
如何从PDF文档中解析数据
由于PDF内部格式的复杂性,程序化地高效提取和利用PDF数据给未来的开发者带来了独特的挑战。
IronPDF 是许多可用的.NET编程库之一,其独特之处在于能够帮助开发者克服从PDF中可靠提取内容(文本和图像)的挑战,以及处理许多其他与PDF相关的任务。 IronPDF使您无需了解PDF内部结构的细节,让您能够专注于快速按时交付项目。
本文深入探讨了PDF文档解析的复杂性、所涉及的工具和技术,以及IronPDF .NET库在帮助您掌握PDF内容方面的变革性影响。
关键概念
- PDF解析: 从PDF文档中提取结构化数据是PDF解析的核心。 它涉及识别文档模式并定义规则以检索特定数据点。 提取的信息通常存储在数据库中或用于其他应用程序。
- PDF解析工具: 这些工具,如IronPDF、Tabula、PyPDF2和PDFMiner,会自动化提取过程。 它们利用算法来解释PDF结构并精确提取信息。
- 数据提取过程: 从PDF中提取数据通常涉及将文件导入解析工具,分析文档结构,并将解析后的数据转换为HTML、CSV、XML等格式,或直接导入Excel或Word等应用程序。
- 结构化数据与非结构化数据: PDF通常包含结构化(例如表格)和非结构化数据。 解析工具必须处理这两种类型以确保有意义的数据提取。
如何从PDF文档中解析数据:循序渐进指南
步骤1:打开免费在线PDF提取器以解析PDF文件
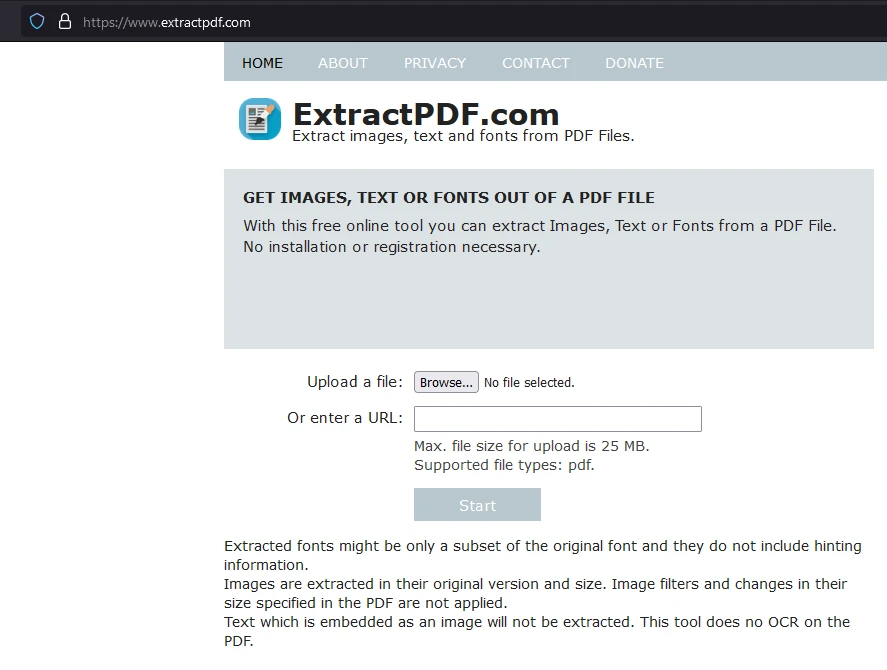
一个易于使用的工具是免费在线PDF提取器。 导航到网站,您可以看到该工具的概述,包括如何导入PDF和可提取数据。
步骤2:上传PDF文件
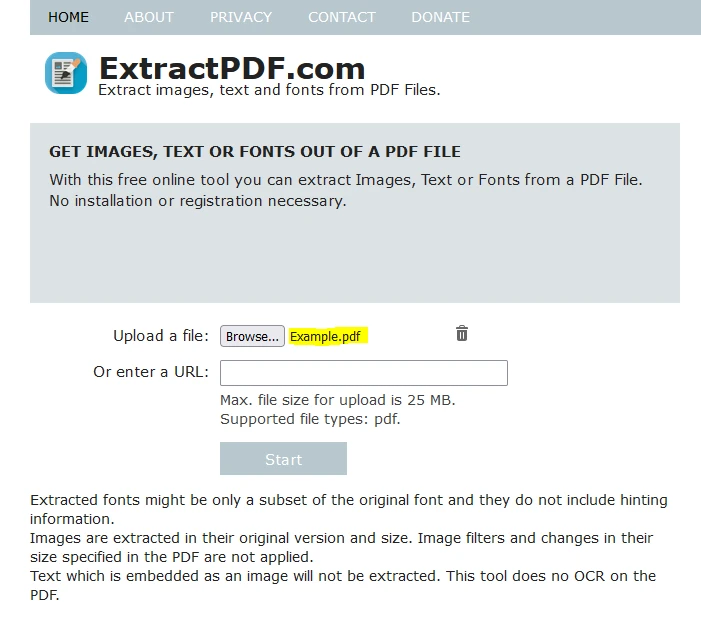
点击"浏览"以选择您希望提取数据的PDF文件。
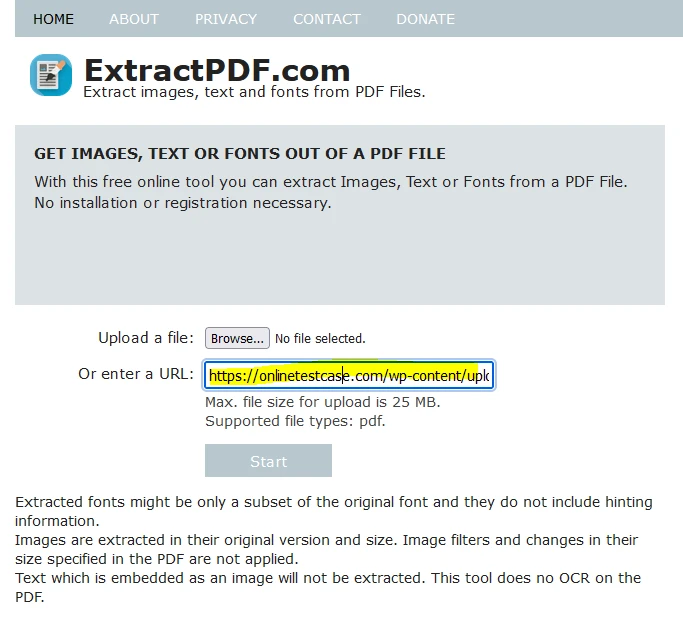
或者,您可以通过粘贴PDF链接来上传文件。
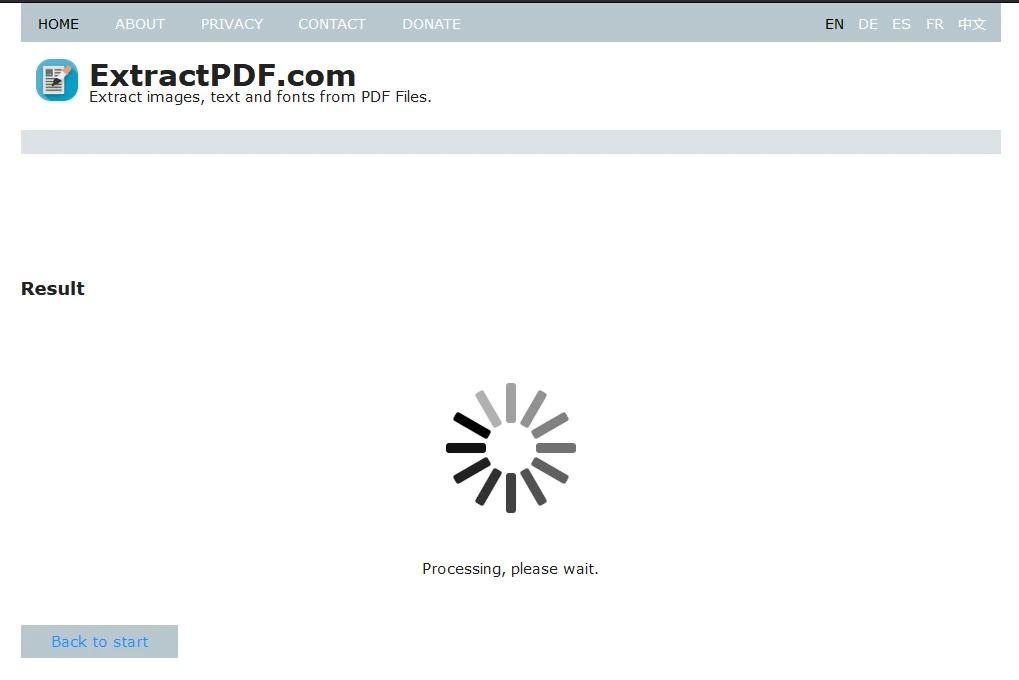
