
Jak analizować dane z dokumentów PDF
Możliwość wydajnego programowego wyodrębniania i wykorzystywania danych z plików PDF stanowi wyjątkowe wyzwanie dla przyszłych programistów ze względu na złożoność wewnętrznego formatu plików PDF.
IronPDF to jedna z wielu dostępnych bibliotek programistycznych .NET, która ma wyjątkową pozycję, pomagając programistom pokonywać wyzwania związane z niezawodnym wyodrębnianiem treści (tekstu i obrazów) z plików PDF, a także z wieloma innymi zadaniami związanymi z plikami PDF. IronPDF uwalnia Cię od konieczności zgłębiania tajników wewnętrznej struktury plików PDF i pozwala skupić czas oraz wysiłek na szybkiej i terminowej realizacji projektu.
W tym artykule zagłębiamy się w zawiłości analizowania dokumentów PDF, związane z tym narzędzia i techniki oraz transformacyjny wpływ, jaki biblioteka IronPDF .NET może wywrzeć, pomagając Ci opanować zawartość Twoich plików PDF.
Kluczowe pojęcia
- Analiza plików PDF: Wyodrębnianie danych strukturalnych z dokumentów PDF stanowi podstawę analizy plików PDF. Obejmuje to rozpoznawanie wzorców dokumentów i definiowanie reguł w celu pobierania określonych punktów danych. Wyodrębnione informacje są często przechowywane w bazach danych lub wykorzystywane w innych aplikacjach.
- Narzędzia do analizy plików PDF: Narzędzia te, takie jak IronPDF, Tabula, PyPDF2 i PDFMiner, automatyzują proces wyodrębniania danych. Wykorzystują one algorytmy do interpretacji struktury plików PDF i dokładnego wyodrębniania informacji.
- Proces pozyskiwania danych: Pozyskiwanie danych z plików PDF zazwyczaj polega na zaimportowaniu plików do narzędzia do parsowania, przeanalizowaniu struktury dokumentu oraz przekształceniu przeanalizowanych danych do formatów takich jak HTML, CSV, XML lub bezpośrednio do aplikacji takich jak Excel czy WORD.
- Dane ustrukturyzowane a dane nieustrukturyzowane: Pliki PDF często zawierają zarówno dane ustrukturyzowane (np. tabele), jak i dane nieustrukturyzowane. Narzędzia do parsowania muszą obsługiwać oba typy, aby zapewnić sensowne wyodrębnianie danych.
Jak analizować dane z dokumentów PDF: przewodnik krok po kroku
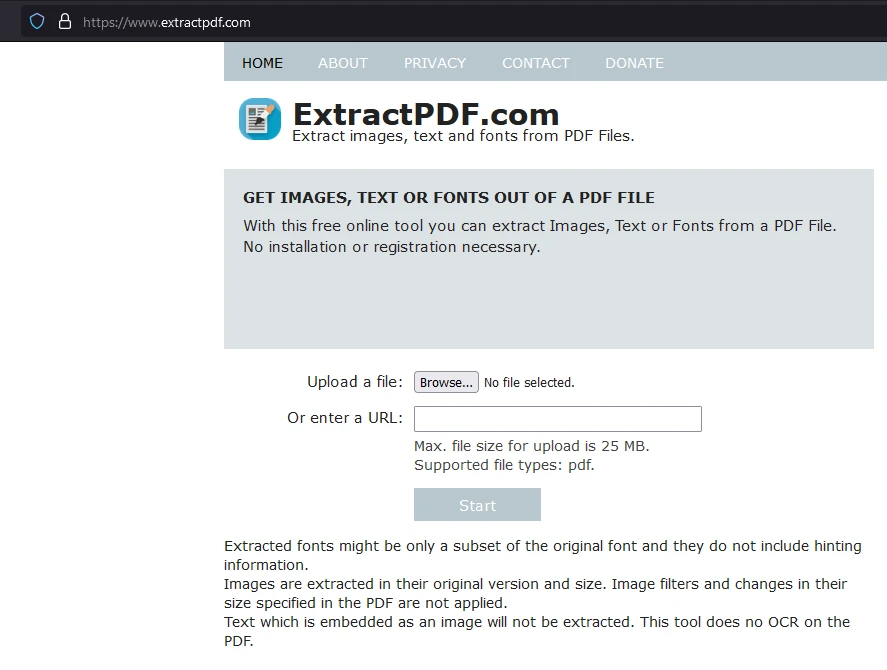
Krok 1: Otwórz darmowy internetowy ekstraktor PDF, aby przeanalizować pliki PDF
Jednym z łatwych w użyciu narzędzi jest darmowy internetowy ekstraktor PDF. Przejdź do strony internetowej, gdzie znajdziesz przegląd narzędzia, w tym informacje o tym, jak importuje ono pliki PDF i jakie dane może wyodrębnić.
