
IronPDF를 구매해야 할까요?
프로그래밍 방식으로 PDF에서 데이터를 효율적으로 추출하고 활용하는 능력은 PDF의 내부 형식의 복잡성 때문에 예비 개발자에게 독특한 도전을 제시합니다.
IronPDF는 많은 .NET 프로그래밍 라이브러리 중 하나로, PDF에서 콘텐츠(텍스트 및 이미지)를 추출하는 어려움을 극복하는 데 독보적으로 위치하고 있습니다. IronPDF는 PDF의 내부 구조에 대해 이해할 필요 없이 프로젝트를 빠르고 제시간에 완료하는 데 시간을 집중할 수 있도록 해줍니다.
이 기사는 PDF 문서 파싱의 복잡성, 관련 도구 및 기술, 그리고 PDF의 콘텐츠를 제어하는 데 도움을 줄 수 있는 IronPDF .NET 라이브러리의 변혁적인 영향을 탐구합니다.
핵심 개념
- PDF 파싱: PDF 문서에서 구조화된 데이터를 추출하는 것이 PDF 파싱의 핵심입니다. 이는 문서 패턴을 인식하고 특정 데이터 포인트를 검색하기 위한 규칙을 정의하는 것을 포함합니다. 추출된 정보는 종종 데이터베이스에 저장되거나 다른 응용 프로그램에서 사용됩니다.
- PDF 파서 도구: IronPDF, Tabula, PyPDF2, PDFMiner와 같은 이 도구들은 추출 프로세스를 자동화합니다. 이들은 PDF 구조를 해석하고 정보를 정확하게 추출하기 위해 알고리즘을 활용합니다.
- 데이터 추출 프로세스: PDF에서 데이터를 추출하는 것은 일반적으로 파일을 파싱 도구로 가져오고, 문서 구조를 분석하고, 구문 분석된 데이터를 HTML, CSV, XML 또는 Excel이나 Word와 같은 응용 프로그램으로 직접 변환하는 것을 포함합니다.
- 구조화된 데이터 vs. 비구조화된 데이터: PDF는 종종 구조화된 데이터(예: 표)와 비구조화된 데이터를 모두 포함하고 있습니다. 파싱 도구는 의미 있는 데이터 추출을 위해 두 가지 유형을 모두 다룰 수 있어야 합니다.
PDF 문서에서 데이터를 파싱하는 방법: 단계별 가이드
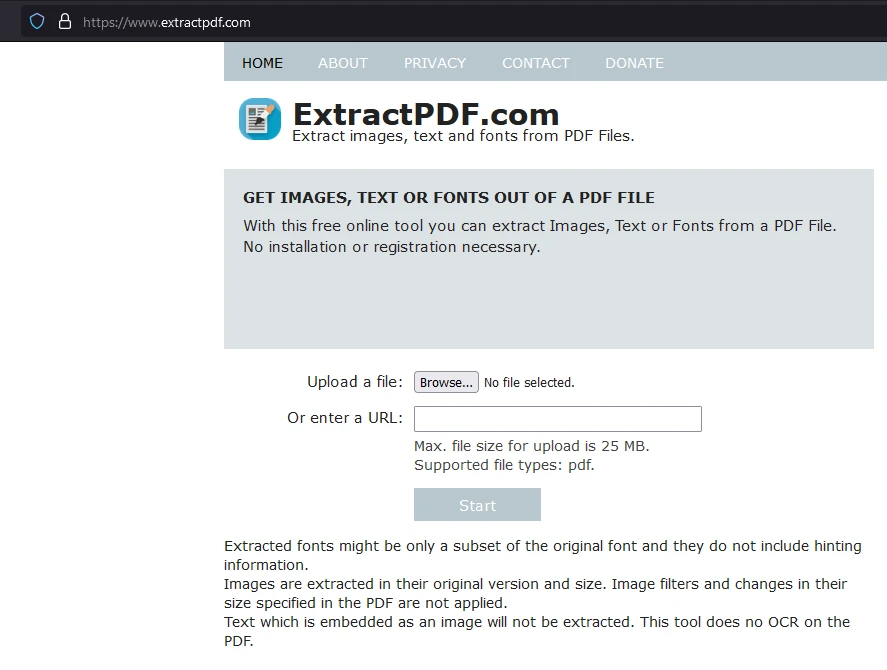
1단계: 무료 온라인 PDF 추출기를 열어 PDF 파일을 파싱하기
사용하기 쉬운 도구 중 하나는 무료 온라인 PDF 추출기입니다. 웹사이트로 이동하여 도구가 PDF를 가져오고 어떤 데이터를 추출할 수 있는지에 대한 개요를 볼 수 있습니다.
