utilisant C#.
Conclusion
La licence de développement pour la bibliothèque IronPDF est gratuite. Si vous utilisez IronPDF dans un environnement de production, différentes licences peuvent être achetées en fonction des besoins du développeur. Le forfait Lite commence à $999 et n'a pas de frais récurrents. Des alternatives de redistribution SaaS et OEM sont également fournies. Toutes les licences incluent des mises à jour, un an de support produit et une licence permanente. Elles sont également utiles pour la fabrication, la mise en scène et le développement. C'est un achat unique. Il existe des licences supplémentaires gratuites, de durée limitée. Visitez l'information complète sur les licences IronPDF pour lire les détails complets des prix et des licences pour IronPDF. IronPDF propose également des licences gratuites pour la protection contre la copie.
Questions Fréquemment Posées
Comment puis-je extraire du texte d'un PDF en VB.NET ?
En utilisant la bibliothèque IronPDF, vous pouvez extraire du texte d'un PDF en utilisant la méthode ExtractAllText. Cela vous permet de récupérer du texte de toutes les pages d'un document PDF dans votre projet VB.NET.
Est-il possible d'extraire des images de pages spécifiques d'un PDF en utilisant VB.NET ?
Oui, IronPDF vous permet d'extraire des images de pages spécifiques en utilisant sa méthode ExtractRawImagesFromPage. Cette méthode renvoie les données de l'image sous forme de tableaux d'octets, que vous pouvez convertir en fichiers image.
Comment puis-je convertir du contenu HTML en document PDF en VB.NET ?
IronPDF offre une puissante conversion HTML en PDF en utilisant le moteur de rendu Chromium. Vous pouvez utiliser des méthodes comme RenderHtmlAsPdf pour convertir des chaînes ou des fichiers HTML en documents PDF de manière efficace.
Quels sont les avantages d'utiliser IronPDF pour l'analyse PDF dans les applications VB.NET ?
IronPDF fournit des API polyvalentes pour l'extraction de texte et d'images, prend en charge la conversion HTML en PDF et est compatible avec diverses plateformes .NET, y compris ASP.NET, Windows Forms et Blazor. Il offre également différentes options de licences pour répondre aux besoins de développement et de production.
Comment intégrer IronPDF dans mon projet VB.NET ?
Pour intégrer IronPDF, téléchargez la bibliothèque depuis NuGet et ajoutez-la à votre projet VB.NET. Cela vous permettra d'accéder à ses méthodes pour analyser et manipuler les fichiers PDF par programmation.
IronPDF peut-il gérer à la fois les tâches d'analyse et de conversion PDF ?
Oui, IronPDF est conçu pour gérer efficacement à la fois les tâches d'analyse (extraction de texte et d'images) et de conversion (comme HTML en PDF), en faisant une solution complète pour la manipulation de PDF en VB.NET.
Quelles sont les options de licence disponibles pour IronPDF ?
IronPDF propose une licence de développement gratuite et diverses licences de production, y compris Lite, SaaS et redistribution OEM. Ces licences incluent des mises à jour et un support pendant un an, répondant à différents besoins de projet.
IronPDF dépend-il de ressources externes pour son fonctionnement ?
Non, IronPDF est autonome et utilise le moteur de rendu Chromium en interne, assurant une fonctionnalité robuste sans dépendre de ressources externes pour la conversion et l'analyse PDF.
IronPDF prend-il en charge .NET 10 et quels avantages offre-t-il aux développeurs VB.NET ?
Oui, IronPDF est entièrement compatible avec .NET 10, ainsi qu'avec les versions antérieures telles que .NET 9, 8, 7, 6, Core, Standard et Framework. Cela signifie que les projets VB.NET ciblant .NET 10 peuvent utiliser IronPDF sans configuration supplémentaire. Les développeurs bénéficient ainsi des nouvelles performances d'exécution offertes par .NET 10, notamment la réduction de l'allocation de mémoire, l'optimisation de l'exécution et du JIT, ce qui améliore la génération de PDF, l'extraction de texte et d'images, ainsi que le rendu HTML vers PDF.













