
Python PdfWriter (Code Example Tutorial)
IronPDF is a pure Python PDF file object library for Python developers looking to write PDF files or manipulate PDF files within their applications. IronPDF stands out for its simplicity and versatility, making it an ideal choice for tasks that require automated PDF creation or integrating PDF generation into software systems.
This guide will explore how IronPDF, a pure Python PDF library, can be used for creating PDF files or PDF page attributes and reading PDF files. It will include examples and practical code snippets, giving you a hands-on understanding of how to use IronPDF for Python's PdfWriter in your Python projects to write PDF files and create a new PDF page.
Setting Up IronPDF
Installation
To start using IronPDF, you'll need to install it via the Python Package Index. Run the following command in the terminal:
pip install ironpdf
Writing PDF Files and Manipulating PDF Files
Creating a New PDF
IronPDF simplifies the process of creating new PDF files and working on existing PDFs. It provides a straightforward interface for generating documents, whether a simple one-page PDF or a more complex document with various elements such as user passwords. This functionality is vital for tasks like report generation, creating invoices, and much more.
from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf")from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf") Output File
Output File
Merging PDF Files
IronPDF simplifies the task of combining several PDF files into one. This feature is beneficial for aggregating various reports, assembling scanned documents, or organizing information that belongs together. For instance, you might need to merge PDF files when creating a comprehensive report from multiple sources or when you have a series of documents that need to be presented as a single file.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")The ability to merge existing PDF files into a new PDF file can also be useful in fields like data science, where a consolidated PDF document could serve as a dataset for training an AI module. IronPDF handles this task effortlessly, maintaining the integrity and formatting of each page from the original documents, resulting in a seamless and coherent output PDF file.
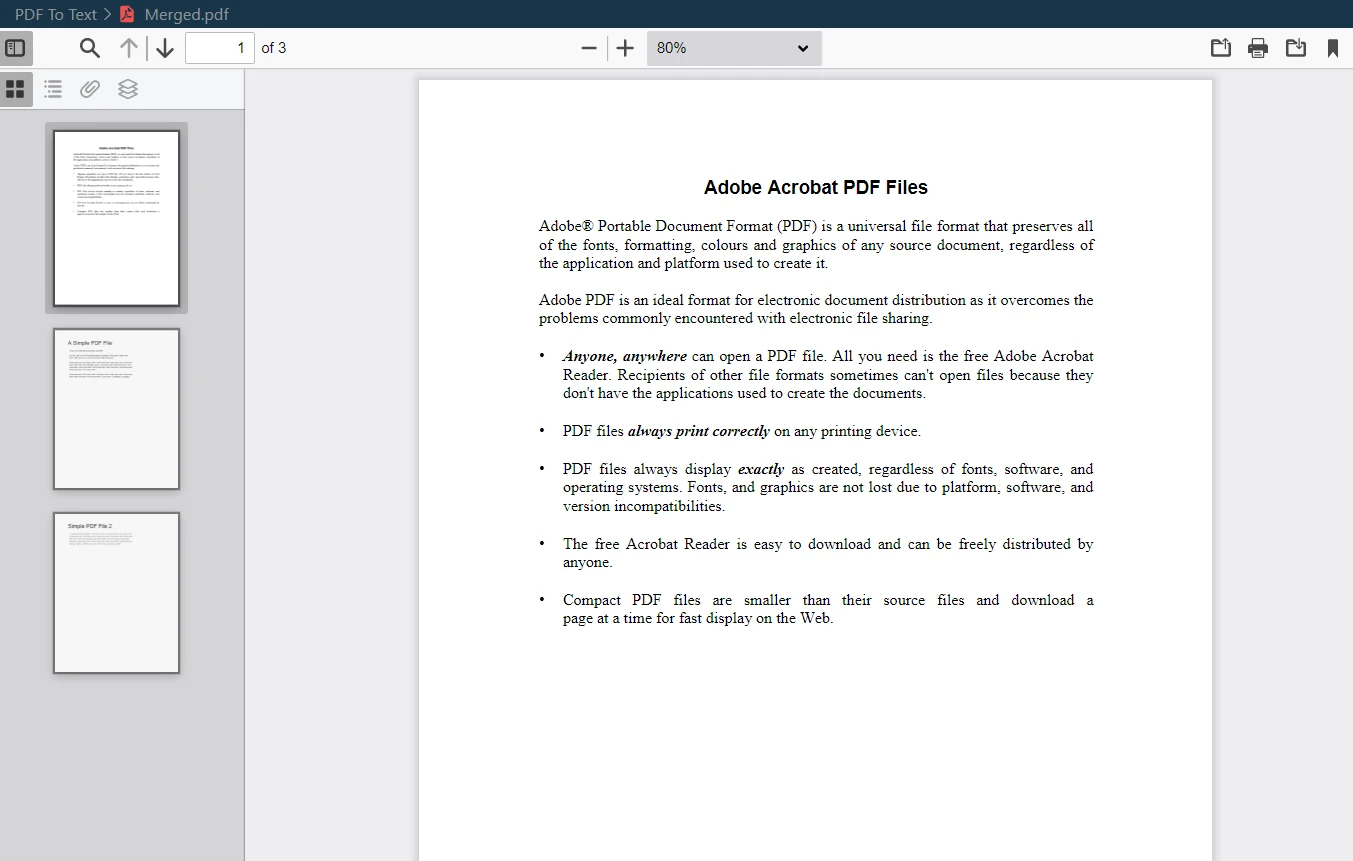 Merged PDF Output
Merged PDF Output
Splitting a Single PDF