步骤3:开始提取
上传文件后,点击"开始"以开始数据提取过程。 工具将在处理过程中显示加载屏幕。
步骤4:下载提取的数据
提取完成后,您可以下载数据。 工具以表格格式提供从PDF中提取的文本、图像、字体和元数据。
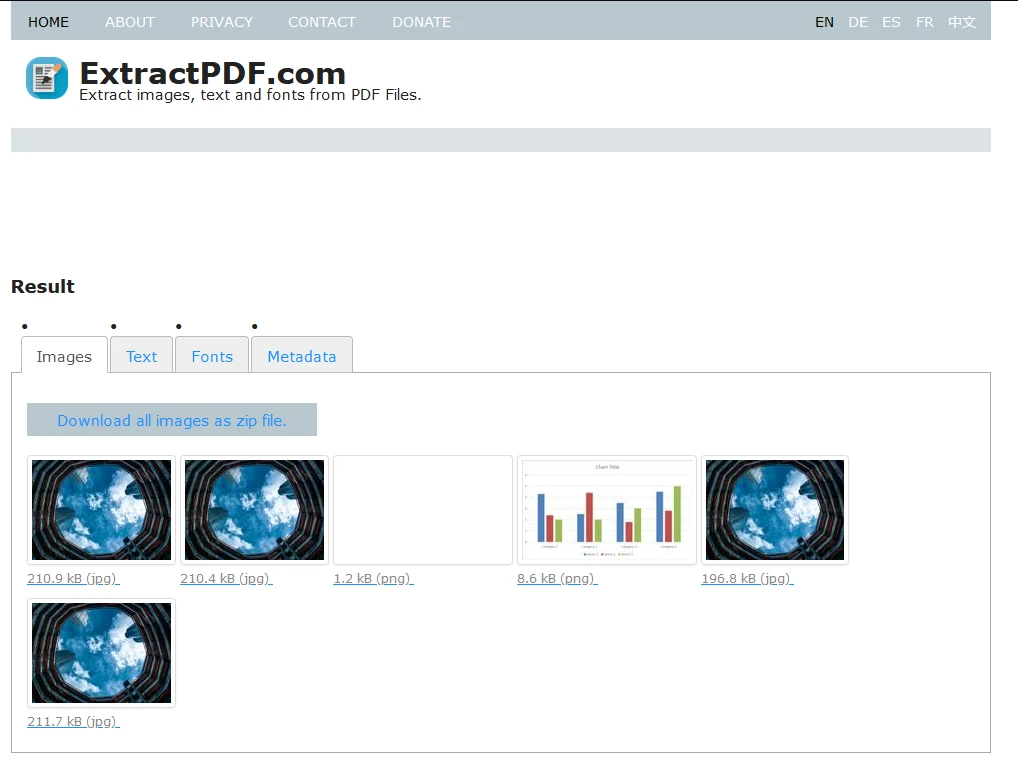
可复制到数据库的文本在"文本"选项卡下找到。
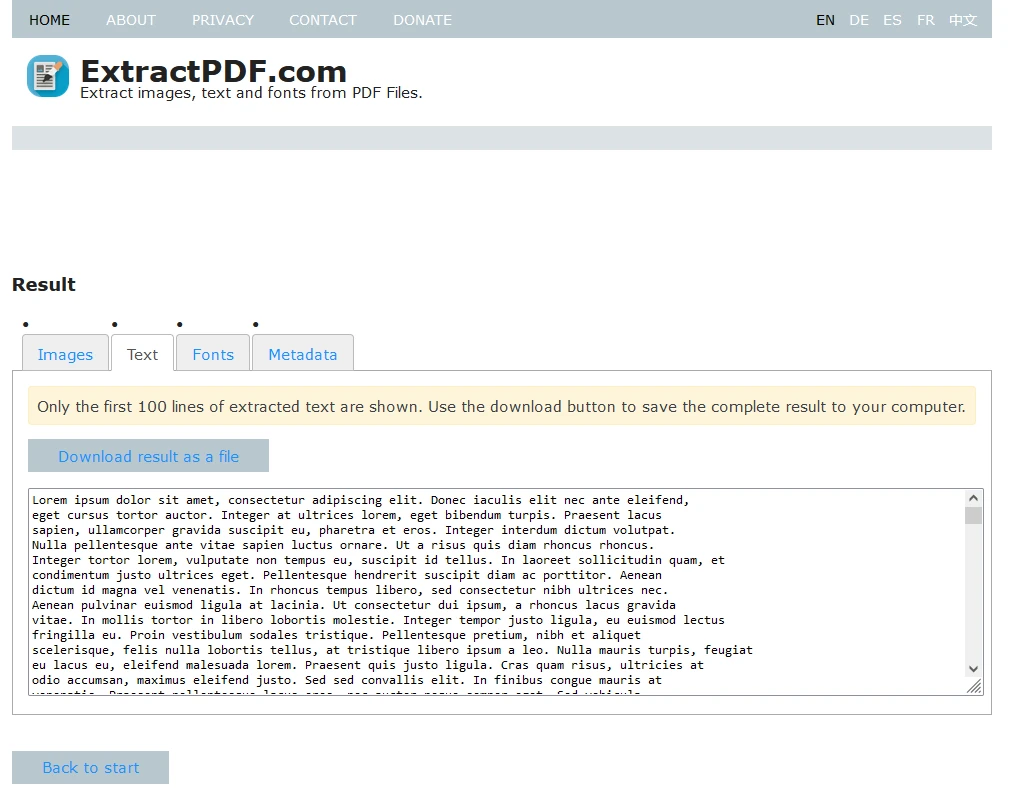
元数据,包括文档标题、作者、创建日期等,可在"元数据"选项卡下查看。
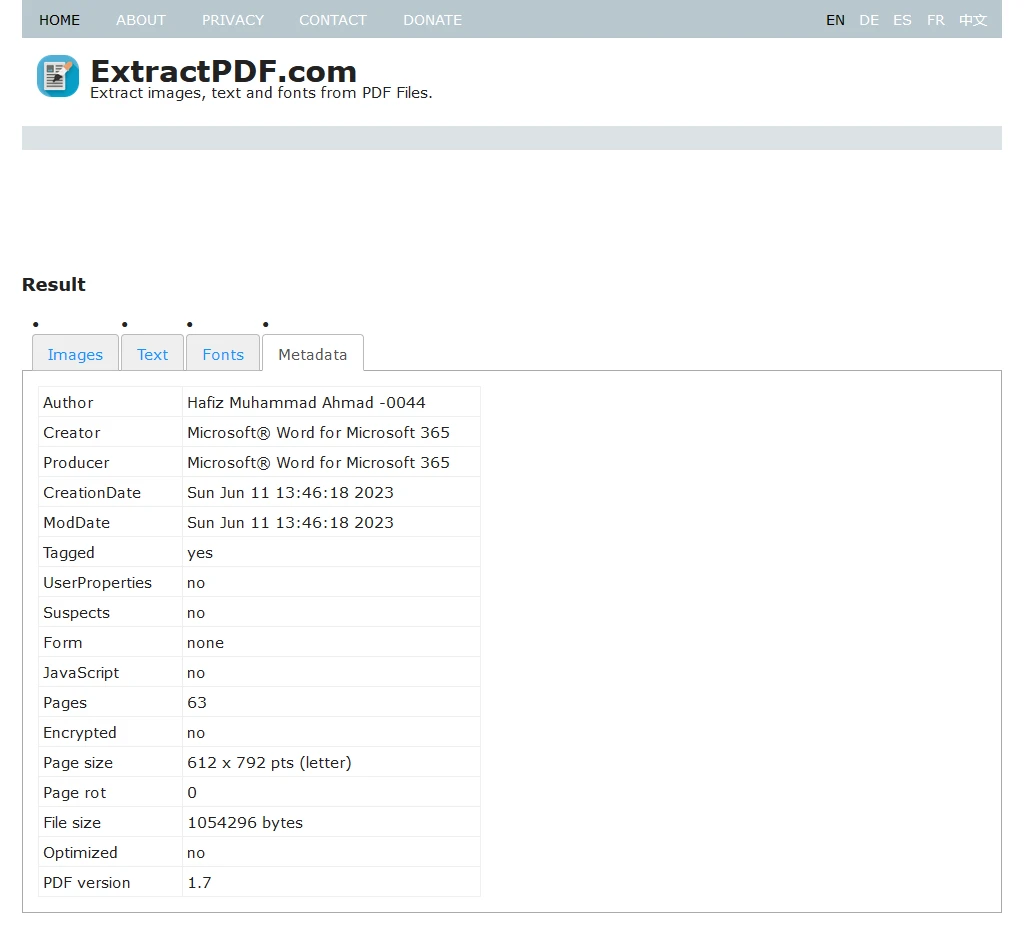
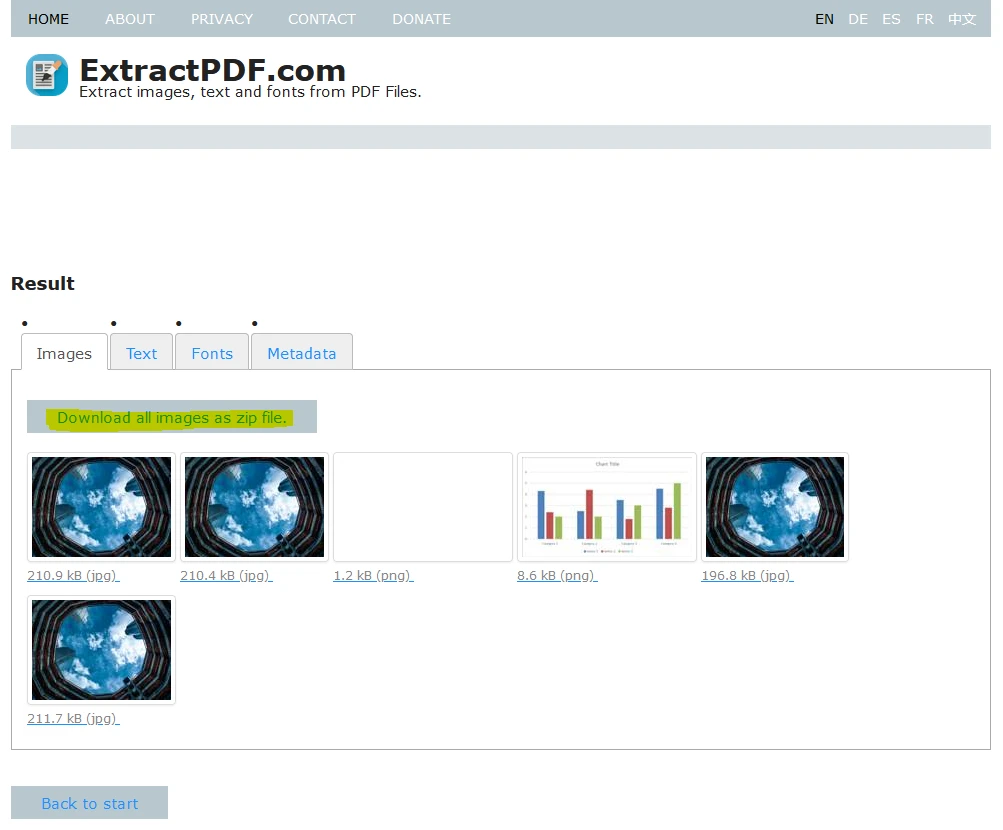
最后,您可以将所有提取的数据下载为ZIP文件。
PDF解析的好处
- 业务流程自动化: PDF解析自动化了数据提取过程,减少了手动工作并增强了业务运营。 这种自动化加快了决策速度,提高了可扩展性。
- 减少错误: 手动数据输入容易出错。 PDF解析工具减少了人为错误,确保更准确的数据处理,减少昂贵的错误。
