
Comment analyser les données à partir de documents PDF
La capacité à extraire et utiliser efficacement des données de fichiers PDF de manière programmatique présente des défis uniques pour les développeurs potentiels, en raison des complexités du format interne des PDF.
IronPDF est l'une des nombreuses bibliothèques de programmation .NET disponibles qui est particulièrement positionnée pour aider les développeurs à surmonter les défis liés à l'extraction de contenu (texte et images) des PDF de manière fiable, parmi de nombreuses autres tâches liées aux PDF. IronPDF vous libère de l'obligation de comprendre les subtilités de la structure interne des PDF et vous permet de concentrer votre temps et vos efforts sur la livraison de votre projet rapidement et dans les délais.
Cet article plonge dans les subtilités de l'analyse de documents PDF, les outils et techniques impliqués, et l'impact transformateur que la bibliothèque IronPDF for .NET peut avoir pour vous aider à maîtriser le contenu de votre PDF.
Concepts Clés
- Analyse PDF : L'extraction de données structurées des documents PDF est au cœur de l'analyse PDF. Cela implique de reconnaître les motifs de documents et de définir des règles pour récupérer des points de données spécifiques. Les informations extraites sont souvent stockées dans des bases de données ou utilisées dans d'autres applications.
- Outils d'Analyse PDF : Ces outils, comme IronPDF, Tabula, PyPDF2 et PDFMiner, automatisent le processus d'extraction. Ils utilisent des algorithmes pour interpréter la structure des PDF et extraire des informations avec précision.
- Processus d'Extraction de Données : Extraire des données de PDF implique souvent d'importer des fichiers dans un outil d'analyse, d'analyser la structure du document, et de convertir les données analysées en formats tels que HTML, CSV, XML, ou directement dans des applications comme Excel ou Word.
- Données Structurées vs Non Structurées : Les PDF contiennent souvent à la fois des données structurées (par exemple, des tableaux) et non structurées. Les outils d'analyse doivent gérer les deux types pour assurer une extraction de données significative.
Comment Analyser des Données à partir de Documents PDF : Guide Étape par Étape
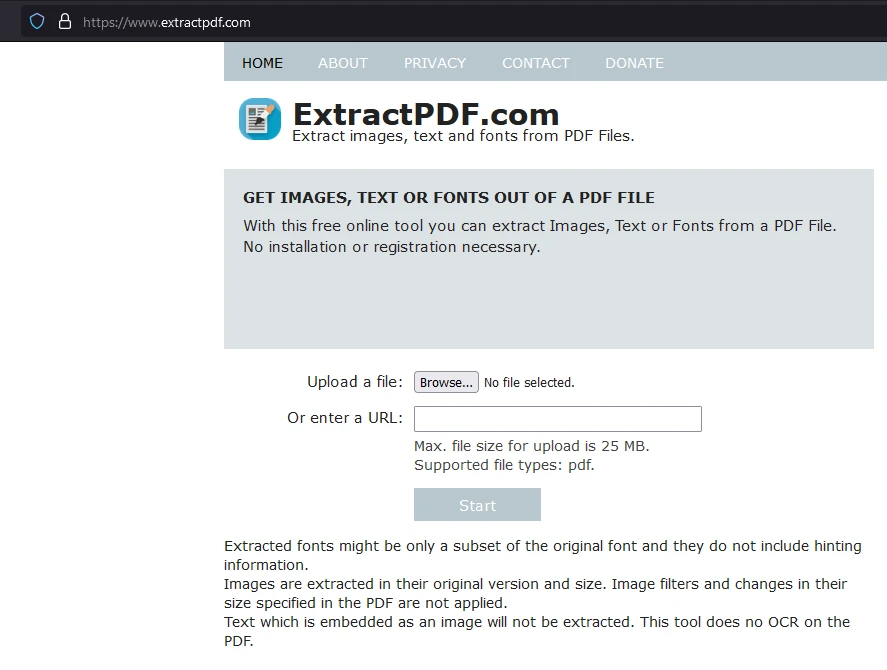
Étape 1 : Ouvrir un Extracteur PDF en Ligne Gratuit pour Analyser des Fichiers PDF
Un outil facile à utiliser est l'Extracteur PDF en Ligne Gratuit. Accédez au site web, où vous pouvez voir un aperçu de l'outil, y compris comment il importe les PDF et quelles données il peut extraire.
