


将 HTML 转换为 PDF Node.js.
_从原始 HTML、CSS 和 JavaScript 创建高保真 PDF 的能力是 IronPDF 最强大和最受欢迎的功能。 本教程是一个全面的入门教程,帮助 Node 开发人员利用 IronPDF 将 HTML 到 PDF 生成集成到他们自己的项目中。
_IronPDF 是一个高级 API 库,可帮助开发人员快速轻松地在软件应用程序中实现强大且可靠的 PDF 处理功能。 IronPDF 提供 多种编程语言。 有关如何在 .NET、Java 和 Python 中创建 PDF 的详细说明,请查阅官方文档页面。 本教程涵盖其在 Node.js 项目中的应用。
如何在 Node.js 中将 HTML 转换为 PDF
- Install the HTML to PDF Node library via NPM: `npm install @ironsoftware/ironpdf`.
- 从 `@ironsoftware/ironpdf` 包中导入 **PdfDocument** 类。
- 从 HTML 字符串、文件或网页 URL 转换。
- (可选)添加页眉和页脚,更改页面大小、方向和颜色。
- 调用 `PdfDocument.saveAs` 保存生成的 PDF
开始
今天在您的项目中使用 IronPDF,免费试用。
为 Node.js 安装 IronPDF 库
通过在您选择的 Node 项目中运行下面给出的 NPM 命令来安装 IronPDF Node.js 包:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf您也可以手动下载并安装 IronPDF 包。
手动安装 IronPDF 引擎(可选)
适用于 Node.js 的 IronPDF 当前需要一个IronPDF 引擎二进制文件才能正常工作。
通过为您的操作系统安装适当的包来安装 IronPDF 引擎二进制文件:
@ironpdf 会在首次运行时自动从 NPM 下载并安装适用于您的浏览器和操作系统的正确二进制文件。 然而,在网络访问有限、减少或不需要的情况下,明确安装此二进制文件将是至关重要的。应用许可证密钥(可选)
默认情况下,IronPDF 将在其生成或修改的所有文档上加上标有标题的背景水印。
 在 ironpdf.com/nodejs/licensing/ 上获取许可证密钥以生成无水印的 PDF 文档。
在 ironpdf.com/nodejs/licensing/ 上获取许可证密钥以生成无水印的 PDF 文档。
要使用IronPDF而不添加水印品牌标识,您必须使用有效的许可证密钥在全局 IronPdfGlobalConfig 对象上设置 licenseKey 属性。 实现这一目标的源代码如下所示:
import { IronPdfGlobalConfig } from "@ironsoftware/ironpdf";
// Get the global config object
var config = IronPdfGlobalConfig.getConfig();
// Set the license key for IronPDF
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";import { IronPdfGlobalConfig } from "@ironsoftware/ironpdf";
// Get the global config object
var config = IronPdfGlobalConfig.getConfig();
// Set the license key for IronPDF
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";从我们的许可页面购买许可证密钥,或联系我们获取免费试用许可证密钥。
在使用其他库函数之前,应先设置许可证密钥和其他全局配置设置,以确保最佳性能和功能正常运行。
本教程后续部分将假设我们有一个许可证密钥并已将其设置在一个名为 config.js 的单独 JavaScript 文件中。 在我们将使用 IronPDF 功能的地方,我们导入这个脚本。
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// ...import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// ...将 HTML 转换为 PDF
IronPDF 库的 Node 版本提供三种从 HTML 内容创建 PDF 文件的方法:
1.从一串 HTML 代码 2.从本地 HTML 文件 3.来自在线网站
本节将详细解释这三种方法。
从 HTML 字符串创建 PDF 文件
PdfDocument.fromHtml 是一种允许您从原始网页标记字符串生成 PDF 的方法。
在三种方法中,此方法提供了最大的灵活性。 这是因为 HTML 字符串中的数据可以几乎来自任何地方:文本文件、数据流、HTML 模板、生成的 HTML 数据等。
下面的代码示例演示了如何在实践中使用 PdfDocument.fromHtml 方法:
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Create a PDF from the HTML String "Hello world!"