2단계: PDF 파일 업로드하기
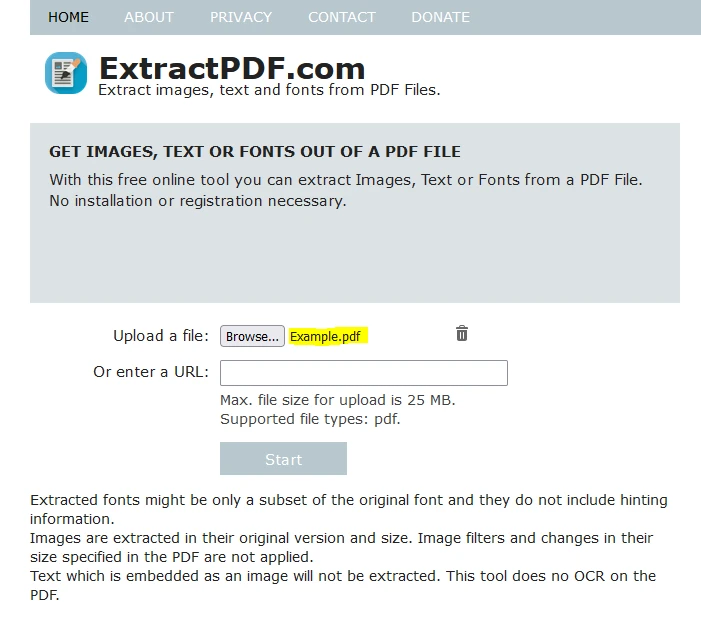
데이터를 추출하고자 하는 PDF 파일을 선택하려면 '찾아보기'를 클릭하십시오.
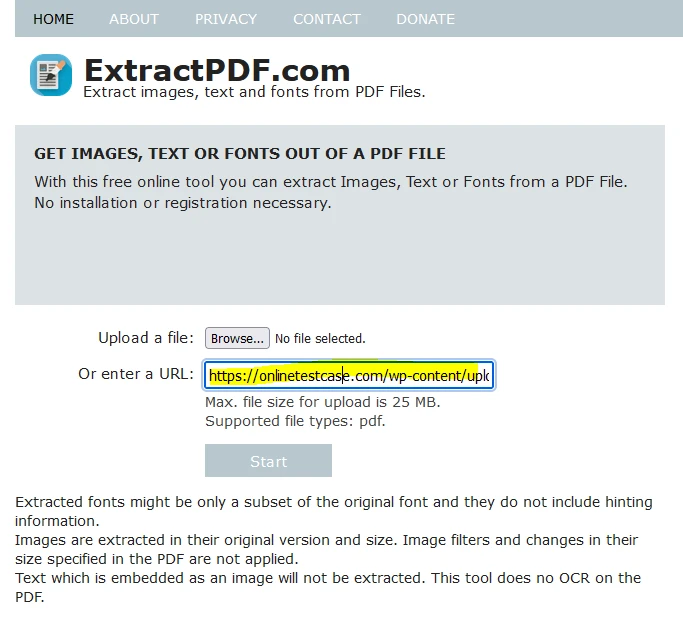
또는 PDF 링크를 붙여 넣어 파일을 업로드할 수 있습니다.
