
Você deveria comprar o IronPDF?
A capacidade de extrair e utilizar dados de PDFs de forma eficiente e programática apresenta desafios únicos para o aspirante a desenvolvedor, devido às complexidades do formato interno dos PDFs.
IronPDF é uma das muitas bibliotecas de programação .NET disponíveis que se destaca por ajudar os desenvolvedores a superar os desafios de extrair conteúdo (texto e imagens) de PDFs de forma confiável, entre muitas outras tarefas relacionadas a PDFs. O IronPDF libera você da necessidade de entender os detalhes da estrutura interna dos PDFs, permitindo que você concentre seu tempo e esforço na entrega rápida e pontual do seu projeto.
Este artigo explora as complexidades da análise de documentos PDF, as ferramentas e técnicas envolvidas e o impacto transformador que a biblioteca IronPDF .NET pode ter para ajudá-lo a compreender o conteúdo do seu PDF.
Conceitos-chave
- Análise de PDF: Extrair dados estruturados de documentos PDF é a essência da análise de PDF. Envolve o reconhecimento de padrões em documentos e a definição de regras para recuperar pontos de dados específicos. As informações extraídas são frequentemente armazenadas em bancos de dados ou utilizadas em outras aplicações.
- Ferramentas de análise de PDF: Essas ferramentas, como IronPDF, Tabula, PyPDF2 e PDFMiner, automatizam o processo de extração. Eles utilizam algoritmos para interpretar a estrutura do PDF e extrair informações com precisão.
- Processo de Extração de Dados: A extração de dados de PDFs normalmente envolve a importação de arquivos para uma ferramenta de análise sintática, a análise da estrutura do documento e a conversão dos dados analisados em formatos como HTML, CSV, XML ou diretamente em aplicativos como Excel ou Word.
- Dados estruturados vs. dados não estruturados: Os PDFs geralmente contêm dados estruturados (por exemplo, tabelas) e dados não estruturados. As ferramentas de análise sintática devem lidar com ambos os tipos de dados para garantir uma extração significativa.
Como analisar dados de documentos PDF: Guia passo a passo
Passo 1: Abra um extrator de PDF online gratuito para analisar arquivos PDF.
Uma ferramenta fácil de usar é o Extrator de PDF Online Gratuito . Acesse o site, onde você poderá ver uma visão geral da ferramenta, incluindo como ela importa PDFs e quais dados ela pode extrair.
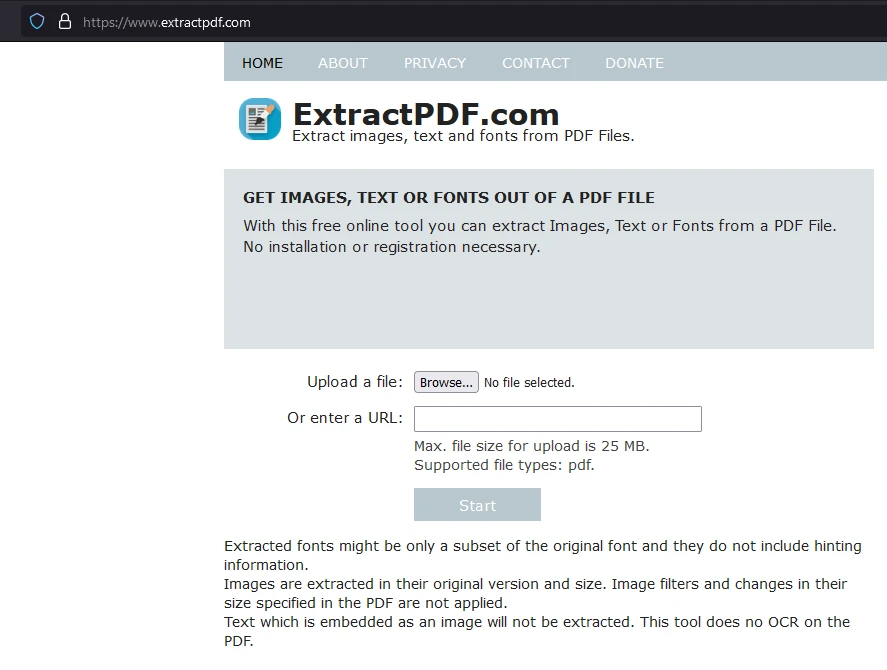
Etapa 2: Carregar o arquivo PDF
Clique em "Procurar" para selecionar o arquivo PDF do qual deseja extrair os dados.
