
IronPDF Satın Almalısınız mı?
PDF'lerden programatik olarak veri çıkartmak ve kullanmak yeteneği, PDF'lerin iç formatının karmaşıklıkları nedeniyle, potansiyel bir geliştirici için benzersiz zorluklar sunar.
IronPDF, .NET programlama kütüphaneleri arasında, geliştiricilerin PDF'lerden içerik (metin ve resimler) çıkarmak gibi birçok PDF ile ilgili görevi güvenilir bir şekilde gerçekleştirme zorluklarının üstesinden gelmelerine özel olarak yardımcı olan bir kütüphanedir. IronPDF, PDF'lerin iç yapısını anlamak zorunda kalmadan, projenizi hızlı ve zamanında teslim etmeye odaklanmanız için size zaman ve çaba kazandırır.
Bu makale, PDF belge çözümlemenin inceliklerine, ilgili araç ve tekniklere ve IronPDF .NET kütüphanesinin PDF içeriğinizi yönetmenize yardımcı olma konusundaki dönüştürücü etkisine derinlemesine giriyor.
Anahtar Kavramlar
- PDF Ayrıştırma: PDF belgelerinden yapılandırılmış verilerin çıkarılması, PDF ayrıştırmanın temelidir. Belge kalıplarını tanımayı ve belirli veri noktalarını almak için kurallar tanımlamayı içerir. Çıkarılan bilgiler genellikle veritabanlarında saklanır veya diğer uygulamalarda kullanılır.
- PDF Ayrıştırıcı Araçları: IronPDF, Tabula, PyPDF2 ve PDFMiner gibi bu araçlar, çıkarım sürecini otomatik hale getirir. PDF yapısını yorumlamak ve bilgileri doğru bir şekilde çıkarmak için algoritmaları kullanırlar.
- Veri Çıkarma Süreci: PDF'lerden veri çıkarma genellikle dosyaların bir ayrıştırma aracına aktarılmasını, belgenin yapısının analiz edilmesini ve ayrıştırılan verilerin HTML, CSV, XML gibi formatlara veya doğrudan Excel ya da Word gibi uygulamalara dönüştürülmesini içerir.
- Yapılandırılmış ve Yapılandırılmamış Veri: PDF'ler genellikle hem yapılandırılmış (örn., tablolar) hem de yapılandırılmamış veri içerir. Ayrıştırma araçları, anlamlı veri çıkarımını sağlamak için her iki türü de işlemelidir.
PDF Belgelerinden Veri Nasıl Ayrıştırılır: Adım Adım Kılavuz
Adım 1: PDF Dosyalarını Ayrıştırmak için Ücretsiz Çevrimiçi PDF Ayrıştırıcıyı Açın
Kullanımı kolay bir araç, Ücretsiz Online PDF Çıkarıcısı'dır. Web sitesine gidin, aracın genel bir görünümünü görebileceğiniz, PDF'leri nasıl içe aktardığını ve hangi verileri çıkarabileceğini içeren bir bölüm bulunmaktadır.
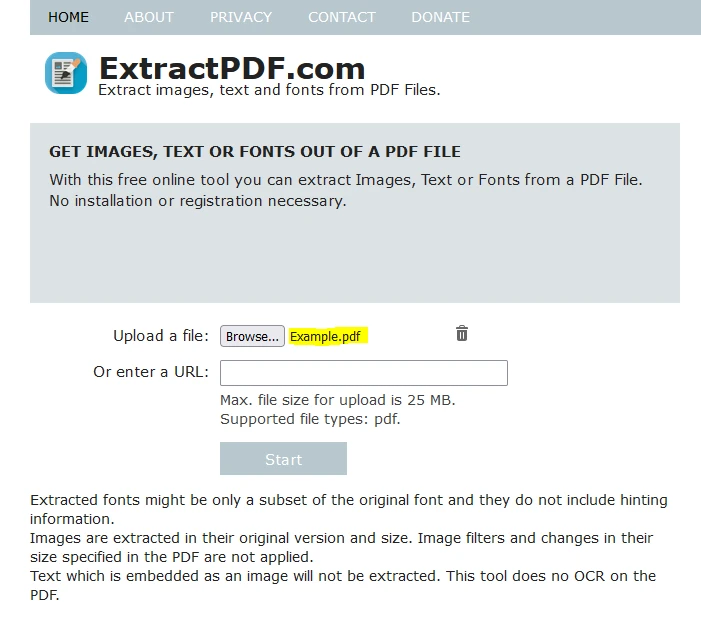
Adım 2: PDF Dosyasını Yükleyin
Verileri çıkarmak istediğiniz PDF dosyasını seçmek için "Gözat" butonuna tıklayın.
