
Jak czytać tabele PDF w C#
Wyciąganie danych z tabeli strukturalnej z dokumentów PDF jest częstą potrzebą dla programistów C#, kluczowe dla analizy danych, raportowania lub integracji informacji z innymi systemami. Jednakże, PDFy są przede wszystkim zaprojektowane do spójnej prezentacji wizualnej, a nie do łatwego wyodrębniania danych. To może sprawić, że programistyczne czytanie tabel z plików PDF w C# staje się wyzwaniem, szczególnie gdy tabele mogą się znacznie różnić — od prostych siatek tekstowych po złożone układy ze scalonymi komórkami, a nawet tabele osadzone jako obrazy w zeskanowanych dokumentach.
Ten przewodnik zapewnia kompleksowy samouczek C# dotyczący wyodrębniania tabel PDF za pomocą IronPDF. Będziemy głównie eksplorować wykorzystanie potężnych możliwości ekstrakcji tekstu IronPDF do dostępu i analizowania danych tabelarycznych z PDFów opartych na tekście. Omówimy skuteczność tej metody, zapewnimy strategie przetwarzania i oferujemy wgląd w obsługę wyodrębnionych informacji. Dodatkowo omówimy strategie radzenia sobie z bardziej złożonymi scenariuszami, w tym zeskanowanymi PDF-ami.
Kluczowe Kroki do Wyciągania Danych Tabelarycznych z PDF w C#
- Zainstaluj bibliotekę IronPDF C# (https://nuget.org/packages/IronPdf/) do przetwarzania PDF.
- (Opcjonalny Krok Demo) Utwórz próbkę PDF z tabelą z ciągu HTML za pomocą
RenderHtmlAsPdfIronPDF. (Patrz sekcja: (Krok Demo) Tworzenie Dokumentu PDF z Danymi Tabeli) - Załaduj dowolny dokument PDF i użyj metody
ExtractAllText, aby uzyskać jego surową zawartość tekstową. (See section: Extract All Text Containing Table Data from the PDF) - Zaimplementuj logikę C# do przetworzenia wyodrębnionego tekstu i zidentyfikowania wierszy oraz komórek tabeli. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Wyświetl dane tabelaryczne w strukturze lub zapisz je w pliku CSV do dalszego wykorzystania. (See section: Parsing Extracted Text to Reconstruct Table Data in C#)
- Rozważ zaawansowane techniki, takie jak OCR dla zeskanowanych PDF (omówione później).
IronPDF - Biblioteka PDF C#
IronPDF to rozwiązanie biblioteki C# .NET do manipulacji PDF w .NET (https://ironpdf.com/), które pomaga programistom w łatwym czytaniu, tworzeniu i edytowaniu dokumentów PDF w ich aplikacjach. Jego solidny silnik Chromium renderuje dokumenty PDF z HTML z wysoką dokładnością i szybkością. Pozwala programistom na bezproblemową konwersję z różnych formatów do PDF i odwrotnie. Wspiera najnowsze frameworki .NET, w tym .NET 7, .NET 6, 5, 4, .NET Core oraz Standard.
Co więcej, API IronPDF dla .NET umożliwia programistom manipulację i edycję PDF, dodawanie nagłówków i stopki oraz co najważniejsze, łatwe wyodrębnianie tekstu, obrazów i (jak zobaczymy) danych tabelarycznych z PDF.
Niektóre ważne funkcje obejmują:
- Tworzenie plików PDF z różnych źródeł (HTML to PDF, Images to PDF)
- Ładowanie, zapisywanie i drukowanie plików PDF
- Scalanie i dzielenie plików PDF
- Wyodrębnianie danych (tekst, obrazy i strukturalne dane jak tabele) z plików PDF
Kroki do Wyodrębniania Danych Tabelarycznych w C# za pomocą Biblioteki IronPDF
Aby wyodrębnić dane tabelaryczne z dokumentów PDF, ustawimy projekt w C#:
- Visual Studio: Upewnij się, że masz zainstalowane Visual Studio (np. 2022). Jeśli nie, pobierz je ze strony Visual Studio (https://visualstudio.microsoft.com/downloads/).
-
Utwórz Projekt:
-
Otwórz Visual Studio 2022 i kliknij Utwórz nowy projekt.
 Ekran startowy Visual Studio
Ekran startowy Visual Studio -
Wybierz "Aplikacja konsolowa" (lub preferowany typ projektu C#) i kliknij Dalej.