Krok 2: Prześlij plik PDF
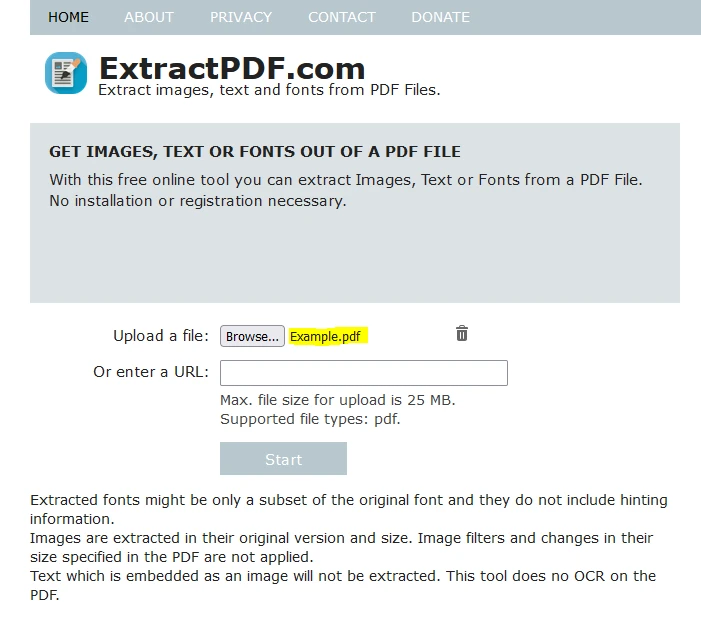
Kliknij "Przeglądaj", aby wybrać plik PDF, z którego chcesz wyodrębnić dane.
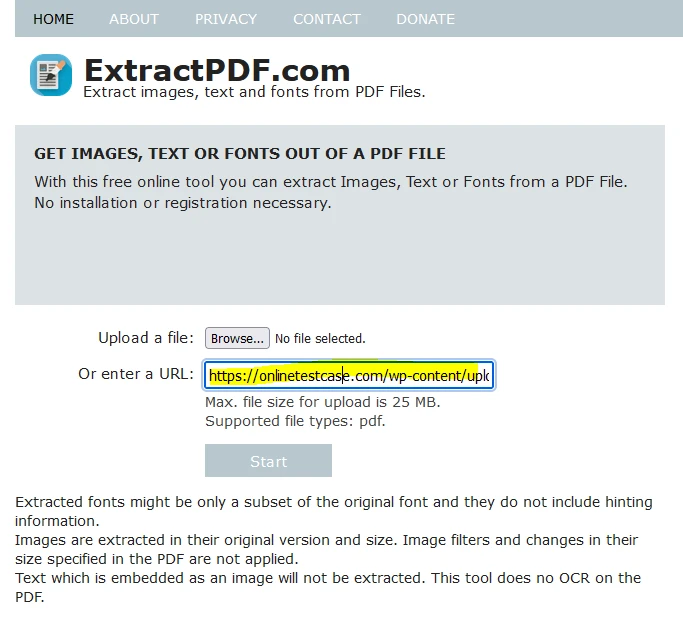
Alternatywnie możesz przesłać plik, wklejając link do pliku PDF.