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system.
await pdf.saveAs("html-string-to-pdf.pdf");import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Create a PDF from the HTML String "Hello world!"
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system.
await pdf.saveAs("html-string-to-pdf.pdf");如上所示,我们调用 PdfDocument.fromHtml 方法,传入一个包含一级标题元素标记代码的文本字符串。
PdfDocument.fromHtml 返回一个 Promise,该 Promise 解析为PdfDocument类的一个实例。 PdfDocument 表示库根据某些源内容生成的 PDF 文件。 该类是 IronPDF 大多数核心功能的基石,推动了重要的 PDF 创建和编辑用例。
最后,我们使用 saveAs 方法将 PdfDocument 文件保存到磁盘。 下面显示了保存的 PDF 文件。
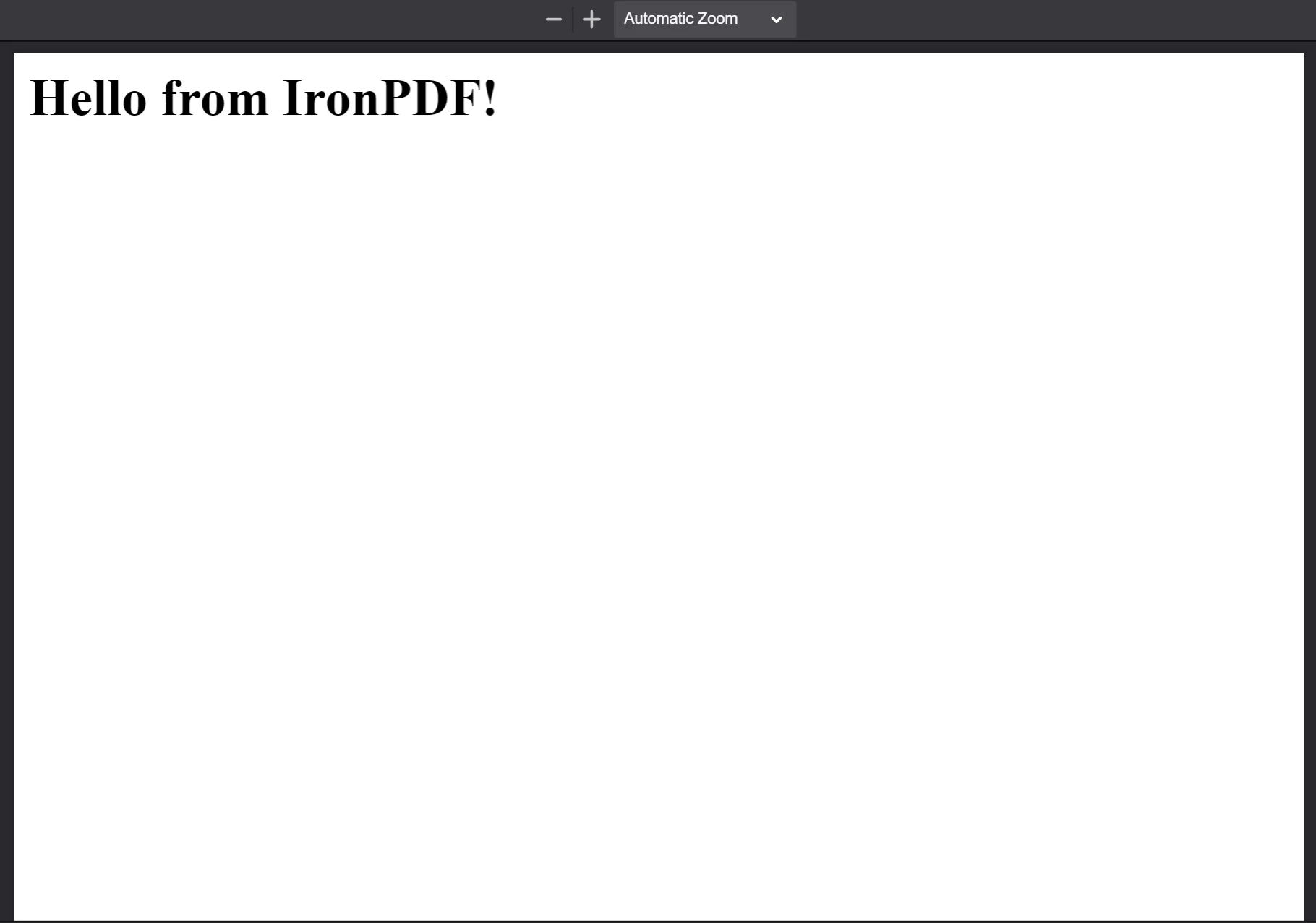 The PDF generated from the HTML string "
The PDF generated from the HTML string "<h1>Hello from IronPDF!</h1>". PdfDocument.fromHtml 生成的 PDF 文件看起来就像网页内容一样。
从 HTML 文件创建 PDF 文件