 Utwórz nową aplikację konsolową w Visual Studio
Utwórz nową aplikację konsolową w Visual Studio -
Nazwij swój projekt (np. "ReadPDFTableDemo") i kliknij Dalej.
 Skonfiguruj nowo utworzoną aplikację
Skonfiguruj nowo utworzoną aplikację -
Wybierz pożądany Framework .NET (np. .NET 6 lub nowszy).
 Wybierz Framework .NET
Wybierz Framework .NET - Kliknij Utwórz. Projekt konsolowy zostanie utworzony.
-
-
Zainstaluj IronPDF:
-
Używając Menadżera Pakietów NuGet Visual Studio:
- Kliknij prawym przyciskiem na swoim projekcie w Eksploratorze rozwiązań i wybierz "Zarządzaj pakietami NuGet..."
 Narzędzia & Zarządzaj Pakietami NuGet
Narzędzia & Zarządzaj Pakietami NuGet- W Menedżerze Pakietów NuGet, wyszukaj "IronPdf" i kliknij "Zainstaluj".
 Narzędzia & Zarządzaj Pakietami NuGet
Narzędzia & Zarządzaj Pakietami NuGet
- Pobierz pakiet NuGet bezpośrednio: Odwiedź stronę pakietów NuGet IronPDF (https://www.nuget.org/packages/IronPdf/).
- Pobierz bibliotekę .DLL IronPDF: Pobierz z oficjalnej strony IronPDF i dołącz bibliotekę DLL do swojego projektu.
-
(Krok Demo) Utwórz Dokument PDF z Danymi Tabeli
W tym samouczku najpierw utworzymy przykładowy PDF zawierający prostą tabelę z ciągu HTML. To da nam znaną strukturę PDF do demonstracji procesu wyodrębniania. W rzeczywistym scenariuszu załadujesz swoje istniejące pliki PDF.
Dodaj przestrzeń nazw IronPDF i opcjonalnie ustaw swój klucz licencyjny (IronPDF jest bezpłatne do rozwoju, ale wymaga licencji do komercyjnego wdrożenia bez znaków wodnych):
using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
using System; // For StringSplitOptions, Console
using System.IO; // For StreamWriter
// Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
// License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
Imports System ' For StringSplitOptions, Console
Imports System.IO ' For StreamWriter
' Apply your license key if you have one. Otherwise, IronPDF runs in trial mode.
' License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Oto ciąg HTML dla naszej przykładowej tabeli:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h1>" + // Corrected typo: h1 not h2
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Teraz, użyj ChromePdfRenderer, aby utworzyć PDF z tego HTML:
var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");var renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");
Console.WriteLine("Sample PDF 'table_example.pdf' created.");Dim renderer = New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")
Console.WriteLine("Sample PDF 'table_example.pdf' created.")Metoda SaveAs zapisuje PDF. Wygenerowany table_example.pdf będzie wyglądał tak (obraz koncepcyjny na podstawie HTML):
 Wyszukaj IronPDF w interfejsie użytkownika menedżera pakietów NuGet
Wyszukaj IronPDF w interfejsie użytkownika menedżera pakietów NuGet
Wyodrębnij Wszystkie Teksty Zawierające Dane Tabeli z PDF
Aby wyodrębnić dane tabelaryczne, najpierw ładujemy PDF (ten, który właśnie utworzyliśmy lub dowolny istniejący PDF) i używamy metody ExtractAllText. Ta metoda pobiera całą zawartość tekstową z stron PDF.
// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();// Load the PDF (if you just created it, it's already loaded in pdfDocument)
// If loading an existing PDF:
// PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
// Or use the one created above:
string allText = pdfDocument.ExtractAllText();' Load the PDF (if you just created it, it's already loaded in pdfDocument)
' If loading an existing PDF:
' PdfDocument pdfDocument = PdfDocument.FromFile("table_example.pdf");
' Or use the one created above:
Dim allText As String = pdfDocument.ExtractAllText()Zmienna allText teraz przechowuje całą zawartość tekstową z pdf. Możesz ją wyświetlić, aby zobaczyć surowe wyodrębnienie:
Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Console.WriteLine("\n--- Raw Extracted Text ---");
Console.WriteLine(allText);Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Raw Extracted Text ---")
Console.WriteLine(allText)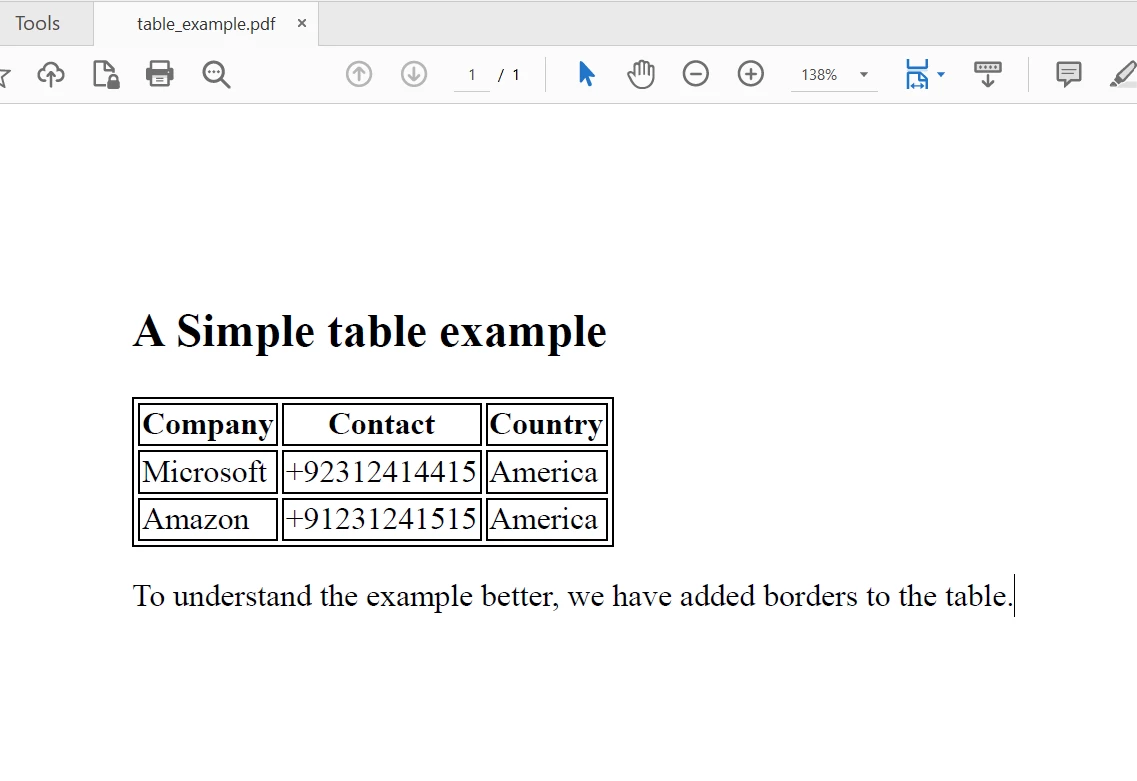 Plik PDF do wyodrębniania tekstu
Plik PDF do wyodrębniania tekstu
Parsowanie Wyodrębnionego Tekstu w celu Rekonstrukcji Danych Tabelarycznych w C#
Z wyodrębnionym surowym tekstem, kolejnym wyzwaniem jest przeparsowanie tego ciągu, aby zidentyfikować i ustrukturalizować dane tabelaryczne. Ten krok jest mocno zależny od spójności i formatu tabel w twoich PDF.
Ogólne Strategie Parsowania:
- Zidentyfikuj Separatory Wierszy: Znaki nowej linii (
\nlub\r\n) są powszechnymi separatorami wierszy. - Zidentyfikuj Separatory Kolumn: Komórki w wierszu mogą być oddzielone przez wiele spacji, tabulatory lub określone znane znaki (jak '|" lub ';'). Czasami, jeśli kolumny są wizualnie wyrównane, ale brakuje im wyraźnych separatorów tekstu, można wnioskować o strukturze na podstawie wzorców spacji, choć jest to bardziej złożone.
- Filtruj Zawartość poza Tabelą: Metoda
ExtractAllTextpobiera cały tekst. Będziesz potrzebować logiki, aby wyizolować tekst, który faktycznie tworzy twoją tabelę, być może poprzez szukanie słów kluczowych w nagłówkach lub pomijanie tekstów wstępnych/kończących.
