
iText7 Read PDF in C# Alternatives (VS IronPDF)
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
IronPDF vs iText / iText
Comprehensive .NET PDF library comparison — feature-by-feature with evidence-based context
| Feature | iText / iText | IronPDF ✦ |
|---|---|---|
| PDF Creation & Conversion | ||
| HTML/CSS to PDF |
$ Paid Add-on
HTML→PDF via
pdfHTML add-on (separate package; AGPL/commercial model). |
✓ Yes
Chromium-based engine with pixel-perfect CSS3, Flexbox, and Grid rendering built-in.
|
| JavaScript Execution |
? Unknown
pdfHTML describes HTML/CSS→PDF conversion, but JS execution support is not stated in docs.
|
✓ Yes
Fully executes JS during rendering — dynamic charts, SPAs, and interactive content.
|
| Programmatic Generation |
✓ Yes
Positioned as a programmable PDF SDK for .NET — create, edit, and enhance.
|
✓ Yes
Generate from HTML templates, strings, ASPX views, or images. Chromium handles layout.
|
| URL to PDF |
$ Paid Add-on
Possible via pdfHTML add-on with URL fetching, but not a core feature.
|
✓ Yes
RenderUrlAsPdf() captures any live URL with full CSS/JS rendering. |
| DOCX to PDF |
✕ No
No native Word conversion — iText is a PDF-native SDK.
|
✓ Yes
DocxToPdfRenderer converts Word docs preserving structure and formatting. |
| Reading & Extraction | ||
| Text Extraction |
✓ Yes
PdfTextExtractor.GetTextFromPage() with multiple extraction strategies. |
✓ Yes
Extracts text with layout awareness. Combines with IronOCR for scanned docs.
|
| Render Pages to Images |
? Unknown
OCR workflows mention rendering, but a primary-source "PDF→image renderer" module isn't
evidenced in cited iText docs.
|
✓ Built-in
Native rasterization to PNG, JPEG, BMP with configurable DPI.
|
| Built-in OCR |
$ Paid Add-on
pdfOCR add-on available; install notes mention platform-specific/native dependencies (e.g.,
Linux/macOS runtime requirements).
|
✓ Via IronOCR
Native integration with IronOCR for 127+ language OCR on scanned PDFs.
|
| Editing & Manipulation | ||
| Merging & Splitting |
✓ Yes
PdfMerger class in .NET API; official examples discuss merging via PdfMerger.
|
✓ Yes
One-line merge, split, append, prepend, and page reordering with intuitive API.
|
| Headers, Footers & Page Numbers |
✓ Yes
PDF Association listing confirms ability to add "page numbers" and similar features to
existing PDFs.
|
✓ Yes
HTML-based headers/footers with auto page numbers, dates, and custom content.
|
| Watermarks |
✓ Yes
PDF Association listing explicitly includes "watermarks … to existing PDF documents."
|
✓ Yes
ApplyWatermark() accepts HTML/CSS — full control over opacity, rotation,
position. |
| Stamp Text & Images |
✓ Yes
Programmatic content placement available via iText's canvas and layout APIs.
|
✓ Yes
TextStamper & ImageStamper with Google Fonts, positioning,
per-page control. |
| Redact Content |
✓ Yes
iText provides redaction annotation support via the cleanup module.
|
✓ Yes
RedactTextOnAllPages() removes sensitive text permanently in a single line.
|
| Security & Compliance | ||
| Encryption & Passwords |
✓ Yes
Full encryption and permission controls via iText's security API.
|
✓ Yes
AES encryption, owner/user passwords, granular permissions (print, copy, annotate).
|
| Digital Signatures |
✓ Yes
Dedicated digital signing documentation and signing API (
PdfSigner). |
✓ Yes
PdfSignature with X509/PFX certificate support. |
| PDF/A & PDF/UA Compliance |
✓ Yes
Documentation covers creating PDF/A and explains constraints (conversion from existing isn't
automatic).
|
✓ Yes
Native PDF/A archival and PDF/UA accessibility compliance for enterprise use.