PdfDocument.fromHtml 不仅适用于 HTML 字符串。 该方法还接受本地 HTML 文档的路径。
在下一个示例中,我们将使用此 示例网页。
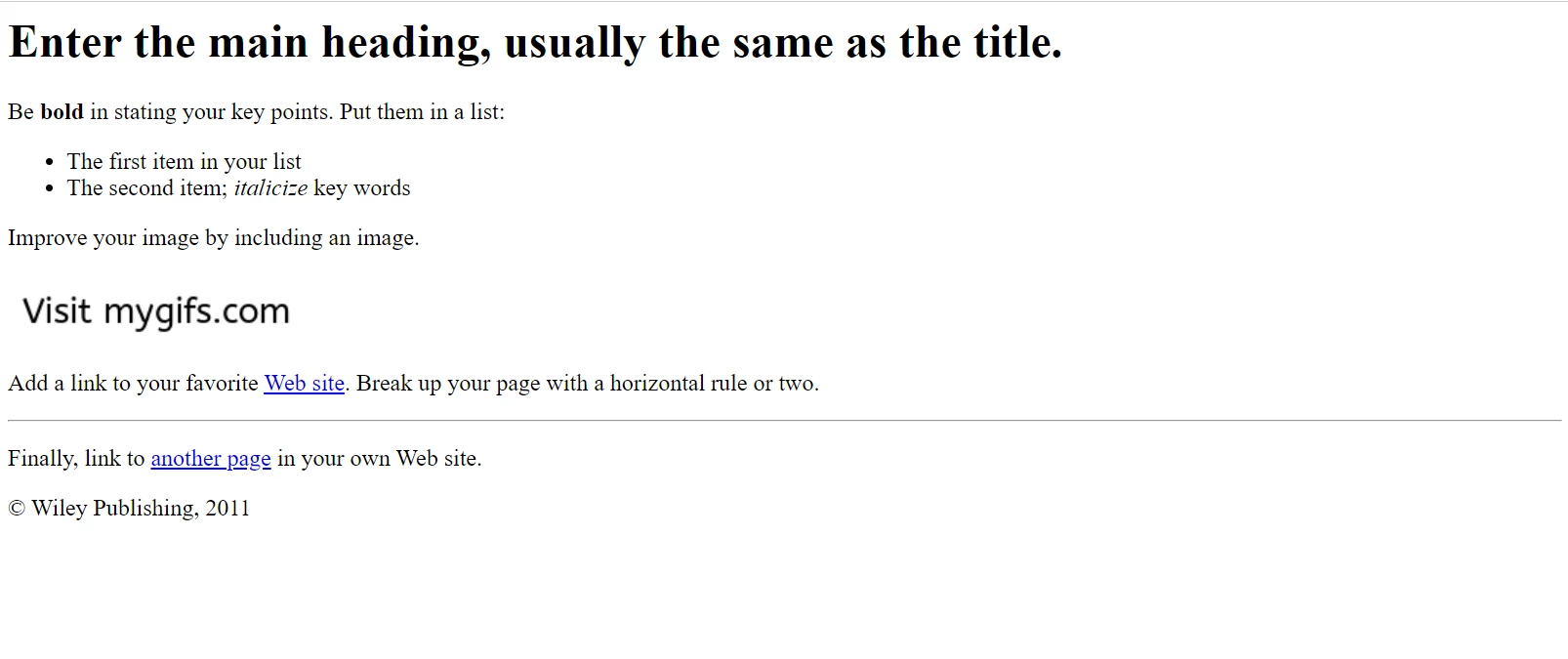 我们的示例 HTML 页面在谷歌浏览器中的显示。 从文件样本网站下载此页面和类似页面:https://filesamples.com/samples/code/html/sample2.html
我们的示例 HTML 页面在谷歌浏览器中的显示。 从文件样本网站下载此页面和类似页面:https://filesamples.com/samples/code/html/sample2.html
下面的代码行将整个示例文档转换为 PDF。 我们不用 HTML 字符串,而是调用 PdfDocument.fromHtml,并传入指向示例文件的有效文件路径:
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from an HTML File
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the same folder as our project.
await pdf.saveAs("html-file-to-pdf-1.pdf");import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from an HTML File
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the same folder as our project.
await pdf.saveAs("html-file-to-pdf-1.pdf");我们在下面包含了生成的 PDF 的内容。 请注意,IronPDF 不仅保留了原始 HTML 文档的外观,还保留了链接、表单和其他常见交互元素的功能。