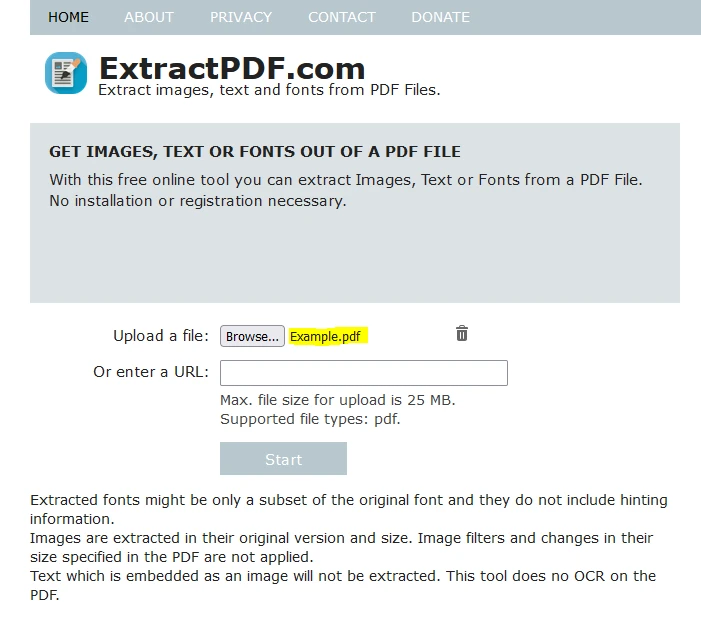
Étape 2 : Téléchargez le Fichier PDF
Cliquez sur "Parcourir" pour sélectionner le fichier PDF à partir duquel vous souhaitez extraire des données.
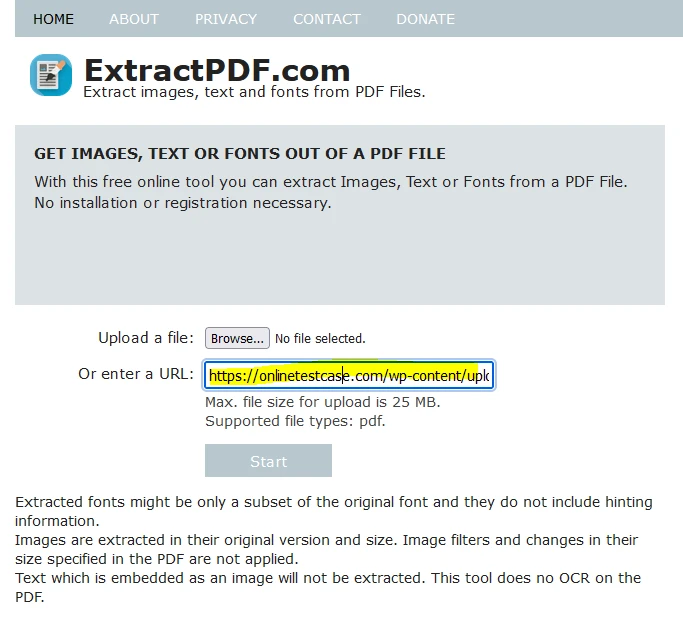
Vous pouvez également télécharger le fichier en collant un lien vers le PDF.