|
| Platform & Deployment | ||
| Cross-Platform Support |
✓ Yes
.NET Standard 2.0 / .NET Framework 4.6.1 — runs on .NET 6+ across OSes.
|
✓ Yes
Windows, Linux, macOS, x64, x86, ARM. .NET 6–10, Core, Standard 2.0+, Framework 4.6.2+.
|
| Server / Docker / Cloud |
~ Complex
Core install requires multiple packages (iText + Bouncy Castle adapter); add-ons
(pdfHTML/pdfOCR) add further dependency/compliance steps.
|
✓ Yes
Docker, Azure, AWS, IIS. Official Docker images and deployment guides.
|
| Ease of Setup |
~ Complex
Core install requires multiple packages (Bouncy Castle adapter); HTML/OCR require additional
add-ons and sometimes native deps.
|
✓ Simple
Single
Install-Package IronPdf NuGet command. Ready in minutes. |
| Licensing & Support | ||
| Licensing Model |
~ Complex
Dual-license: AGPLv3 (source-disclosure obligations for network use) or commercial. AGPL can
be restrictive for proprietary apps.
|
✓ Commercial
Perpetual licenses. 30-day fully functional free trial, no watermarks.
|
| Commercial Support & SLA |
✓ Yes
iText site includes commercial licensing + support agreements as part of its licensing model.
|
✓ 24/5 Support
Dedicated engineering support with guaranteed SLA — email, live chat, phone.
|
| Documentation |
✓ Yes
Installation guides, knowledge base articles, and API references available (core + add-ons).
|
✓ Extensive
Full API reference, 100+ how-tos, tutorials, code examples, troubleshooting, videos.
|
Data sourced from official iText documentation, PDF Association listing, and NuGet package references.
iText is powerful but carries AGPL licensing complexity and multi-package setup overhead.
IronPDF delivers full coverage with simpler setup — try free for 30
days.
PDF is a portable document format created by Adobe Acrobat Reader, widely used for sharing information digitally over the internet. It preserves the formatting of data and provides features like setting security permissions and password protection. As a C# developer, you may have encountered scenarios where integrating PDF functionality into your software application is necessary. Building it from scratch can be a time-consuming and tedious task. Therefore, considering the performance, effectiveness, and efficiency of the application, the trade-off between creating a new service from scratch or using a prebuilt library is significant.
There are several PDF libraries available for C#. In this article, we will explore two of the most popular PDF libraries for reading PDF documents in C#.
iText software
iText, formerly known as iText Core, is a PDF library to program PDF documents in .NET C# and Java. It is available as an open source license (AGPL) and can be licensed for commercial applications.
iText Core is a high-level API that provides easy methods to generate and edit PDFs in all possible ways. With iText Core, you can split, merge, annotate, fill forms, digitally sign, and do much more on PDF files. iText provides an HTML to PDF converter.
IronPDF
Learn more about IronPDF is a .NET and .NET Framework C# and Java API used for generating PDF documents from HTML, CSS, and JavaScript either from a URL, HTML files, or HTML strings. IronPDF allows you to manipulate existing PDF files like splitting, merging, annotating, digitally signing, and much more.
IronPDF is enriched with 50+ features to create, read, and edit PDF files. It prioritizes speed, ease of use, and accuracy when you need to deliver high-quality, pixel-perfect professional PDF files with Adobe Acrobat Reader. The API is well documented, and a lot of sample source code can be found on its code examples page.
Create a Console Application
We are going to use Visual Studio 2022 IDE for creating an application to start with. Visual Studio is the official IDE for C# development, and you must have it installed. You can download it from the Microsoft Visual Studio website if not installed.
The following steps will create a new project named "DemoApp".