图 4 此 PDF 是从上一个代码示例生成的。 比较其外观与前一个图像,注意其显著的相似之处!
如果您查看过示例页面的源代码,您会注意到它更加复杂。** 它使用更多类型的 HTML 元素(段落、无序列表、换行、水平线、超链接、图像等),并且还包含一些脚本(用于设置 Cookies)。
IronPDF 能够渲染比我们目前使用的更复杂的网络内容。 为了证明这一点,请让我们考虑以下页面:
图 5 一篇关于 Puppeteer 的文章,Puppeteer 是一个 Node 库,因其能够使用无头浏览器实例以编程方式控制 Chrome 浏览器而广受欢迎。
上图显示的页面是一篇关于 Puppeteer Node 库的文章。 Puppeteer 运行无头浏览器会话,Node 开发人员使用这些会话来执行服务器端或客户端上的许多浏览器任务(其中之一包括服务器端 HTML PDF 生成)。
新页面来源众多资产(CSS 文件、图像、脚本文件等),布局更加复杂。 在接下来的示例中,我们将把此页面的保存副本(及其源资产)转换为像素完美的 PDF。
下面的代码段假设该页面与我们项目位于同一目录中,文件名为 "sample4.html":
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from even more complex HTML code.
PdfDocument.fromHtml("./sample4.html").then(async (pdf) => {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from even more complex HTML code.