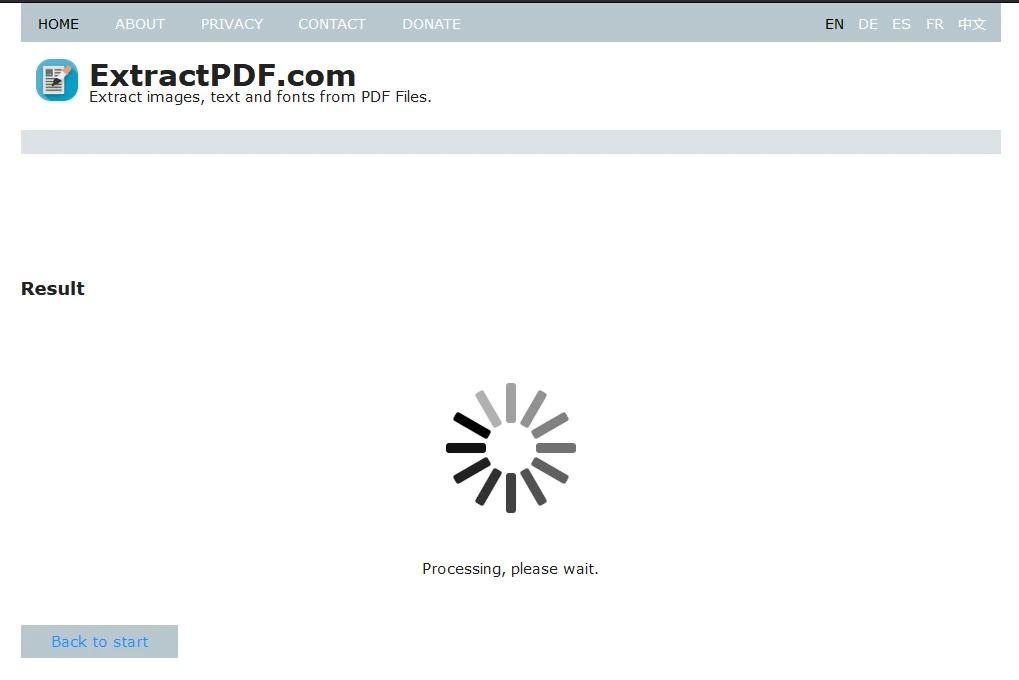
Krok 3: Rozpocznij ekstrakcję
Po przesłaniu pliku kliknij "Start", aby rozpocząć proces ekstrakcji danych. Podczas przetwarzania narzędzie wyświetli ekran ładowania.
Krok 4: Pobierz wyodrębnione dane
Po zakończeniu ekstrakcji można pobrać dane. Narzędzie udostępnia tekst, obrazy, czcionki i metadane wyodrębnione z pliku PDF w formacie tabelarycznym.
Tekst, który można skopiować do baz danych, znajduje się w zakładce "Tekst".
Metadane, w tym tytuł dokumentu, autor, data utworzenia i inne informacje, są dostępne w zakładce "Metadane".
Na koniec można pobrać wszystkie wyodrębnione dane w postaci pliku ZIP.
Zalety parsowania plików PDF
- Automatyzacja procesów biznesowych: Analiza plików PDF automatyzuje proces pozyskiwania danych, ograniczając nakład pracy ręcznej i usprawniając działalność biznesową. Ta automatyzacja umożliwia szybsze podejmowanie decyzji i większą skalowalność.
- Ograniczenie błędów: Ręczne wprowadzanie danych jest podatne na pomyłki. Narzędzia do analizy plików PDF ograniczają liczbę błędów ludzkich, zapewniając dokładniejsze przetwarzanie danych i zmniejszając ryzyko kosztownych pomyłek.
- Oszczędność czasu i kosztów: Automatyzacja ekstrakcji danych z plików PDF pozwala zaoszczędzić znaczną ilość czasu i zasobów, które organizacje mogą przeznaczyć na zadania o charakterze bardziej strategicznym.
- Wszechstronność w wykorzystaniu danych: Wyodrębnione dane można konwertować na różne formaty, co ułatwia integrację z narzędziami takimi jak Excel, WORD czy Arkusze Google.
Analiza danych PDF przy użyciu IronPDF
IronPDF to potężna biblioteka firmy Iron Software, którą programiści mogą wykorzystać do programowego wyodrębniania danych z plików PDF. Obsługuje wydajne wyodrębnianie tekstu, tabel, obrazów oraz metadanych z plików PDF.
Instalacja IronPDF
IronPDF można zainstalować za pośrednictwem menedżera pakietów IronPDF w NuGet w programie Visual Studio.
Instalacja za pomocą menedżera pakietów NuGet
W programie Visual Studio wyszukaj "IronPDF" w menedżerze pakietów NuGet i kliknij "Zainstaluj".