-
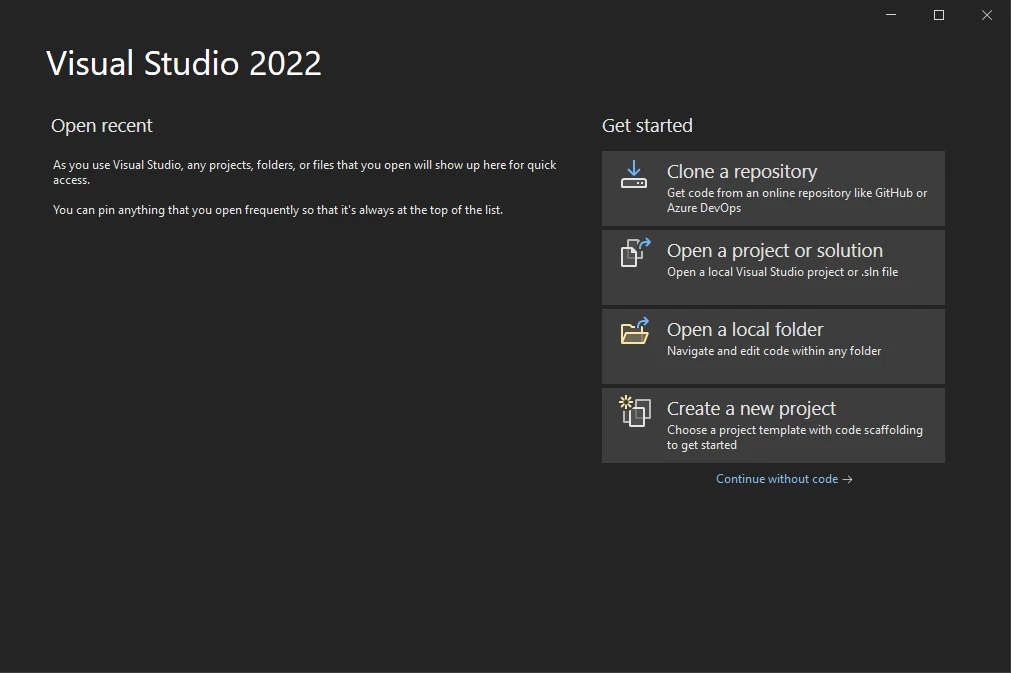
Open Visual Studio and click on "Create a New Project".
-
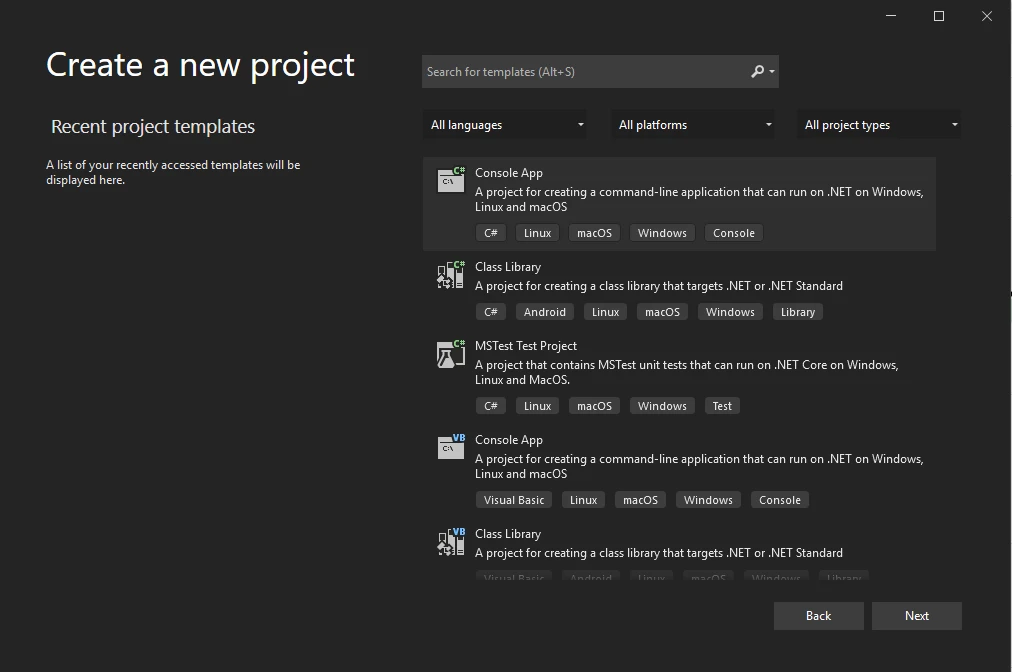
Select "Console Application" and click "Next".