PdfDocument.fromHtml("./sample4.html").then(async (pdf) => {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});下图显示了以上代码段的结果。
图 6 如果在 Google Chrome 中看起来很好,那么转换为 PDF 时效果也很好。 这包括 CSS 和 JavaScript 密集的页面设计。
从 URL 创建 PDF 文件
IronPDF 可以转换任意大小和复杂度的 HTML 字符串和 HTML 文件。 不过,您不限于只使用来自字符串和文件的原始标记。 IronPDF 还可以从 URL 请求 HTML。
请看位于 https://en.wikipedia.org/wiki/PDF 的 Wikipedia 文章。
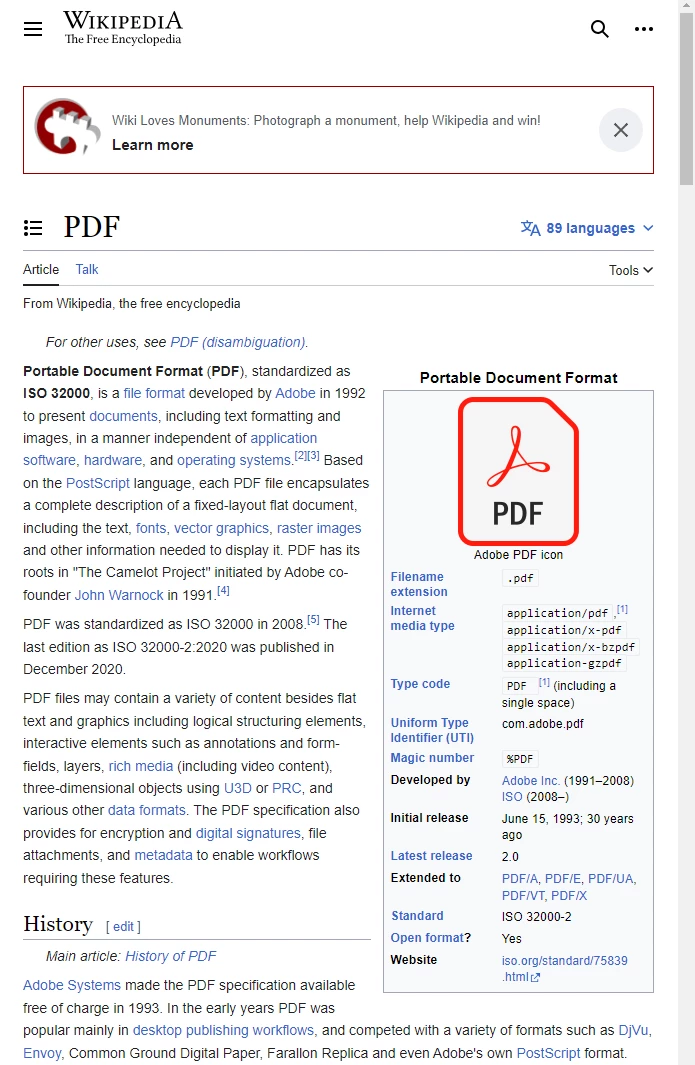 关于 PDF 格式的 Wikipedia 文章,其在符合标准的网络浏览器中的显示方式。
关于 PDF 格式的 Wikipedia 文章,其在符合标准的网络浏览器中的显示方式。
使用该源代码将此 Wikipedia 文章转换为 PDF:
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert the Web Page to a pixel-perfect PDF file.
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document.
await pdf.saveAs("url-to-pdf.pdf");import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert the Web Page to a pixel-perfect PDF file.
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document.
await pdf.saveAs("url-to-pdf.pdf");上面,我们使用 PdfDocument.fromUrl 将网页转换为 PDF,只需几行代码即可。 IronPDF 会为您获取该网址的 HTML 代码,并无缝呈现。 不需要 HTML 文件或文本字符串!