Zainstaluj za pomocą konsoli menedżera pakietów
Alternatywnie, użyj tego polecenia w konsoli menedżera pakietów:
Install-Package IronPdf
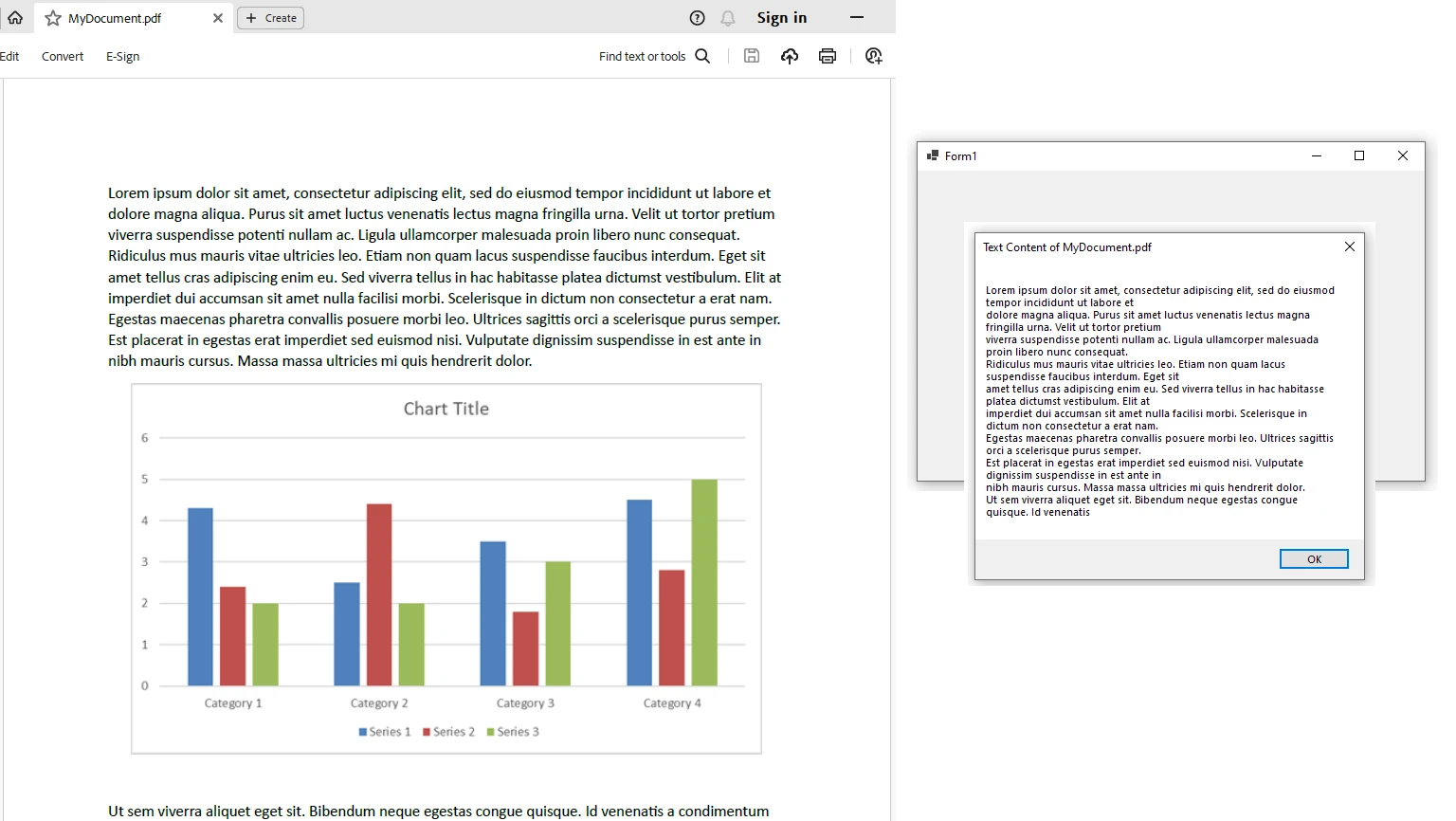
Przykład kodu: Analiza pliku PDF przy użyciu IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End NamespaceW tym przykładzie tworzymy aplikację Windows Forms, która wykorzystuje IronPDF do wyodrębniania tekstu z wybranego pliku PDF. Wyodrębniony tekst jest następnie wyświetlany w oknie komunikatu.