-
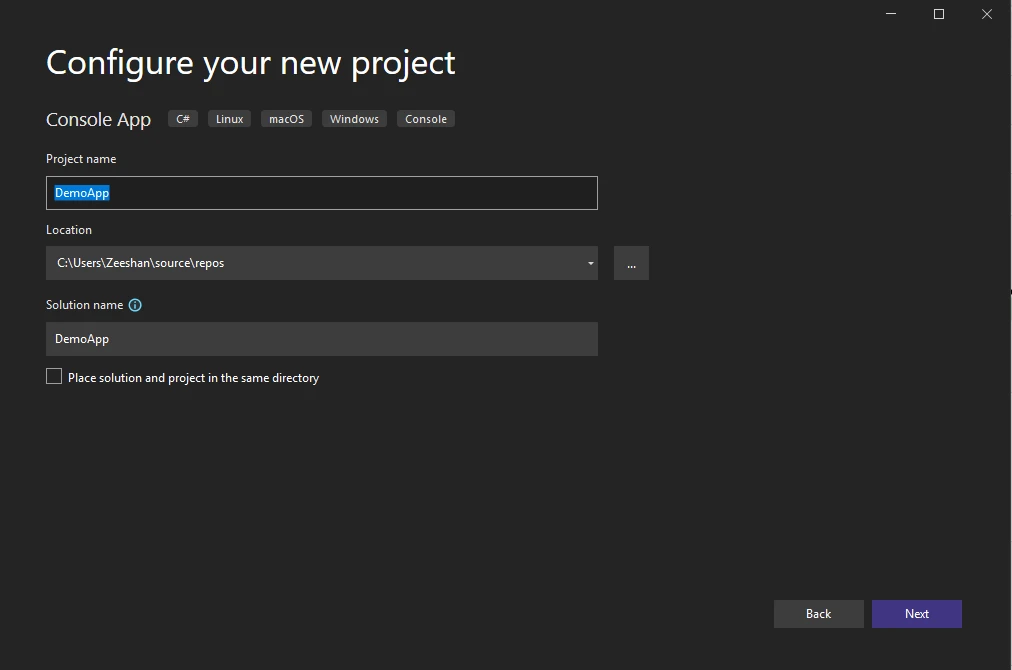
Set the name of the project.
-
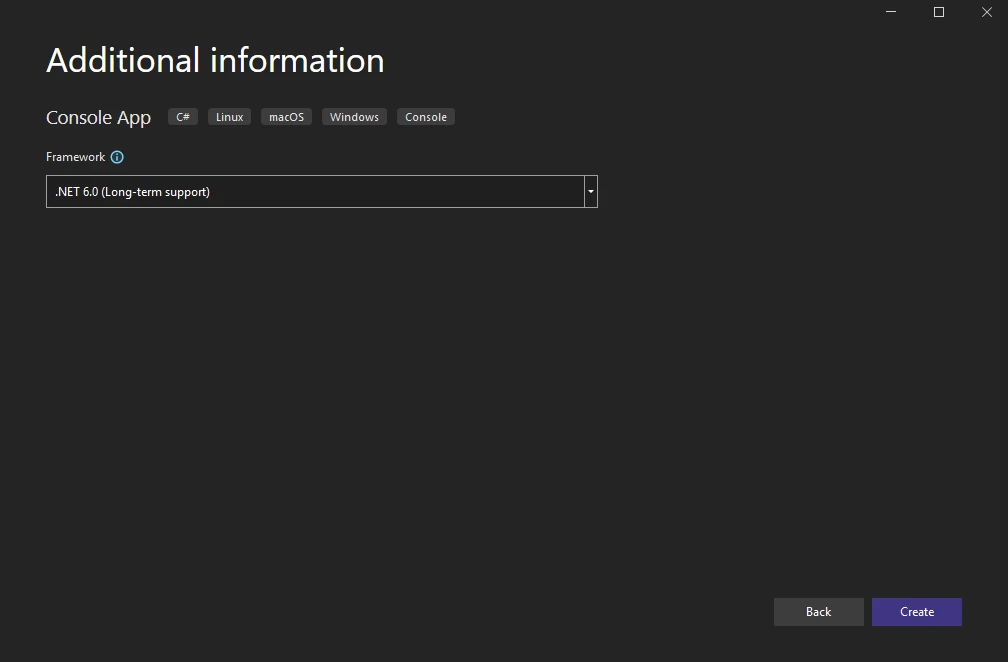
Select the .NET version. Choose the stable version .NET 6.0.