 调用 PdfDocument.fromUrl 对维基百科文章生成的 PDF。 注意其与原始网页的相似之处。
通过 Zip 压缩档案创建 PDF 文件
使用 PdfDocument.fromZip 将位于压缩 (zip) 文件中的特定 HTML 文件转换为 PDF。
例如,假设我们在项目目录中有一个 Zip 文件,其内部结构如下所示:
html-zip.zip
├─ index.html
├─ style.css
├─ logo.pngindex.html 文件包含代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html>style.css 声明了五个 CSS 规则:
@font-face {
font-family: 'Gotham-Black';
src: url('gotham-black-webfont.eot?') format('embedded-opentype'),
url('gotham-black-webfont.woff2') format('woff2'),
url('gotham-black-webfont.woff') format('woff'),
url('gotham-black-webfont.ttf') format('truetype'),
url('gotham-black-webfont.svg') format('svg');
font-weight: normal;
font-style: normal;
font-display: swap;
}
body {
display: flex;
flex-direction: column;
justify-content: center;
margin-left: auto;
margin-right: auto;
margin-top: 200px;
margin-bottom: auto;
color: white;
background-color: black;
text-align: center;
font-family: "Helvetica"
}
h1 {
font-family: "Gotham-Black";
margin-bottom: 70px;
font-size: 32pt;
}
img {
width: 400px;
height: auto;
}
p {
text-decoration: underline;
font-size: smaller;
}最后,logo.png 显示了我们的产品徽标:
图 9 假设 HTML zip 文件中的示例图片。
调用 fromZip 方法时,在第一个参数中指定 zip 文件的有效路径,以及一个 JSON 对象,该对象将 mainHtmlFile 属性设置为我们要转换的 zip 文件中的 HTML 文件的名称。
我们以类似方式转换 zip 文件夹中的 index.html 文件:
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render the HTML from a zip archive
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render the HTML from a zip archive
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});图 10 使用 PdfDocument.fromZip 函数创建 PDF。 该功能成功呈现 zip 文件中包含的 HTML 代码及其包含的资产。
高级 HTML 到 PDF 生成选项
ChromePdfRenderOptions接口允许 Node 开发人员修改库的 HTML 渲染行为。 那里公开的属性允许在PDF呈现之前对PDF的外观进行细粒度的自定义。 此外,它们还能处理特定的 HTML 到 PDF 转换边缘案例。
IronPDF最初使用一些默认值渲染新的 PDF 文件。 你可以通过调用 defaultChromePdfRenderOptions 函数来获取这些预设值:
import { defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
// Retrieve a ChromePdfRenderOptions object with default settings.
var options = defaultChromePdfRenderOptions();import { defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
// Retrieve a ChromePdfRenderOptions object with default settings.
var options = defaultChromePdfRenderOptions();本节将简要介绍需要使用 ChromePdfRenderOptions 接口的最流行的 HTML 到 PDF 渲染用例。
每个子节均始于预设值,并根据目标结果需要进行修改。
自定义 PDF 生成输出
添加自定义页眉和页脚
使用 textHeader 和 textFooter 属性,您可以将自定义页眉和/或页脚内容附加到新渲染的 PDF。
下面的示例为 Google 搜索主页创建了一个 PDF 版本,其自定义页眉和页脚为文本内容。 我们使用分割线将此内容与页面主体分开。 我们还在页眉和页脚中使用不同字体以使区分更明显。
import { PdfDocument, defaultChromePdfRenderOptions, AffixFonts } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Build a Custom Text-Based Header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Build a custom Text-Based Footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render a PDF from a URL
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});import { PdfDocument, defaultChromePdfRenderOptions, AffixFonts } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Build a Custom Text-Based Header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Build a custom Text-Based Footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render a PDF from a URL
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});源代码生成了此 PDF:
图 11 新页面被创建为 PDF 格式,生成自 Google 首页。 注意包含了额外的页眉和页脚。
为了更好地控制页眉和页脚中包含的布局、位置和内容,您还可以使用原始 HTML 而不是文本来定义它们。
在后续代码区块中,我们使用 HTML 在页眉和页脚中引入更丰富的内容。 在页眉中,我们将页面 URL 加粗并居中排列; 在页脚中嵌入并居中一个徽标。
import { PdfDocument, defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Define a rich HTML header
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
// Define a rich HTML footer
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Render a PDF from a URL
await PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});import { PdfDocument, defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Define a rich HTML header
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
// Define a rich HTML footer
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Render a PDF from a URL
await PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});下图显示了这些更改的结果。
图 12 IronPDF for Node.js 可以在将 HTML 页面转换为 PDF 时应用自定义设置。
设置边距、页面大小、页面方向和颜色
IronPDF 支持其他设置,用于定义新转换的 PDF 的自定义页边距、页面大小和页面方向。
import { PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Set top, left, right, and bottom page margins in millimeters.