Metoda C# String.Split jest podstawowym narzędziem do tego. Oto przykład, który próbuje wyodrębnić tylko linie tabeli z naszej próbki, filtrując linie z kropkami (prosta heurystyka dla tego konkretnego przykładu):
Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Console.WriteLine("\n--- Parsed Table Data (Simple Heuristic) ---");
string[] textLines = allText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (string line in textLines)
{
// Simple filter: skip lines with a period, assuming they are not table data in this example
// and skip lines that are too short or headers if identifiable
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// Further split line into cells based on expected delimiters (e.g., multiple spaces)
// This part requires careful adaptation to your PDF's table structure
// Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line); // For now, just print the filtered line
}
}Imports Microsoft.VisualBasic
Console.WriteLine(vbLf & "--- Parsed Table Data (Simple Heuristic) ---")
Dim textLines() As String = allText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line As String In textLines
' Simple filter: skip lines with a period, assuming they are not table data in this example
' and skip lines that are too short or headers if identifiable
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' Further split line into cells based on expected delimiters (e.g., multiple spaces)
' This part requires careful adaptation to your PDF's table structure
' Example: string[] cells = line.Split(new[] { " ", "\t" }, StringSplitOptions.None);
Console.WriteLine(line) ' For now, just print the filtered line
End If
Next lineTen kod dzieli tekst na linie. Warunek if to bardzo podstawowy filtr dla tego konkretnego przykładu tekstów spoza tabeli. W rzeczywistych scenariuszach potrzebowałbyś bardziej solidnej logiki do dokładnego identyfikowania i analizowania wierszy oraz komórek tabeli.
Wynik prostego przefiltrowanego tekstu:
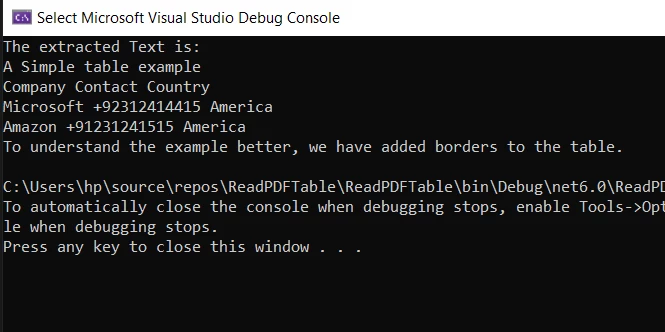 Konsola wyświetla wyodrębnione teksty
Konsola wyświetla wyodrębnione teksty
Ważne Rozważania dla Metody Parsowania Tekstu:
- Najlepiej Pasuje Do: PDFy oparte na tekście z prostymi, spójnymi strukturami tabelarycznymi i wyraźnymi delimitatorami tekstu.
- Ograniczenia: Ta metoda może mieć problemy z:
- Tabelami z połączonymi komórkami lub złożoną strukturą zagnieżdżoną.
- Tabelami, gdzie kolumny są określone przez wizualne odstępy, a nie delimitatory tekstu.
- Tabelami osadzonymi jako obrazy (wymagającymi OCR).
- Różnicami w generacji PDF prowadzącymi do niespójności w kolejności wyodrębniania tekstu.
Możesz zapisać przefiltrowane linie (które idealnie reprezentują wiersze tabeli) w pliku CSV:
using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");using (StreamWriter file = new StreamWriter("parsed_table_data.csv", false))
{
file.WriteLine("Company,Contact,Country"); // Write CSV Header
foreach (string line in textLines)
{
if (line.Contains(".") || line.Contains("A Simple table example") || line.Length < 5)
{
continue;
}
else
{
// For a real CSV, you'd split 'line' into cells and join with commas
// E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
// string csvLine = string.Join(",", cells);
// file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()); // Basic replacement for this example
}
}
}
Console.WriteLine("\nFiltered table data saved to parsed_table_data.csv");Imports Microsoft.VisualBasic
Using file As New StreamWriter("parsed_table_data.csv", False)
file.WriteLine("Company,Contact,Country") ' Write CSV Header
For Each line As String In textLines
If line.Contains(".") OrElse line.Contains("A Simple table example") OrElse line.Length < 5 Then
Continue For
Else
' For a real CSV, you'd split 'line' into cells and join with commas
' E.g., string[] cells = line.Split(new[] {" "}, StringSplitOptions.RemoveEmptyEntries);
' string csvLine = string.Join(",", cells);
' file.WriteLine(csvLine);
file.WriteLine(line.Replace(" ", ",").Trim()) ' Basic replacement for this example
End If
Next line
End Using
Console.WriteLine(vbLf & "Filtered table data saved to parsed_table_data.csv")Strategie do Bardziej Złożonego Wyodrębniania Tabel PDF w C#
Wyodrębnianie danych z bardziej złożonych lub obrazowych tabel PDF często wymaga bardziej zaawansowanych technik niż proste parsowanie tekstu. IronPDF oferuje funkcje, które mogą pomóc:
- Użycie Zdolności IronOCR dla Zeskanowanych Tabel: Jeśli tabele znajdują się w obrazach (np. zeskanowane PDF),
ExtractAllText()samodzielnie ich nie uchwyci. Funkcjonalność wykrywania tekstu IronOCR najpierw może przekształcić te obrazy na tekst.
// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}// Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
// Install Package IronOcr
using IronOcr;
using (var ocrInput = new OcrInput("scanned_pdf_with_table.pdf"))
{
ocrInput.TargetDPI = 300; // Good DPI for OCR accuracy
var ocrResult = new IronOcr().Read(ocrInput);
string ocrExtractedText = ocrResult.Text;
// Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine("\n--- OCR Extracted Text for Table Parsing ---");
Console.WriteLine(ocrExtractedText);
}' Conceptual OCR usage (refer to IronOCR's documentation for detailed implementation)
' Install Package IronOcr
Imports Microsoft.VisualBasic
Imports IronOcr
Using ocrInput As New OcrInput("scanned_pdf_with_table.pdf")
ocrInput.TargetDPI = 300 ' Good DPI for OCR accuracy
Dim ocrResult = (New IronOcr()).Read(ocrInput)
Dim ocrExtractedText As String = ocrResult.Text
' Now, apply parsing logic to 'ocrExtractedText'
Console.WriteLine(vbLf & "--- OCR Extracted Text for Table Parsing ---")
Console.WriteLine(ocrExtractedText)
End UsingDla szczegółowych wskazówek, odwiedź dokumentację IronOCR (https://ironsoftware.com/csharp/ocr/). Po OCR, przetwarzasz wynikowy ciąg tekstowy.
-
Wyodrębnianie Tekstu na Podstawie Współrzędnych (Zaawansowane): Choć IronPDF
ExtractAllText()dostarcza strumień tekstowy, niektóre scenariusze mogą skorzystać na poznaniu współrzędnych x,y każdego fragmentu tekstu. Jeśli IronPDF oferuje API do uzyskania tekstu z informacją o jego polu ograniczającym (sprawdź aktualną dokumentację), to mogłoby to pozwolić na bardziej wyrafinowane parsowanie przestrzenne do rekonstrukcji tabel na podstawie wizualnego wyrównania. - Konwersja PDF do Innego Formatu: IronPDF może konwertować PDF do formatów strukturali jak HTML. Często analizowanie tabeli HTML jest prostsze niż przetwarzanie surowego tekstu PDF.
PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.PdfDocument pdfToConvert = PdfDocument.FromFile("your_document.pdf");
string htmlOutput = pdfToConvert.ToHtmlString();
// Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.Dim pdfToConvert As PdfDocument = PdfDocument.FromFile("your_document.pdf")
Dim htmlOutput As String = pdfToConvert.ToHtmlString()
' Then use an HTML parsing library (e.g., HtmlAgilityPack) to extract tables from htmlOutput.- Rozpoznawanie Wzorów i Wyrażenia Regularne: Dla tabel z bardzo przewidywalnymi wzorcami, ale niespójnymi delimitatorami, złożone wyrażenia regularne zastosowane do wyodrębnionego tekstu mogą czasami wyizolować dane tabelaryczne.
Wybór właściwej strategii zależy od złożoności i spójności źródłowych PDF. Dla wielu powszechnych dokumentów biznesowych z tabelami opartymi na tekście, IronPDF ExtractAllText w połączeniu z inteligentną logiką parsowania C# może być bardzo skuteczne. Dla tabel opartych na obrazach, jego możliwości OCR są niezbędne.
Podsumowanie
W tym artykule pokazano, jak wyodrębnić dane tabeli z dokumentu PDF w C# za pomocą IronPDF, głównie koncentrując się na wykorzystaniu metody ExtractAllText() i kolejnego parsowania ciągu tekstowego. Widzieliśmy, że choć to podejście jest potężne dla tabel opartych na tekście, bardziej złożone scenariusze jak tabele obrazowe, można rozwiązać używając funkcji OCR IronPDF lub poprzez konwersję PDF do innych formatów.