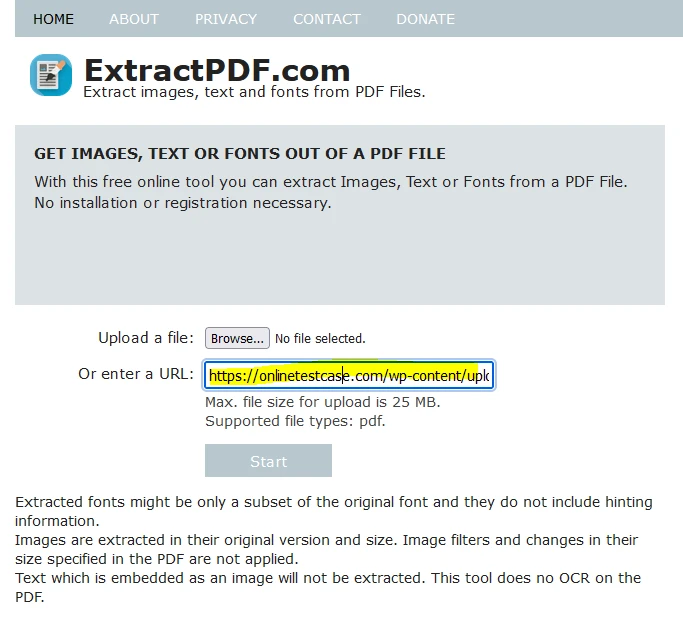
Alternatif olarak, PDF'ye bir bağlantı yapıştırarak dosyayı yükleyebilirsiniz.
Adım 3: Ekstraksiyona Başlayın
Dosyayı yükledikten sonra, veri çıkarma sürecine başlamak için "Başlat"a tıklayın. Araç, işlem sırasında bir yükleme ekranı gösterecektir.
Adım 4: Çıkarılan Verileri İndirin
Çıkarma tamamlandıktan sonra, verileri indirebilirsiniz. Araç, PDF'den çıkarılan metin, resimler, yazı tipleri ve meta verileri tablolarda sunar.
Veritabanlarına kopyalanabilir metin, 'Metin' sekmesinde bulunur.
Belge başlığı, yazar, oluşturma tarihi ve daha fazlasını içeren meta veriler 'Meta Veriler' sekmesinde bulunur.
Son olarak, tüm çıkarılan verileri bir ZIP dosyası olarak indirebilirsiniz.
PDF Ayrıştırmanın Faydaları
- İş Süreci Otomasyonu: PDF ayrıştırması veri çıkarma işlemini otomatikleştirir, manuel çalışmayı azaltır ve iş süreçlerini geliştirir. Bu otomasyon daha hızlı karar verme sağlar ve daha fazla ölçeklenebilirlik sunar.
- Hata Azaltma: Manuel veri girişi hatalara açıktır. PDF ayrıştırma araçları, insan hatalarını azaltır, daha doğru veri işleme sağlar ve maliyetli hataları önler.
- Zaman ve Maliyetten Tasarruf: PDF veri çıkarmayı otomatikleştirmek, önemli ölçüde zaman ve kaynak tasarrufu sağlar, bu da kuruluşlar tarafından daha stratejik görevlere yönlendirilebilir.
- Veri Kullanımında Esneklik: Çıkarılan veriler farklı formatlara dönüştürülebilir, bu da onları Excel, Word veya Google Sheets gibi araçlara entegre etmeyi kolaylaştırır.
IronPDF Kullanarak PDF Verilerini Ayrıştırma
IronPDF, Iron Software tarafından geliştirilmiş güçlü bir kütüphanedir ve geliştiricilerin PDF'lerden programatik olarak veri çıkarmasına olanak tanır. Yüksek verimlilikle metin, tablolar, resimler ve PDF meta verilerini çıkarmayı destekler.
Installing IronPDF
IronPDF'yi Visual Studio'da NuGet üzerinde IronPDF paket yöneticisi aracılığıyla yükleyebilirsiniz.
NuGet Paket Yöneticisi ile Kurulum
Visual Studio'da, NuGet Paket Yöneticisi'nde "IronPDF" arayın ve yükleye tıklayın.

Paket Yöneticisi Konsolu Kullanarak Kurulum
Alternatif olarak, Paket Yöneticisi Konsolu'nda bu komutu kullanın:
Install-Package IronPdf
Kod Örneği: IronPDF Kullanarak Bir PDF'yi Ayrıştırma
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End NamespaceBu örnekte, IronPDF kullanarak seçili bir PDF dosyasından metin çıkartan bir Windows Forms uygulaması oluşturuyoruz. Çıkarılan metin ardından bir mesaj kutusunda gösterilir.