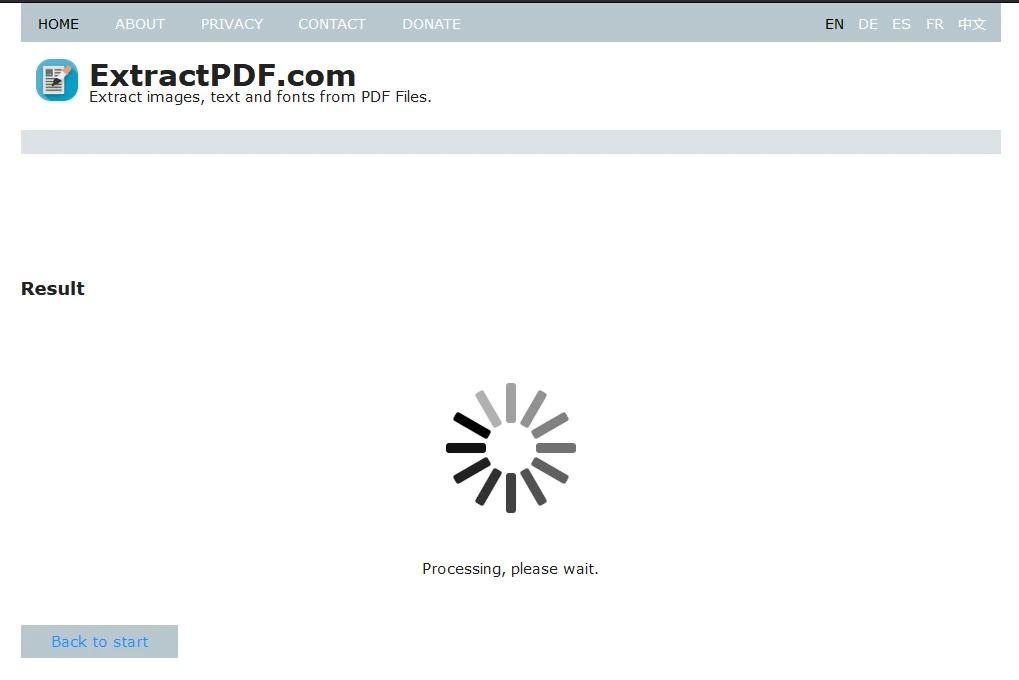
Étape 3 : Commencer l'Extraction
Après avoir téléchargé le fichier, cliquez sur "Démarrer" pour commencer le processus d'extraction de données. L'outil affichera un écran de chargement pendant le traitement.
Étape 4 : Télécharger les Données Extraites
Une fois l'extraction terminée, vous pouvez télécharger les données. L'outil fournit le texte, les images, les polices et les métadonnées extraites du PDF dans un format tabulaire.
Le texte qui peut être copié dans des bases de données se trouve sous l'onglet 'Texte'.
Les métadonnées, y compris le titre du document, l'auteur, la date de création, etc., sont disponibles sous l'onglet 'Métadonnées'.
Enfin, vous pouvez télécharger toutes les données extraites sous forme de fichier ZIP.
Avantages de l'Analyse PDF
- Automatisation des Processus Métier : L'analyse PDF automatise le processus d'extraction de données, réduisant le travail manuel et améliorant les opérations commerciales. Cette automatisation permet une prise de décision plus rapide et une plus grande évolutivité.
- Réduction des Erreurs : La saisie manuelle de données est sujette aux erreurs. Les outils d'analyse PDF réduisent les erreurs humaines, garantissant une gestion plus précise des données et réduisant les erreurs coûteuses.
- Économies de Temps et de Coûts : L'automatisation de l'extraction de données PDF permet de gagner beaucoup de temps et de ressources, que les organisations peuvent rediriger vers des tâches plus stratégiques.
- Polyvalence dans l'Utilisation des Données : Les données extraites peuvent être converties en divers formats, facilitant leur intégration avec des outils comme Excel, Word, ou Google Sheets.
Analyse des Données PDF à l'aide d'IronPDF
IronPDF est une bibliothèque puissante de Iron Software que les développeurs peuvent utiliser pour extraire des données de PDF de manière programmatique. Elle prend en charge l'extraction de texte, de tableaux, d'images, et de métadonnées PDF avec une grande efficacité.
Installer IronPDF
Vous pouvez installer IronPDF via le gestionnaire de packages IronPDF sur NuGet dans Visual Studio.
Installer en Utilisant le Gestionnaire de Packages NuGet
Dans Visual Studio, recherchez "IronPDF" dans le Gestionnaire de Packages NuGet et cliquez sur installer.