IronPDF oferuje wszechstronny zestaw narzędzi dla programistów .NET, upraszczając wiele zadań związanych z PDF, od tworzenia i edytowania po kompleksowe wyodrębnianie danych. Oferuje metodologie jak ExtractTextFromPage do ekstrakcji specyficznej dla strony i wspiera konwersje z formatów jak markdown lub DOCX do PDF.
IronPDF jest darmowe dla rozwoju i oferuje bezpłatną licencję probną do testowania jego pełnych funkcji komercyjnych. Dla produkcyjnego wdrożenia dostępne są różne opcje licencjonowania.
Dla dalszych szczegółów i zaawansowanych przypadków użycia, zobacz oficjalną dokumentację IronPDF oraz przykłady (https://ironpdf.com/)
Często Zadawane Pytania
Jak moge programowo odczytywac tabele z plikow PDF w C#?
Możesz użyć metody `ExtractAllText` IronPDF, aby wyodrębnić surowy tekst z dokumentów PDF. Po wyodrębnieniu możesz parsować ten tekst w C#, aby zidentyfikować wiersze i komórki tabeli, co pozwala na wyodrębnianie ustrukturyzowanych danych.
Jakie kroki są związane z wyodrębnianiem danych tabeli z PDF za pomocą C#?
Proces obejmuje instalację biblioteki IronPDF, użycie metody `ExtractAllText` w celu pobrania tekstu, parsowanie tego tekstu w celu identyfikacji tabel i opcjonalne zapisanie ustrukturyzowanych danych w formacie CSV.
Jak moge obsluzyc zeskanowane PDFy z tabelami w C#?
Dla zeskanowanych PDFow, IronPDF potrafi wykorzystac OCR (Optical Character Recognition), aby przekształcić obrazy tabel w tekst, który można następnie parsować w celu wyodrębnienia danych tabelarycznych.
Czy IronPDF potrafi konwertowac PDFy do innych formatow, aby ulatwic wyodrebnianie tabel?
Tak, IronPDF potrafi konwerować PDFy do HTML, co moze uprościć wyodrębnianie tabel poprzez umożliwienie programistom użycia technik parsowania HTML.
Czy IronPDF jest odpowiedni do wyodrębniania danych ze złożonych tabel PDF?
IronPDF oferuje zaawansowane możliwości, takie jak OCR i wyodrębnianie tekstu oparte na współrzędnych, które można wykorzystać do obsługi skomplikowanych układów tabel, w tym z komórkami scalonymi lub niespójnymi ogranicznikami.
Jak zintegrować IronPDF z aplikacją .NET Core?
IronPDF jest kompatybilny z aplikacjami .NET Core. Możesz go zintegrować, instalując bibliotekę za pomocą Menedżera Pakietów NuGet w Visual Studio.
Jakie są zalety korzystania z IronPDF do obróbki plików PDF w języku C#?
IronPDF oferuje wszechstronny zakres funkcji do tworzenia, edytowania i wyodrębniania danych z PDFów, w tym wsparcie dla OCR i konwersji do różnych formatów, co czyni go potężnym narzędziem dla programistów .NET.
Jakie są powszechne wyzwania związane z wyodrębnianiem danych tabeli z PDFow?
Wyzwania obejmują radzenie sobie z złożonymi układami tabel, takimi jak scalone komórki, tabele osadzone jako obrazy i niespójne ograniczniki, co może wymagać zaawansowanych strategii parsowania lub OCR.
Jak zaczac korzystac z IronPDF do przetwarzania PDFow?
Rozpocznij od zainstalowania biblioteki IronPDF za pomocą Menedżera Pakietów NuGet lub pobrania jej z witryny IronPDF. Ta konfiguracja jest niezbędna do wykorzystania jego możliwości przetwarzania PDF-ów w projektach C#.
Czy używanie IronPDF wymaga licencji?
IronPDF jest bezpłatny do celów rozwojowych, ale wymaga licencji do komercyjnego wdrożenia, aby usunąć znaki wodne. Jest dostępna bezpłatna licencja próbna do testowania pełnych funkcji.
Czy IronPDF jest kompatybilny z .NET 10 podczas wyodrębniania tabel z PDFow?
Tak. IronPDF wspiera .NET 10 (oraz .NET 9, 8, 7, 6, Core, Standard i Framework), więc wszystkie funkcje wyodrębniania tabel działają bez modyfikacji w aplikacjach .NET 10.