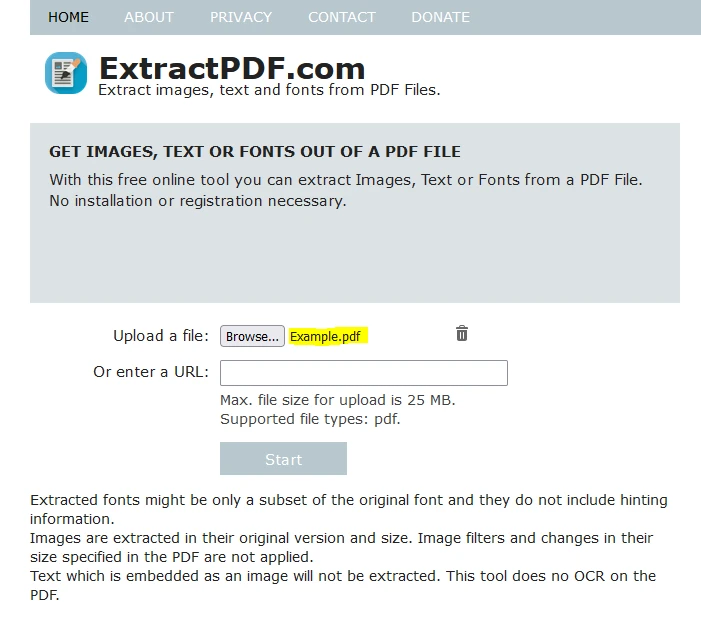
Alternativamente, você pode fazer o upload do arquivo colando um link para o PDF.
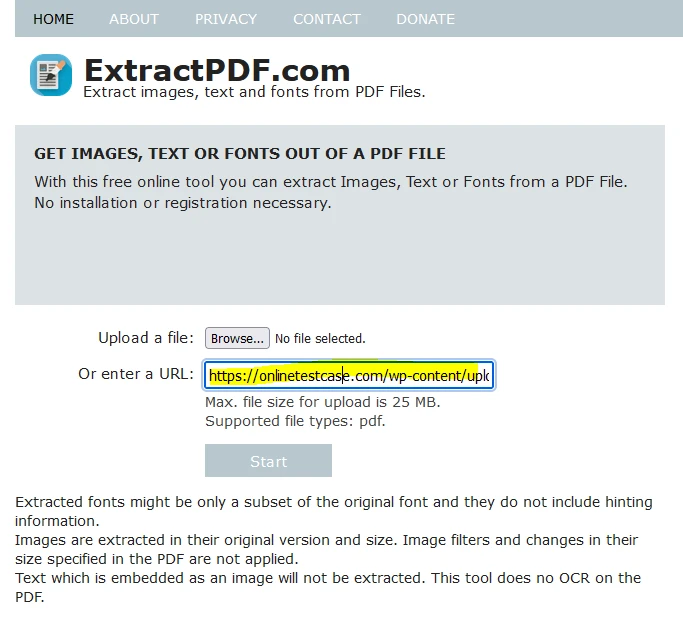
Etapa 3: Iniciar a extração
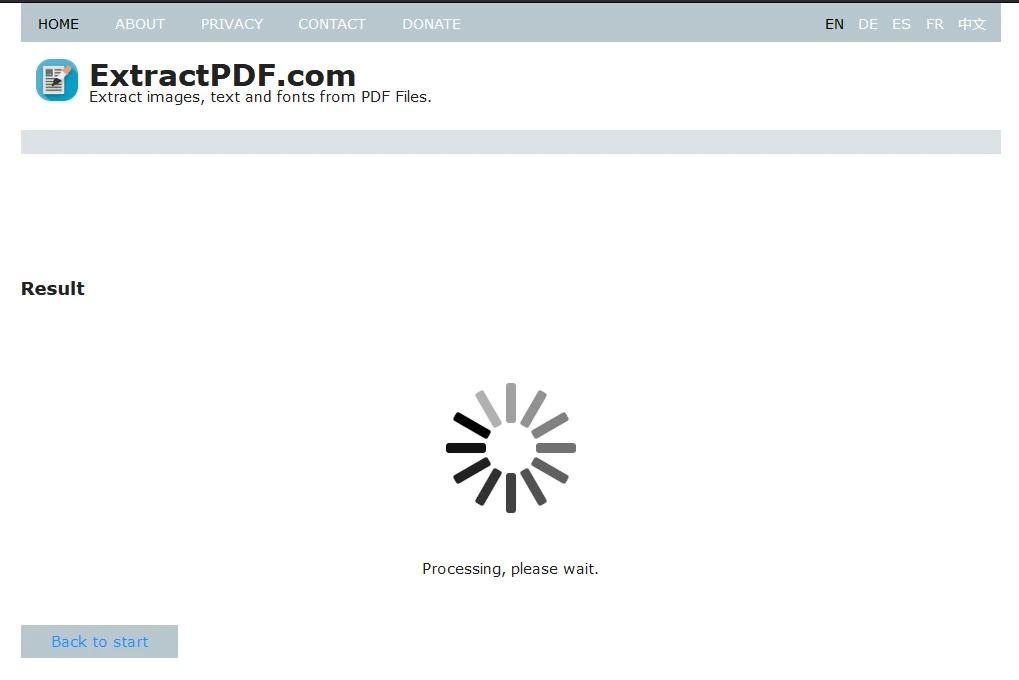
Após carregar o arquivo, clique em "Iniciar" para começar o processo de extração de dados. A ferramenta exibirá uma tela de carregamento durante o processamento.
Etapa 4: Baixe os dados extraídos
Após a extração ser concluída, você poderá baixar os dados. A ferramenta fornece o texto, as imagens, as fontes e os metadados extraídos do PDF em formato tabular.
O texto que pode ser copiado para bancos de dados encontra-se na aba 'Texto'.
Os metadados, incluindo título do documento, autor, data de criação e muito mais, estão disponíveis na aba 'Metadados'.
Por fim, você pode baixar todos os dados extraídos como um arquivo ZIP.
Benefícios da análise sintática de PDFs
- Automação de Processos de Negócio: A análise de PDFs automatiza o processo de extração de dados, reduzindo o trabalho manual e aprimorando as operações comerciais. Essa automação permite uma tomada de decisão mais rápida e maior escalabilidade.
- Redução de erros: A entrada manual de dados é propensa a erros. As ferramentas de análise de PDF reduzem os erros humanos, garantindo um processamento de dados mais preciso e evitando erros dispendiosos.
- Economia de tempo e custos: A automatização da extração de dados de PDFs economiza tempo e recursos significativos, que as organizações podem redirecionar para tarefas mais estratégicas.
- Versatilidade no uso de dados: os dados extraídos podem ser convertidos em vários formatos, facilitando a integração com ferramentas como Excel, Word ou Planilhas Google.
Analisando dados de PDF usando o IronPDF
IronPDF é uma biblioteca poderosa da Iron Software que os desenvolvedores podem usar para extrair dados de PDFs programaticamente. Ele oferece suporte à extração de texto, tabelas, imagens e metadados de PDF com alta eficiência.
Instalando o IronPDF
Você pode instalar o IronPDF através do gerenciador de pacotes NuGet do IronPDF no Visual Studio.