- 时间和成本节省: 自动化PDF数据提取节省了大量时间和资源,组织可以将这些资源重定向到更具战略性的任务。
- 数据使用的多样性: 提取的数据可以转换为多种格式,使其更易与Excel、Word或Google表格等工具集成。
使用IronPDF解析PDF数据
IronPDF是Iron Software提供的一个强大的库,开发者可以使用它以编程方式从PDF中提取数据。 它支持高效提取文本、表格、图像和PDF元数据提取。
安装 IronPDF。
您可以通过Visual Studio中的IronPDF on NuGet包管理器安装IronPDF。
使用NuGet包管理器安装
在Visual Studio中,在NuGet包管理器中搜索"IronPDF"并点击安装。

使用包管理器控制台安装
或者,在包管理器控制台中使用以下命令:
Install-Package IronPdf
代码示例:使用IronPDF解析PDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
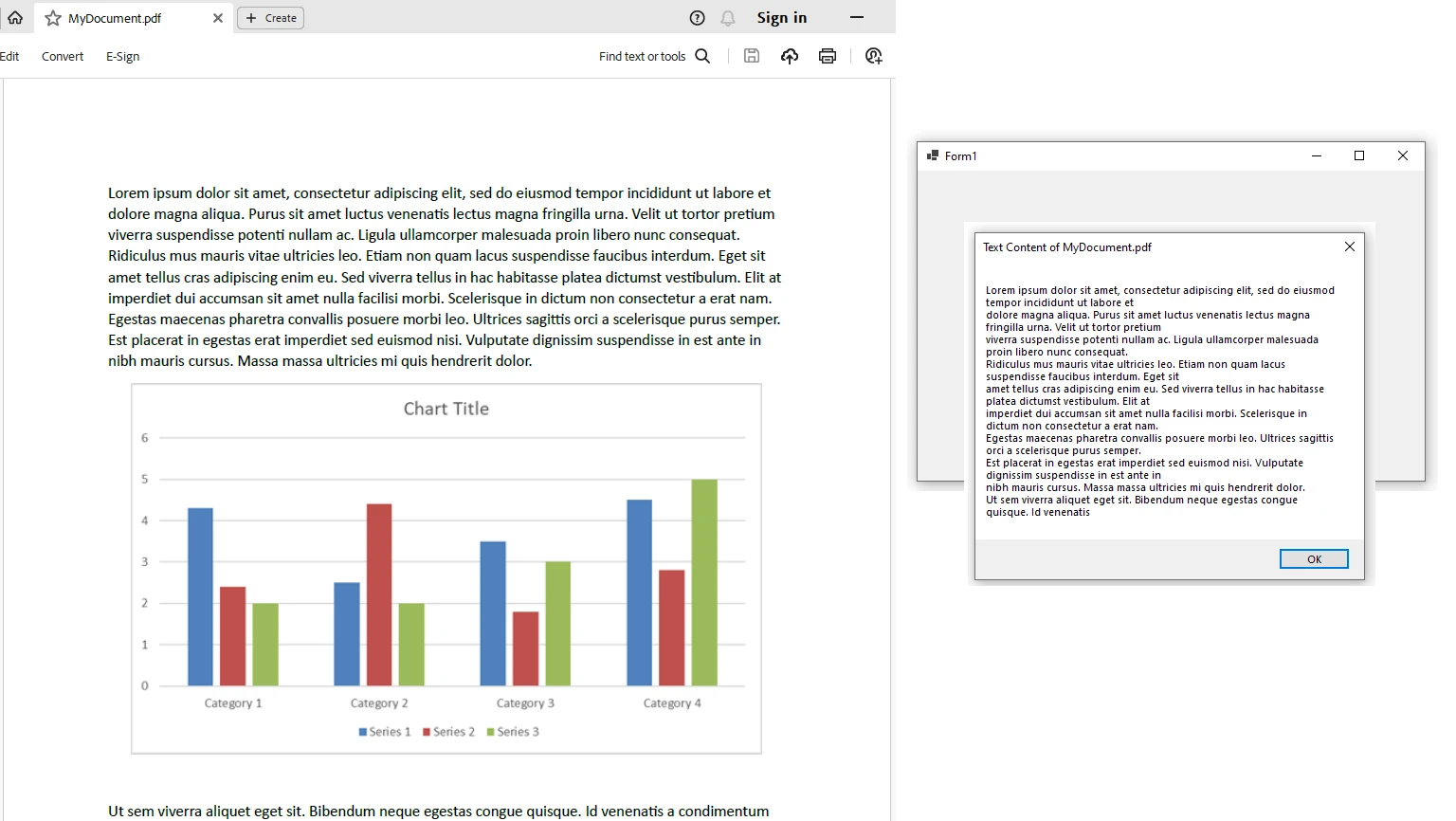
End Namespace在此示例中,我们创建一个使用IronPDF从选择的PDF文件中提取文本的Windows窗体应用程序。提取的文本随后显示在一个消息框中。
IronPDF的许可
IronPDF需要IronPDF的许可密钥,您可以通过免费试用许可证获取。 将许可证密钥添加到您的 appsettings.json 文件中:
{
"IronPdf.LicenseKey": "your license key here"
}结论
高效的PDF解析释放了数字文档的全部潜力,使企业能够自动化流程,减少错误,节省时间和金钱。 通过掌握PDF解析技术和工具,组织可以提高生产力,并利用其数字资产取得更多成就。 IronPDF为希望以编程方式处理PDF文档的开发者提供了理想的解决方案。
常见问题解答
如何使用 C# 从 PDF 文档中提取文本?