Installer en Utilisant la Console du Gestionnaire de Packages
Alternativement, utilisez cette commande dans la Console du Gestionnaire de Packages :
Install-Package IronPdf
Exemple de Code : Analyser un PDF en Utilisant IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
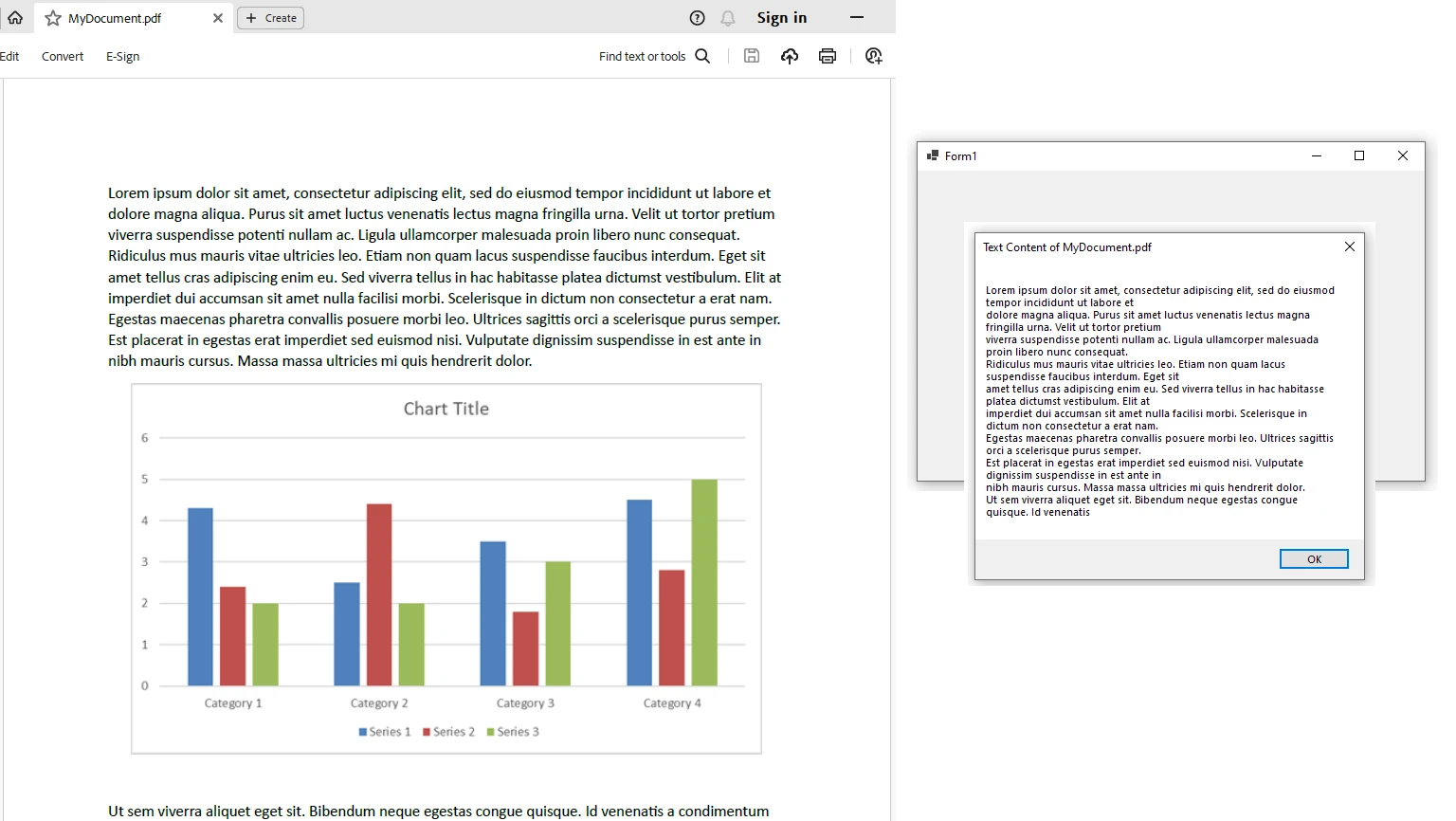
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End NamespaceDans cet exemple, nous créons une application Windows Forms qui utilise IronPDF pour extraire du texte d'un fichier PDF sélectionné. Le texte extrait est ensuite affiché dans une boîte de message.