Instale usando o Gerenciador de Pacotes NuGet
No Visual Studio, procure por "IronPDF" no Gerenciador de Pacotes NuGet e clique em instalar.

Instale usando o console do gerenciador de pacotes.
Alternativamente, utilize este comando no Console do Gerenciador de Pacotes:
Install-Package IronPdf
Exemplo de código: Analisando um PDF usando o IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
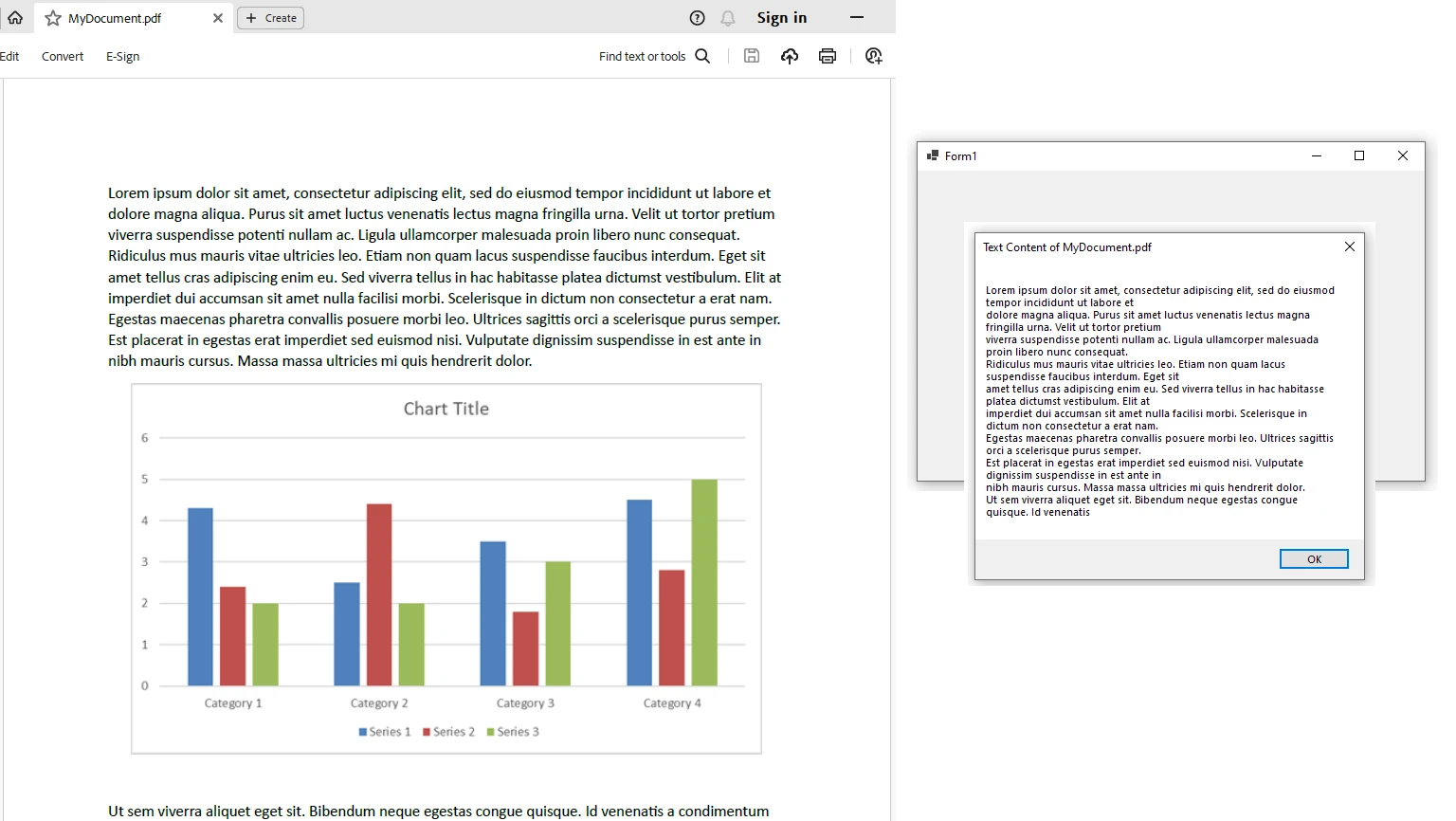
End NamespaceNeste exemplo, criamos um aplicativo Windows Forms que usa o IronPDF para extrair texto de um arquivo PDF selecionado. O texto extraído é então exibido em uma caixa de mensagem.