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Create a PDF from the Google.com Home Page
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});import { PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Initialize render options with default settings
var options = defaultChromePdfRenderOptions();
// Set top, left, right, and bottom page margins in millimeters.
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Create a PDF from the Google.com Home Page
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});在上面的代码块中,我们配置 IronPDF 以使用黑白色调的横向方向及至少 50 毫米的边距空间生成我们的 Google 主页 PDF。 我们还设置它以适合 A5 纸张大小的内容。
从动态网页生成 PDF
对于包含在页面加载时不立即显示和呈现的内容的网页,可能需要暂停该页面内容的呈现,直到满足某些条件。
例如,开发人员可能需要生成一个包含在页面加载后 15 秒才出现的内容的 PDF。 在另一种情况下,相同内容可能仅在某些复杂的客户端代码执行后才出现。
为了处理这两种极端情况(以及更多其他情况), IronPDF的 Node 版本定义了 WaitFor 机制。 开发者可以在其 ChromePdfRenderOptions 设置中包含此属性,以指示 IronPDF 的 Chrome 渲染引擎在发生某些事件时转换页面内容。
以下代码块设置 IronPDF 等待 20 秒后捕获我们的主页内容作为 PDF:
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the Chrome Renderer to wait until 20 seconds has passed
// before rendering the web page as a PDF.
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
}
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the Chrome Renderer to wait until 20 seconds has passed
// before rendering the web page as a PDF.
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
}
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});下一个代码块配置 IronPDF 等待直到可以成功选择一个流行SEO 文本编辑器上的元素。
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the Chrome Renderer to wait up to 20 seconds for a specific element to appear
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
}
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the Chrome Renderer to wait up to 20 seconds for a specific element to appear
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
}
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});从 HTML 模板生成 PDF
在本教程的最后一部分中,我们将应用前几节中介绍的所有知识来完成一个非常实用的自动化:使用 HTML 模板生成一个或多个 PDF。
我们将在本节中使用的模板如下所示。 它是从这个公开访问的发票模板修改而来,包含了可替换内容的占位符标记(例如 {COMPANY-NAME}, {FULL-NAME}, {INVOICE-NUMBER} 等)。
图 13 示例发票模板。 我们将编写额外的 JavaScript 代码,在生成 PDF 之前向该模板添加动态数据。
在下一段源代码中,我们将把 HTML 模板加载到一个新的 PdfDocument 对象中,用一些虚拟测试数据替换我们定义的占位符,然后将 PdfDocument 对象保存到文件系统中。
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system.
*/
async function getTemplateHtml(fileLocation) {
// Return promise for loading template file
return PdfDocument.fromFile(fileLocation);
}
/**
* Save the PDF document at a given location.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Use the PdfDocument.replaceText method to replace
* a specified placeholder with a provided value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the template file
const template = "./sample-invoice.html";
// Load the template, replace placeholders, and save the PDF
getTemplateHtml(template).then(async (doc) => {
// Replace placeholders with real data
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system.
*/
async function getTemplateHtml(fileLocation) {
// Return promise for loading template file
return PdfDocument.fromFile(fileLocation);
}
/**
* Save the PDF document at a given location.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Use the PdfDocument.replaceText method to replace
* a specified placeholder with a provided value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the template file
const template = "./sample-invoice.html";
// Load the template, replace placeholders, and save the PDF
getTemplateHtml(template).then(async (doc) => {
// Replace placeholders with real data
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));上面的源代码定义了三个异步辅助函数:
getTemplateHtml: 使用PdfDocument.fromHtml方法将 HTML 模板加载到新的PdfDocument对象中。addTemplateData: 使用PdfDocument.replaceText方法将提供的占位符(称为键)替换为其替换数据值。generatePdf: 将PdfDocument保存到指定的文件位置。
此外,我们声明了一个变量 const template 来保存 HTML 模板文件的位置。下面显示了根据上述源代码生成的 PDF 文件。
图 14 从用实际数据替换 HTML 模板中的占位符所创建的新 PDF 文档。 该文档保留了我们期望在未进行任何替换时的 CSS 样式和布局。
进一步阅读
本教程仅仅触及了使用 IronPDF 的高级 API 函数所可能实现的广度。 考虑学习这些相关主题,以进一步增加您的知识和理解。
PdfGenerator类:这是一个专门用于从 HTML、URL、Zip 存档和其他源媒体创建PdfDocument对象的实用程序类。 此类为使用PdfDocument类中定义的 PDF 渲染函数提供了一种可行的替代方案。HttpLoginCredentials: 如果您需要从需要特定 cookie 或受密码保护的网页生成 PDF,那么此参考资料将非常有用。
常见问题解答
如何在 Node.js 中不丢失格式地将 HTML 转换为 PDF?