Conversely, IronPDF also excels at dividing an existing PDF file into multiple new files. This function is handy when you need to extract specific sections from a substantial PDF document or when dividing a document into smaller, more manageable parts.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")For example, you might want to isolate certain PDF pages from a large report or create individual documents from different chapters of a book. IronPDF lets you select the desired multiple pages to convert into a new PDF file, ensuring you can manipulate and manage your PDF content as needed.
 Split PDF Output
Split PDF Output
Implementing Security Features
Securing your PDF documents becomes a top priority when dealing with sensitive or confidential information. IronPDF addresses this need by offering robust security features, including user password protection and encryption. This ensures that your PDF files remain secure and accessible only to authorized users.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")By implementing user passwords, you can control who can view or edit your PDF documents. Encryption options add an extra layer of security, safeguarding your data against unauthorized access and making IronPDF a reliable choice for managing sensitive information in PDF format.
Extracting Text from PDFs
Another critical feature of IronPDF is its ability to extract text from PDF documents. This functionality is particularly useful for data retrieval, content analysis, or even for repurposing text content from existing PDFs into new documents.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)Whether you're extracting data for analysis, searching for specific information within a large document, or transitioning content from PDF to text files for further processing, IronPDF makes it straightforward and efficient. The library ensures that the extracted text maintains its original formatting and structure, making it immediately usable for your specific needs.
Managing Document Information
Efficient management of PDFs extends beyond their content. IronPDF allows for effectively managing document metadata and properties such as the author's name, document title, creation date, and more. This capability is vital for organizing and cataloging your PDF documents, particularly in environments where document provenance and metadata are important.
from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")For instance, in an academic or corporate setting, being able to track the creation date and authorship of documents can be essential for record-keeping and document retrieval purposes. IronPDF makes managing this information easy, providing a streamlined way to handle and update document information within your Python applications.