Licenciamento IronPDF
O IronPDF requer uma chave de licença da IronPDF , que você pode obter como parte de uma licença de avaliação gratuita . Adicione a chave de licença ao seu arquivo appsettings.json:
{
"IronPdf.LicenseKey": "your license key here"
}Solicite uma licença de avaliação gratuita na página de licenciamento de produtos da IronPDF.
Conclusão
A análise eficiente de PDFs libera todo o potencial dos documentos digitais, permitindo que as empresas automatizem processos, reduzam erros e economizem tempo e dinheiro. Ao dominar as técnicas e ferramentas de análise de PDFs, as organizações podem aumentar a produtividade e obter melhores resultados com seus ativos digitais. O IronPDF oferece uma solução ideal para desenvolvedores que desejam trabalhar com documentos PDF de forma programática.
Perguntas frequentes
Como posso extrair texto de documentos PDF usando C#?
Você pode usar a classe PdfDocument do IronPDF para carregar um arquivo PDF e o método ExtractAllText() para extrair o texto. Isso permite a fácil recuperação de dados de texto de PDFs.
Quais métodos estão disponíveis no IronPDF para extrair imagens de um PDF?
O IronPDF oferece métodos como ExtractImages() que podem ser usados para extrair imagens incorporadas de arquivos PDF, convertendo-as em formatos como JPEG ou PNG.
Como posso converter dados de um PDF para o formato CSV usando uma biblioteca .NET?
O IronPDF permite analisar e extrair dados de PDFs, que podem então ser convertidos programaticamente para o formato CSV usando técnicas padrão de manipulação de dados do .NET.
Quais são os desafios comuns na análise de documentos PDF?
Analisar PDFs pode ser um desafio devido à sua estrutura complexa, que inclui diversos elementos como texto, imagens e metadados. Ferramentas como o IronPDF ajudam a superar esses desafios, fornecendo métodos simples para extrair e manipular o conteúdo de PDFs.
O IronPDF pode ser usado para analisar a estrutura de PDFs antes da extração?
Sim, o IronPDF fornece ferramentas para analisar a estrutura de PDFs, permitindo que os desenvolvedores identifiquem padrões e determinem as maneiras mais eficientes de extrair os dados necessários.
Quais são os requisitos de licenciamento para usar o IronPDF?
O IronPDF requer uma licença válida para implantação em ambientes de produção. No entanto, um período de avaliação gratuito está disponível para fins de teste, permitindo que os usuários experimentem os recursos antes de efetuar a compra.
Como a automatização da extração de dados de PDFs beneficia as empresas?
Automatizar a extração de dados de PDFs com ferramentas como o IronPDF pode reduzir significativamente a entrada manual de dados, minimizar erros, economizar tempo e diminuir os custos operacionais, melhorando assim a eficiência geral dos negócios.
Quais linguagens de programação são suportadas pelo IronPDF para extração de dados de PDF?
O IronPDF foi projetado para uso com linguagens .NET, principalmente C#, permitindo integração perfeita com outros aplicativos e serviços .NET para extração eficiente de dados de PDF.
O IronPDF é totalmente compatível com o .NET 10 na análise de dados PDF?
Sim — o IronPDF oferece suporte completo ao .NET 10, o que significa que você pode usar seus recursos de análise, como extração de texto e imagem, leitura de metadados, análise de tabelas e conversão de HTML para PDF em projetos .NET 10 sem soluções alternativas ou problemas de compatibilidade.