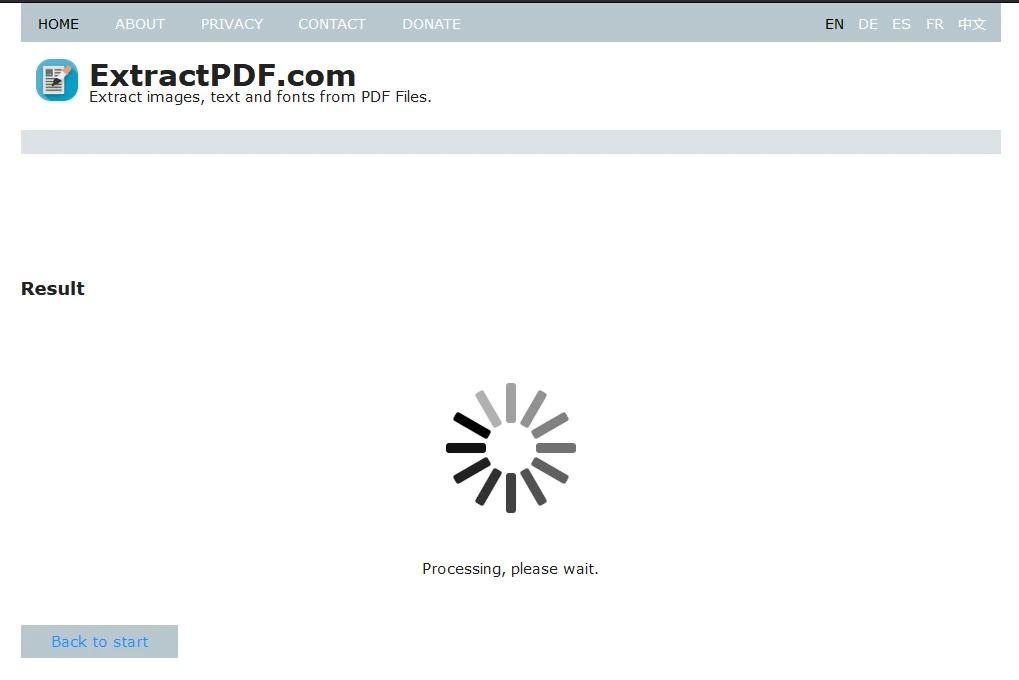
3단계: 추출 시작하기
파일을 업로드한 후, '시작'을 클릭하여 데이터 추출 프로세스를 시작하십시오. 처리 중 도구가 로딩 화면을 표시할 것입니다.
4단계: 추출된 데이터 다운로드하기
추출이 완료되면 데이터를 다운로드할 수 있습니다. 도구는 PDF에서 텍스트, 이미지, 폰트 및 메타데이터를 표 형식으로 제공합니다.
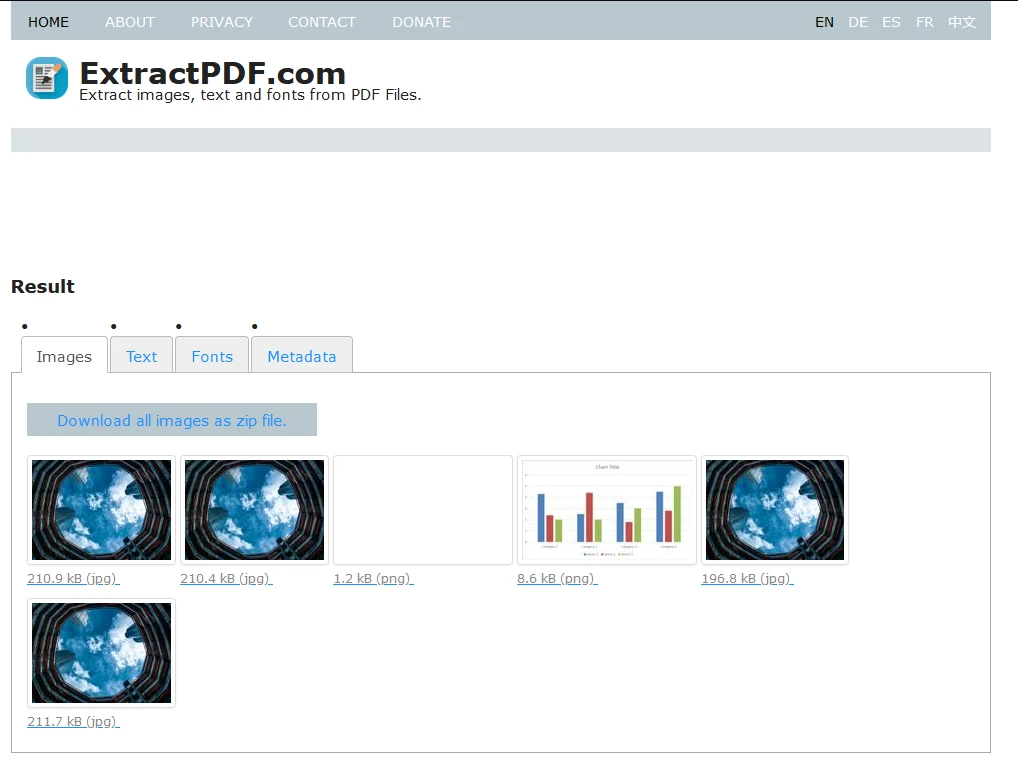
'텍스트' 탭에 데이터베이스로 복사할 수 있는 텍스트가 있습니다.