Conclusion
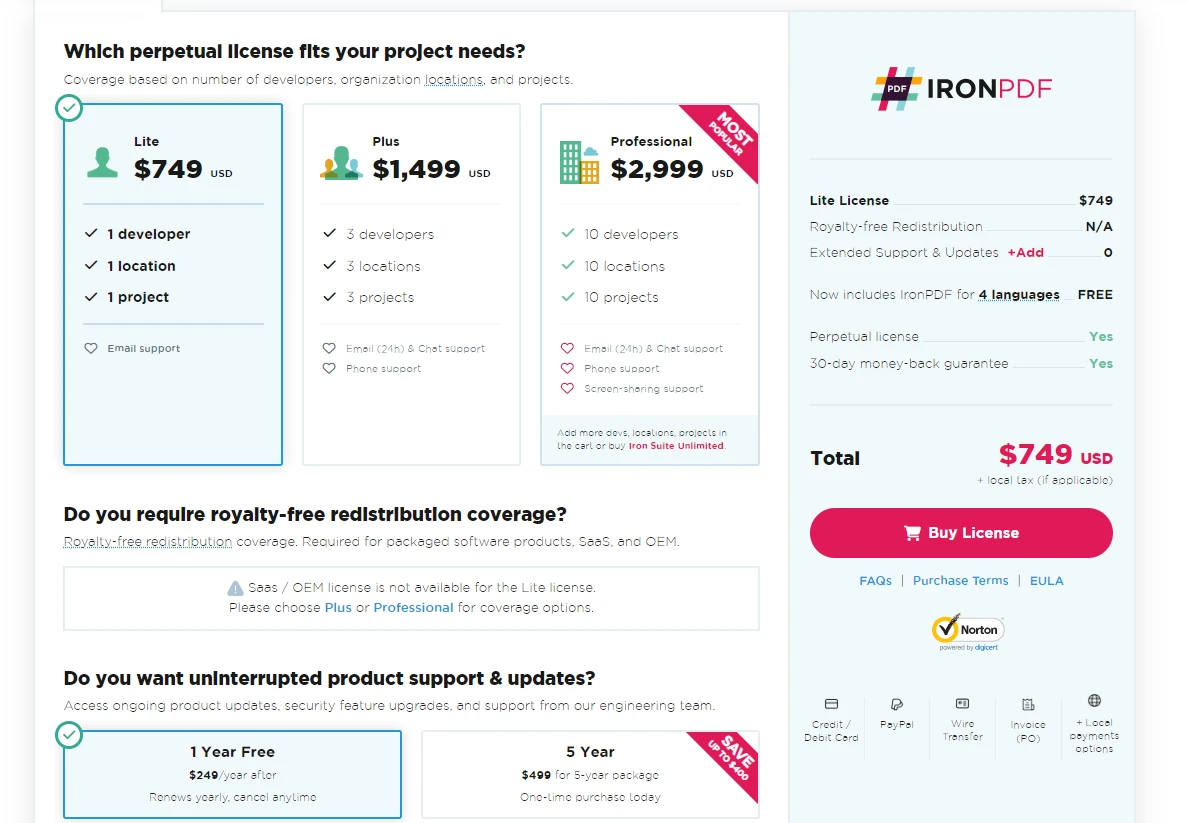 License
License
This tutorial has covered the basics of using IronPDF in Python for PDF manipulation. From creating new PDF files to merging existing ones, and adding security features, IronPDF is a versatile tool for any Python developer.
IronPDF for Python also offers the following features:
- Create new PDF file from scratch using HTML or URL
- Editing existing PDF files
- Rotate PDF pages
- Extract text, metadata, and images from PDF files
- Secure PDF files with passwords and restrictions
- Split and merge PDFs
IronPDF for Python offers a free trial for users to explore its features. For continued use beyond the trial, licenses start at $799. This pricing allows developers to utilize the full range of IronPDF's capabilities in their projects.
Frequently Asked Questions
How can I create a PDF file in Python?
You can use IronPDF's CreatePdf method to generate new PDF files. This method allows you to create custom PDF documents from scratch using Python.
What are the steps to install IronPDF for Python?
To install IronPDF for Python, you can use the Python Package Index by executing the command: pip install ironpdf.
How do I merge multiple PDFs into one using Python?
IronPDF offers functionalities to merge multiple PDF files. You can use the MergePdfFiles method to combine several PDFs into a single document.
Can I split a PDF into separate pages with IronPDF?
Yes, IronPDF provides the SplitPdf function, which allows you to divide a PDF into individual pages or sections, creating separate files for each part.
What security features does IronPDF support for PDFs?
IronPDF supports several security features, including password protection and encryption, to ensure your PDF files are secure and accessible only to authorized users.
How can I extract text from a PDF document in Python?
With IronPDF, you can easily extract text from PDF documents using the ExtractText method, which is useful for data retrieval and analysis.
What are the key PDF manipulation features provided by IronPDF?
IronPDF allows you to create, merge, and split PDFs, apply security measures, extract text, and manage document metadata such as author name and creation date.
Is there a free trial for IronPDF, and how can I access it?
Yes, IronPDF offers a free trial. You can explore its features during the trial period, and licenses are available for purchase for continued use after the trial ends.
What are some practical use cases for IronPDF in Python projects?
IronPDF is ideal for generating reports, creating invoices, securing documents, and managing PDF metadata in various Python projects.
How can I manage PDF metadata using IronPDF?
IronPDF enables you to manage PDF metadata, including author names, document titles, and creation dates, which is crucial for document organization and cataloging.
