Licencjonowanie IronPDF
IronPDF wymaga klucza licencyjnego od IronPDF, który można uzyskać w ramach bezpłatnej licencji próbnej. Dodaj klucz licencyjny do pliku appsettings.json:
{
"IronPdf.LicenseKey": "your license key here"
}Poproś o bezpłatną licencję probną na stronie licencji produktów IronPDF.
Wnioski
Wydajne parsowanie plików PDF pozwala w pełni wykorzystać potencjał dokumentów cyfrowych, umożliwiając firmom automatyzację procesów, ograniczenie błędów oraz oszczędność czasu i pieniędzy. Dzięki opanowaniu technik i narzędzi do analizy plików PDF organizacje mogą zwiększyć produktywność i osiągnąć więcej dzięki swoim zasobom cyfrowym. IronPDF oferuje idealne rozwiązanie dla programistów, którzy chcą pracować z dokumentami PDF programowo.
Często Zadawane Pytania
Jak wyodrębnić tekst z dokumentów PDF przy użyciu języka C#?
Można użyć klasy PdfDocument biblioteki IronPDF do załadowania pliku PDF oraz metody ExtractAllText() do wyodrębnienia tekstu. Umożliwia to łatwe pobieranie danych tekstowych z plików PDF.
Jakie metody są dostępne w IronPDF do wyodrębniania obrazów z plików PDF?
IronPDF udostępnia metody, takie jak ExtractImages(), które można wykorzystać do wyodrębniania obrazów osadzonych w plikach PDF i konwertowania ich do formatów takich jak JPEG lub PNG.
Jak mogę przekonwertować dane z pliku PDF do formatu CSV przy użyciu biblioteki .NET?
IronPDF umożliwia analizowanie i wyodrębnianie danych z plików PDF, które następnie można programowo przekonwertować do formatu CSV przy użyciu standardowych technik manipulacji danymi w środowisku .NET Standard.
Jakie są typowe wyzwania związane z analizowaniem dokumentów PDF?
Analiza plików PDF może stanowić wyzwanie ze względu na ich złożoną strukturę, która obejmuje różnorodne elementy, takie jak tekst, obrazy i metadane. Narzędzia takie jak IronPDF pomagają sprostać tym wyzwaniom, zapewniając proste metody wyodrębniania i manipulowania zawartością plików PDF.
Czy IronPDF może służyć do analizy struktury pliku PDF przed wyodrębnieniem danych?
Tak, IronPDF udostępnia narzędzia do analizy struktury plików PDF, umożliwiające programistom identyfikację wzorców i określenie najbardziej efektywnych sposobów pozyskiwania potrzebnych danych.
Jakie są wymagania licencyjne dotyczące korzystania z IronPDF?
IronPDF wymaga ważnej licencji do wdrożenia w środowiskach produkcyjnych. Dostępna jest jednak bezpłatna wersja próbna do celów ewaluacyjnych, umożliwiająca użytkownikom przetestowanie funkcji przed podjęciem decyzji o zakupie.
Jakie korzyści dla firm płyną z automatyzacji ekstrakcji danych z plików PDF?
Automatyzacja ekstrakcji danych z plików PDF za pomocą narzędzi takich jak IronPDF może znacznie ograniczyć ręczne wprowadzanie danych, zminimalizować liczbę błędów, zaoszczędzić czas i obniżyć koszty operacyjne, poprawiając w ten sposób ogólną wydajność firmy.
Jakie języki programowania są obsługiwane przez IronPDF do ekstrakcji danych z plików PDF?
IronPDF jest przeznaczony do użytku z językami .NET, głównie C#, umożliwiając płynną integrację z innymi aplikacjami i usługami .NET w celu wydajnego pozyskiwania danych z plików PDF.
Czy IronPDF jest w pełni kompatybilny z .NET 10 podczas analizowania danych PDF?
Tak — IronPDF w pełni obsługuje .NET 10, co oznacza, że można korzystać z jego funkcji parsowania, takich jak wyodrębnianie tekstu i obrazów, odczytywanie metadanych, parsowanie tabel oraz konwersja HTML do PDF w projektach .NET 10 bez konieczności stosowania obejść lub problemów z kompatybilnością.