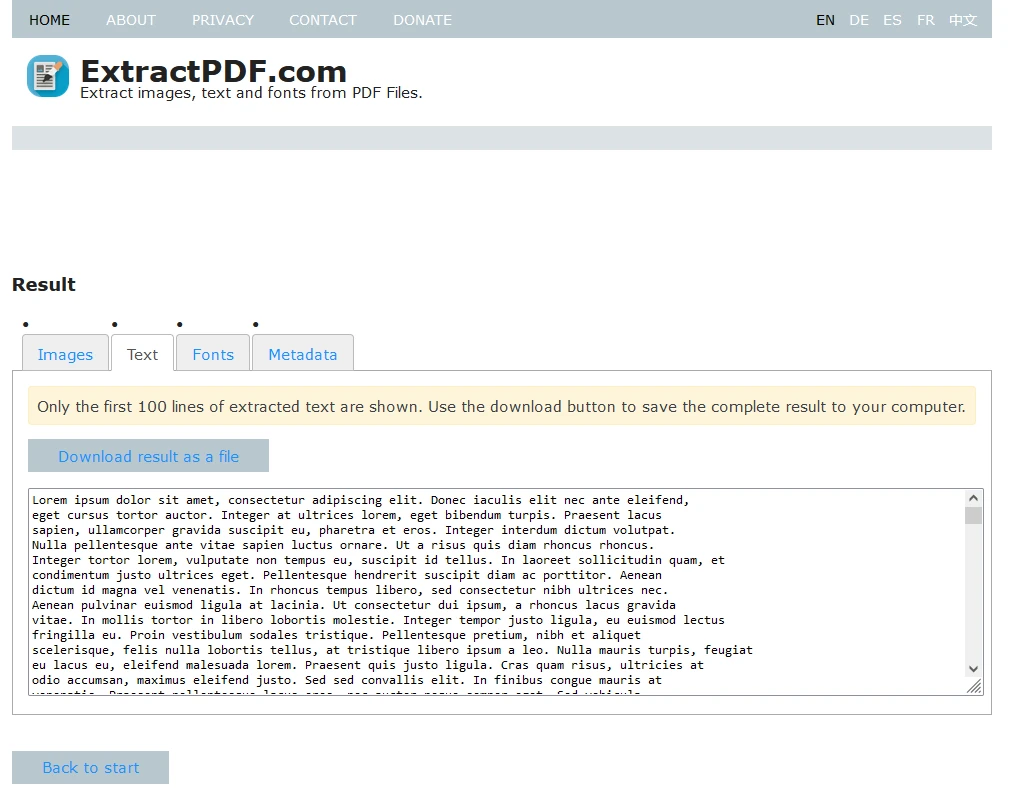
문서 제목, 저자, 작성 날짜 등에 대한 메타데이터는 '메타데이터' 탭에서 확인할 수 있습니다.