Licence d'IronPDF
IronPDF nécessite une clé de licence d'IronPDF que vous pouvez obtenir dans le cadre d'une licence d'essai gratuite. Ajoutez la clé de licence à votre fichier appsettings.json :
{
"IronPdf.LicenseKey": "your license key here"
}Demandez une licence d'essai gratuite sur la page de licence de produit d'IronPDF.
Conclusion
Une analyse PDF efficace libère tout le potentiel des documents numériques, permettant aux entreprises d'automatiser leurs processus, de réduire les erreurs, et d'économiser du temps et de l'argent. En maîtrisant les techniques et outils d'analyse PDF, les organisations peuvent améliorer leur productivité et en faire plus avec leurs actifs numériques. IronPDF offre une solution idéale pour les développeurs souhaitant travailler avec des documents PDF de manière programmatique.
Questions Fréquemment Posées
Comment puis-je extraire du texte à partir de documents PDF en utilisant C# ?
Vous pouvez utiliser la classe PdfDocument d'IronPDF pour charger un fichier PDF et la méthode ExtractAllText() pour extraire le texte. Cela permet de récupérer facilement les données textuelles des PDF.
Quelles méthodes sont disponibles dans IronPDF pour extraire des images d'un PDF ?
IronPDF fournit des méthodes telles que ExtractImages() qui peuvent être utilisées pour extraire des images intégrées des fichiers PDF, les convertissant en formats comme JPEG ou PNG.
Comment puis-je convertir des données PDF en format CSV en utilisant une bibliothèque .NET ?
IronPDF vous permet d'analyser et d'extraire des données des PDF, qui peuvent ensuite être converties en format CSV de manière programmatique en utilisant des techniques de manipulation de données standard .NET.
Quels sont les défis courants de l'analyse des documents PDF ?
L'analyse des PDF peut être difficile en raison de leur structure complexe, qui comprend des éléments divers tels que le texte, les images et les métadonnées. Des outils comme IronPDF aident à surmonter ces défis en fournissant des méthodes simples pour extraire et manipuler le contenu des PDF.
IronPDF peut-il être utilisé pour analyser la structure d'un PDF avant l'extraction ?
Oui, IronPDF fournit des outils pour analyser la structure d'un PDF, permettant aux développeurs d'identifier des motifs et de déterminer les moyens les plus efficaces pour extraire les données nécessaires.
Quelles sont les exigences de licence pour utiliser IronPDF ?
IronPDF nécessite une licence valide pour le déploiement dans des environnements de production. Cependant, un essai gratuit est disponible à des fins d'évaluation, permettant aux utilisateurs de tester les fonctionnalités avant de s'engager dans un achat.
Comment l'automatisation de l'extraction de données PDF profite-t-elle aux entreprises ?
L'automatisation de l'extraction de données PDF avec des outils comme IronPDF peut réduire considérablement la saisie manuelle des données, minimiser les erreurs, gagner du temps et réduire les coûts opérationnels, améliorant ainsi l'efficacité globale de l'entreprise.
Quels langages de programmation sont pris en charge par IronPDF pour l'extraction de données PDF ?
IronPDF est conçu pour être utilisé avec les langages .NET, principalement C#, permettant une intégration transparente avec d'autres applications et services .NET pour une extraction efficace des données PDF.
IronPDF est-il entièrement compatible avec .NET 10 lors de l'analyse des données PDF ?
Oui, IronPDF prend entièrement en charge .NET 10, ce qui signifie que vous pouvez utiliser ses fonctionnalités d'analyse telles que l'extraction de texte et d'images, la lecture des métadonnées, l'analyse de tableaux et la conversion HTML vers PDF dans les projets .NET 10 sans solutions de contournement ni problèmes de compatibilité.