Install IronPDF Library
Once the project is created, the IronPDF library needs to be installed in the project to use it. Follow these steps to install it.
-
Open NuGet Package Manager, either from solution explorer or Tools.
-
Browse for IronPDF Library and select it for the current project. Click Install.
Add the following namespace at the top of Program.cs file:
using IronPdf;using IronPdf;Imports IronPdfInstall iText Library
Once the project is created, the iText library needs to be installed in the project to use it. Follow the steps to install it.
-
Open NuGet Package Manager either from solution explorer or Tools.
-
Browse for iText Library and select it for the current project. Click install.
Add the following namespaces at the top of Program.cs file:
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Imports iText.Kernel.PdfOpen PDF files
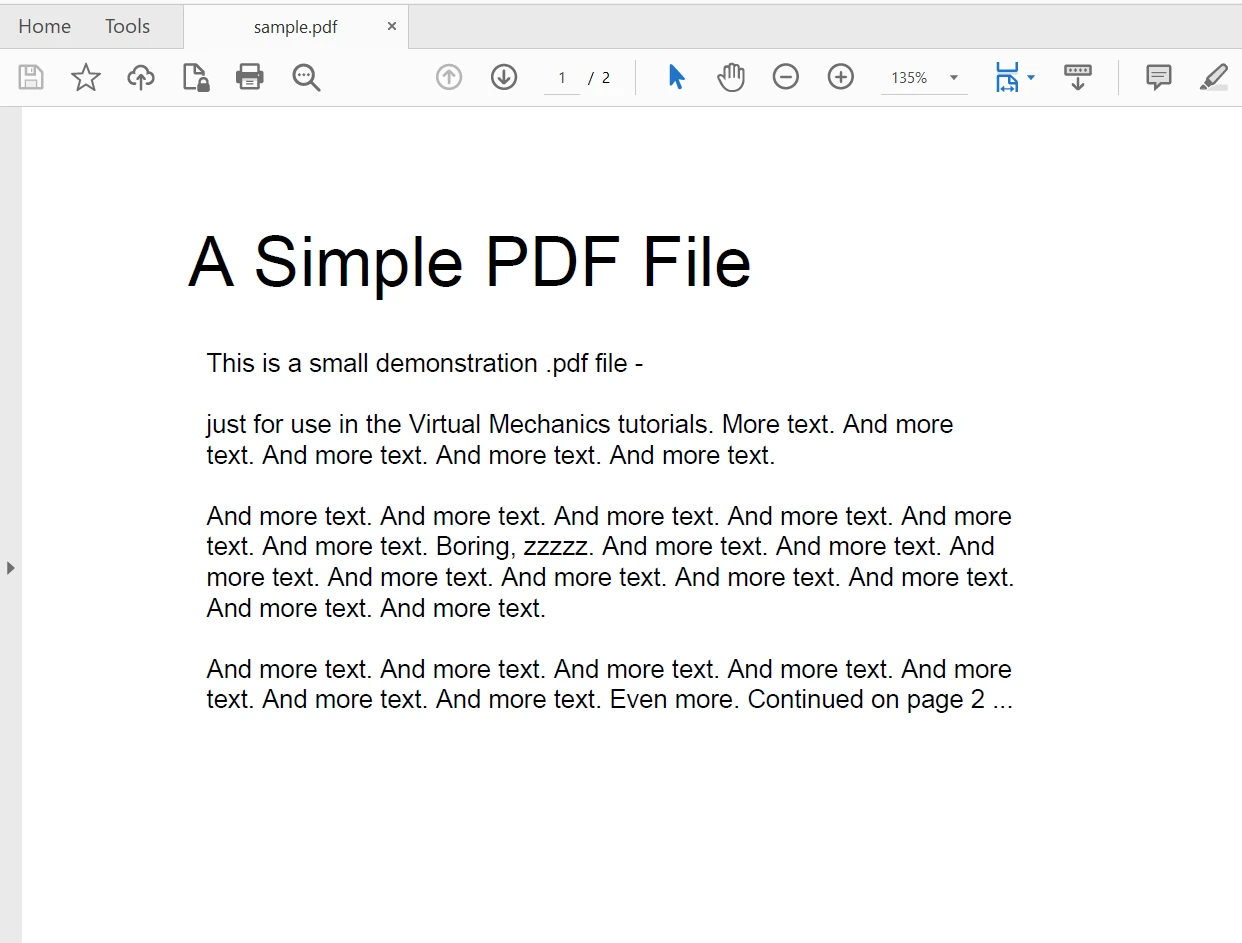
We are going to use the following PDF file to extract text from it. It is a two-page PDF document.