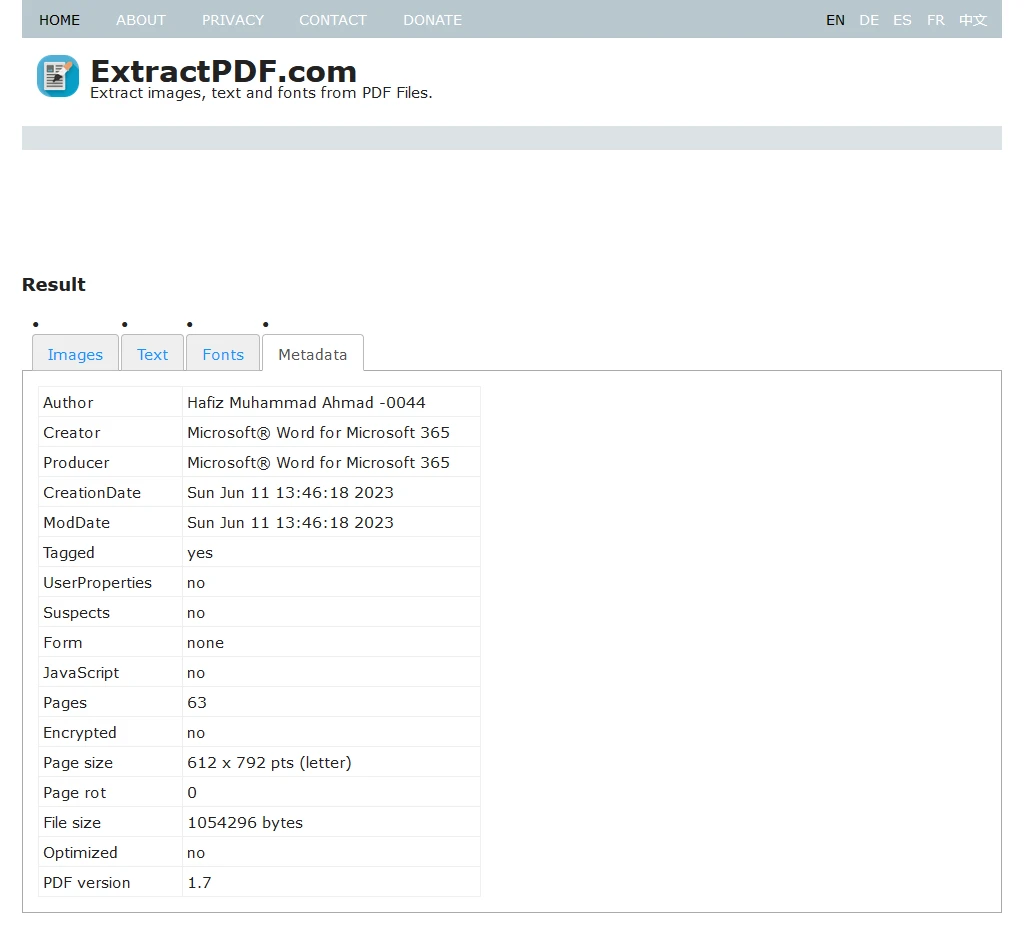
마지막으로, 모든 추출된 데이터를 ZIP 파일로 다운로드할 수 있습니다.
PDF 파싱의 이점
- 비즈니스 프로세스 자동화: PDF 파싱은 데이터 추출 프로세스를 자동화하여 수작업을 줄이고 비즈니스 운영을 향상시킵니다. 이 자동화는 더 빠른 의사결정과 더 큰 확장성을 가능하게 합니다.
- 오류 감소: 수작업 데이터 입력은 실수를 야기하기 쉽습니다. PDF 파싱 도구는 사람의 실수를 줄여 더 정확한 데이터 처리를 보장하고, 비용이 많이 드는 실수를 줄입니다.
- 시간 및 비용 절감: PDF 데이터 추출을 자동화하면 상당한 시간과 자원을 절약할 수 있으며, 조직은 이를 더 전략적인 작업에 재투입할 수 있습니다.
- 데이터 활용의 다양성: 추출된 데이터를 다양한 형식으로 변환할 수 있어 Excel, Word, Google Sheets 같은 도구와 통합하기가 용이합니다.
IronPDF를 사용한 PDF 데이터 파싱
Iron Software에서 제공하는 강력한 라이브러리인 IronPDF를 통해 개발자는 프로그래밍적으로 PDF에서 데이터를 추출할 수 있습니다. 텍스트, 표, 이미지, PDF 메타데이터 추출 지원을 고효율로 제공합니다.
IronPDF 설치 중
IronPDF는 Visual Studio의 NuGet의 IronPDF 패키지 관리자를 통해 설치할 수 있습니다.
NuGet 패키지 관리자를 사용한 설치
Visual Studio에서 NuGet 패키지 관리자를 사용하여 'IronPDF'를 검색하고 설치를 클릭합니다.

패키지 관리자 콘솔을 사용한 설치
또는 패키지 관리자 콘솔에서 이 명령어를 사용하십시오:
Install-Package IronPdf
코드 예제: IronPDF를 사용한 PDF 파싱
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End Namespace이 예제에서는 IronPDF를 사용하여 선택한 PDF 파일에서 텍스트를 추출하고, 추출된 텍스트를 메시지 상자에 표시하는 Windows Forms 응용 프로그램을 만듭니다.