IronPDF'yi Lisanslama
IronPDF, IronPDF'den bir lisans anahtarı gerektirir, bu anahtarı ücretsiz deneme lisansı olarak edinebilirsiniz. Lisans anahtarını appsettings.json dosyanıza ekleyin:
{
"IronPdf.LicenseKey": "your license key here"
}IronPDF'nin ürün lisans sayfasından ücretsiz bir deneme lisansı isteyin.
Sonuç
Verimli PDF ayrıştırma, dijital belgelerin tam potansiyelini açığa çıkarır, işletmeleri süreçleri otomatikleştirmeye, hataları azaltmaya ve zaman ile para tasarrufuna olanak tanır. PDF ayrıştırma teknikleri ve araçlarında ustalaşarak, kuruluşlar üretkenliği artırabilir ve dijital varlıklarıyla daha fazlasını başarabilir. IronPDF, PDF belgeleriyle programlı olarak çalışmak isteyen geliştiriciler için ideal bir çözüm sunar.
Sıkça Sorulan Sorular
C# kullanarak PDF belgelerinden metni nasıl çıkarabilirim?
IronPDF'nin PdfDocument sınıfını kullanarak bir PDF dosyasını yükleyebilir ve ExtractAllText() yöntemini kullanarak metni çıkarabilirsiniz. Bu, PDF'lerden metin verilerinin kolayca alınmasına olanak tanır.
IronPDF'de PDF'den resim çıkarmak için hangi yöntemler mevcut?
IronPDF, PDF dosyalarından katıştırılmış resimleri çıkartmak ve bunları JPEG veya PNG gibi formatlara dönüştürmek için kullanılan ExtractImages() gibi yöntemler sağlar.
.NET kütüphanesi kullanarak PDF verilerini CSV formatına nasıl dönüştürebilirim?
IronPDF, PDF'lerden verileri çözmenizi ve ardından standart .NET veri manipülasyon tekniklerini kullanarak programlı olarak CSV formatına dönüştürmenizi sağlar.
PDF belgelerini ayrıştırmanın yaygın zorlukları nelerdir?
PDF'leri ayrıştırmak, metin, resimler ve metadata gibi çeşitli öğeler içeren karmaşık yapılarına bağlı olarak zorlu olabilir. IronPDF gibi araçlar, PDF içeriğini çıkarmak ve manipüle etmek için kolay yöntemler sağlayarak bu zorlukların üstesinden gelmenize yardımcı olur.
IronPDF, çıkarım öncesinde PDF yapısını analiz etmek için kullanılabilir mi?
Evet, IronPDF, PDF yapısını analiz etme araçları sağlar, geliştiricilerin çıkarılması gereken verileri en verimli şekilde çıkarmak için desenleri tanımlayıp belirlemesini sağlar.
IronPDF kullanmak için lisans gereksinimleri nelerdir?
IronPDF, üretim ortamlarında dağıtım için geçerli bir lisans gerektirir. Ancak, kullanıcıların özellikleri satın almadan önce test etmelerini sağlamak için değerlendirme amacıyla ücretsiz bir deneme mevcuttur.
IronPDF, PDF veri çıkarımını otomatikleştirmek işletmeler için nasıl faydalıdır?
IronPDF gibi araçlarla PDF veri çıkarımını otomatikleştirmek, manuel veri girişini önemli ölçüde azaltabilir, hataları minimize edebilir, zaman kazandırabilir ve operasyonel maliyetleri düşürerek iş verimliliğini artırabilir.
PDF veri çıkarımı için IronPDF tarafından desteklenen programlama dilleri nelerdir?
IronPDF, .NET dilleri ile kullanım için tasarlanmıştır, öncelikle C#, verimli PDF veri çıkarımı için diğer .NET uygulamaları ve hizmetleri ile sorunsuz entegrasyon sağlar.
IronPDF, PDF veri ayrıştırmada .NET 10 ile tamamen uyumlu mu?
Evet — IronPDF, .NET 10 için tam destek sağlamaktadır, bu da metin ve resim çıkarımı, metadata okuma, tablo ayrıştırma ve HTML'den PDF'ye dönüştürme gibi ayrıştırma özelliklerini .NET 10 projelerinde dolambaçsız veya uyumluluk sorunları olmadan kullanabileceğiniz anlamına gelir.