Using iText library
To open a PDF file using the iText library is a two-step process. First, we create a PdfReader object and pass the file location as a parameter. Then we use the PdfDocument class to create a new PDF document. The code goes as follows:
// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);' Initialize a reader instance by specifying the path of the PDF file
Dim pdfReader As New PdfReader("sample.pdf")
' Initialize a document instance using the PdfReader
Dim pdfDoc As New PdfDocument(pdfReader)Using IronPDF
Opening PDF files using IronPDF is easy. Use the PdfDocument class's FromFile method to open PDFs from any file location. The following one-line code opens a PDF file for reading data:
// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");' Open a PDF file using IronPDF and create a PdfDocument instance
Dim pdf = PdfDocument.FromFile("sample.pdf")Read Data from PDF files
Using iText library
To read PDF data is not that straightforward in the iText library. We have to manually loop through each page of the PDF document to extract text from each page. The following source code helps to extract text from the PDF document page by page:
// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();' Iterate through each page and extract text
Dim page As Integer = 1
Do While page <= pdfDoc.GetNumberOfPages()
' Define the text extraction strategy
Dim strategy As ITextExtractionStrategy = New SimpleTextExtractionStrategy()
' Extract text from the current page using the strategy
Dim pageContent As String = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy)
' Output the extracted text to the console
Console.WriteLine(pageContent)
page += 1
Loop
' Close document and reader to release resources
pdfDoc.Close()
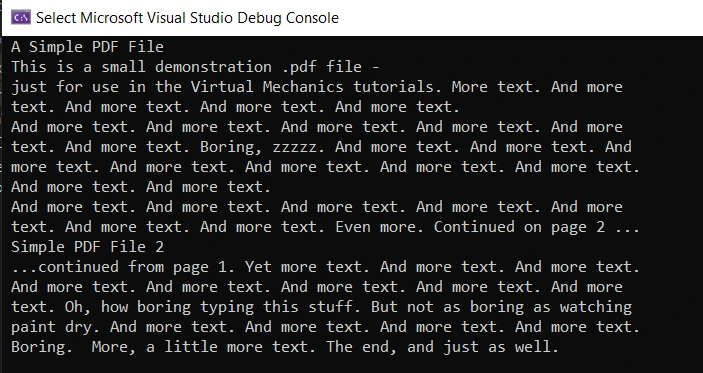
pdfReader.Close()There is a lot going on in the code above. First, we declare the Text Extraction Strategy, and then we use the PdfExtractor class's GetTextFromPage method to read text. This method accepts two parameters: the first one is the PDF document page, and the second one is the strategy. To get the PDF document page, use the instance of PdfDocument to call the GetPage method and pass the page number as a parameter. The output is returned as a string, which is then displayed on the console output screen. Finally, the PDFReader and PdfDocument objects are closed. Also, look at the following code example on extracting text from PDF using iText.