在 Node.js 中,您可以使用 IronPDF 将 HTML 转换为 PDF,而不会丢失格式,使用 PdfDocument.fromHtml 等方法,它支持将 HTML 字符串和文件精确渲染为 PDF 格式。
安装 IronPDF for Node.js 的步骤是什么?
要在 Node.js 项目中安装 IronPDF,请运行命令 npm install @Iron Software/ironpdf。这将把 IronPDF 包添加到您项目的依赖项中,允许您使用其 PDF 处理功能。
如何在 Node.js 中从网页 URL 生成 PDF?
您可以在 IronPDF 中使用 PdfDocument.fromUrl 方法通过提供页面的 URL 将网页直接转换为 PDF。该方法获取内容并将其渲染为 PDF 格式。
在 IronPDF 中定制 PDF 输出的选项是什么?
IronPDF 提供 ChromePdfRenderOptions 接口,允许自定义 PDF 输出。您可以通过此接口调整页面大小、方向、边距,并包含动态内容。
如何使用 IronPDF 向 PDF 文档添加页眉和页脚?
要在 IronPDF 中为 PDF 添加页眉和页脚,请利用 textHeader 和 textFooter 属性,这些属性在 ChromePdfRenderOptions 中可用。这允许在每页的顶部和底部插入自定义文本。
是否可以使用 Node.js 将 zip 压缩包中的 HTML 文件转换为 PDF?
是的,IronPDF 支持使用 PdfDocument.fromZip 方法将位于 zip 存档中的 HTML 文件转换为 PDF,实现对多个 HTML 文件的批处理。
如何移除使用 IronPDF 生成的 PDF 中的水印?
要从使用 IronPDF 创建的 PDF 中删除水印,必须在您的应用程序中应用有效的许可证密钥。这可以通过使用 IronPdf.License.LicenseKey 方法来完成。
如何处理将异步 Web 内容转换为 PDF 的问题?
IronPDF 提供了 WaitFor 机制来管理异步内容,确保在开始 PDF 渲染过程之前,所有动态元素都已完全加载。
IronPDF 可以将受密码保护的网页转换为 PDF 吗?
是的,使用 HttpLoginCredentials 在 ChromePdfRenderOptions 中,您可以输入必要的凭据来访问和转换受密码保护的网页为 PDF。
如果 HTML 到 PDF 转换无法保持正确布局,我应该怎么做?
确保您使用适当的 ChromePdfRenderOptions 来匹配布局要求。调整页面大小、方向和边距等设置可以帮助保持转换后 PDF 的期望布局。
IronPDF 是否完全支持 .NET 10 中的 HTML 转 PDF 转换?
是的——IronPDF 支持 .NET 10,可使用ChromePdfRenderer等类将 HTML 转换为 PDF,包括RenderHtmlAsPdf 、 RenderHtmlFileAsPdf和RenderUrlAsPdf方法,并支持 CSS3、JavaScript、图像和外部资源。IronPDF 的 .NET PDF 库功能文档中对此有明确说明。


还在滚动吗?
想快速获得证据?
运行示例看着你的HTML代码变成PDF文件。