IronPDF 라이센스
IronPDF는 IronPDF에서 제공하는 라이센스 키가 필요하며, 이는 무료 체험 라이선스의 일부로 획득할 수 있습니다. 라이선스 키를 appsettings.json 파일에 추가하세요:
{
"IronPdf.LicenseKey": "your license key here"
}무료 체험 라이센스 요청은 IronPDF 제품 라이센스 페이지에서 가능합니다.
결론
효율적인 PDF 파싱은 디지털 문서의 전체 잠재력을 열어주어 기업이 프로세스를 자동화하고 오류를 줄이며 시간과 비용을 절약할 수 있도록 합니다. PDF 구문 분석 기술과 도구를 마스터함으로써 조직은 생산성을 높이고 디지털 자산을 더 잘 활용할 수 있습니다. IronPDF는 PDF 문서를 프로그래밍 방식으로 다루려는 개발자에게 이상적인 솔루션을 제공합니다.
자주 묻는 질문
C#을 사용하여 PDF 문서에서 텍스트를 추출할 수 있는 방법은 무엇입니까?
IronPDF의 PdfDocument 클래스를 사용하여 PDF 파일을 로드하고 ExtractAllText() 메서드로 텍스트를 추출할 수 있습니다. 이를 통해 PDF에서 텍스트 데이터를 쉽게 가져올 수 있습니다.
IronPDF에서 PDF에서 이미지를 추출하는 데 사용할 수 있는 메서드에는 무엇이 있습니까?
IronPDF는 ExtractImages()와 같은 메서드를 제공하여 PDF 파일에서 임베디드 이미지를 추출하고 JPEG 또는 PNG와 같은 형식으로 변환할 수 있습니다.
.NET 라이브러리를 사용하여 PDF 데이터를 CSV 형식으로 변환할 수 있는 방법은 무엇입니까?
IronPDF를 사용하면 PDF에서 데이터를 구문 분석하고 추출할 수 있으며, 이 데이터를 표준 .NET 데이터 조작 기술을 사용하여 CSV 형식으로 프로그래밍 방식으로 변환할 수 있습니다.
PDF 문서를 구문 분석하는 데 일반적인 문제는 무엇입니까?
PDF는 텍스트, 이미지, 메타데이터와 같은 다양한 요소를 포함하는 복잡한 구조 때문에 구문 분석하기가 어렵습니다. IronPDF와 같은 도구는 PDF 콘텐츠를 추출하고 조작하기 위한 간단한 방법을 제공하여 이러한 문제를 극복하도록 돕습니다.
IronPDF를 사용하여 추출 전에 PDF 구조를 분석할 수 있습니까?
네, IronPDF는 PDF 구조를 분석하는 도구를 제공하여 개발자가 패턴을 식별하고 필요한 데이터를 추출하는 가장 효율적인 방법을 결정할 수 있도록 합니다.
IronPDF를 사용하는데 필요한 라이선스 요건은 무엇입니까?
IronPDF는 프로덕션 환경에서의 배포를 위해 유효한 라이선스가 필요합니다. 하지만 구매 전에 기능을 테스트할 수 있도록 평가 목적으로 무료 체험판을 제공합니다.
PDF 데이터 추출을 자동화하면 비즈니스에 어떤 이점이 있습니까?
IronPDF와 같은 도구를 사용하여 PDF 데이터 추출을 자동화하면 수작업 데이터 입력을 크게 줄이고, 오류를 최소화하며, 시간을 절약하고 운영 비용을 낮출 수 있어 전반적인 비즈니스 효율성을 향상시킵니다.
IronPDF에서 PDF 데이터 추출을 지원하는 프로그래밍 언어는 무엇입니까?
IronPDF는 주로 C#과 같은 .NET 언어와 함께 사용할 수 있도록 설계되어 다른 .NET 애플리케이션 및 서비스와 매끄럽게 통합하여 효율적인 PDF 데이터 추출을 가능하게 합니다.
IronPDF는 .NET 10과 완전히 호환되어 PDF 데이터를 구문 분석할 수 있습니까?
네 — IronPDF는 .NET 10을 완벽하게 지원하여 .NET 10 프로젝트에서 Text 및 이미지 추출, 메타데이터 읽기, 테이블 구문 분석, HTML-to-PDF 변환과 같은 구문 분석 기능을 문제없이 사용할 수 있습니다.