可以使用 IronPDF 的 PdfDocument 类加载 PDF 文件,并使用 ExtractAllText() 方法提取文本。这使从 PDF 中轻松检索文本数据成为可能。
IronPDF 中有哪些方法用于从 PDF 中提取图像?
IronPDF 提供的方法如 ExtractImages(),可以用来从 PDF 文件中提取嵌入图像,并将其转换为例如 JPEG 或 PNG 格式。
如何使用 .NET 库将 PDF 数据转换成 CSV 格式?
IronPDF 允许您解析和提取 PDF 中的数据,然后可以通过标准的 .NET 数据操作技术将其以编程方式转换为 CSV 格式。
解析 PDF 文档的常见挑战是什么?
解析 PDF 具有挑战性,因为其复杂的结构,包括多种元素如文本、图像和元数据。像 IronPDF 这样的工具通过提供简单的方法来提取和操纵 PDF 内容,有助于克服这些挑战。
IronPDF 能否在提取前分析 PDF 结构?
是的,IronPDF 提供工具来分析 PDF 结构,允许开发人员识别模式并确定提取所需数据的最高效方法。
使用 IronPDF 的许可要求是什么?
IronPDF 在生产环境中部署需要有效的许可证。然而,为评估目的提供免费试用,允许用户在购买前测试功能。
自动化 PDF 数据提取如何使企业受益?
使用像 IronPDF 这样的工具自动化 PDF 数据提取可以显著减少手动数据输入,减少错误,节省时间和降低运营成本,从而提高整体业务效率。
IronPDF 支持哪些编程语言进行 PDF 数据提取?
IronPDF 专为与 .NET 语言一起使用而设计,主要是 C#,使其能够与其他 .NET 应用程序和服务无缝集成,以实现高效的 PDF 数据提取。
IronPDF 在解析 PDF 数据时是否与 .NET 10 完全兼容?
是的——IronPDF 完全支持 .NET 10,这意味着您可以在 .NET 10 项目中使用其解析功能,例如文本和图像提取、元数据读取、表格解析以及 HTML 到 PDF 的转换,而无需任何变通方法或兼容性问题。