Output
Using IronPDF
Just like opening the PDF file was one line of code, similarly, reading text from a PDF file is also a one-line process. The PDFDocument class provides the ExtractAllText method to read the entire content from the PDF. Console.WriteLine is used to print the text on the screen. The code is as follows:
// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);' Extract all text from the PDF document
Dim text As String = pdf.ExtractAllText()
' Display the extracted text
Console.WriteLine(text)Output
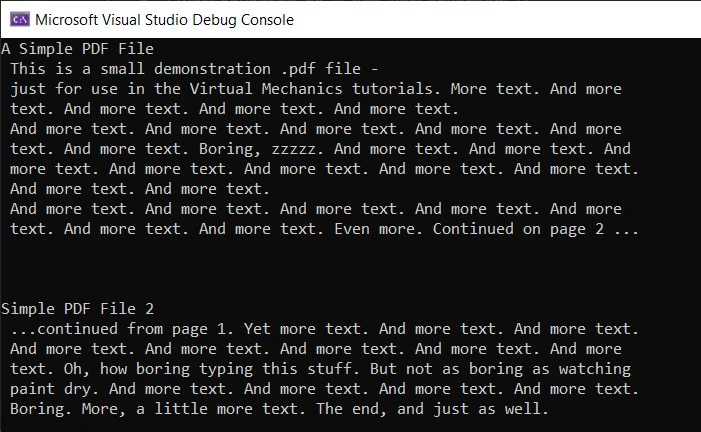
The output is accurate and without any errors. However, to use the ExtractAllText method, you need to have a license as it only works in production mode. You can get your trial license key for 30 days from the IronPDF trial license page.
Comparison
In comparison, both libraries produce accurate results while extracting text from a PDF document. They are comparable when it comes to text extraction accuracy. However, IronPDF is more efficient in terms of code readability and developer ergonomics.
IronPDF only takes two lines of code to achieve the same task as iText. It provides text extraction methods out of the box without any extra logic to be implemented. iText code is a bit tricky, and you have to close the two instances created at the time of opening a PDF document. Whereas, IronPDF clears the memory automatically once the task is performed.
Summary
In this article, we looked at how to read PDF documents using the iText library in C# and then compared it with IronPDF. Both libraries give accurate results and provide numerous PDF manipulation methods to work with. You can create, edit, and read data from PDF files using both of these libraries.
iText is open source and free to use but with restrictions. It can be licensed for commercial use. IronPDF is also free to use and can be licensed for commercial activities with a 30-day free trial available.
Download IronPDF and give it a try.
Frequently Asked Questions
What is IronPDF and how does it compare to iText 7?
IronPDF is a .NET library designed for generating and manipulating PDF documents from HTML, CSS, and JavaScript. Compared to iText 7, IronPDF emphasizes speed, ease of use, and accuracy, requiring fewer lines of code to achieve PDF tasks.
How can I convert HTML to PDF in C#?
You can use IronPDF's RenderHtmlAsPdf method to convert HTML strings into PDFs. Additionally, you can convert HTML files into PDFs using RenderHtmlFileAsPdf.
What are the installation steps for IronPDF in a C# project?
To install IronPDF in a C# project, open the NuGet Package Manager in Visual Studio, search for IronPDF, select it for your project, and click Install. Include using IronPdf; at the top of your C# file.
How do I extract text from a PDF using IronPDF?
To extract text from a PDF using IronPDF, utilize the PdfDocument class's FromFile method to load the PDF, followed by the ExtractAllText method to retrieve the text.
What are some troubleshooting tips for using IronPDF?
Ensure IronPDF is correctly installed via NuGet and that the proper namespaces are included in your C# file. Verify the file paths and ensure that the HTML content is well-formed if converting HTML to PDF.
Can IronPDF handle PDF forms and annotations?
Yes, IronPDF supports features such as filling forms and adding annotations to PDFs, allowing you to create interactive and dynamic PDF documents.
Is IronPDF free to use?
IronPDF offers a free version with limited features and a 30-day free trial for its commercial version, which provides a full range of functionalities.
What are the limitations of using iText 7 for PDF manipulation?
While iText 7 is a robust PDF library, it requires additional logic for certain tasks like text extraction, which can result in more complex and lengthy code compared to IronPDF.













